# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
自回归(AR)大语言模型逐 token 顺序解码的范式限制了推理效率;扩散 LLM(dLLM)以并行生成见长,但过去难以稳定跑赢自回归(AR)模型,尤其是在 KV Cache 复用、和 可变长度 支持上仍存挑战。
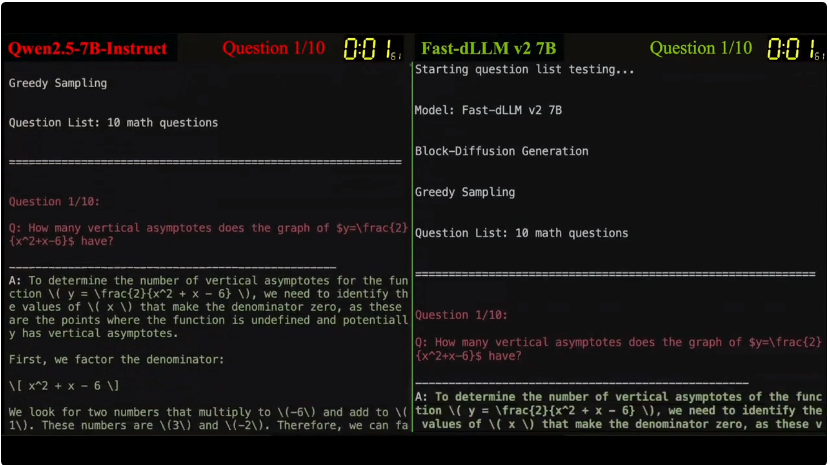
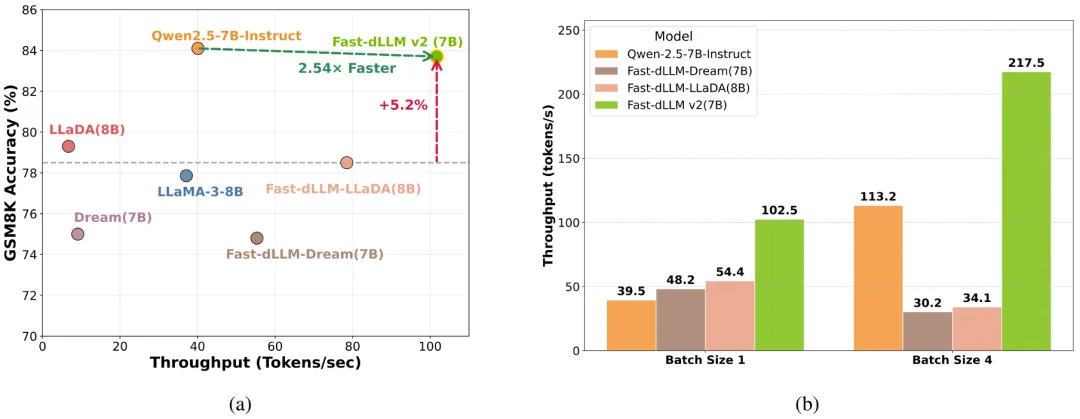
Fast-dLLM v2 给出了一条务实路线:将预训练 AR 模型适配为适配为能并行解码的 Block-dLLM—— 且只需~1B tokens 量级的微调即可达到 “无损” 迁移,不必训练数百 B tokens(如 Dream 需~580B tokens)。在 A100/H100 上,它在保持精度的同时,将端到端吞吐显著拉高,最高可达 2.5×。

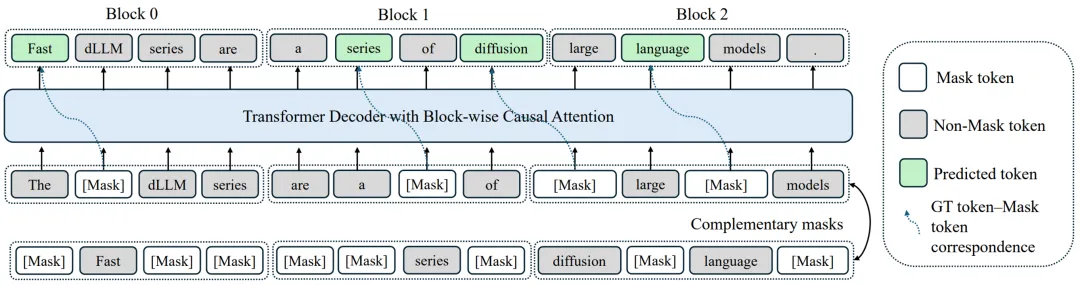
1)块式扩散与 AR - 友好注意力
Fast-dLLM v2 按固定块大小把序列切成若干块:块内双向注意力以并行去噪,块间保持左到右的因果关系,从而既能并行、又能沿用 AR 的语义组织、可变长度和 KV Cache;配合互补掩码(complementary masking)与 token-shift,保证每个 token 都在 “可见 / 被遮” 两种视角下学习,稳定恢复 AR 语义表征。
2)层级缓存(Hierarchical Cache)
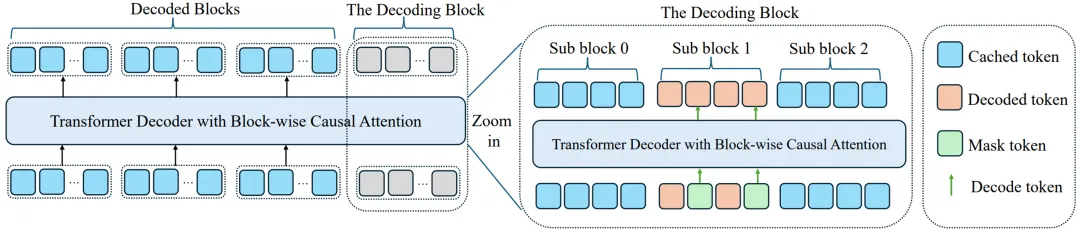
3)置信度感知的并行解码
延续 v1 的思路:当某位置的预测置信度超过阈值(如 0.9),即可并行确定多个 token,其余不确定位置保留待后续细化。在 GSM8K 上,阈值 0.9 时吞吐从 39.1→101.7 tokens/s,提速约 2.6×,精度影响可忽略。

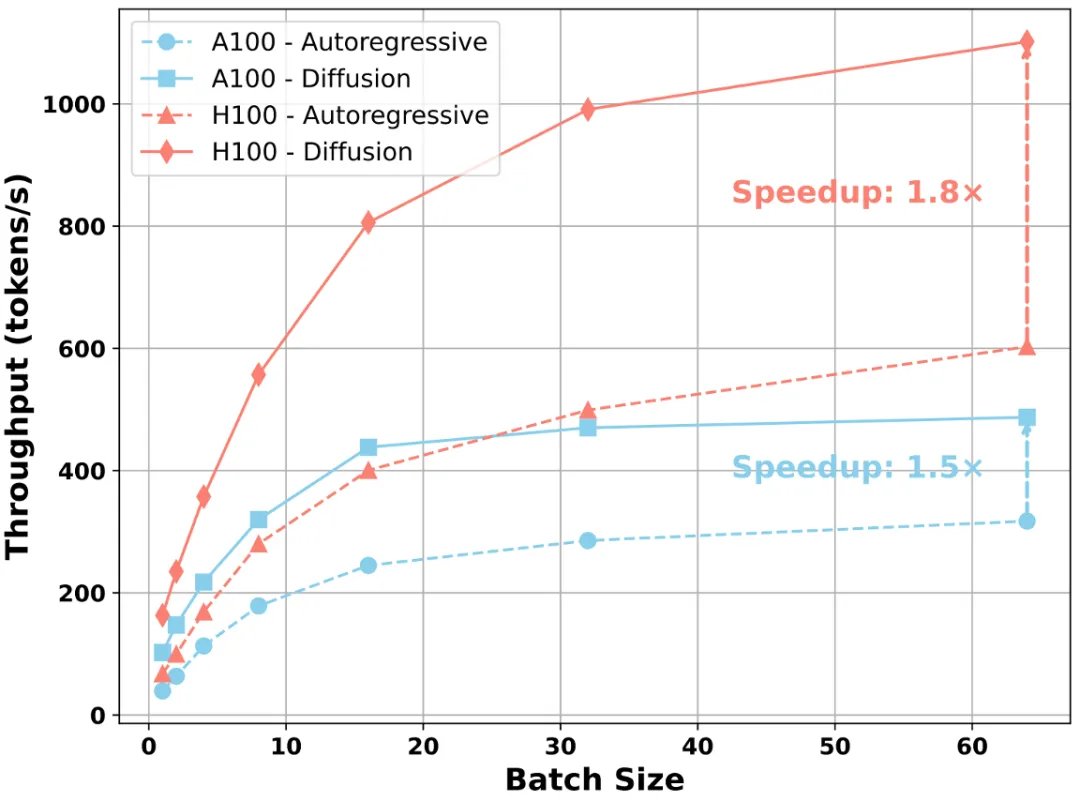
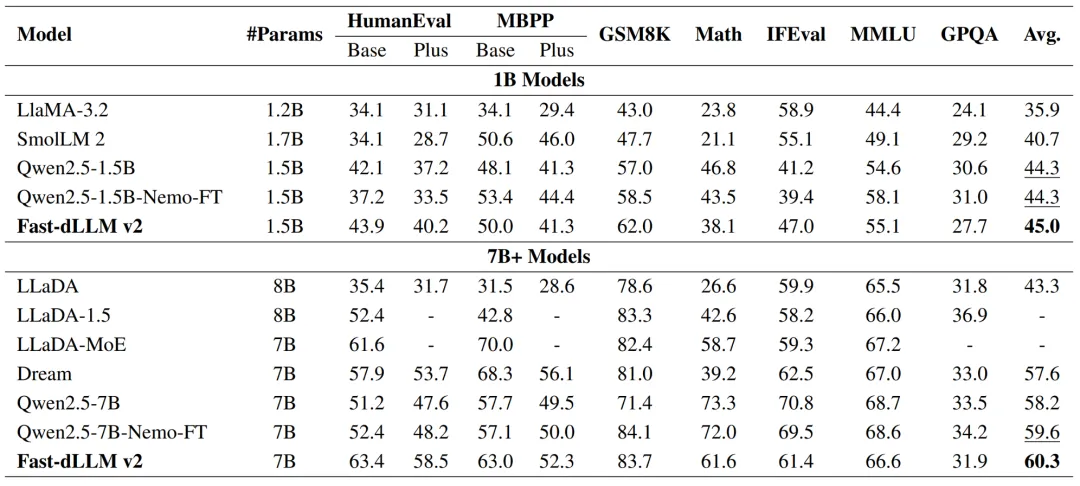
数据 / 算力成本:以~1B tokens 量级微调把 AR 模型适配为 Block Diffusion LLM(对比 Dream 的~500B tokens),门槛显著降低;论文给出了 Qwen2.5-Instruct 1.5B/7B 在 64×A100 上的具体训练步数与配置,只需要几个小时即可完成训练,可复现性强。
Fast-dLLM v2 提供了一条务实路线:用很少的数据(~1B tokens)把 AR 模型适配为 Block Diffusion LLM,相较等规模 AR 的端到端吞吐量约提升 2.5×,精度保持可比,并且关键开关(块大小、阈值、缓存)都能工程化地按目标调优,这是一个成本与收益比较均衡的解法。
文章来自于“机器之心”,作者“机器之心”。



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
