# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
前脚谢赛宁刚宣告VAE在图像生成领域退役,后脚清华与快手可灵团队也带着无VAE潜在扩散模型SVG来了。
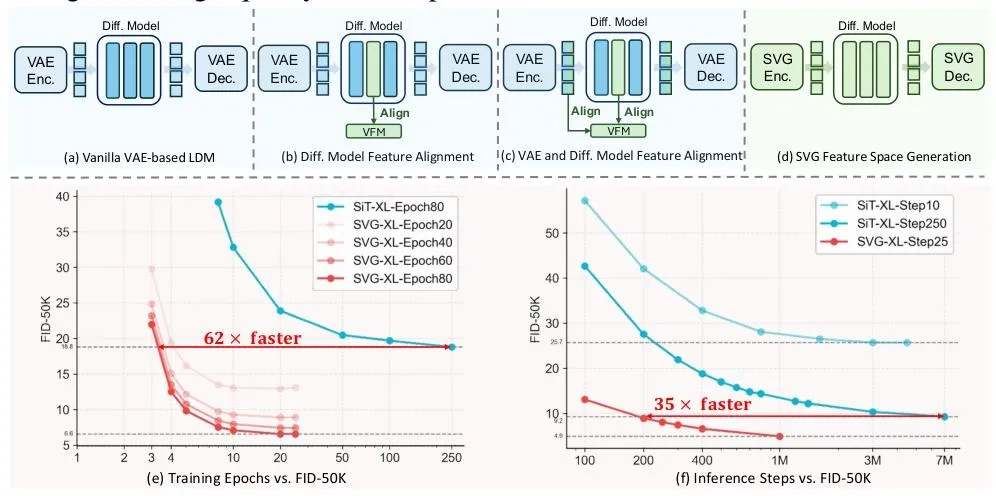
该方法实现了在训练效率上62倍、生成速度上35倍的提升。
VAE为何被接连抛弃?主要还是因为语义纠缠的缺陷——语义特征都放在同一个潜空间,调一个数值就会“牵一发而动全身”,比如只想改变猫的颜色,结果体型、表情都跟着变。
和谢赛宁团队极简复用预训练编码器、改造DiT架构,专注于生成性能的RAE不同,SVG通过语义+细节双分支+分布对齐,实现了多任务通用。

下面具体来看。
在传统的「VAE+扩散模型」图像生成范式中,VAE的核心作用是将高分辨率图像压缩为低维的潜空间特征(可以理解为图像的简化代码),供后续扩散模型学习生成逻辑。
但这样会使不同类别、不同语义的图像特征会混乱地交织在一起,比如猫和狗的特征边界模糊不清等。
直接导致两个问题:
并且,生成的特征空间用途单一,除了图像生成,几乎无法适配图像识别、语义分割等其他视觉任务。
面对VAE的困境,谢赛宁团队的RAE技术选择了极致聚焦生成的思路。直接复用DINOv2、MAE等成熟的预训练编码器,不额外修改编码器结构,仅通过优化解码器来还原图像细节,同时针对性地改造扩散模型架构。
最终实现了生成效率与质量的跨越式提升,简单说就是把重心全放在了“把图生成得又快又好”上。
而清华&快手可灵团队的SVG技术,则走了兼顾生成与多任务通用的路线,核心差异就在于对特征空间的构建逻辑上。
RAE是直接复用预训练特征,SVG 则是主动构建语义与细节融合的特征空间。
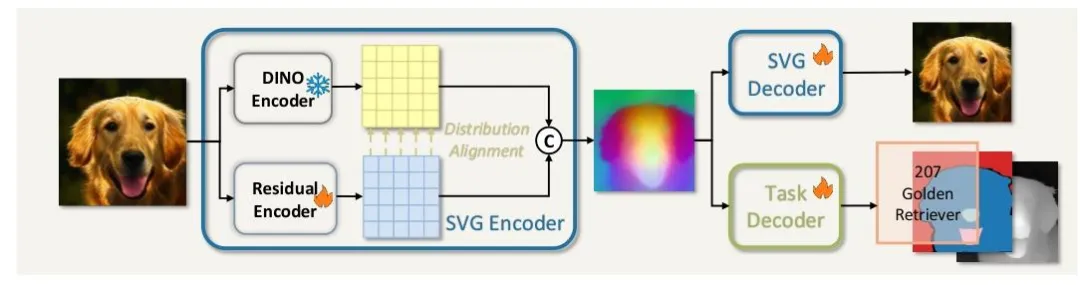
具体来看,SVG选择以DINOv3预训练模型作为语义提取器。
原因是DINOv3经过大规模自监督学习,能够精准捕捉图像的高层语义信息,让猫、狗、汽车等不同类别的特征边界能够清晰可辨,从根源上解决了语义纠缠问题。
但团队也发现,DINOv3提取的特征偏重于宏观语义,会丢失颜色、纹理等高频细节,因此又专门设计了一个轻量级的残差编码器来进行细节补充,针对性地学习这些被忽略的细节信息。
而为了让「语义」和「细节补充」能够完美融合,SVG还加入了关键的分布对齐机制。
这一机制通过技术手段调整残差编码器输出的细节特征,使其在数值分布上与DINOv3的语义特征完全匹配,避免细节信息扰乱语义结构。
实验数据也印证了这一机制的重要性。去掉分布对齐后,SVG生成图像的FID值(衡量生成图像与真实图像相似度的核心指标,数值越低越优)从6.12升至9.03,生成质量大幅下滑。

实验结果显示,SVG在生成质量、效率、多任务通用性上全面超越传统VAE方案。
训练效率方面,在ImageNet 256×256数据集上,SVG-XL模型仅训练80个epoch,在无分类器引导时FID达6.57,远超同规模基于VAE的SiT-XL(22.58);如果延长训练至1400个epoch,FID可低至1.92,接近当前顶级生成模型水平。
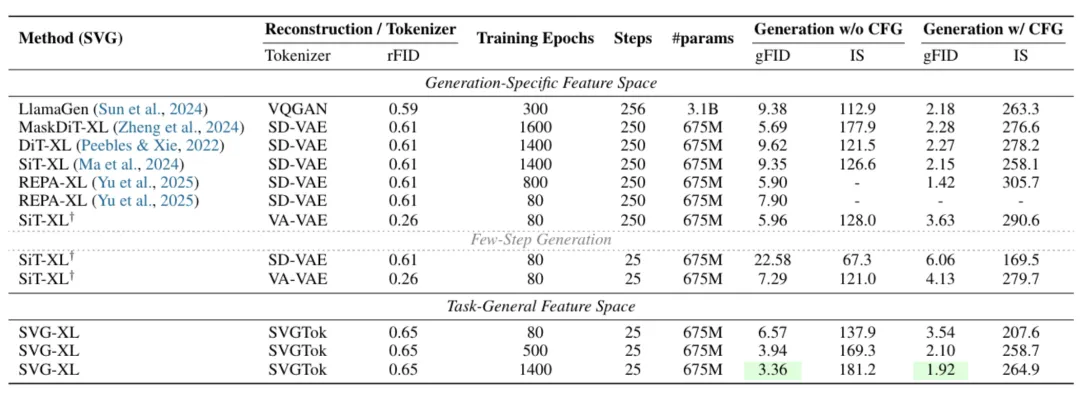
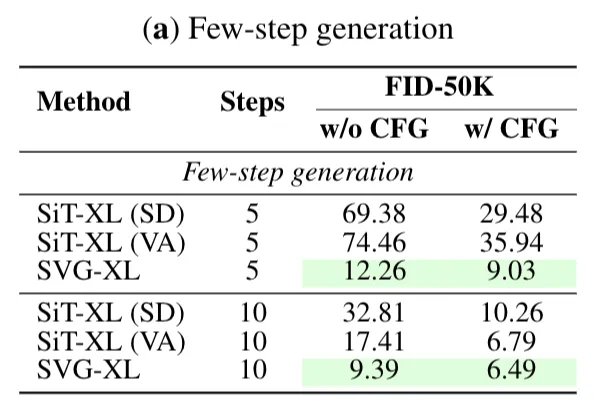
推理效率方面,消融实验中,5步采样时,SVG-XL的gFID为12.26,而SiT-XL(SD-VAE)为69.38、SiT-XL(VA-VAE)为74.46。这表明在较少的采样步数下,SVG-XL就能达到较好的生成质量。
不仅是生图,SVG的特征空间继承了DINOv3的能力,可直接用于图像分类、语义分割、深度估计等任务,且无需微调编码器。例如,在ImageNet-1K分类任务中Top-1精度达到81.8%,与原始DINOv3几乎一致;在ADE20K语义分割任务中mIoU达46.51%,接近专门的分割模型。

团队由郑文钊担任项目负责人,目前是加州大学伯克利分校博士后。此前,他在清华大学自动化系获博士学位,研究集中在人工智能和深度学习领域。
同样来自清华自动化系的史明磊和王皓霖目前均在攻读博士学位,研究重点为多模态生成模型。
其中,史明磊透露自己还在创办一家专注于人工智能应用的公司。

△从左到右:郑文钊、史明磊、王皓霖
Ziyang Yuan、Xiaoshi Wu、Xintao Wang、Pengfei Wan则来自快手可灵团队。
其中,Pengfei Wan是快手可灵视频生成模型负责人。
从谢赛宁团队的RAE到清华快手的SVG,尽管技术路线各有侧重,但从两者的突破可以看出,预训练视觉模型的特征空间,或许已经具备了替代VAE的能力。
论文地址:https://arxiv.org/abs/2510.15301
代码地址:https://github.com/shiml20/SVG
文章来自于“量子位”,作者“闻乐”。


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
