# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
人工智能,即大家说的AI(Artificial Intelligent),当属最热门的技术之一。
今天站在嵌入式的角度给大家分享一下人工智能包含的一些要点。
人类科技发展日新月异、突飞猛进,不断涌现令人激动的新技术。当前,人工智能(Artificial Intelligent)当属最热门的技术之一。
人工智能(Artificial Intelligence),英文缩写为AI。它是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。它是一个构建能够推理、学习和行动的计算机和机器的科学领域,这种推理、学习和行动通常需要人类智力,或者涉及超出人类分析能力的数据规模。
下图中的人工智能、机器学习、深度学习、数据挖掘、模式识别等,这些非常相关的术语或知识我们经常看到,也见到很多关于它们之间关系的文章和讨论。一般来说,人工智能是一个很大的研究领域,是很多学科交叉形成的;机器学习是人工智能的一个分支,提供很多算法,深度学习又是机器学习的一个重要分支,它基于人工神经网络;而数据挖掘、模式识别是偏向算法应用的部分。它们之间相辅相成,另外也需要其他领域的知识支持。
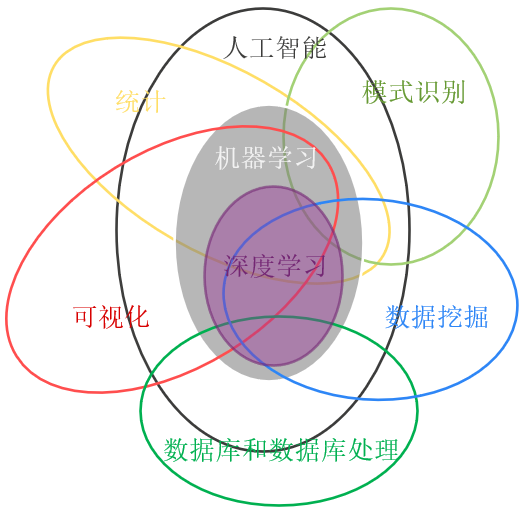
人工智能的目标包括:推理、知识表示、自动规划、机器学习、自然语言理解、计算机视觉、机器人学和强人工智能共八个方面。
• 知识表示和推理包括:命题演算和归结、谓词演算和归结,可以进行一些公式或定理的推导。
• 自动规划包括机器人的计划、动作和学习,状态空间搜索,敌对搜索,规划等内容。
• 机器学习这一研究领域是由AI的一个子目标发展而来,用来帮助机器和软件进行自我学习来解决遇到的问题。
• 自然语言处理是另一个由AI的一个子目标发展而来的研究领域,用来帮助机器与真人进行沟通交流。
• 计算机视觉是由AI的目标而兴起的一个领域,用来辨认和识别机器所能看到的物体。
• 机器人学也是脱胎于AI的目标,用来给一个机器赋予实际的形态以完成实际的动作。
• 强人工智能是人工智能研究的最主要目标之一,强人工智能也指通用人工智能(Artificial General Intelligence,AGI),或具备执行一般智慧行为的能力。强人工智能通常把人工智能和意识、感性、知识和自觉等人类的特征互相连结。

人工智能的三要素:数据、算法、模型。
• 数据是基础,基于数据发现数据的规律。
• 算法是关键,如何用数据去求解模型,变成可以运行的程序。
• 模型是核心,用何种模型解释数据,发现数据规律。
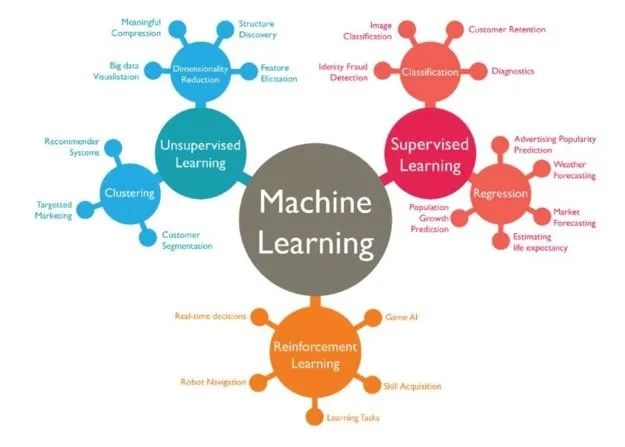
机器学习是人工智能的一个重要分支,它通过计算的手段、学习经验(也可以说是利用经验)来改善系统的性能。它包括:有监督学习、无监督学习和强化学习。其中的算法有:回归算法(最小二乘法、LR等),基于实例的算法(KNN、LVQ等),正则化方法(LASSO等),决策树算法(CART、C4.5、RF等),贝叶斯方法(朴素贝叶斯、BBN等),基于核的算法(SVM、LDA等),聚类算法(K-Means、DBSCAN、EM等),关联规则(Apriori、FP-Grouth),遗传算法,人工神经网络(PNN、BP等),深度学习(RBN、DBN、CNN、DNN、LSTM、GAN等),降维方法(PCA、PLS等),集成方法(Boosting、Bagging、AdaBoost、RF、GBDT等)。
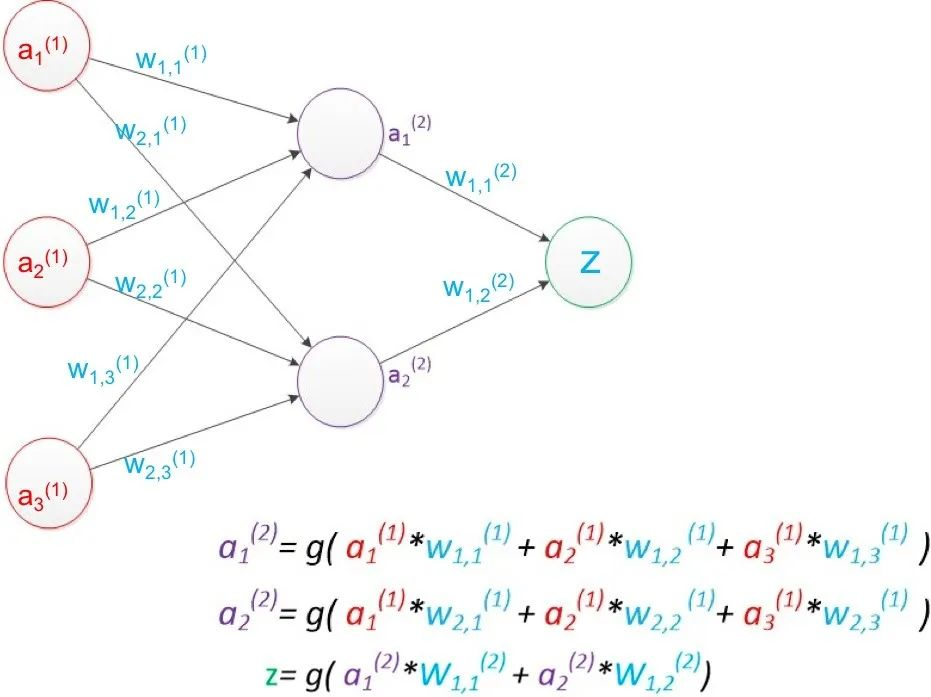
深度学习是机器学习的一个重要分支,它基于人工神经网络。深度学习的学习过程之所以是深度性的,是因为人工神经网络的结构由多个输入、输出和隐藏层构成。每个层包含的单元可将输入数据转换为信息,供下一层用于特定的预测任务。得益于这种结构,机器可以通过自身的数据处理进行学习。以两层网络为例,如下图,其中a是“单元”的值,w表示“连线”权重,g是激活函数,一般为方便求导采用sigmoid函数。采用矩阵运算来简化图中公式:a(2) = g( a(1) * w(1) ), z = g( a(2) * w(2) )。设训练样本的真实值为y,预测值为z,定义损失函数 loss = (z – y)2,所有参数w优化的目标就是使对所有训练数据的损失和尽可能的小,此时这个问题就被转化为一个优化问题,常用梯度下降算法求解。一般使用反向传播算法,从后往前逐层计算梯度,并最终求解各参数矩阵。
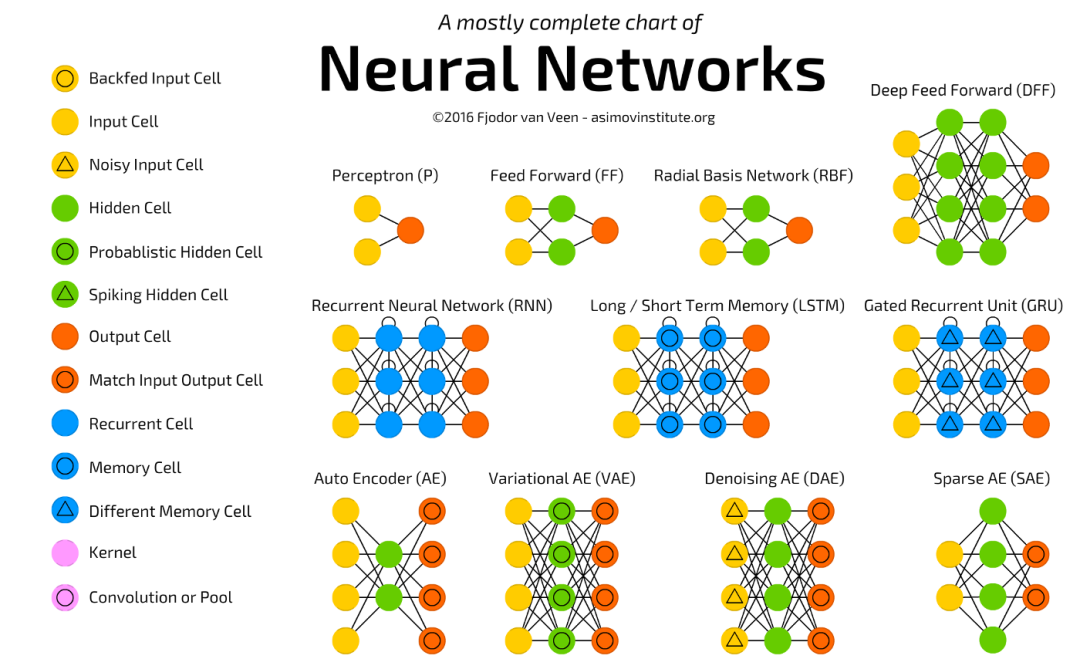
深度学习的神经网络(Neural Network)架构
• 感知器(Perceptron)
o 感知器是所有神经网络中最基本的,也是更复杂的神经网络的基本组成部分。它只连接一个输入神经元和一个输出神经元。
• 前馈(Feed-Forward)网络
o 前馈网络是感知器的集合,其中有三种基本类型的层: 输入层、隐藏层和输出层。在每个连接过程中,来自前一层的信号被乘以一个权重,增加一个偏置,然后通过一个激活函数。前馈网络使用反向传播迭代更新参数,直到达到理想的性能。
• 循环神经网络(Recurrent Neural Network/RNN)
o 循环神经网络是一种特殊类型的网络,它包含环和自重复,因此被称为“循环”。由于允许信息存储在网络中,RNNs使用以前训练中的推理来对即将到来的事件做出更好、更明智的决定。它是具有时间联结的前馈神经网络:它们有了状态,通道与通道之间有了时间上的联系。神经元的输入信息,不仅包括前一神经细胞层的输出,还包括它自身在先前通道的状态。
• 长短期记忆网络(Long Short Term Memory Network/LSTM)
o 由于上下文信息的范围在实践中是非常有限的,所以RNNs有个大问题。给定的输入对隐藏层(即对网络的输出)输入的影响(反向传播误差),要么指数级爆炸,要么网络连接循环衰减为零。解决这个梯度消失问题的方法是长短期记忆网络(LSTM)。
• 自动编码器(Auto Encoder/AE)
o 自动编码器的基本思想是将原始的高维数据“压缩”成高信息量的低维数据,然后将压缩后的数据投影到一个新的空间中。自动编码器有许多应用,包括降维、图像压缩、数据去噪、特征提取、图像生成和推荐系统。它既可以是无监督的方法,也可以是有监督的,可以得到对数据本质的洞见。
• 变分自动编码器(Variational Auto Encoder/VAE)
o 自动编码器学习一个输入(可以是图像或文本序列)的压缩表示,例如,压缩输入,然后解压缩回来匹配原始输入,而变分自动编码器是学习基于数据的概率分布。不仅仅是学习一个代表数据的函数,它还获得了更详细和细致的数据视图,从分布中抽样并生成新的输入数据样本。
• 卷积神经网络(Deep Convolutional Network/DCN)
o 图像具有非常高的维数,因此训练一个标准的前馈网络来识别图像将需要成千上万的输入神经元,除了显而易见的高计算量,还可能导致许多与神经网络中的维数灾难相关的问题。卷积神经网络提供了一个解决方案,利用卷积和池化层,来降低图像的维度。由于卷积层是可训练的,但参数明显少于标准的隐藏层,它能够突出图像的重要部分,并向前传播每个重要部分。传统的CNNs(卷积神经网络)中,最后几层是隐藏层,用来处理“压缩的图像信息”。
• 反卷积神经网络(Deconvolutional Network/DN)
o 正如它的名字所暗示的那样,反卷积神经网络与卷积神经网络操作相反。DN不是通过卷积来降低图像的维数,而是利用反卷积来创建图像,通常是从噪声中获得图像。
• 生成对抗网络(Generative Adversarial Network/GAN)
o 生成对抗网络是一种专门设计用于生成图像的网络,由两个网络组成: 一个鉴别器和一个生成器。鉴别器的任务是区分图像是从数据集中提取的还是由生成器生成的,生成器的任务是生成足够逼真的图像,以至于鉴别器无法区分图像是否真实。随着时间的推移,在谨慎的监督下,这两个对手相互竞争,彼此都想成功地改进对方。最终的结果是一个训练有素的生成器,可以生成逼真的图像。鉴别器是一个卷积神经网络,其目标是最大限度地提高识别真假图像的准确率,而生成器是一个反卷积神经网络,其目标是最小化鉴别器的性能。
• 马尔可夫链(Markov Chain/MC)
o 马尔可夫链(MC:Markov Chain)或离散时间马尔可夫链(DTMC:MC or discrete time Markov Chain)在某种意义上是BMs和HNs的前身。
• 霍普菲尔网络(Hopfield network/HN)
o 一种每一个神经元都跟其它神经元相互连接的网络。
• 玻尔兹曼机(Boltzmann machines/BM)
o 和霍普菲尔网络很接近,差别只是:一些神经元作为输入神经元,剩余的则是作为隐神经元。在整个神经网络更新过后,输入神经元成为输出神经元。刚开始神经元的权重都是随机的,通过反向传播(back-propagation)算法进行学习,或是最近常用的对比散度(contrastive divergence)算法(马尔可夫链用于计算两个信息增益之间的梯度)。
• 回声状态网络(Echo state networks/ESN)
o 回声状态网络是另一种不同类型的(循环)网络。它的不同之处在于:神经元之间的连接是随机的(没有整齐划一的神经细胞层),其训练过程也有所不同。不同于输入数据后反向传播误差,ESN先输入数据、前馈、而后更新神经元状态,最后来观察结果。它的输入层和输出层在这里扮演的角色不太常规,输入层用来主导网络,输出层作为激活模式的观测器随时间展开。在训练过程中,只有观测和隐藏单元之间连接会被改变。
• 深度残差网络(Deep residual networks/DRN)
o 是非常深的FFNN网络,它有一种特殊的连接,可以把信息从某一神经细胞层传至后面几层(通常是2到5层)。
• Kohonen 网络(KN)
o KN利用竞争学习来对数据进行分类,不需要监督。先给神经网络一个输入,而后它会评估哪个神经元最匹配该输入。然后这个神经元会继续调整以更好地匹配输入数据,同时带动相邻的神经元。相邻神经元移动的距离,取决于它们与最佳匹配单元之间的距离。
• 神经图灵机(Neural Turing machines/NTM)
o 可以理解为对LSTM的抽象,它试图把神经网络去黑箱化(以窥探其内部发生的细节)。NTM不是把记忆单元设计在神经元内,而是分离出来。NTM试图结合常规数字信息存储的高效性、永久性与神经网络的效率及函数表达能力。它的想法是设计一个可作内容寻址的记忆库,并让神经网络对其进行读写操作。NTM名字中的“图灵(Turing)”是表明,它是图灵完备(Turing complete)的,即具备基于它所读取的内容来读取、写入、修改状态的能力,也就是能表达一个通用图灵机所能表达的一切。

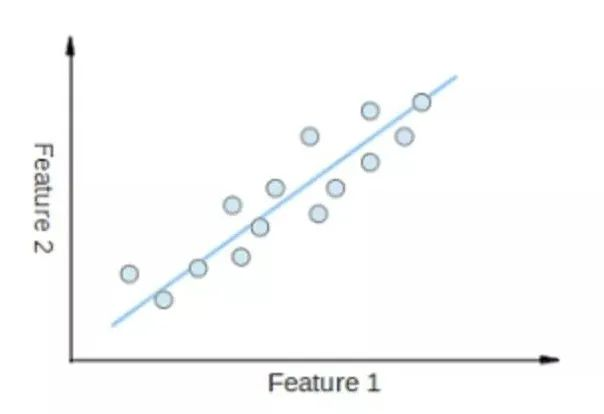
• 线性回归(Liner Regression)
o 线性回归就是找到一条直线,使用数据点来寻找最佳拟合线。它试图通过将直线方程与该数据拟合来表示自变量(x值)和数值结果(y值)。如公式,y=kx+b,y是因变量,x是自变量,利用给定的数据集求k和c的值。

• 逻辑回归(Logistic Regression)
o 逻辑回归与线性回归类似,但它用于输出二元分类情况(即,输出结果只有两个可能值),对最终输出的预测是一个非线性的S型函数。
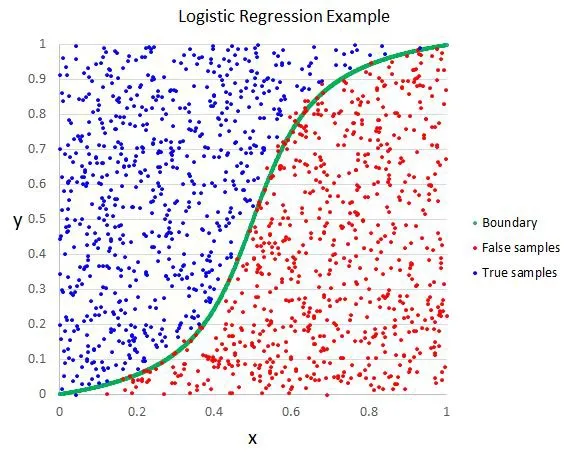
这个逻辑函数将中间结果映射到结果变量y,其值范围在0和1之间。这些值是y出现的概率。S型逻辑函数的性质让逻辑回归更适合用于分类问题。
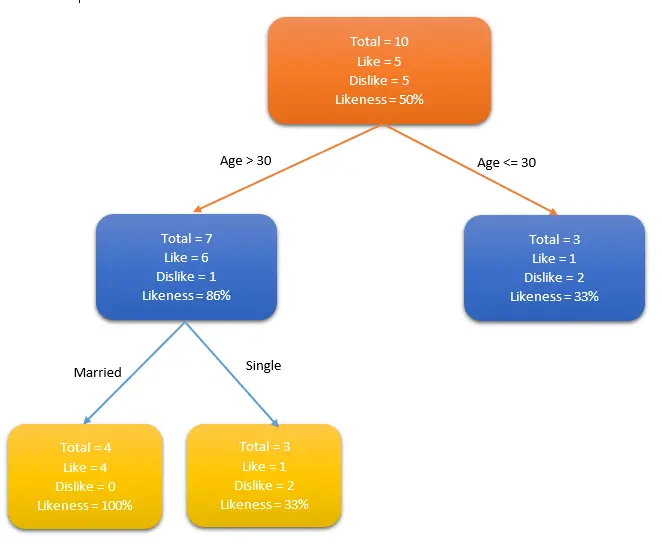
• 决策树(Decision Tree)
o 决策树用于回归和分类问题。训练模型通过学习树表示的决策规则来学习预测目标变量的值。树是具有相应属性的节点组成的。在每个节点上,根据可用的特征询问有关数据问题,左右分支表示可能的答案,最终节点(叶节点)对应一个预测值。每个特征的重要性是通过自顶而下方法确定的,节点越高,其属性越重要。如下图人群中谁喜欢使用信用卡例子中,如果一个人结婚了,他超过30岁,他们更有可能拥有信用卡(100%偏好)。测试数据用于生成决策树。
• 朴素贝叶斯(Naïve Bayes)
o 朴素贝叶斯基于贝叶斯定理。它测量每个类的概率,每个类的条件概率给出x值。这个算法用于分类问题,得到一个二进制”是/非”的结果。

• 支持向量机(Support Vector Machine/SVM)
o 支持向量机是一种用来解决二分类问题的机器学习算法,它通过在样本空间中找到一个划分超平面,将不同类别的样本分开,同时使得两个点集到此平面的最小距离最大,两个点集中的边缘点到此平面的距离最大。如下图所示,图中有黑点和白点两类样本,支持向量机的目标就是找到一条直线(H3),将黑点和白点分开,同时所有黑点和白点到这条直线(H3)的距离加起来的值最大。

• K-最近邻算法(K-Nearest Neighbors/KNN)
o KNN算法是一种基于实例的学习,或者是局部近似和将所有计算推迟到分类之后的惰性学习。用最近的邻居(k)来预测未知数据点。k值是预测精度的一个关键因素,无论是分类还是回归,衡量邻居的权重都非常有用,较近邻居的权重比较远邻居的权重大。KNN算法的缺点是对数据的局部结构非常敏感。计算量大,需要对数据进行规范化处理,使每个数据点都在相同的范围。
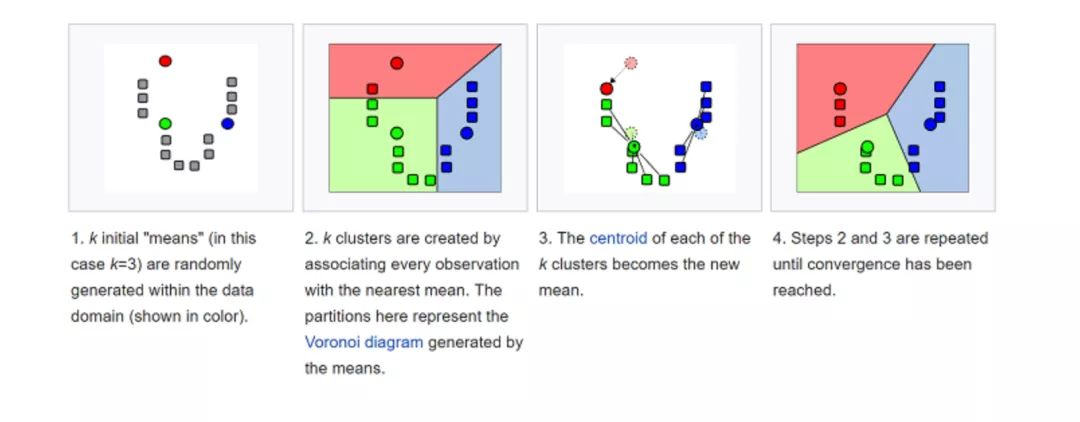
• K均值(K-Means)
o k-平均算法(K-Means)是一种无监督学习算法,为聚类问题提供了一种解决方案。K-Means算法把n个点(可以是样本的一次观察或一个实例)划分到k个集群(cluster),使得每个点都属于离他最近的均值(即聚类中心,centroid)对应的集群。重复上述过程一直持续到重心不改变。
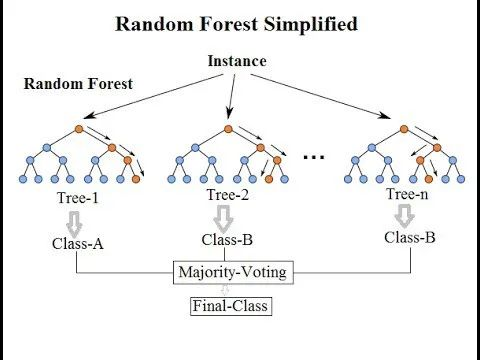
• 随机森林(Random Forest)
o 随机森林(Random Forest)是一种非常流行的集成机器学习算法。这个算法的基本思想是,许多人的意见要比个人的意见更准确。在随机森林中,我们使用决策树集成(参见决策树)。为了对新对象进行分类,我们从每个决策树中进行投票,并结合结果,然后根据多数投票做出最终决定。
• 降维(Dimensional Reduction)
o 降维是指在限定条件下,降低随机变量个数,得到一组“不相关”主变量的过程,并可进一步细分为特征选择和特征提取两大方法。
------------ END ------------
文章来自于微信公众号 “strongerHuang”




【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
