# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
几天前,库克在苹果电话会上证实,「今年晚些时候会发布生成式AI」。
ChatGPT掀起全球热潮之后,苹果也在悄悄发力AI,曾曝出的大模型框架Ajax、AppleGPT等AI工具让业界充满了期待。
6月举办的WWDC上,这家曾霸占全球市值第一公司,将会宣布各种AI能力整合到iOS 18、iPadOS 18等软件产品中。
而在此之前,你在iPhone可以抢先用上AI超能力了!
随意拍摄一张餐桌图,然后说一句「在餐桌上添加一份披萨」。披萨瞬间就出现在桌子上了。

此外,你还可以随意选一张图,可以让图片中哭脸变成笑脸、照片提亮、移除背景人物,甚至可以将绿植景色更换成海洋。
这些魔法实现,只需你动动嘴,立刻完成P图。

这项神奇的技术背后是由一个基于自然语言修改图片的新模型——MGIE加持,由UCSB和苹果全华人团队共同完成。
具体就是,通过多模态模型,去引导图像进行编辑。

论文地址:https://arxiv.org/pdf/2309.17102.pdf
从上面例子中看的出,MGIE最大的特点便是,用简短的话,就能实现出色的图像编辑能力。
目前,这篇论文已被ICLR 2024录用为spotlight,并且在今天正式开源。
所有人都可以上线试玩。

地址:http://128.111.41.13:7122/
文本引导的图像编辑,在近来的研究中逐渐得到了普及。
因其对真实图像进行建模拥有的强大能力,扩散模型也被用于图像编辑。
大模型在各种语言任务中,包括机器翻译、文本摘要和问答,展现出强大的能力。LLM通过从大规模语料库中学习,包含潜在的视觉知识和创造力,可以协助各种视觉和语言任务。
另外,多模态大模型(MLLM)可以自然地将图片作为输入,在提供视觉感知响应,以及充当多模态助手展现出强大的能力。
受MLLM的启发,研究人员将其合并以解决指令引导不足的问题,并引入MLLM引导图像编辑(MGIE)。
如图2所示,MGIE由MLLM和扩散模型组成。MLLM学习导出简洁的表达指令,并提供明确的视觉相关指导。
通过端到端训练,扩散模型会联合更新,并利用预期目标的潜在想象力执行图像编辑。

具体来说,通过给定的指令X将输入图像V,编辑为目标图像![]() 。为了处理不精确的指令,MGIE包含MLLM并学习导出明确而简洁的表达指令
。为了处理不精确的指令,MGIE包含MLLM并学习导出明确而简洁的表达指令![]() 。
。
为了桥接语言和视觉的模态,研究人员在![]() 之后添加特殊的 [IMG] token,并采用编辑头T对其进行转换。
之后添加特殊的 [IMG] token,并采用编辑头T对其进行转换。
它们将指导扩散模型F实现预期的编辑目标。然后,MGIE能够通过视觉相关感知来理解模糊命令,以进行合理的图像编辑。
这样,MGIE就能从固有的视觉推导中获益,并解决模糊的人类指令,从而实现合理的编辑。
比如,下图中在没有额外的语境情况下,很难捕捉到「健康」的含义。
而MGIE模型可以将「蔬菜配料」与披萨精确地联系起来,并按照期望进行相关编辑。

即便用蒙版遮住人脸,MGIE也能准确理解背景中的女人并移除。

照片提亮,也做的很出色。

图片中,MGIE在具体某块区域的精准编辑。

为了学习基于指令的图像编辑,研究中采用了IPr2Pr作为预训练数据集。
它包含 1M CLIP过滤数据,其中指令由GPT-3提取,图像由Prompt-to-Prompt合成。
为了进行全面评估,研究人员考虑了编辑的各个方面,包括EVR、GIER、MA5k、MagicBrush,并发现MGIE可进行Photoshop风格的修改、全局照片优化和局部对象修改。
基线
研究人员将InsPix2Pix作为基线,它建立在CLIP文本编码器上,具有用于基于指令的图像编辑的扩散模型。
另外,还考虑了类似的LLM引导图像编辑(LGIE)模型,其中采用LLaMA-7B来表达来自仅指令输入但没有视觉感知的表达指令![]() 。
。

实施细节
MLLM 和扩散模型![]() 从LLaVA-7B和 StableDiffusion-v1.5初始化,并共同更新图像编辑任务。请注意,MLLM中只有词嵌入和LM head是可训练的。
从LLaVA-7B和 StableDiffusion-v1.5初始化,并共同更新图像编辑任务。请注意,MLLM中只有词嵌入和LM head是可训练的。
按照GILL的方法,研究人员使用N =8个视觉token。编辑头T是一个4层的Transformer,它将语言特征转化为编辑指导。我们采用批大小为128的AdamW来优化 MGIE。
MLLM和![]() 的学习率分别为5e-4和1e-4。所有实验均在PyTorch中在8个A100 GPU上进行。
的学习率分别为5e-4和1e-4。所有实验均在PyTorch中在8个A100 GPU上进行。
定量结果
表一显示了零样本编辑结果,其中模型仅在IPr2Pr上进行训练。
对于涉及Photoshop风格修改的EVR和GIER,表达性指令可以揭示具体目标,而简短但模糊的命令去无法让编辑更接近意图。
对于MA5k上的全局照片优化,由于相关训练三元组的稀缺,InsPix2Pix很难处理。
LGIE和MGIE虽然是同一来源的训练,但可以通过LLM的学习提供详细的解释,但LGIE仍然局限于其单一的模式。
通过访问图像,MGIE可以得出明确的指令,例如哪些区域应该变亮,或哪些对象更加清晰。
它可以带来显著的性能提升,另外在MagicBrush也发现了类似的结果。MGIE也在精确的视觉上获得了最佳的表现。

为了研究针对特定目的的基于指令的图像编辑,表2对每个数据集上的模型进行了微调。
对于EVR和GIER,所有模型在适应Photoshop风格的编辑任务后都获得了改进。由于微调也使表达指令更加针对特定领域,因此MGIE通过学习领域相关指导来增加最多。
从上面的实验中,说明了使用表达指令进行学习,可以有效地增强图像编辑,而视觉感知在获得最大增强的明确指导方面起着至关重要的作用。

消融研究
MLLM引导图像编辑在零样本和微调场景中,都表现出了巨大的改进。
现在,团队还研究了不同的架构来使用表达指令。
表3中,研究人员将FZ、FT和E2E架构进行了对比,结果表明,图像编辑可以从LLM/MLLM指令推导过程中的明确指导中受益。
E2E与LM一起更新编辑扩散模型,LM学习通过端到端的隐藏状态,同时提取适用的指导,并丢弃不相关的叙述。
此外,E2E还可以避免表达指令可能传播的潜在错误。
因此,研究人员观察到全局优化(MA5k)和本地编辑(MagicBrush)方面的增强最多。在FZ、FT、E2E中,MGIE持续超过LGIE。这表明具有关键视觉感知的表达指令,在所有消融设置中始终具有优势。

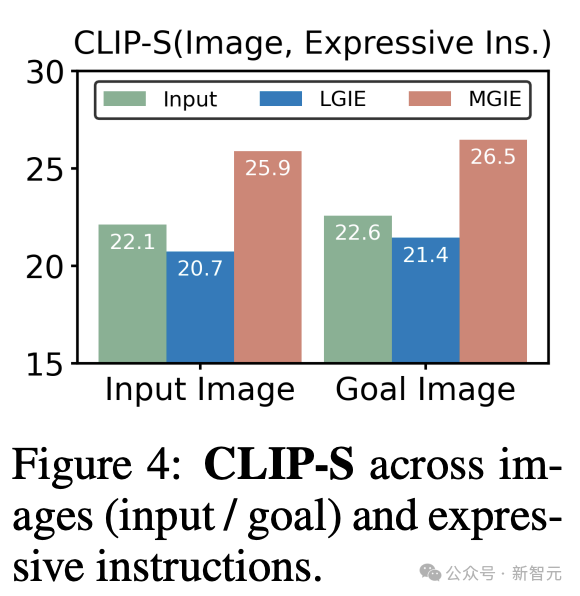
为什么MLLM的指导有很大帮助?
图4显示了输入或真实目标图像与表达指令之间的CLIP-Score值。
输入图像的CLIP-S分数越高,说明指令与编辑源相关。更好地与目标图像保持一致可提供明确、相关的编辑指导。
由于无法获得视觉感知,LGIE的表达式指令仅限于一般语言想象,无法针对源图像量身定制。CLIP-S甚至低于原始指令。
相比之下,MGIE更符合输入/目标,这也解释了为什么表达性指令很有帮助。有了对预期结果的清晰叙述,MGIE可以在图像编辑方面取得最大的改进。
人工评估
除了自动评估指标外,研究还进行了人工评估,以研究生成的表达指令和图像编辑结果。
研究人员具体为每个数据集随机采样25个示例(共100个),并考虑由人类对基线和MGIE进行排名。
为避免潜在的排名偏差,研究人员为每个示例聘请了3名标注者。
图5显示了生成的表达性指令的质量。
首先,超过53%的人支持MGIE提供更实用的表达式指导,这有助于在明确的指导下完成图像编辑任务。
同时,有57%的标注者表示,MGIE可以避免LGIE中由语言衍生的幻觉所产生的不相关描述,因为它认为图像有一个精确的编辑目标。

图6比较了InsPix2Pix、LGIE和MGIE在指令遵循、地面真值相关性和整体质量方面的图像编辑结果。排名分数从1-3不等,越高越好。
利用从LLM或MLLM派生的表达式指令,LGIE和MGIE的表现均优于基线,其执行的图像编辑与指令相关,并与地面真值目标相似。
此外,由于研究中的表达式指令可以提供具体的视觉感知指导,因此MGIE在包括整体编辑质量在内的各个方面都具有较高的人类偏好。这些性能趋势也与自动评估结果一致。

推理效率
尽管依靠MLLM来促进图像编辑,MGIE仅给出了简洁的表达指令(少于32个token)并包含与InsPix2Pix一样的可行效率。
表4显示了NVIDIA A100 GPU上的推理时间成本。
对于单次输入,MGIE可以在10秒内完成编辑任务。随着数据并行化程度的提高,我们花费了相似的时间(例如,当批大小为8时,需要37秒)。
整个过程只需一个GPU(40GB)就可以负担得起。
总之,MGIE超越了质量基准,同时保持了有竞争力的效率,从而实现了有效且实用的图像编辑。

定性比较
图7展示了所有使用的数据集的可视化比较。

图8进一步比较了LGIE或MGIE的表达指令。

总之,在最新研究中,UCSB和苹果团队提出了MLLM引导图像编辑(MGIE),通过学习生成表达指令来增强基于指令的图像编辑。
参考资料:
https://github.com/apple/ml-mgie
文章来自于微信公众号“新智元”



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
