# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
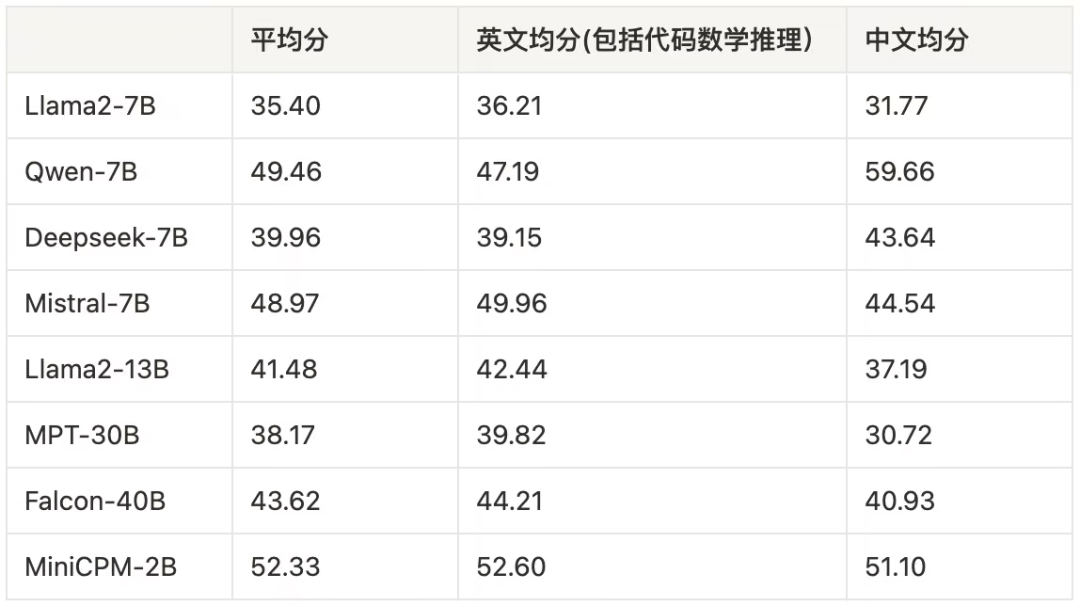
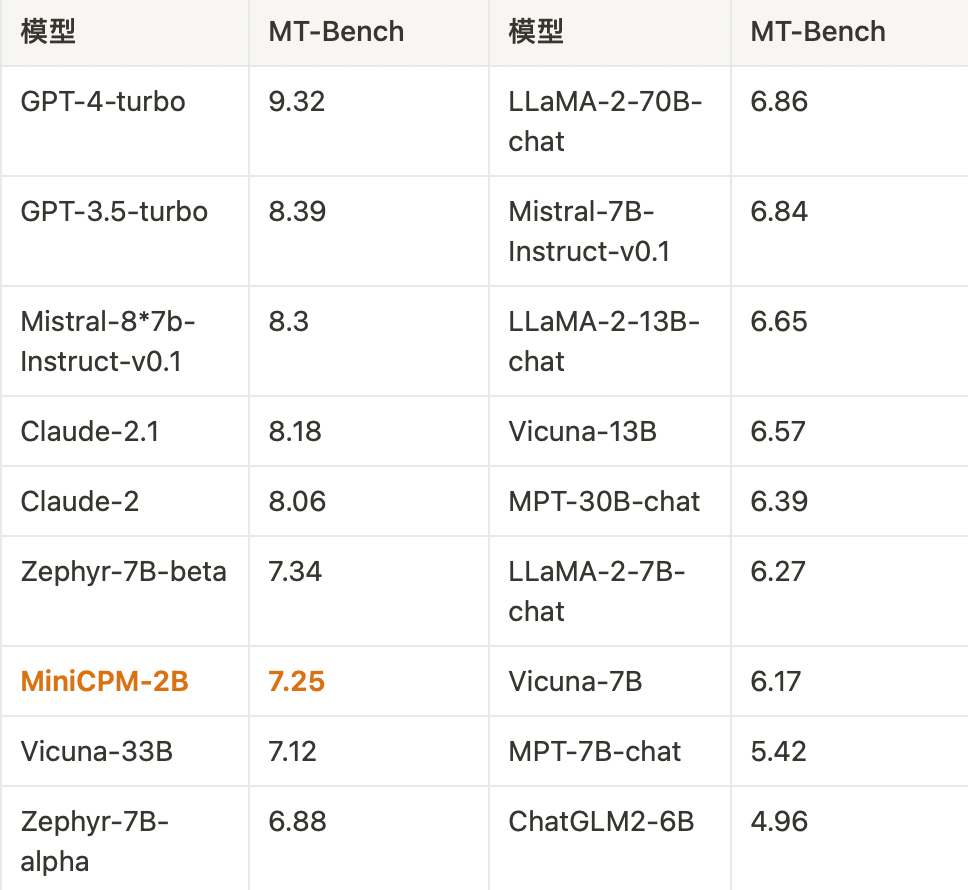
MiniCPM 是一系列端侧语言大模型,主体语言模型 MiniCPM-2B 具有 2.4B 的非词嵌入参数量。在综合性榜单上与 Mistral-7B 相近(中文、数学、代码能力更优),整体性能超越 Llama2-13B、MPT-30B、Falcon-40B 等模型。在当前最接近用户体感的榜单 MTBench 上,MiniCPM-2B 也超越了 Llama2-70B-Chat、Vicuna-33B、Mistral-7B-Instruct-v0.1、Zephyr-7B-alpha 等众多代表性开源大模型。
我们将完全开源 MiniCPM-2B 的模型参数供学术研究和有限商用,以及训练过程中的所有 Checkpoint 和大部分非专有数据给模型机理研究。
具体而言,我们已开源以下模型:
模型整体性能:
局限性:
大模型的实验成本高昂,难以在不进行配置调优的情况下得到最优秀的大模型性能。
借鉴 μΡ 等优秀的前人工作,我们提出在小模型上进行广泛的实验,通过可迁移的配置,获得大模型的最优训练方法。MiniCPM 本身,即为模型沙盒实验的成果。
我们进行了 Hyper-paramters、Batch size、Learning Rate、Learning Rate Scheduler、Data Strategy 五个方面的模型沙盒研究。
1. 超参稳定的模型规模扩增
超参数对模型的性能具有重大影响,在传统训练方法中,需要对每个模型进行超参数调整,这对于大模型并不现实。借鉴 μP 的方法,我们对模型的各参数模块之间进行了连接权重的调整、以及对模型初始化的调整。部分调整接近 Cerebras-GPT。
整体方案如下:

上述操作的具体参数由近 400 次在 0.009B 模型规模上的贝叶斯参数搜索得到。
2. 最优 Batchsize
Batchsize 决定了模型的收敛速度和消耗计算资源的平衡。Batchsize 过大,达到一定的损失消耗的数据量和计算量都会很大,而 batchsize 过小,则需要消耗过多的训练步数,且有可能损失函数下降有限。在 2020 年 OpenAI 的开山之作中,OpenAI 研究了损失函数随 token 数变化的规律。在他们的实验中,他们将认为消耗更多的步数等价于消耗更多的时间,在这种假设下,OpenAI 定义了临界 Batchsize(Critical Batchsize),使得达到一定的损失,既不消耗过多 step,也不消耗过多 token。然而我们观察到在利用当前以 A100 为主的计算资源,结合 gradient checkpointing 策略进行训练时,通常计算速度(而不是显存)是瓶颈,这意味着在相同机器数量下,多一倍 Batchsize 几乎等同于慢一倍的单步时间。基于这个观察,我们取消了对“不消耗过多 step ”的追求,而转向追求用最少的token量达到最低的 loss。
我们在 0.009B,0.036B,0.17B 的模型上分别进行了 6 个 batchsize 的训练实验,将结果记录如图下。
我们观察到了最优 batchsize 随着 C4 数据集上的 loss 的偏移规律(图中的红线)。将这三个图的红线进行连接,并进行拟合,我们得到了如下 Batchsize 关于C4 Loss 的规律:
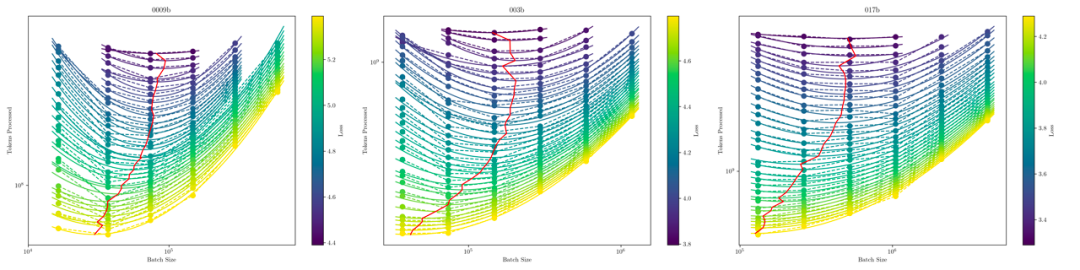
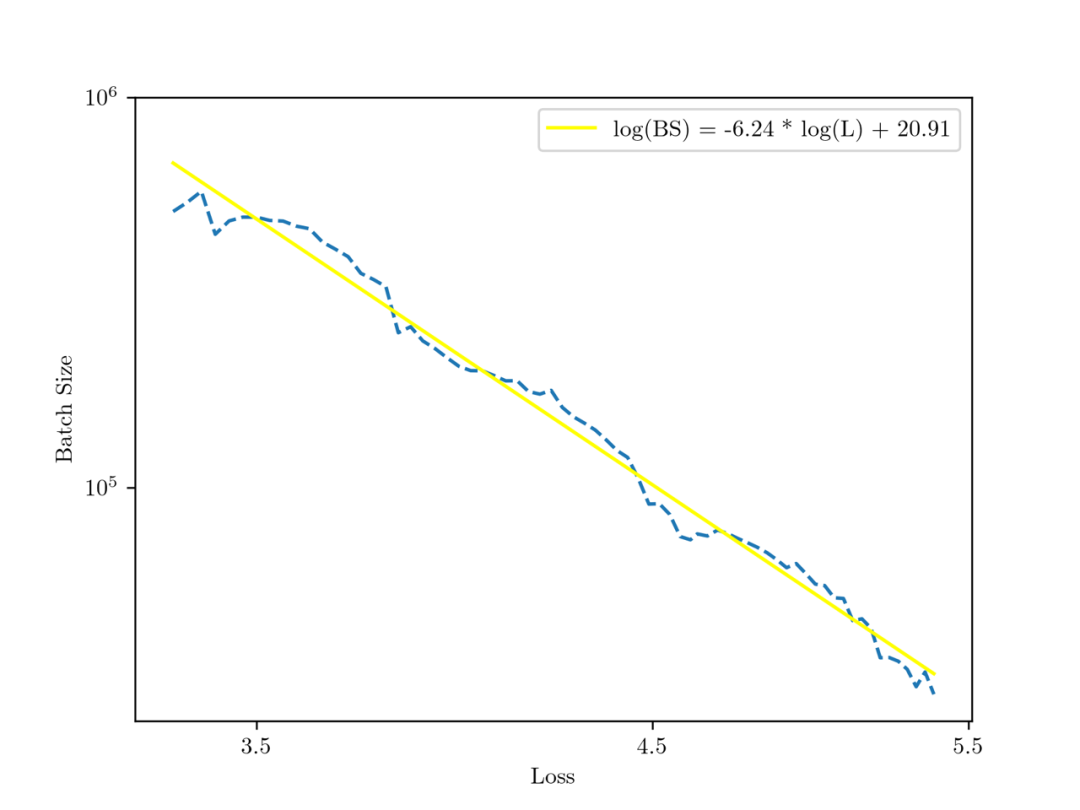
连接上述的红线(log scale 之后)并拟合
将这三个图的红线进行连接,并进行拟合,我们得到了如下 Batchsize 关于 C4 Loss 的规律:
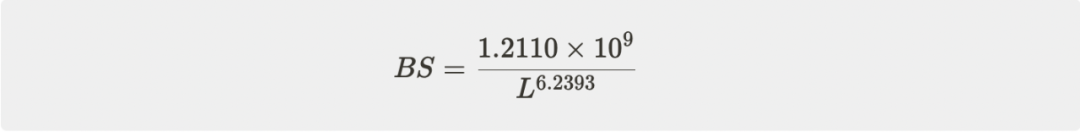
根据这个规律,我们预估了 2B 模型达到 C4 损失 2.5 左右,4M 是比较合适的 Batchsize。
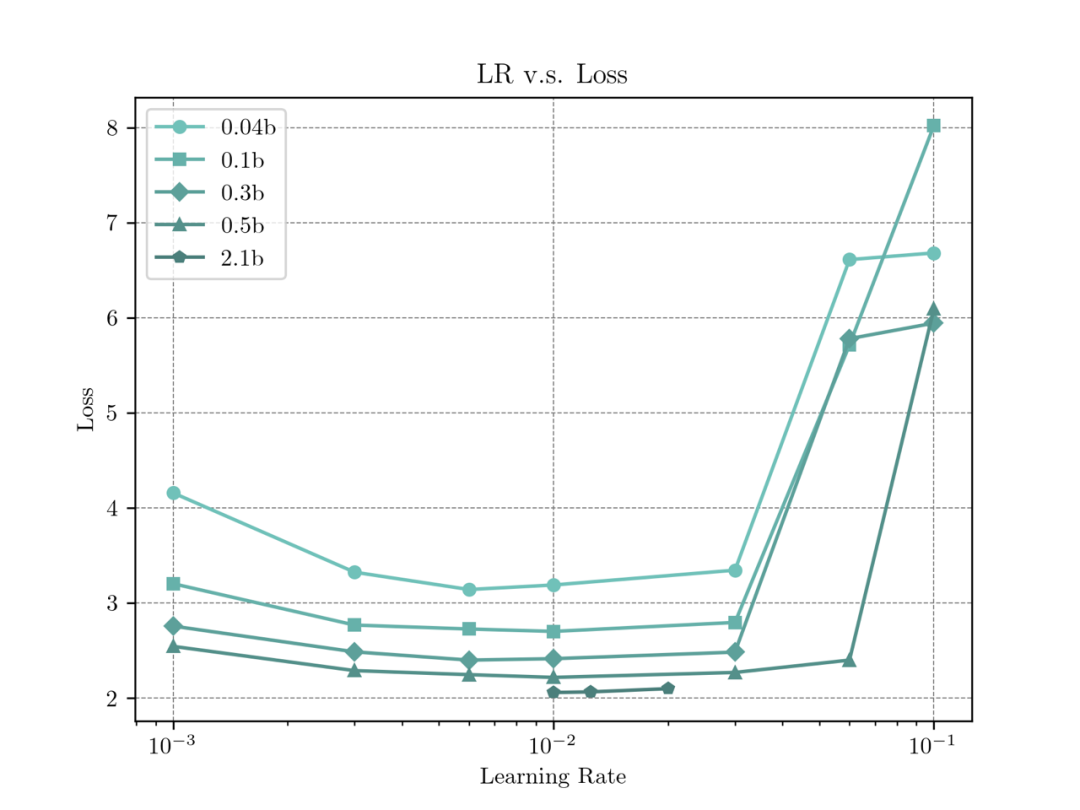
3. 最优学习率
由于我们使用了超参稳定的参数化方案,我们预期模型的最关键超参数:学习率,不会因为模型规模扩大有大幅度的改变,因此我们在 0.04B, 0.1B, 0.3B, 0.5B 上分别做了 6 组学习率实验,我们发现虽然模型大小扩大了 10 倍,但是最优学习率偏移并不明显,均在 0.01 左右,我们在 2.1B 的规模上进行了简单验证,发现在 0.01 的学习率确实能取得最低的 Loss。
学习率调度器,即训练不同阶段使用不同学习率的调整策略,对模型性能影响很关键。当前通用的学习率策略是 Cosine 图像,即在学习率从 Warmup 阶段升高到最高点之后,开始呈现余弦函数的降低。几乎所有大模型都使用了 Cosine Learning Rate Scheduler (简称 Cosine LRS )的方式。
为了研究为什么 Cosine 的 Scheduler 表现优异,我们进行了大量实验。我们对0.036B 的模型,设置不同的 Learning Rate Scheduler 的截止步数 Τ,进行了持续训练。结果如下图:
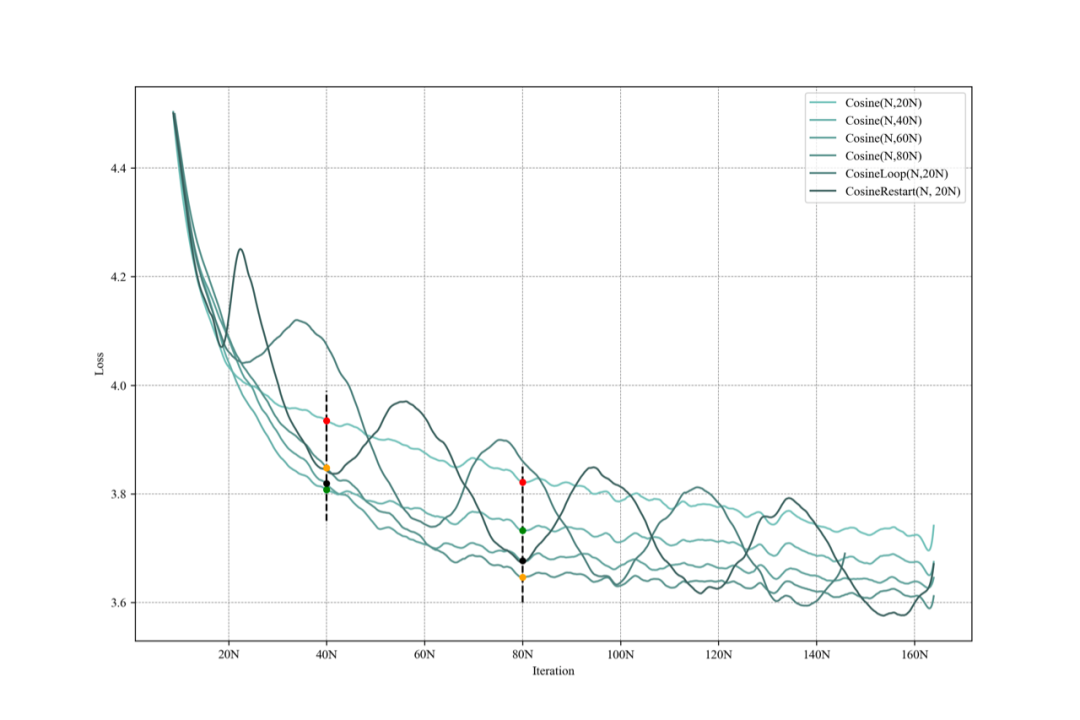
从图中可以看出,对于训练至 S 步的模型,将 Cosine LRS 的截止步数 Τ设置为 S步总是能获得最优的性能,而设置为更多或者更少性能都不是最优。
当我们考虑持续训练的场景,会发现 Cosine 调度器的问题有更多问题。如果我们在 Cosine 的截止步数之后继续沿用 0.1 倍的最大学习率(通常做法),则继续训练收敛非常缓慢;如果我们在 Cosine 的截止步数之后重启 Cosine LRS(即再次从最大学习率开始下降,或者是逐渐上升到最大学习率,再开始下降)则会发现损失会经历长时间的上升周期,而这段时间,模型处于不可用状态。
我们猜想 Cosine LRS 在预先指定步数的时候性能优异的原因有两点:
结合这两点,我们提出了一种新的学习率调度策略,Warmup-Stable-Decay(WSD)调度器。这种学习率调度器分为三个阶段,warmup 阶段(用 W 表示warmup 阶段结束时的步数/训练量),稳定训练阶段(用 S 表示稳定训练阶段结束时的步数/训练量),退火阶段(用 D 表示退火阶段的训练量)。这种调度器可以写为:
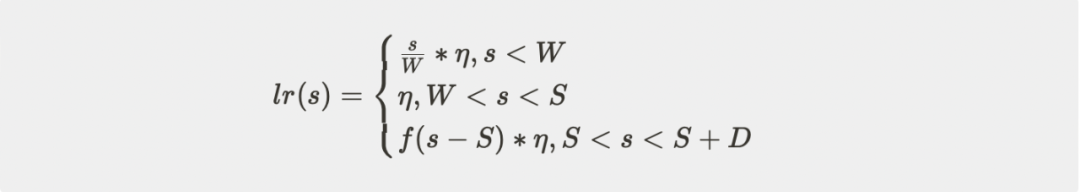
其中 0<ƒ(s-S)≤1 是一个关于 s 的减函数,η是最大学习率。这种策略有以下四个好处:
WSD 和 Cosine LRS 的图像对比如下:
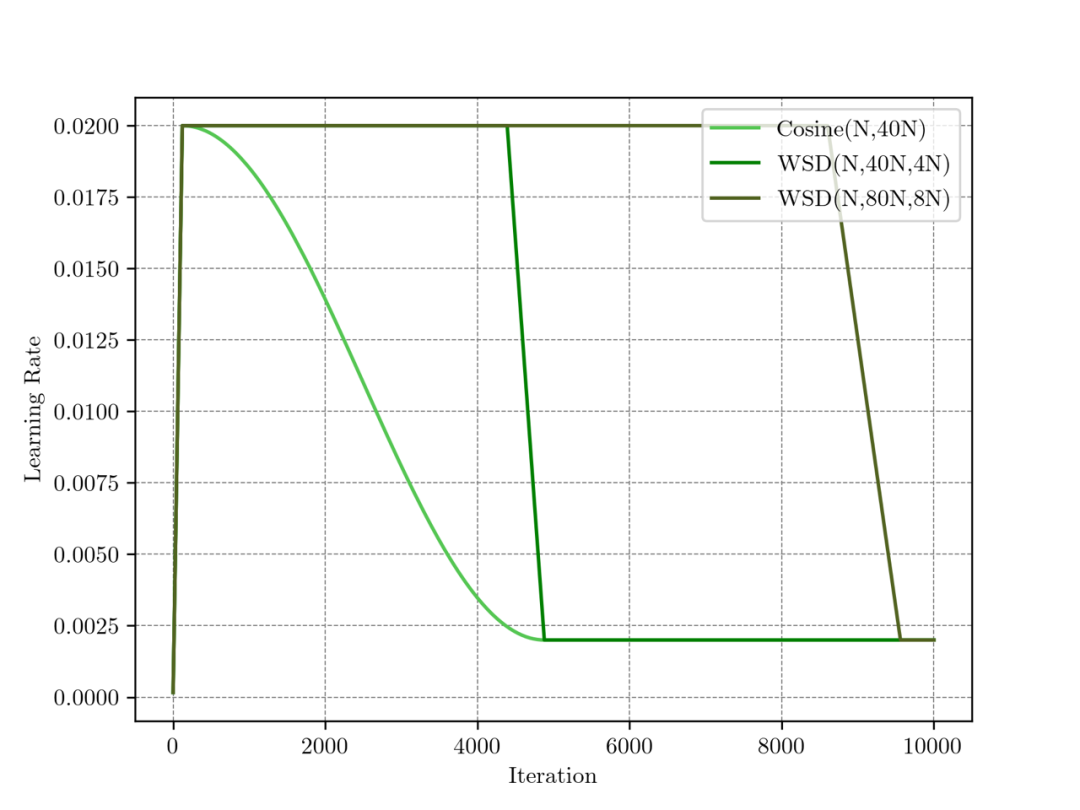
图中显示了 CosineWSD(W, S, D) 学习率调度器和 Cosine 的对比。可以看到,在 Cosine 调度器结束之后需要持续保持最低学习率,以保证 loss 不上升,而 WSD 调度器则可以从退火之前开始继续用最大学习率训练,经过更长的训练再开始退火。
我们发现如我们所设想的,在 Decay 阶段(退火阶段),随着学习率的变小,损失有大幅度的快速下降,在步数S时迅速降低至和 T=S 的 Cosine LRS 相等或更低。与此同时,我们可以复用Decay前的模型,进行大学习率的继续训练,在更多的步数 S’ 之后进行退火,取得和 T’=S’ 的 Cosine LRS 相等的效果。
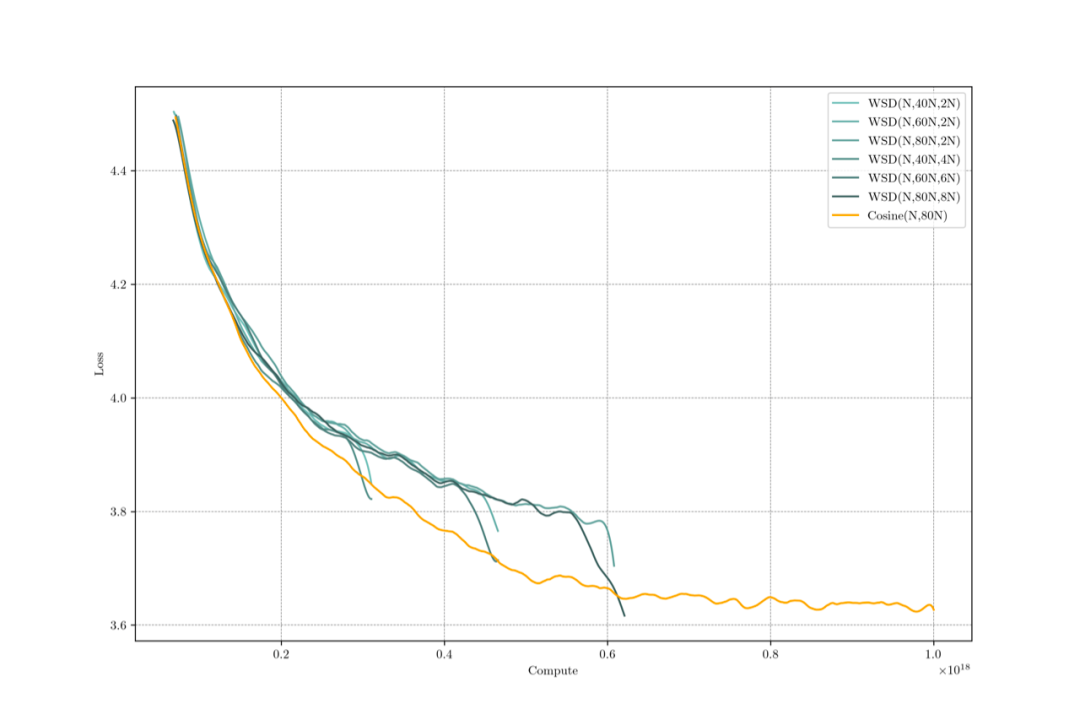
图中最下方的橙色线为 Cosine LRS,上方绿色线为 WSD LRS。尽管 WSD LRS 在学习率恒定的 stable 阶段表现差于 Cosine,但是在最后的退火阶段,会形成快速下降的趋势,最终达到或者超越 Cosine LRS。我们尝试了不同的退火步长,例如 WSD(N, 80N, 2N) 的退火比例为 2/80 = 2.5%, 而WSD(N, 80,N, 8N) 的比例为 8/80 = 10%。我们发现在我们测试的 4 个训练阶段(20N,40N, 60N,80N),2.5% 的退火长度都不够达到最优的性能。而 10% 的退火长度则足够达到甚至超越Cosine LRS。
我们对 Decay 阶段的训练步数需求进行了探索。我们发现在所有训练时长中,总步数 10% 的 Decay 都足够达到最好的效果,而 2.5% 的 Decay 都较为欠缺。因此我们最终将 Decay 的步数定为最后10%。
5. Batchsize 调度
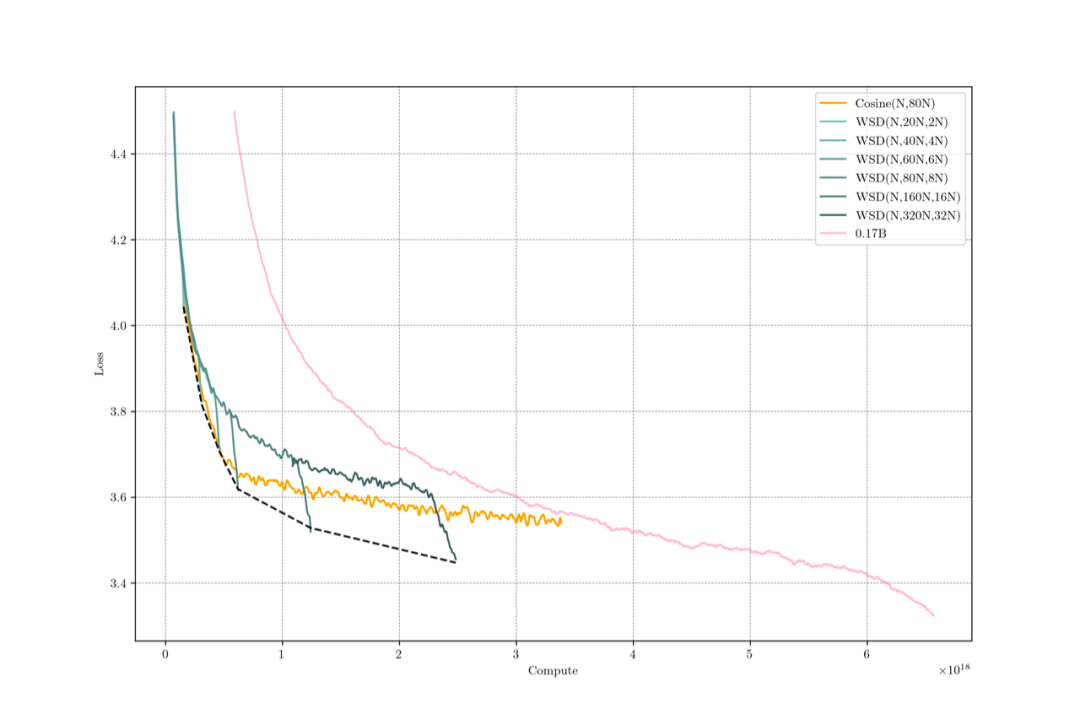
根据 Batchsize 随损失变化的实验结果,不难猜想,用更大的 Batchsize 可能可以达到更低的 loss。我们在 0.036B、2.4B 的模型实验中都发现了类似的现象,即在扩大Batchsize 的时候损失会有一次较大幅度的下降(我们猜想 Batchsize 扩大和Learning Rate 降低可能有相似的动力学效果)。如下图所示,我们进行了 Batch size 扩大,Loss 降低约0.2,并且在后续的退火阶段,仍然能形成一样的下降效果。但是遗憾的是,在我们正式实验中,我们进行的 Batchsize 扩大后退火阶段的降低有所减少,因此我们最终没有采用 Batchsize 扩大的训练方法。这个问题留作后续研究。
0.036B 的模型在 Batchsize 扩大以后 loss 有降低
6. 固定大小模型持续训练最多可以达到几倍的大模型?
由于我们的 WSD 学习率优化器可以在任何阶段退火,取得该阶段最优的模型,因此我们有机会探索,如果持续训练一个大小为 N 的模型,最优情况下能超过多大参数量的 Chinchilla-Optimal 模型。
首先我们估计了持续训练过程中,模型性能随着规模的变化。由于不确定函数形式,我们尝试了两种拟合公式。
指数形式: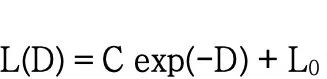
幂律形式:![]()
两种函数的拟合结果如图:
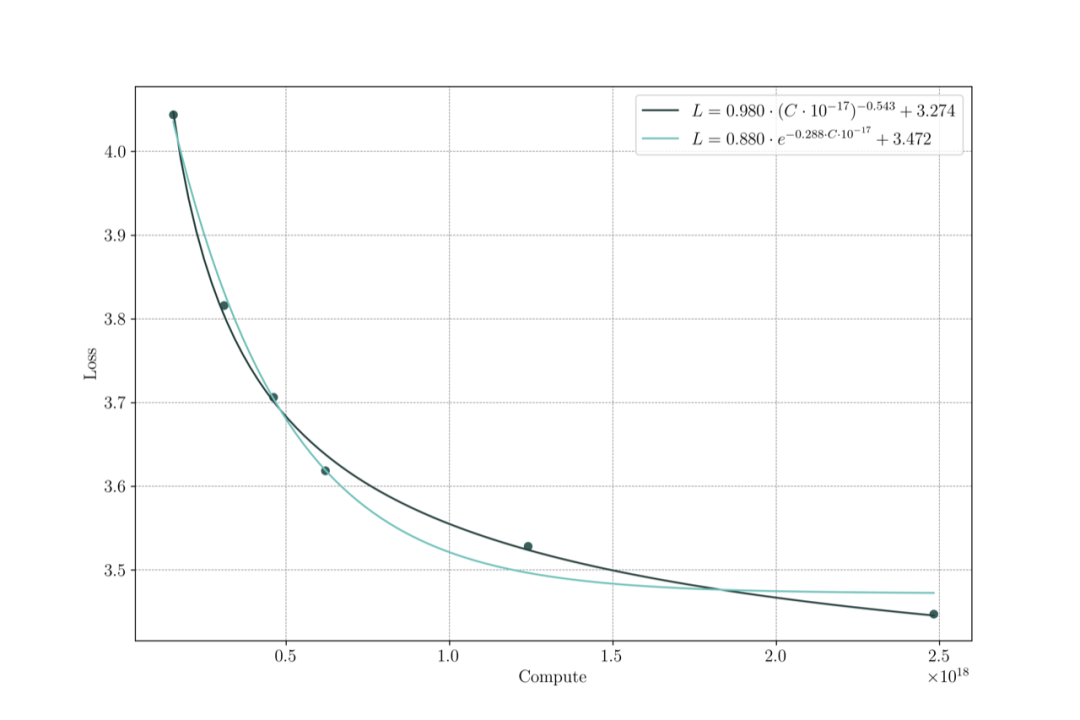
因此我们认为幂律形式的拟合效果更好。通过拟合我们得到 0.036B 持续训练,最终理论上可以达到 3.27 的 C4 Loss。为了从直观上估计和感受,在可接受的训练时长内,0.036B 得模型可以达到多大的 Chinchilla Optimal 模型的效果,我们同样以最优配置训练了一个 0.17B 的模型。0.17B 模型在 Chinchilla Optimal 数据量下训练,消耗的计算量为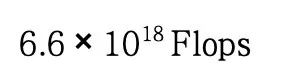 。
。
在这个计算量下,0.036B 的模型可以获得 3.37 的 C4 Loss,与 0.17B 的模型的 3.34 Loss 接近。因此我们认为一个模型用我们的 WSD 调度器训练,在消耗等量计算量时,可以达到约 5 倍模型参数量的 Chinchilla-optimal 模型。而持续训练下去,有可能超越更大的 Chinchilla-optimal 模型。
我们在 MiniCPM 上进行了验证。我们以完全相同的数据配方训练了 0.036B、0.1B、0.2B、0.5B、0.8B,1.2B 六个小模型,分别至其 Chinchilla Optimal 的数据量。绘制得到 Scaling 图像如下,根据这个图像,我们可以预测 9B 模型的 Chinchilla Optimal 的终态 C4 Loss 约为 2.40,7B 模型约为 2.45。MiniCPM 的最终C4 Loss 为 2.41,接近于 9B 的 Chinchilla Optimal 模型。
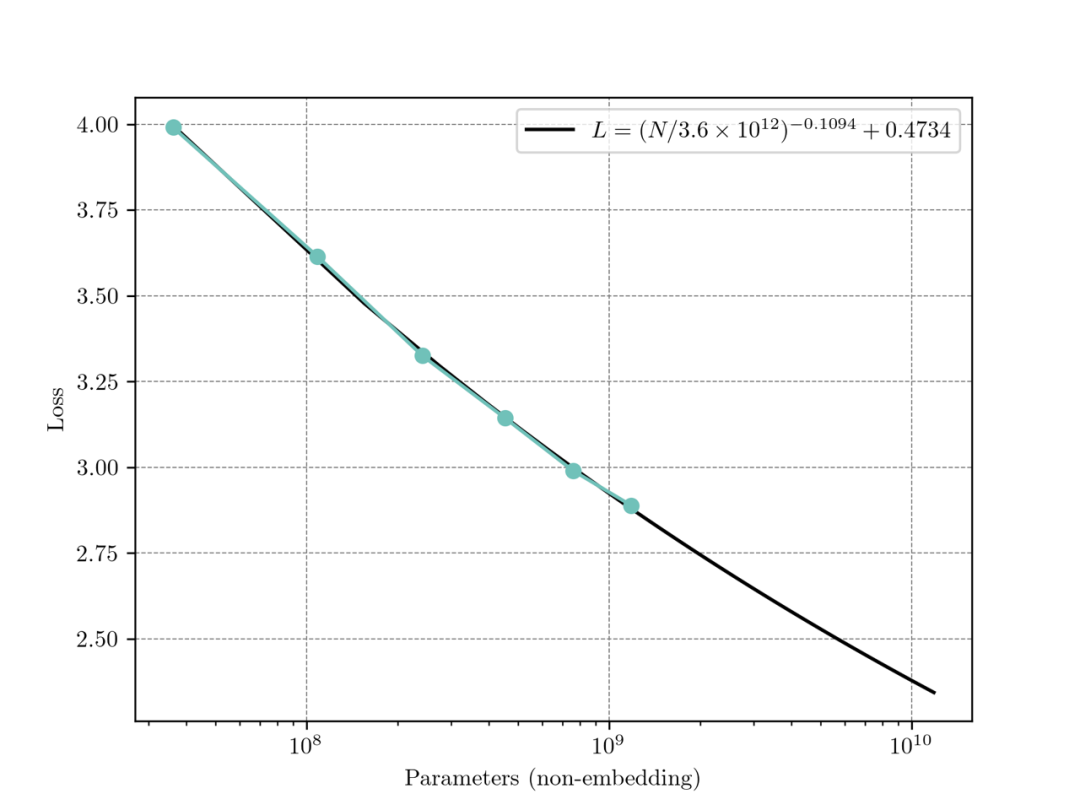
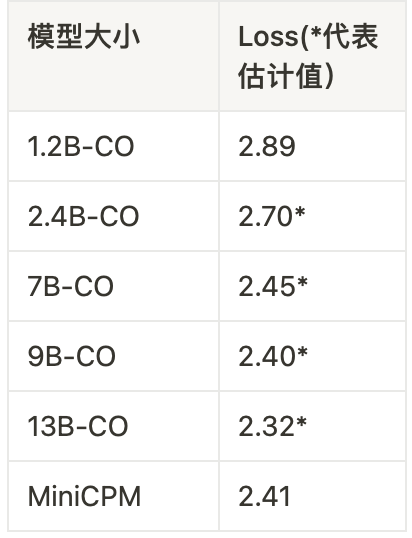
-CO意为Chinchilla Optima
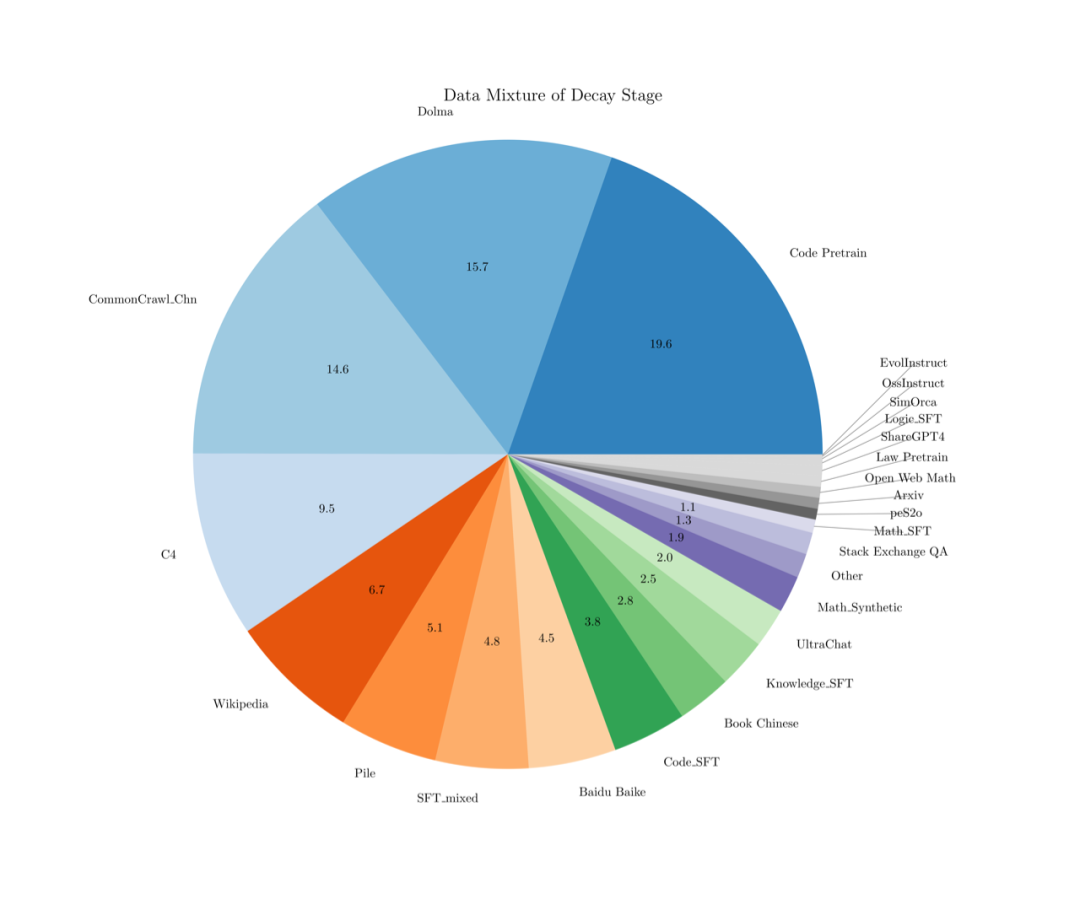
7. 持续训练友好的数据策略
由于 WSD LRS 的退火阶段模型会有较大幅度的损失下降,我们猜想在这个阶段加入高质量数据,会有如下两个优点:
基于这两点猜想,我们提出:在预训练阶段只使用通用、量大的预训练粗质量数据,而在退火阶段,使用非常广泛的高质量知识和能力数据以及 SFT 的高质量数据,混合入预训练数据进行退火。
为了验证我们的方法与直接SFT相比的优势,我们从一个中间检查点开始进行了两组实验。
实验 A:仅使用预训练数据进行退火,接着进行 4B token 的 SFT。
实验 B:使用如上的高质量数据+SFT数据混入预训练数据进行退火,同样进行 4B token 的 SFT。
两组实验结果如下:

实验结果表明在退火开始时加入高质量数据的收益远高于在退火完成后的sft阶段加入。因此我们建议模型能力的特化和增强应从退火阶段开始进行。
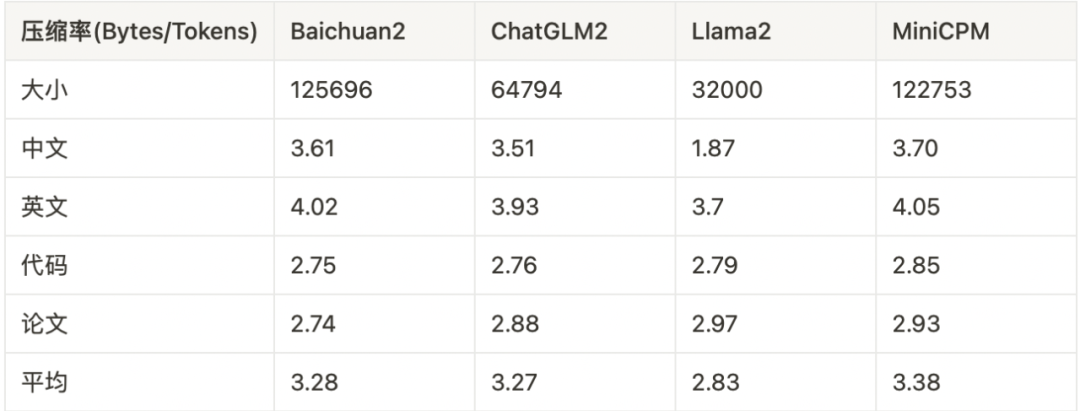
MiniCPM 模型作为通用模型,具备英文、中文、中国古文、代码、颜文字,其他语言等多方面能力,因此词表相对较大,大小为 122753。该词表构建于大量综合语料上,使用 sentencepiece 库进行 BPE,添加了包括繁体中文、罕见字、emoji、希腊字母、俄文字母等等特殊符号。
我们在中文、英文、代码、论文各 30 万篇非训练文档上进行了压缩率测量,MiniCPM的tokenizer取得了最高的压缩率(Bytes/Tokens)
共享输入输出层
词表的大小主要决定了模型覆盖面的宽窄,而不决定模型本身的能力深浅。在大模型参数规模下,词嵌入参数量可以忽略不计,但是小模型下却不可忽视,因此我们使用了 tie_word_embedding 的方案进一步减少参数量,即输出层和输入层共享参数,在预实验中,我们发现这几乎不会牺牲性能。在使用 tie_word_embedding后,MiniCPM 的词嵌入为 2304\times 122753\sim0.28B 的参数量
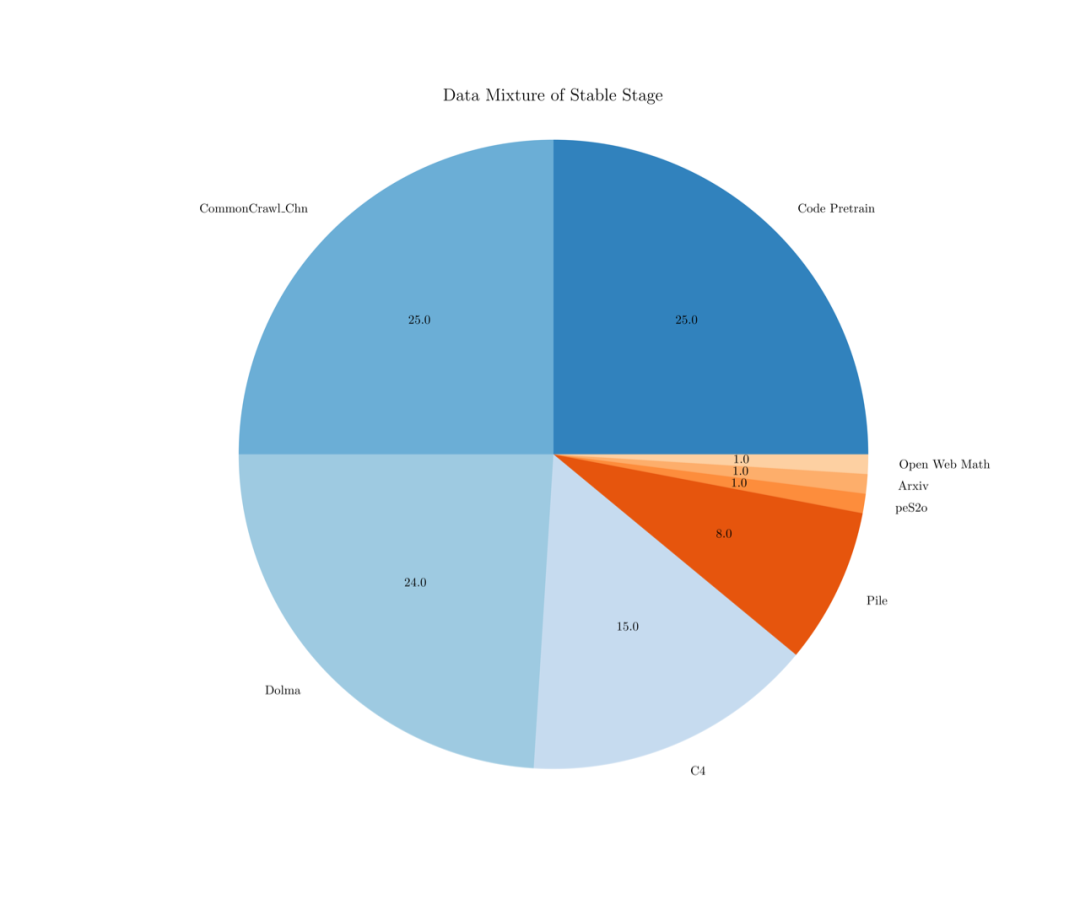
1. 稳定训练阶段
我们使用了 1T 的去重后的数据,其中大部分数据从开源数据中收集来,比例如下图。
我们使用了模型沙盒实验中探索出的最优配置,WSD LRS,batchsize 为 3.93M,Max Learning Rate 为 0.01。
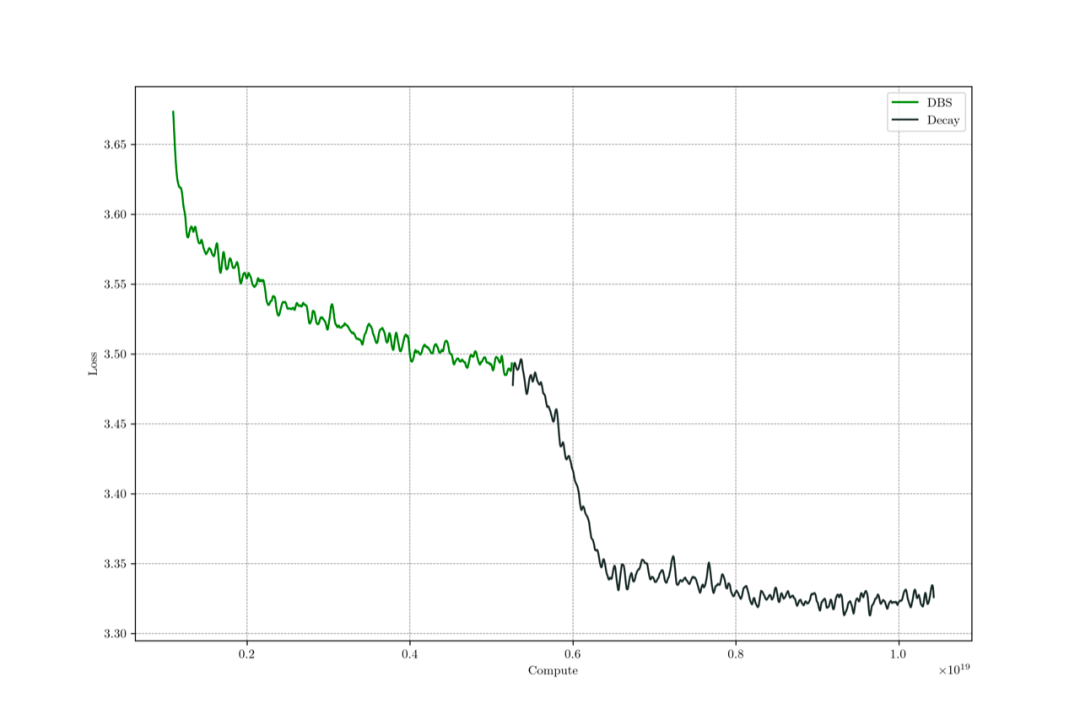
最终我们两阶段预训练的过程中,C4 Loss 的变化如下图,在 263000 步(约 1T 数据)时,开始进行退火,退火过程也变现出了损失函数急剧下降的现象,同时在各种任务数据、SFT 数据上的 Loss 也有显著下降。
具体在 WSD 调度器的退火形式上,我们采用了指数退火,
即: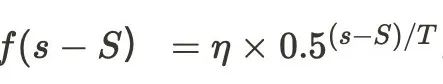
其中T为退火的半衰期,我们设置为T=8000步。
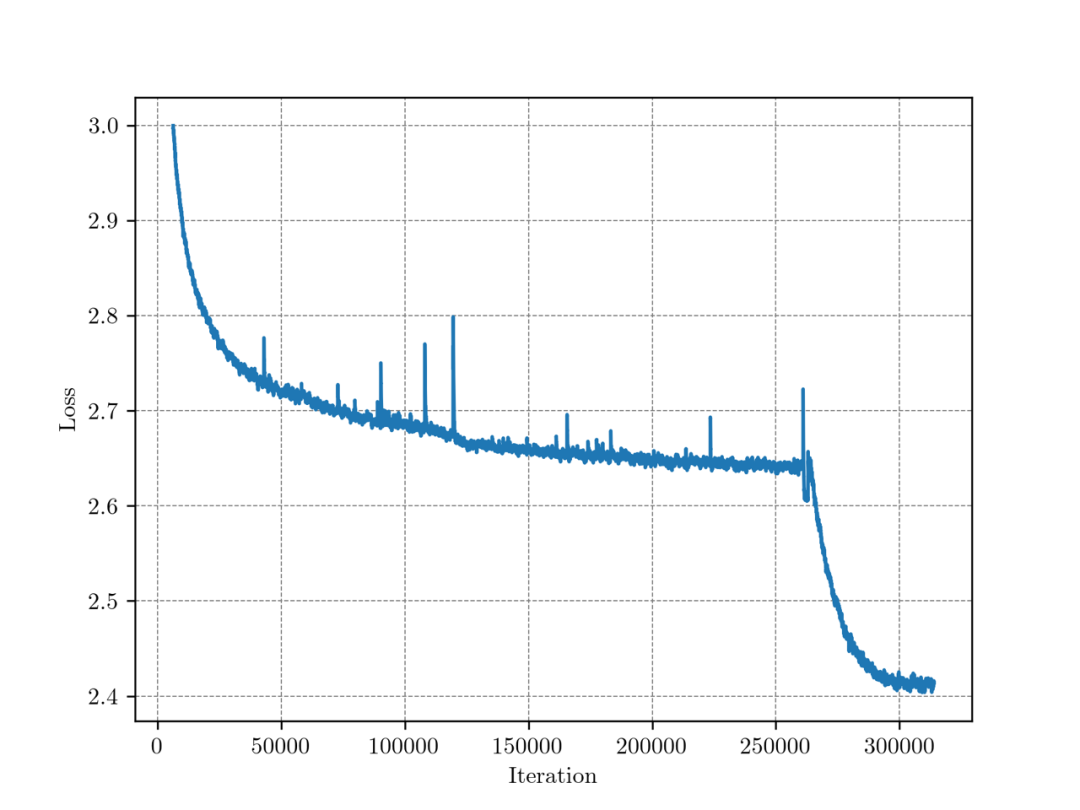
整个训练过程中,C4 训练集上 Loss,由于数据不重复,所以训练集 loss 可以当作验证集 Loss。
在上述获得的基础模型之上,我们进行了对齐(alignment)。尽管 sft 的数据已经加入退火阶段,但是我们发现仍然有必要进行 SFT 阶段,换言之,退火阶段和 SFT 阶段缺一不可。我们使用了和退火阶段类似的SFT 数据(不同的是将预训练数据去除)。我们进行了约 6B token 的 SFT 训练。SFT 的学习率衔接上退火结束的学习率,为 1e-3,同样使用了 WSD Scheduler。
在 SFT 之后,我们采用 DPO 对模型进行进一步的人类偏好对齐。在这一阶段,我们采用 UltraFeedback 作为主要的对齐数据集,并内部构建了一个用于增强模型代码和数学能力的偏好数据集。我们进行了一个 Epoch 的 DPO 训练,学习率为 1e-5且使用 Cosine Scheduler。更多 DPO 和数据设置细节可以可见我们 UltraFeedback 论文。
1. 榜单
SFT 模型: MiniCPM-sft
整体评测使用了我们的开源工具 UltraEval。UltraEval 是一个开源的基础模型能力评测框架,提供了一套轻量级、易于使用的评测体系,支持主流大模型的性能评估,服务模型训练团队的快速评测需求。底层使用开源框架 vLLM 进行推理和加速,数据集选取了常用的权威数据集,包括:
由于大模型评测比较难以统一,且大量评测也没有公开的 prompt 和测试代码,对于具体评测方式,我们只能尽量做到适合各类模型。整体而言,我们测试时采用统一的输入 prompt,并会按照各自模型适合的模板进行调整。模型评测脚本及prompt 已开源在我们的 Github 仓库中,也欢迎更多开发者来不断改进我们的评测方式。
整体评测结果如下。总体而言,MiniCPM 在上述数据集上,英文均分与 Mistral-7B-v0.1 相近,中文均分显著优于 Mistral-7B-v0.1。
以下是具体评测结果:
与大模型相比:超过或持平大部分 7B 规模模型,超越部分 10B 以上的模型。
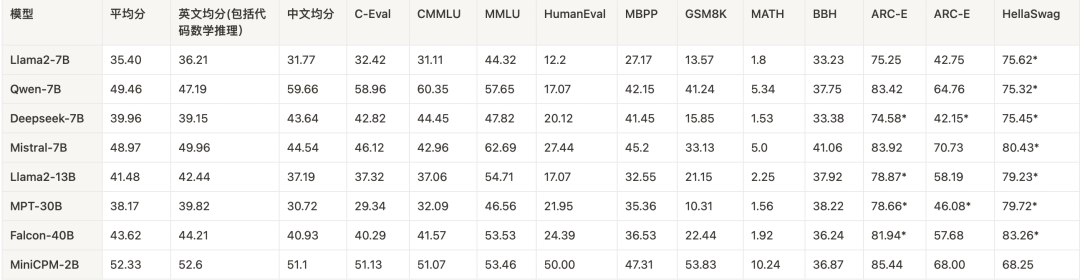
与小模型对比,除部分英文评测集外,其他测试集均超过现有模型。
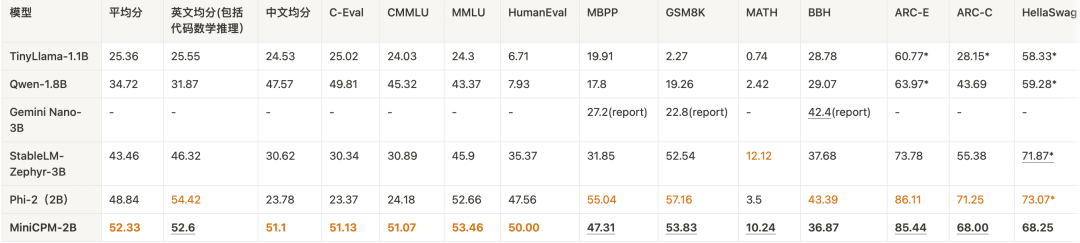
与Chat模型比较。
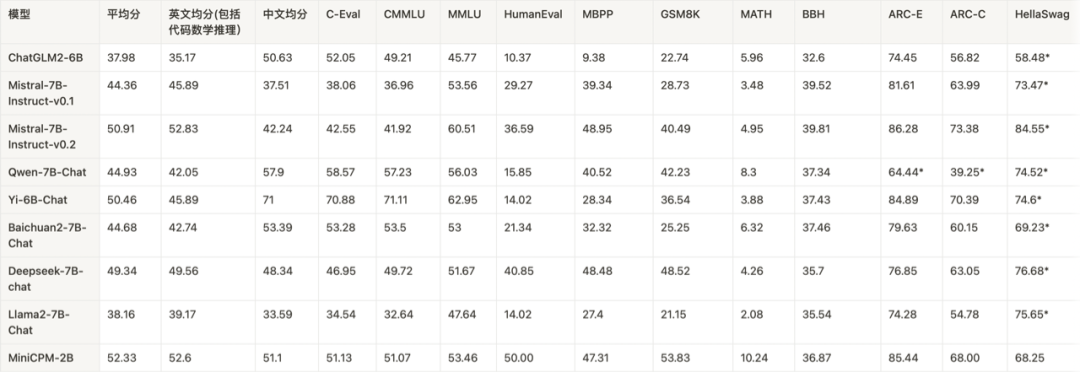
注:
DPO 模型:MiniCPM-dpo
在使用 DPO 完成偏好对齐后,模型在 MT-Bench 上的分数从 SFT 后的 6.89 上涨至7.25,甚至超过了包括 Llama2-70B-Chat 在内的大模型。
知识推理
代码
数学
翻译
特殊任务
为进一步降低 MiniCPM 的计算开销,使用 GPT-Q 方法将 MiniCPM 量化为 int4 版本。相较于 bfloat16 版本与 float32 版本,使用 int4 版本时,模型存储开销更少,推理速度更快。量化模型时,我们量化 Embedding 层、LayerNorm 层外的模型参数。

依照上述放缩系数和零点,w 量化后为
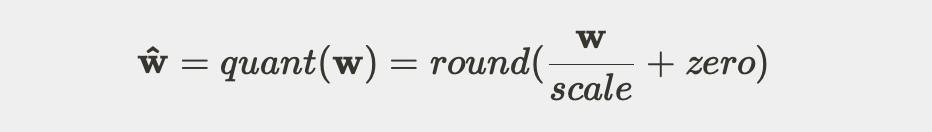
其中取整函数 round()为向最近整数取整。反量化时,操作方式如下:
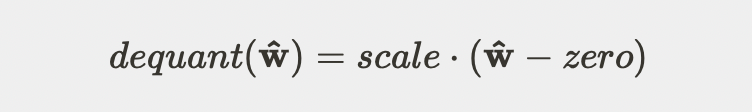
使用 GPT-Q 方法进行量化时,在标注数据 X 上最小化量化误差 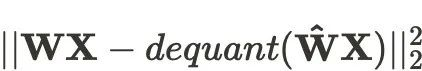
, 并循环对矩阵的未量化权重进行如下更新,其中 q 是当前量化的参数位置,F 为未量化权重,是量化误差的 Hessian 矩阵。
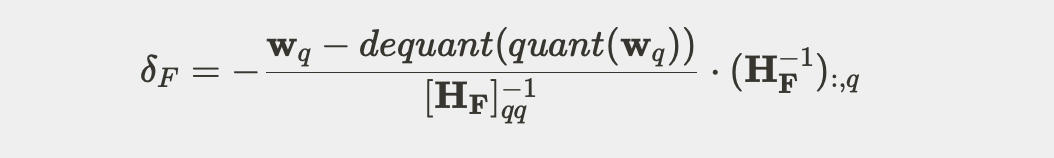
对于 MiniCPM-2B-SFT 与 MiniCPM-2B-DPO,我们均进行了 int4 量化,导出模型 MiniCPM-2B-SFT-Int4 与 MiniCPM-2B-DPO-Int4。
基于 MiniCPM,我们构建了一个支持中英双语对话的端侧多模态模型 MiniCPM-V。该模型可以接受图像和文本输入,并输出文本内容。MiniCPM-V 的视觉模型部分由 SigLIP-400M 进行初始化,语言模型部分由 MiniCPM 进行初始化,两者通过perceiver resampler 进行连接。
MiniCPM-V 有三个突出特点:
MiniCPM-V 模型的训练分为 2 个基本阶段:
详细训练与微调过程也可见我们 ICLR 2024 splotlight 论文。
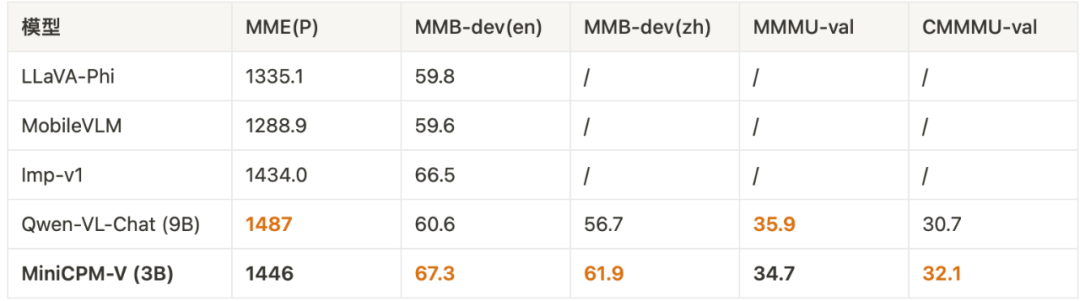
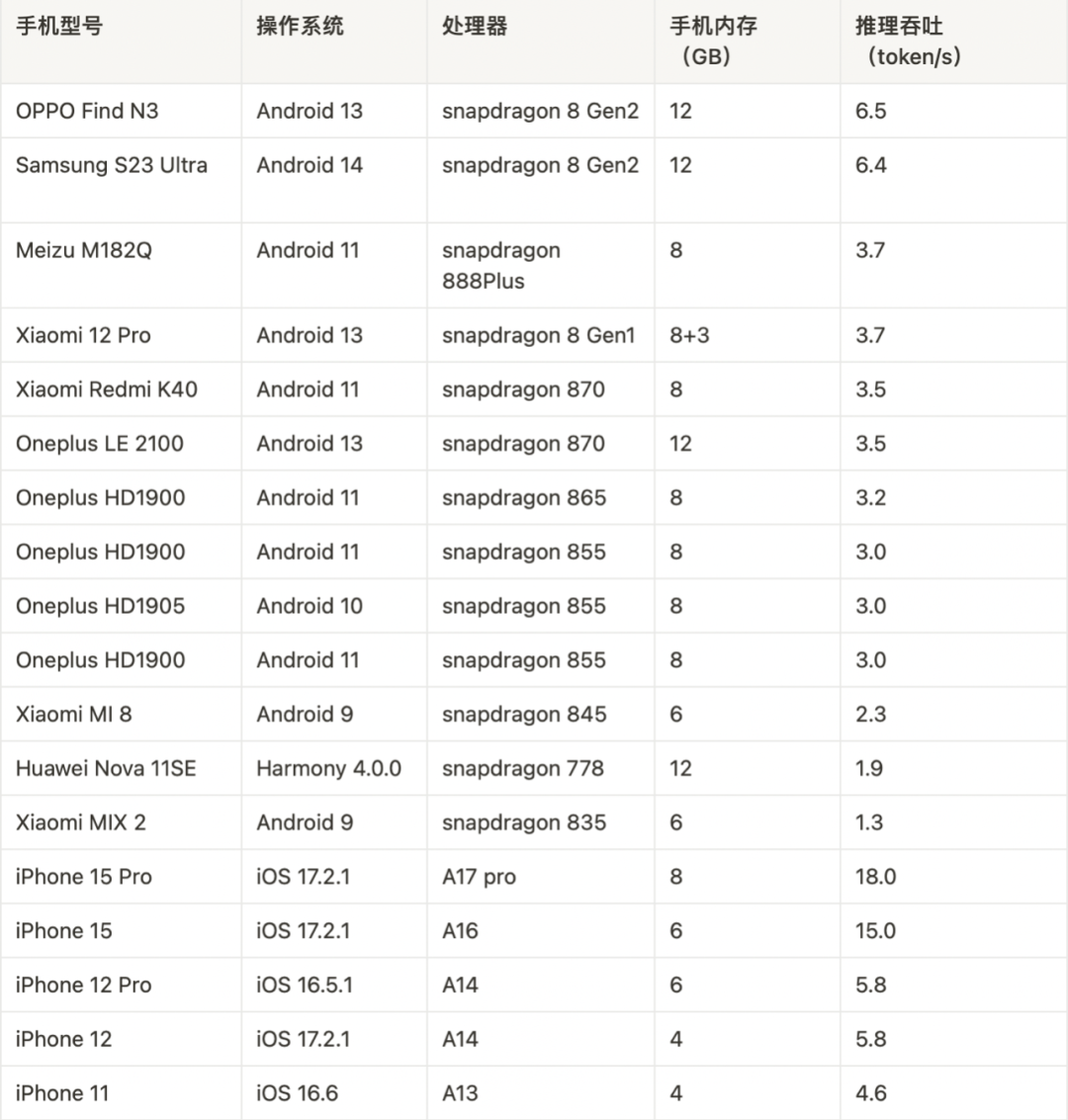
进行 Int4 量化后,MiniCPM 只占 2GB 空间,具备了在端侧手机进行模型部署的条件。对此,我们针对 Android 和 Harmony 系统使用开源框架 MLC-LLM 进行模型适配,针对 iPhone 系统使用开源框架 LLMFarm 进行模型适配,并分别选取了部分端侧手机设备进行了测试。此外,我们首次验证了在端侧手机运行多模态大模型的可行性,并成功在手机上运行。
值得注意的是,我们并未针对手机部署进行优化,仅验证 MiniCPM 在手机侧进行推理的可行性,我们也欢迎更多开发者进一步调优更新下面的测试列表,不断提升大模型在手机侧的推理性能。
文章来自于微信公众号 “OpenBMB开源社区”




【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
