# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在短视频推荐、跨模态搜索等工业场景中,传统多模态模型常受限于模态支持单一、训练不稳定、领域适配性差等问题。
近日,字节跳动抖音 SAIL 团队联合香港中文大学 MMLab 提出 SAIL-Embedding——一款专为大规模推荐场景设计的全模态嵌入基础模型,不仅实现了视觉、文本、音频的统一表征,更在抖音真实业务场景中带来显著效果提升,相关技术报告已正式公开。

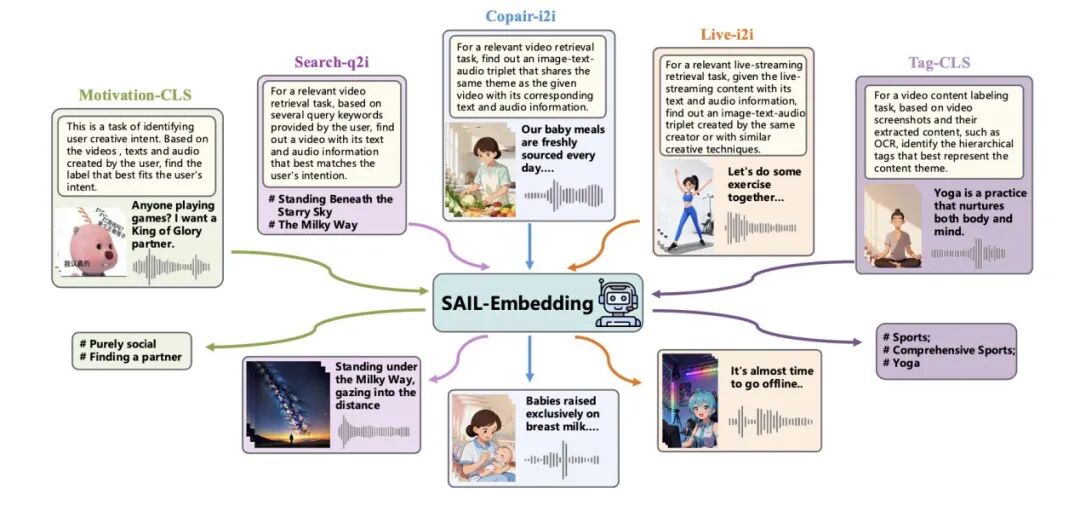
SAIL-Embedding 能力概览
现有多模态嵌入模型主要分为两类:以 CLIP 为代表的双塔架构,虽高效但模态融合浅;以 MLLM 为基础的融合架构,虽语义能力强却多局限于图文模态。SAIL-Embedding 则从根源上解决这些痛点:
全模态输入:覆盖短视频核心信息维度
不同于仅支持图文的传统模型,SAIL-Embedding 可处理任意模态组合——包括视觉模态侧的视频关键帧/封面、文本模态侧的标题/标签/OCR/ASR 文本、以及音频模态侧的背景音乐/语音,以适配抖音等短视频平台的信息结构。例如,在视频检索任务中,模型能同时利用画面内容、字幕文本与背景音效,避免单一模态信息缺失导致的语义偏差。
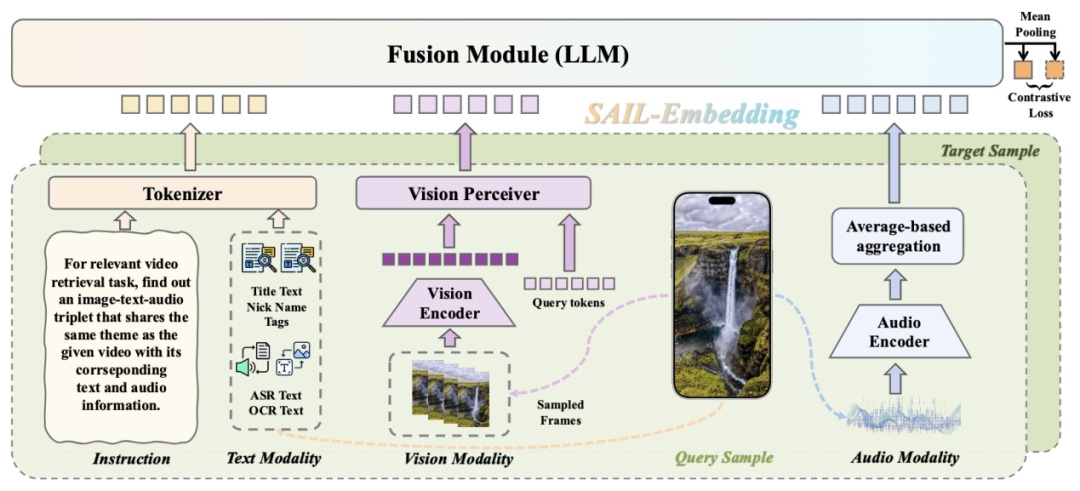
SAIL-Embedding 架构图
训练稳定性升级:动态难负样本 + 自适应数据平衡
为解决大规模训练中的噪声干扰与数据分布不均问题,团队提出引入两种策略:
SAIL-Embedding 的训练并非单一阶段,而是一套覆盖「基础能力-任务适配-推荐增强」的多阶段体系,确保模型既能理解内容语义,又能贴合真实推荐场景需求:
内容感知渐进式训练:从通用到领域的精准过渡
训练分三阶段逐步深入:
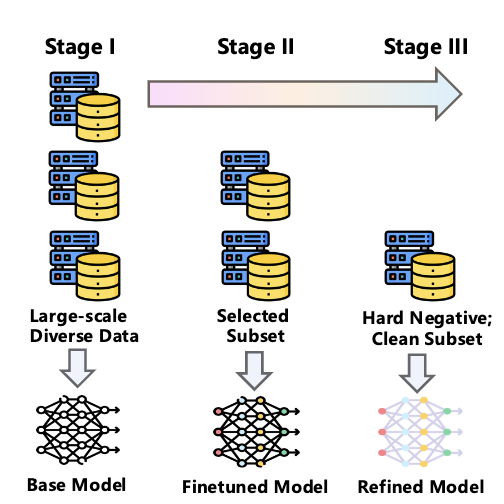
内容感知的渐进式训练
推荐感知的增强训练:融入用户行为信号
针对推荐场景,团队将多模态表征向用户历史序列表征和线上 ID 表征两个维度进行知识蒸馏以融于用户协同行为信息:
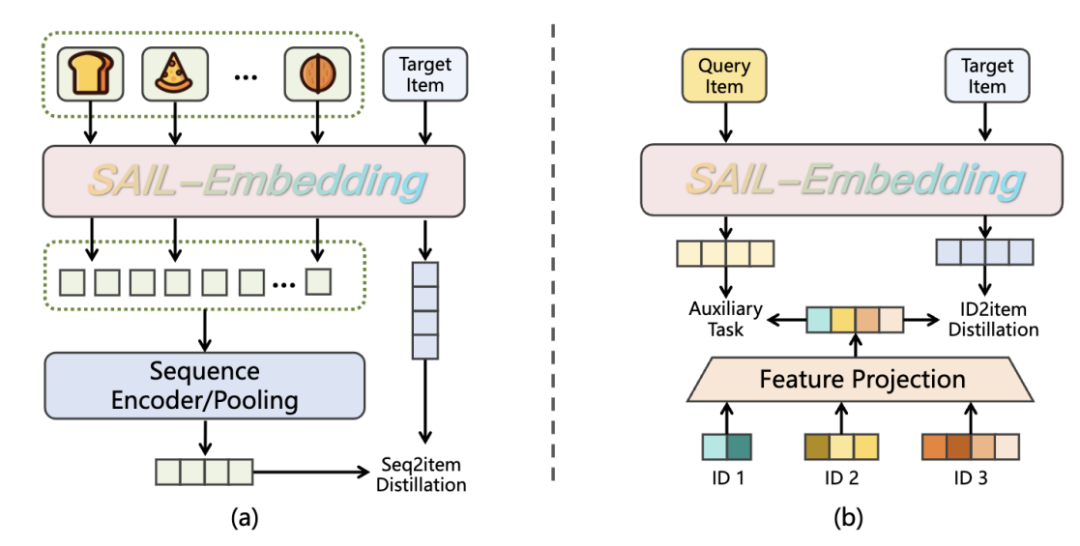
协同感知的两阶段推荐增强训练
无论是标准数据集的基准测试,还是抖音真实场景的在线实验,SAIL-Embedding 均展现出卓越性能:
离线任务性能:多场景检索与分类任务综合领先
(1) Item-to-Item Retrieval (物品到物品检索)
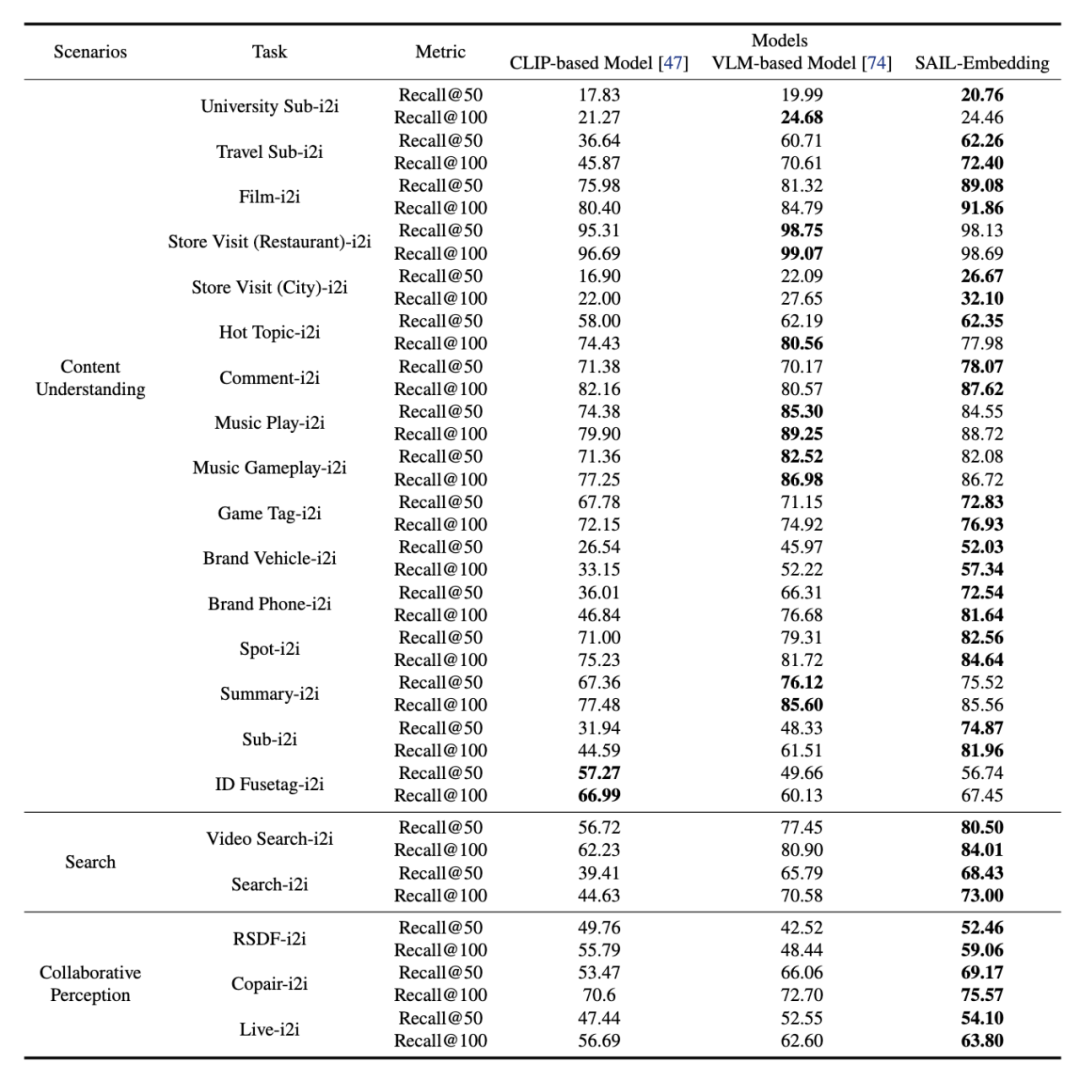
在 21 个涵盖内容理解、搜索,以及协同感知的多任务场景下,SAIL-Embedding 显著优于 CLIP-based 模型与 VLM-based 的模型:
(2) Query-to-Item Retrieval (查询到物品检索)
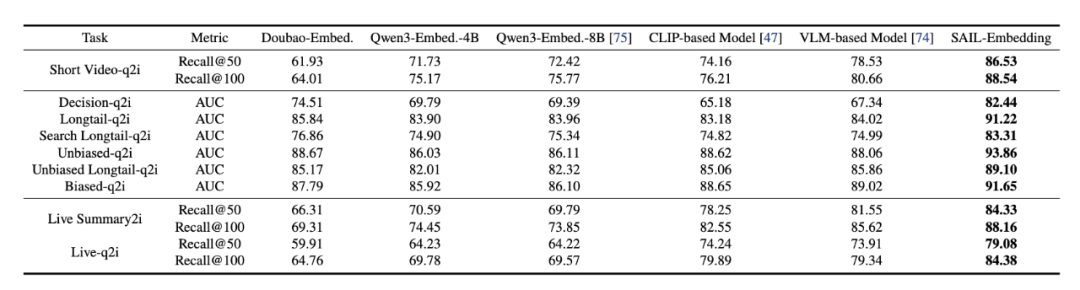
在 9 个涵盖检索为导向和分类为导向的多任务场景下,模型的 AUC 与 Recall 指标均取得领先:
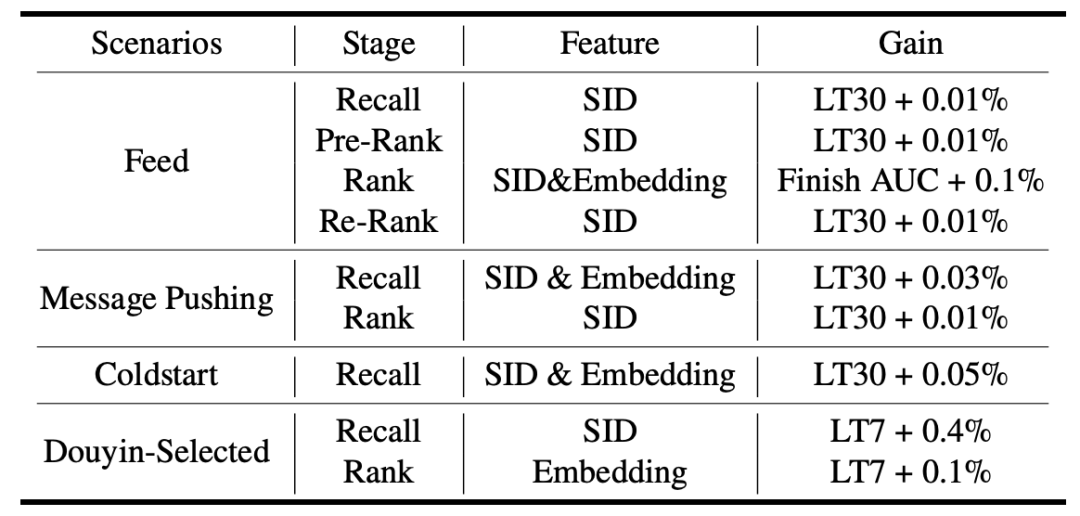
在线落地效果:抖音多场景推荐指标显著提升
在抖音 Feed 流、冷启动、抖音精选、消息推送等核心场景中,SAIL-Embedding 通过潜入向量与嵌入离散化的语义 ID 两种形式赋能推荐全链路,带来了一致的 LT 和 AUC 增益,体现了其显著的业务应用潜力。
SAIL-Embedding 的核心价值在于,它不仅是一款性能领先的全模态嵌入模型,更构建了一套从学术研究到工业落地的完整解决方案:通过全模态架构突破输入局限,用动态数据策略解决训练稳定性问题,以推荐增强训练填补产业鸿沟,最终在抖音真实场景中验证了技术价值,在短视频、直播等富模态推荐场景中,具备极强的推广价值。
抖音 SAIL 团队在未来将进一步探索 VLMs 与推荐系统的深度融合,例如通过生成式任务注入推荐知识,让模型不仅能「理解」内容,更能「预测」用户偏好。
文章来自于“机器之心”,作者 “机器之心”。


【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
