# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
传统智能体系统难以兼顾稳定性和学习能力,斯坦福等学者提出AgentFlow框架,通过模块化和实时强化学习,在推理中持续优化策略,并使小规模模型在多项任务中超越GPT-4o,为AI发展开辟新思路。
当前AI Agent的发展正陷入两难的境地:
一方面,训练「全能型」大模型让其同时承担推理、规划与工具调用,虽具一体化优势,但在长链推理中往往训练不稳定、扩展性受限;
另一方面,基于prompt的智能体系统虽具灵活性,却缺乏学习与自我优化能力,无法从交互中持续进化。
如何突破这一瓶颈?
斯坦福大学联合德州农工大学(Texas A&M)、加州大学圣地亚哥分校(UC San Diego)和Lambda的研究团队给出了新答案:让智能体系统在推理「流」中进行在线强化学习,从而实现持续的自我提升与能力进化。

论文地址: https://arxiv.org/abs/2510.05592
项目主页: https://agentflow.stanford.edu/
开源代码: https://github.com/lupantech/AgentFlow
在线展示:https://huggingface.co/spaces/AgentFlow/agentflow
视频教程:https://www.youtube.com/watch?v=kIQbCQIH1SI
他们提出AgentFlow框架采用模块化架构,通过4个专门化智能体协同工作,配合专门设计的Flow-GRPO算法,使系统能够在真实交互环境中持续优化决策策略。
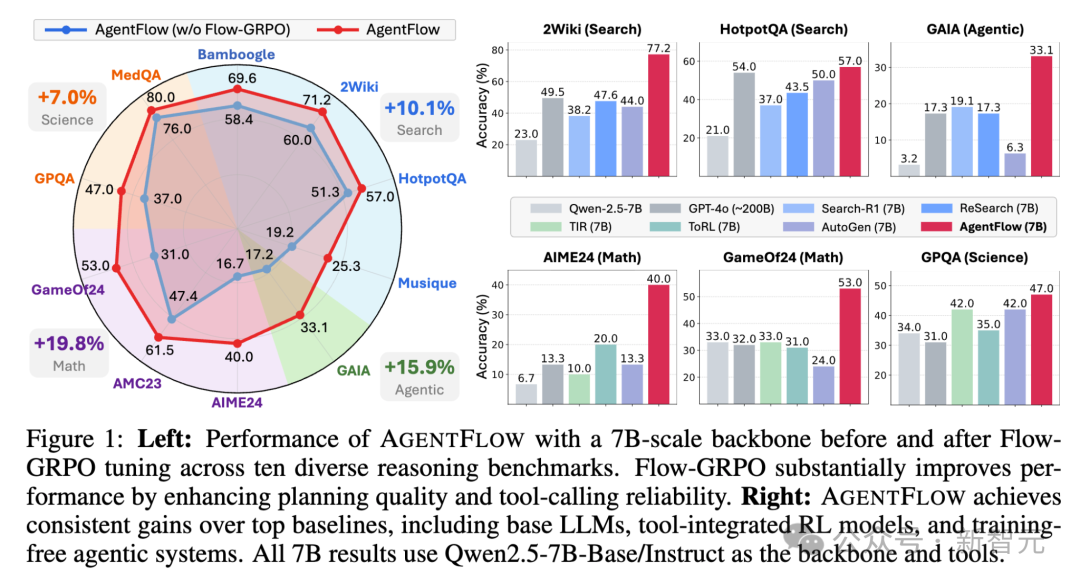
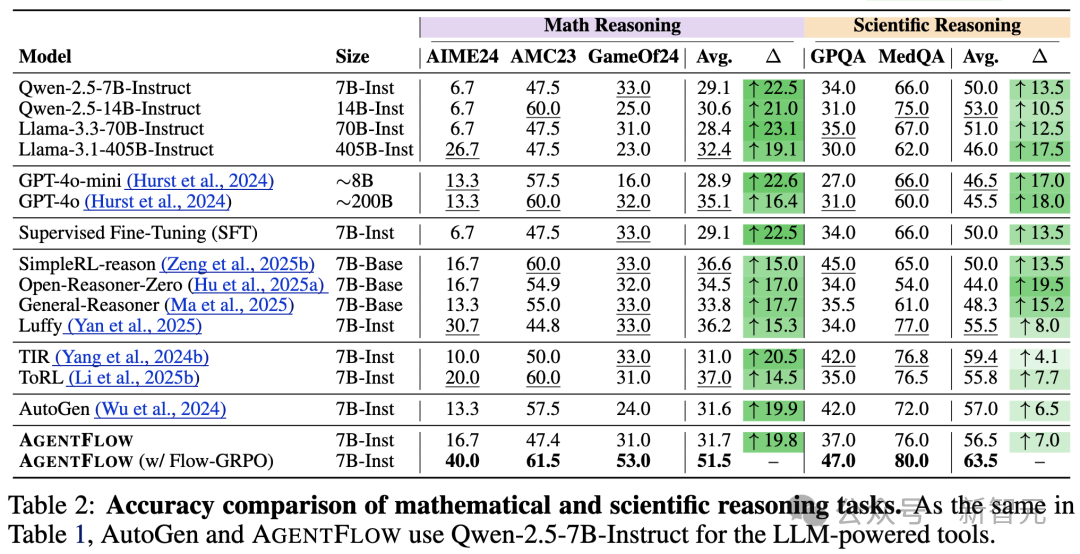
实验结果显示,仅7B参数的AgentFlow在搜索、数学、科学等多个任务上全面超越GPT-4o(约200B参数)和 Llama-3.1-405B。
团队负责人在推特上分享了工作,获得了极大的关注。



该工作目前已登上HuggingFace Paper日榜第二名,以及周最火Huggingface 项目。

训练智能体系统面临的核心挑战是多轮信用分配(multi-turn credit assignment)问题:在长时跨度、奖励稀疏的环境中,如何准确判断每一步决策对最终结果的贡献?
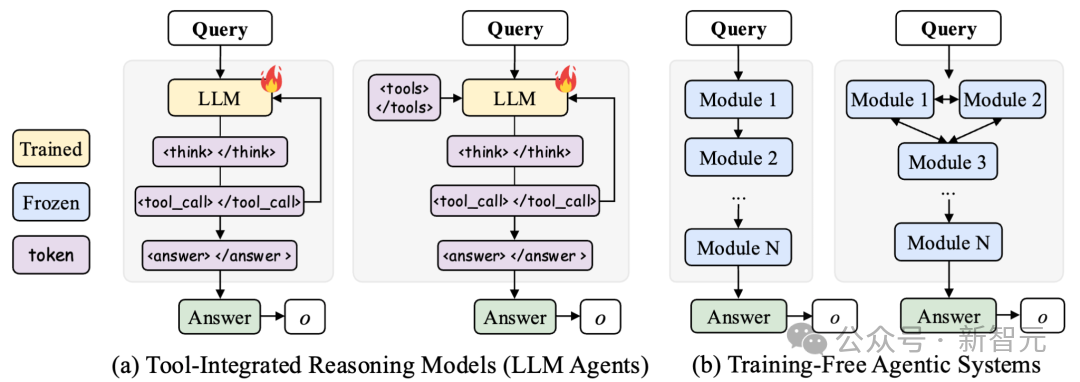
传统的单一模型方法将所有功能集成在一个LLM中,通过特殊标签(如 <tool_call>)一体化输出思考、工具调用和回复。
这种方式在短链任务中有效,但在复杂场景下容易出现:推理链过长导致训练不稳定、工具选择错误难以追溯、无法根据环境反馈动态调整策略。
而现有的智能体系统(如 LangGraph、OWL、Pydantic、AutoGen)虽然实现了模块化,但大多依赖固定的 prompt 工程,缺乏从经验中学习的机制。
AgentFlow的设计思路是:将复杂的推理任务分解给专门化的智能体模块,同时让核心决策模块能够在交互中持续学习。
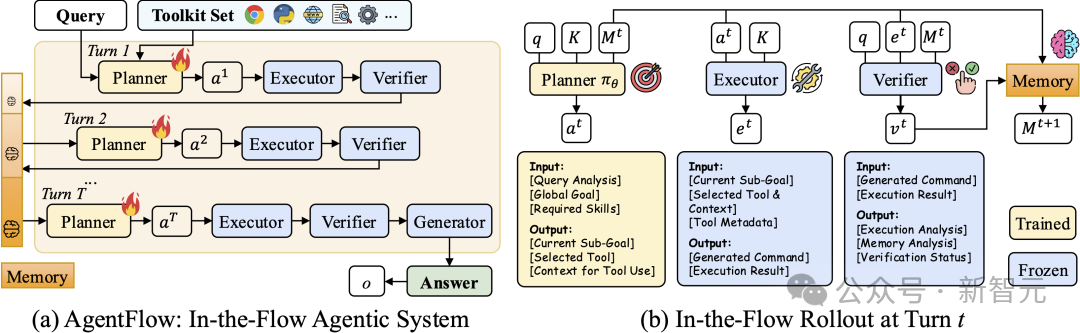
四模块协同架构
系统由四个具备记忆能力的专门化智能体组成:
关键创新在于:规划器不是静态的,而是通过在线(on-policy) 强化学习在推理流中实时优化。
每轮交互后,系统会根据最终结果的成功或失败,更新规划器的决策策略,并将优化结果整合到系统记忆中,形成闭环的自适应学习过程。
团队提出Flow-GRPO(Flow-based Group Relative Policy Optimization)算法,专门针对多轮推理场景设计。核心思想是将轨迹最终的奖励信号(成功/失败)广播到每一步动作,把复杂的多轮强化学习问题转化为一系列单轮策略更新。
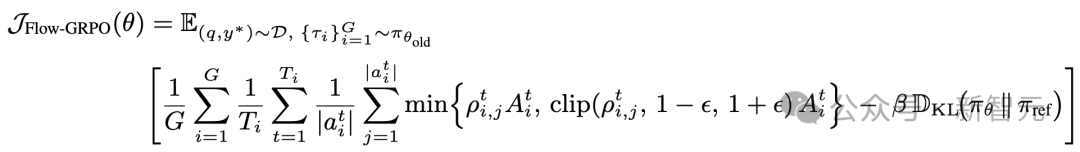
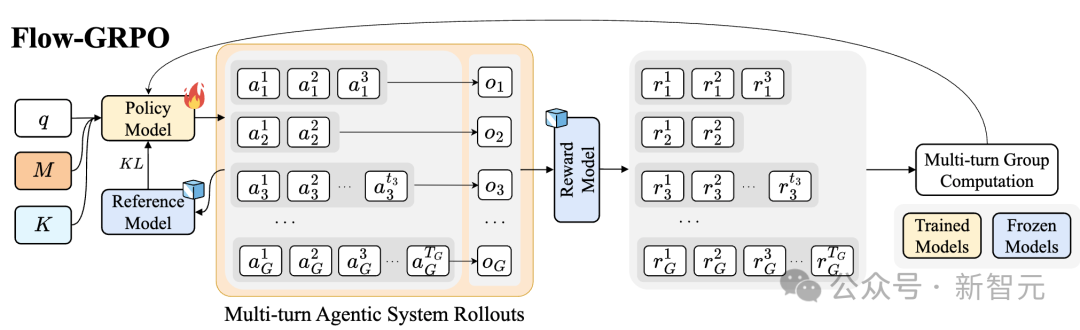
具体做法是:
1. 收集完整的推理轨迹(从初始任务到最终结果);
2. 根据最终结果计算 outcome reward;
3. 将这个 reward 分配给轨迹中每个规划动作;
4. 使用相对优势函数计算每个动作的优势,进行策略梯度更新。
这种方法有效缓解了奖励稀疏问题,同时保持了训练的稳定性。
在线学习使系统能够:快速纠正错误的工具调用、探索更优的子任务分解方式、根据环境反馈动态调整推理深度。
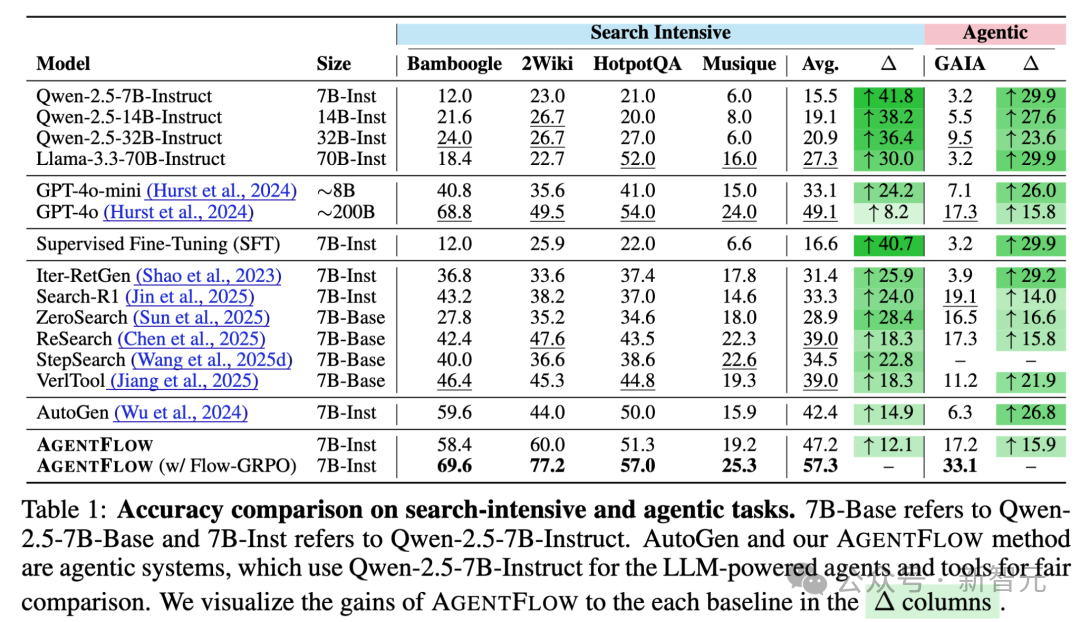
研究团队在10个跨领域基准上进行了系统评测,覆盖知识检索、智能体任务、数学推理和科学推理四大类。
性能对比
以Qwen-2.5-7B-Instruct为基座模型,AgentFlow 在所有类别中均显著领先。
知识检索:相比基线提升14.9%
智能体推理:提升14.0%
数学推理:提升14.5%
科学推理:提升4.1%
更令人惊讶的是跨规模对比结果:
消融实验的关键发现
1. 在线学习 vs 离线学习
对比实验显示,如果用传统SFT方式训练规划器,性能反而会平均下降19%。这证明在真实交互环境中的在线学习是实现高效推理的必要条件。

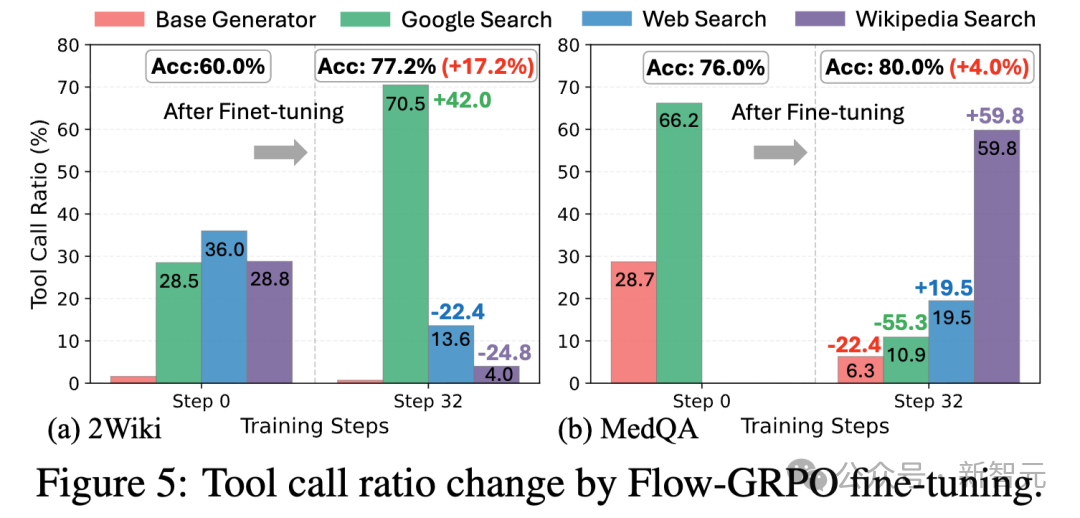
2. 自主探索新策略
根据任务特点选择合适的工具组合;同时,经过训练的系统会自发探索出新的工具使用模式,比如组合使用维基百科搜索(Wikipedia Search) 和特定网页增强搜索(Web Search)的连招,通过工具链获得更加深入地信息挖掘,而这些模式几乎没有在未训练的推理流中出现。
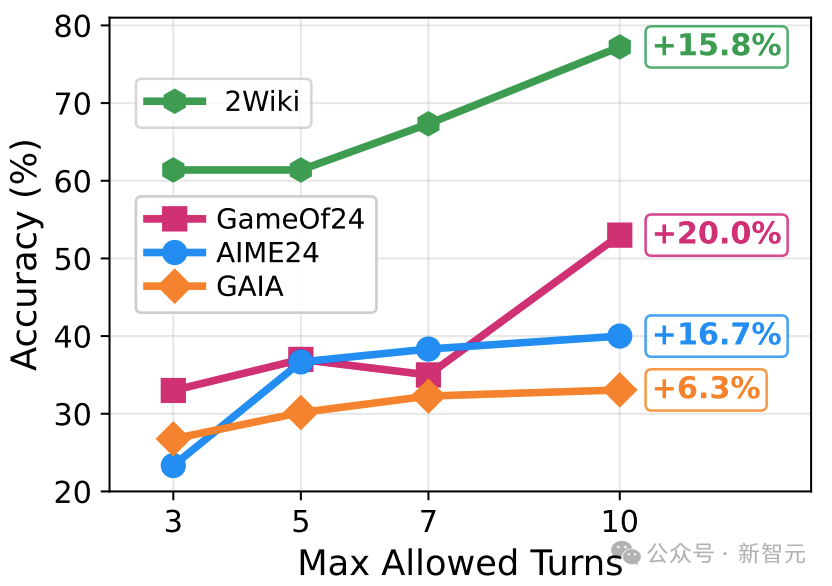
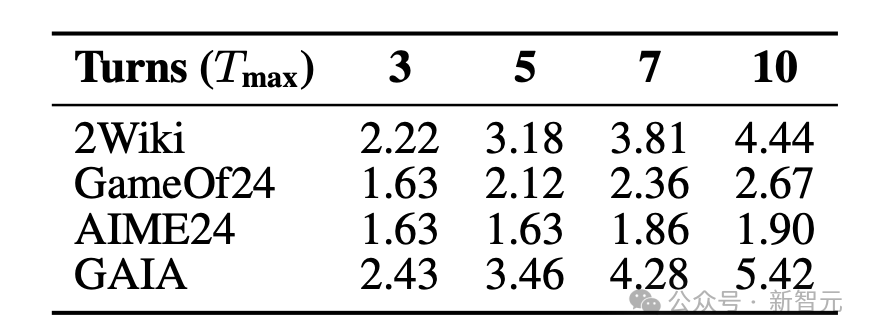
3. 动态推理深度
在多跳搜索等密集推理任务中,训练后的AgentFlow展现出「智能的懒惰」:对简单任务保持较少的推理步数,对复杂任务才会增加推理深度。
随着最大步数限制的提升,性能稳步上升但平均步数不会同比例增长。
4. 模块协作的价值
虽然推理流本身就能带来性能提升,但未经训练的系统容易出现循环错误或卡顿。
通过强化学习训练后,系统在工具调用准确性、子任务规划精细度和全局性能上都有明显改善。作者团队提供过了一个例子来生动展示了在实验中的有趣发现。

在这个例子中,在经过Flow-GRPO训练前的推理系统,一旦遇到了诸如这里的python变量定义错误,便会反复输出相同的子目标和工具调用,极大地浪费时间和推理效率。
在经过Flow-GRPO在线更新后,动作规划器能够根据之前的错误自动调整用更确切的子目标和任务描述来指导后续步骤,并且经过这样的随机应变后,一步成功。
这个例子也极大程度展现了,在智能体系统真实推理中进行强化学习的极大潜力。
AgentFlow的工作价值在于:
1. 提供了新的训练范式证明了智能体系统可以通过在线强化学习获得类似大模型的学习能力,且在特定任务上效率更高。
2. 验证了「小而精」的可行性在合理的系统设计下,小模型通过模块化协作和持续学习,可以在复杂推理任务中超越大规模通用模型。
3. 为可扩展AI提供思路模块化架构使得系统可以灵活添加新工具、调整模块功能。
AgentFlow至少让我们看到:Agentic AI的发展不必完全依赖模型规模的堆砌,系统架构创新+高效训练方法可能是更值得探索的方向。
参考资料:
https://arxiv.org/abs/2510.05592
文章来自于“新智元”,作者 “LRST”。



【开源免费】OWL是一个完全开源免费的通用智能体项目。它可以远程开Ubuntu容器、自动挂载数据、做规划、执行任务,堪称「云端超级打工人」而且做到了开源界GAIA性能天花板,达到了57.7%,超越Huggingface 提出的Open Deep Research 55.15%的表现。
项目地址:GitHub:https://github.com/camel-ai/owl
【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】Semantic Search on Wikipedia是一个索引数百万维基百科文章的AI搜索引擎。该项目开源免费,通过维基百科数据创建了一个语义搜索引擎和一个RAG聊天机器人。
项目地址:https://github.com/upstash/wikipedia-semantic-search?tab=readme-ov-file
在线使用:https://wikipedia-semantic-search.vercel.app/
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
