# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在大语言模型快速发展的今天,“记忆”正成为智能体能否真正具备长期智能的关键。
即使是支持百万级上下文的GPT-4.1,当交互持续增长时,成本和延迟依然会呈指数级上升。于是,外部记忆系统应运而生——然而,大多数现有方案依赖人工规则与 prompt 指令,模型并不真正“理解”何时该记、记什么、如何更新。
Mem-α 的出现,正是为了解决这一困境。由加州大学圣地亚哥分校的 Yu Wang 在 Anuttacon 实习期间完成,这项工作是首次将强化学习引入大模型的记忆管理体系,让模型能够自主学习如何使用工具去存储、更新和组织记忆。

现有的记忆增强智能体(如 MIRIX、MemGPT)通常依赖开发者提前设计好的指令模板来指导记忆操作。但在复杂的交互环境中,模型往往面临三大挑战:
结果就是“记错”,“忘记”频发:如图所示,在没有强化学习优化前,Qwen3-4B 模型未能更新核心记忆、语义记忆仅保存了片段性信息,最终导致问答错误。而经过Mem-α训练后,模型开始展现出“主动学习”的能力:能识别出关键事件,将它们分别写入核心记忆 (Core Memory)、情景记忆 (Episodic Memory) 和语义记忆 (Semantic Memory)中,实现全面的信息保留与压缩。

Mem-α 的核心贡献在于将记忆构建问题转化为一个可通过强化学习优化的序列决策问题。与以往依赖监督学习或手工规则的方法不同,Mem-α 让智能体在处理信息流的过程中自主探索最优的记忆管理策略,并通过下游任务表现直接获得反馈。这种端到端的优化方式使得模型能够学习到真正有效的记忆构建策略。
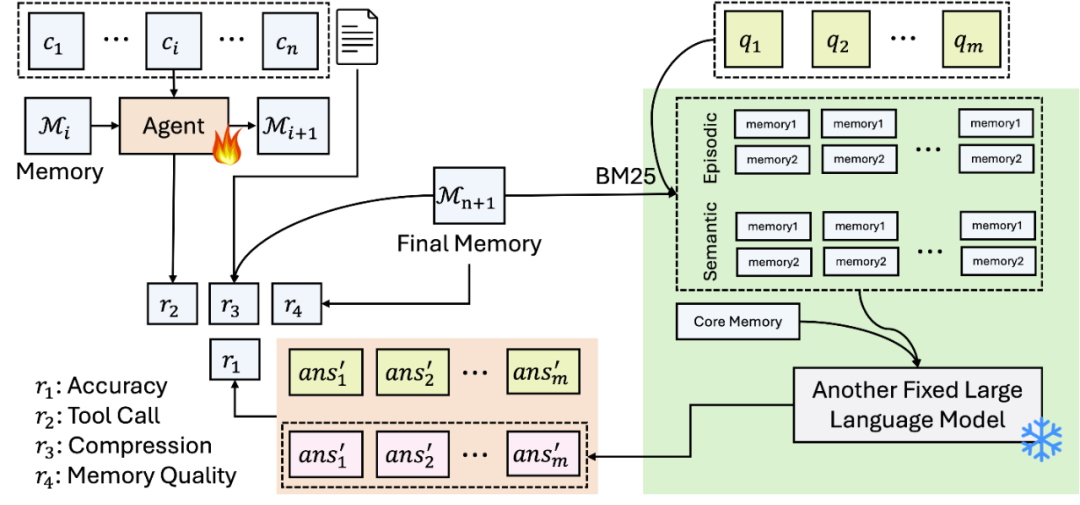
任务设定(Task Setup)

奖励函数设计
Mem-α采用多维度奖励函数优化记忆构建:

Mem-α 的架构参考了认知科学中的记忆分类理论,构建了一个三层记忆体系:
智能体需要在每个时间步决定调用哪种记忆类型、执行插入或更新操作。通过强化学习优化后,模型学会了如人类一般“灵活调用不同记忆系统”。

训练数据集构建
Mem-α 的训练数据集的构建思路来源于MemoryAgentBench中的四个维度:
1.精确检索(Accurate Retrieval):从历史数据中提取正确信息以回答查询,涵盖单跳和多跳检索场景
2.测试时学习(Test-Time Learning):在部署期间获取新行为或能力
3.长期理解(Long-Range Understanding):整合分布在多个片段中的信息,回答需要全面序列分析的查询
4.冲突解决(Conflict Resolution): 在遇到矛盾证据时修订、覆盖或删除先前存储的信息
本研究聚焦于前三个维度,排除了冲突解决维度。这是因为目前缺乏真实的评估基准——现有的冲突解决数据集主要是合成的,未能充分捕捉真实世界的复杂性。研究团队收集并整理了来自不同源头的八个数据集,处理到统一的范式,最后构造了一个完善的数据集并保证与MemoryAgentBench的测试集没有交织,涵盖了以上的前三个维度进行训练。
主实验:性能与泛化能力
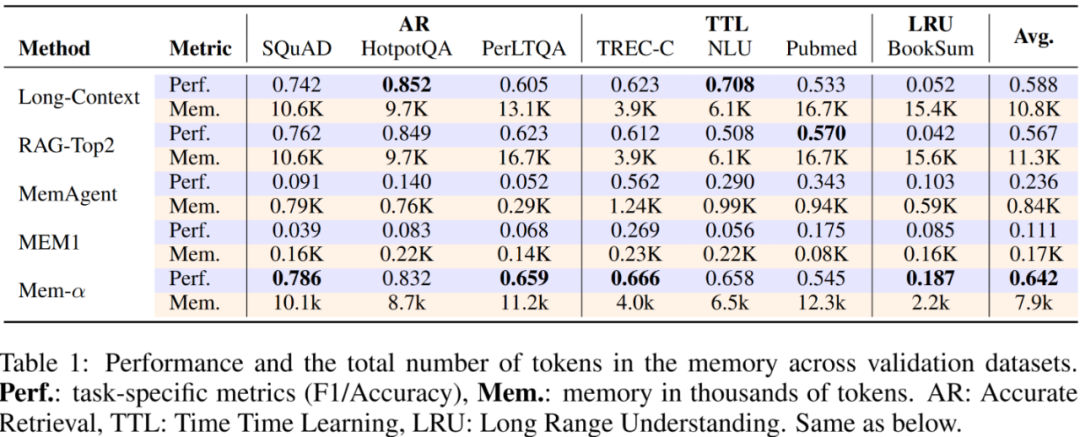
Mem-α 在 30k tokens 上训练,在验证集(验证集也是<30k tokens的)上的效果如下:
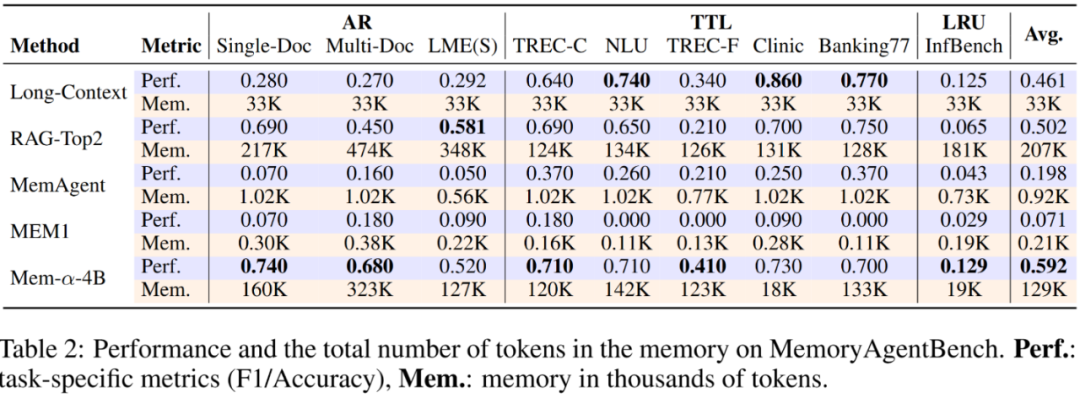
在测试集上的效果如下:
四个关键发现:
1.全面超越现有方法:Mem-α 在所有评测任务中均显著领先于基线模型。在 MemoryAgentBench 的 精确检索(Accurate Retrieval) 与 长期理解(Long-Range Understanding) 两个维度上表现尤为突出,展现出对未见分布的强泛化能力——证明强化学习训练出的记忆策略不仅“学得好”,还能“迁得远”。
2.效率与性能兼得的记忆压缩:相较于 Long-Context 与 RAG-Top2,Mem-α 在保持更高性能的同时,记忆占用减少近 50%。
在 BookSum 与 InfBench-Sum 等长文理解任务中,语义压缩机制的优势进一步放大,证明其在“保真度”与“存储效率”之间实现了理想平衡。
3.结构化记忆的决定性作用:实验显示,使用单一段落表示的扁平记忆基线(MEM1、MemAgent)在复杂任务上表现受限。相比之下,Mem-α 的分层记忆架构让模型能够区分核心、情景与语义信息层次,配合强化学习优化策略,大幅提升了复杂信息的组织与检索能力。
4.极强的长度外推能力:尽管训练仅基于平均长度小于 30K tokens 的样本,Mem-α 却能稳定泛化至超过 400K tokens的超长文档(MemoryAgentBench 最长达 474K tokens)。这意味着模型不仅学会了“如何记忆”,还具备了对极端长序列的推理鲁棒性——在记忆建模领域首次实现真正意义上的长度外推。
消融实验:从“不会用记忆”到“学会管理记忆”

在消融实验中,研究团队对比了Qwen3-4B 在强化学习训练前后的表现。结果显示,在引入 Mem-α 之前,模型虽然具备完整的记忆模块,却几乎不知道如何正确使用它们——平均准确率仅为 38.9%,工具调用频繁出错,核心与语义记忆更新紊乱。而经过 Mem-α 训练后,模型的表现出现质变:准确率跃升至 64.2%,能够主动选择合适的记忆类型与操作顺序,实现了真正意义上的“自主记忆管理”。这一结果证明,强化学习不仅提升了任务表现,更赋予模型理解和优化自身记忆行为的能力。
从工程到学习:智能体记忆的未来
Mem-α 让我们看到一个重要趋势:“记忆管理不再是工程问题,而是可以被学习的问题。”
通过强化学习信号,模型不再依赖人工设计的规则,而是通过交互自行演化出有效的记忆策略。这项研究为记忆增强智能体打开了新的方向——未来,类似的机制或许可以扩展到多模态记忆(图像、音频)、个性化记忆策略甚至多智能体协作记忆系统。正如论文作者所言,Mem-α 的意义在于让智能体第一次真正理解自己的记忆。
文章来自于微信公众号 “机器之心”,作者 “机器之心”


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
