# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
多模态大语言模型(MLLMs)在处理来自图像和文本等多种来源的信息时能力强大 。
然而,一个关键挑战随之而来:当这些模态呈现相互冲突的信息时(例如,图像显示一辆蓝色汽车,而文本描述它为红色),MLLM必须解决这种冲突 。模型最终输出与某一模态信息保持一致的行为,称之为“模态跟随”(modality following) 。
以往的研究大多试图用粗粒度的、数据集层面的统计数据来衡量这种行为 ,但这忽视了一个至关重要的因素:模型在进行单模态推理时,对每个具体案例的“置信度”(即不确定性)是不同的 。
本文的核心论点是,这种宏观的“模态跟随”统计数据具有误导性,因为它混淆了模型的能力和偏好。我们提出,模态跟随并非一个静态属性,而是一个动态过程,它由两个更深层次的因素相互作用所支配:
相对推理不确定性(Relative Reasoning Uncertainty):在单个具体案例上,模型对文本推理和视觉推理的置信度差距 。固有模态偏好(Inherent Modality Preference):当模型感知到两种模态的不确定性(即推理难度)相等时,其内在的、稳定的偏向 。

本文的主要作者来自北京大学、华南理工大学、佐治亚大学以及KAUST和MBZUAI。研究团队的核心成员包括担任第一作者的北京大学博士生张卓然、北京大学博士生史阳、华南理工大学的本科生王腾岳以及来自佐治亚大学的博士生宫熙琳。本文的通讯作者为KAUST王帝老师和MBZUAI胡丽杰老师。
该篇工作的主要贡献和结论包括:
(1)构建了一个新的玩具数据集,可以系统地、独立地改变视觉和文本输入的推理难度,从而实现不同难度的多模态组合输入。
(2)首次提出将“模态跟随”这一外显行为分解为两个核心组成部分:案例特定的“相对推理不确定性”和模型稳定的“固有模态偏好” 。这一框架旨在将模型的单模态能力(反映为不确定性)与其内在偏见(固有偏好)清晰地解耦。
(3)实证发现了一个基本规律——模型跟随某一模态的概率,会随着该模态相对推理不确定性的增加而单调递减。
(4)该框架提供了一种更合理、更少混淆的“固有偏好”量化方法。研究者将模型偏好定义为该单调曲线上的“平衡点”(balance point) ——即模型对两种模态“同等看待”(50%跟随概率)时所需的相对不确定性补偿值 。这成功地将“固有偏好”从“数据集伪影”和“单模态能力”中分离出来。
(5)深入探究了模型内部的决策机制,发现在“模糊区域”(即相对不确定性接近模型的“平衡点”)时,模型的逐层预测会在两种冲突答案之间表现出强烈的“振荡”(oscillations)。这种内部的犹豫不决,为模型在外部观察到的平均化选择行为提供了机制性的解释。
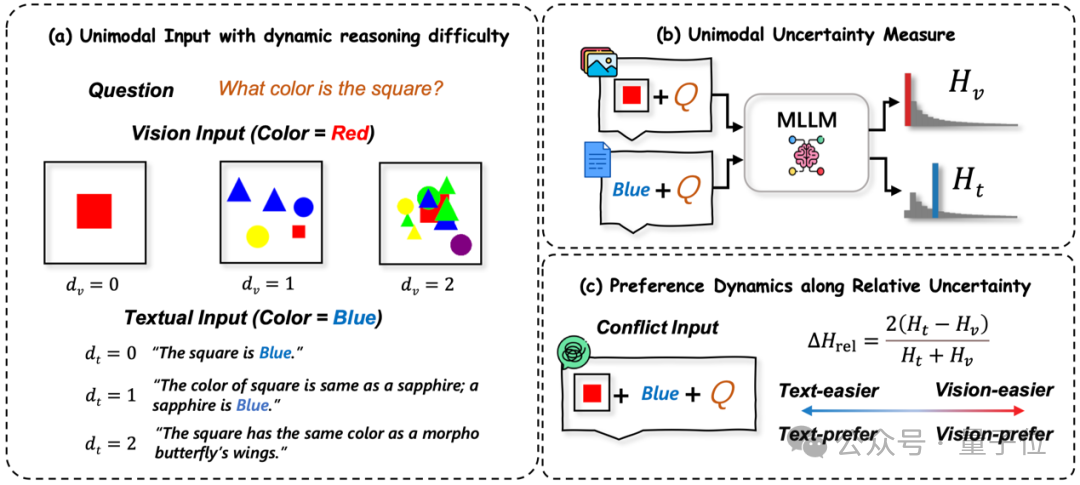
1. 可控数据集
为了系统地验证假设,研究者必须建立一个受控的实验环境。为此,他们构建了一个新颖的可控“玩具”数据集,其核心特性是能够通过两个独立的设计等级——视觉难度和文本难度——来系统地、独立地控制两种模态的推理复杂性,如图1a所示
2. 不确定性度量
虽然设计等级提供了人类可解释的难度,但分析需要一个以模型为中心、能反映其自身感知不确定性的指标。为此,研究采用了输出答案词元(token)的输出熵(Entropy)作为精细化的不确定性度量。
低熵值表示一个自信、尖锐的预测(如“红色”概率很高),而高熵值则表明模型还在考虑其他替代选项(如“橙色”、“棕色”),反映了其更高的不确定性。随后的单模态熵趋势分析(如图2所示)有力地证实了这一点:熵值随着设计难度的增加而一致上升,验证了熵作为模型感知不确定性代理指标的有效性。
3. 相对不确定性
为了量化模型在每个冲突案例中的“置信度差距”,研究者引入了“相对单模态不确定性”。该指标通过一个公式来计算,如图1c所示,即(文本熵减去视觉熵的差值)除以(两者之和),最后再进行归一化处理,从而测量了文本熵和视觉熵之间的归一化差异。这一指标构成了后续分析的核心。在这个定义下,负值表示模型对文本更自信(即文本更容易),而正值则表示模型对视觉更自信(即视觉更容易)。
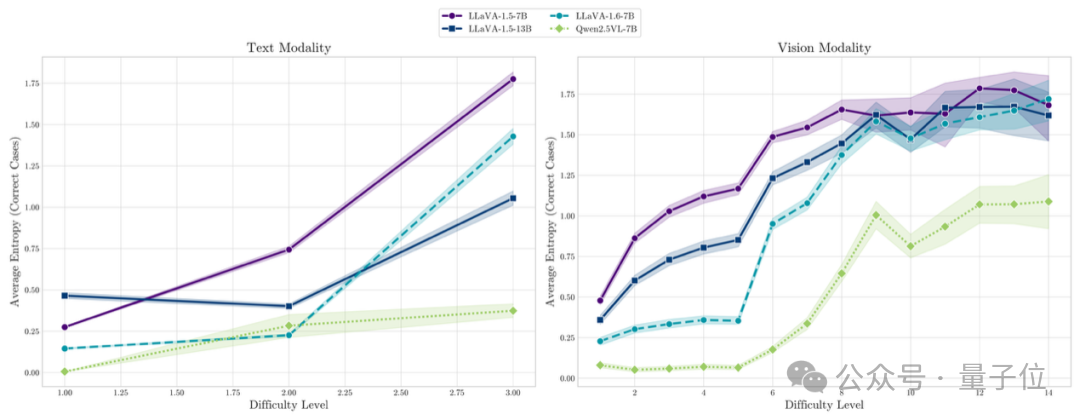
图2:展示构造数据集上文本和视觉单模态上的输出熵随着难度的变化趋势。
研究者首先在构建的可控数据集上,针对LLaVA和Qwen-VL系列等6个MLLM,使用传统的宏观指标(如“文本跟随率”TFR和“视觉跟随率”VFR)进行了测试。结果如图3所示,发现了两种令人困惑的组合模式,充分暴露了这些宏观指标的局限性。
相似的难度感知,相反的宏观偏好
首先,当观察精细化的“相对不确定性”分布时,研究发现一个普遍趋势:对LLaVA系列和Qwen2.5-VL等大多数模型而言,该数据集的文本模态在平均水平上更容易处理(即不确定性更低)。然而,这些模型在宏观指标上的表现却截然相反:LLaVA系列呈现出强烈的“文本跟随”倾向,而Qwen2.5-VL却显著地“跟随视觉”。这就引出了第一个谜题:既然这些模型都感知到文本模态更简单、更确定,为什么它们最终的宏观选择会完全相反?
相似的宏观偏好,相反的难度感知
其次,对比Qwen2-VL和Qwen2.5-VL。在宏观指标上,两者都表现出“跟随视觉”的相似倾向(甚至 Qwen2-VL 的视觉倾向更显著)。然而,它们各自感知的“相对不确定性”分布却截然不同:
对Qwen2-VL而言,更多的数据点落在了“视觉更容易”(即视觉不确定性更低)的区间;而Qwen2.5-VL面临的却是前述的“文本更容易”的分布。
这就引出了第二个谜题:同样是“跟随视觉”,Qwen2-VL的行为似乎可以被“选择更简单的选项”来解释,但 Qwen2.5-VL却是在尽管文本更简单的情况下,也依然选择了视觉。
这两个矛盾共同指向了一个核心问题:导致宏观指标结果的根本原因究竟是什么?是一种由数据集难度偏向和模型特定能力共同作用下产生的“数据集伪影”(dataset artifact),还是一种更深层、更顽固的“固有模态偏好”(inherent preference)?
传统的宏观指标(TFR/VFR)之所以具有误导性,正是因为它将这两个完全不同的因素——即模型的“单模态能力”(反映为感知到的不确定性)和其“固有偏好”——混为一谈,从而让我们无法看清模型决策的真正动机。
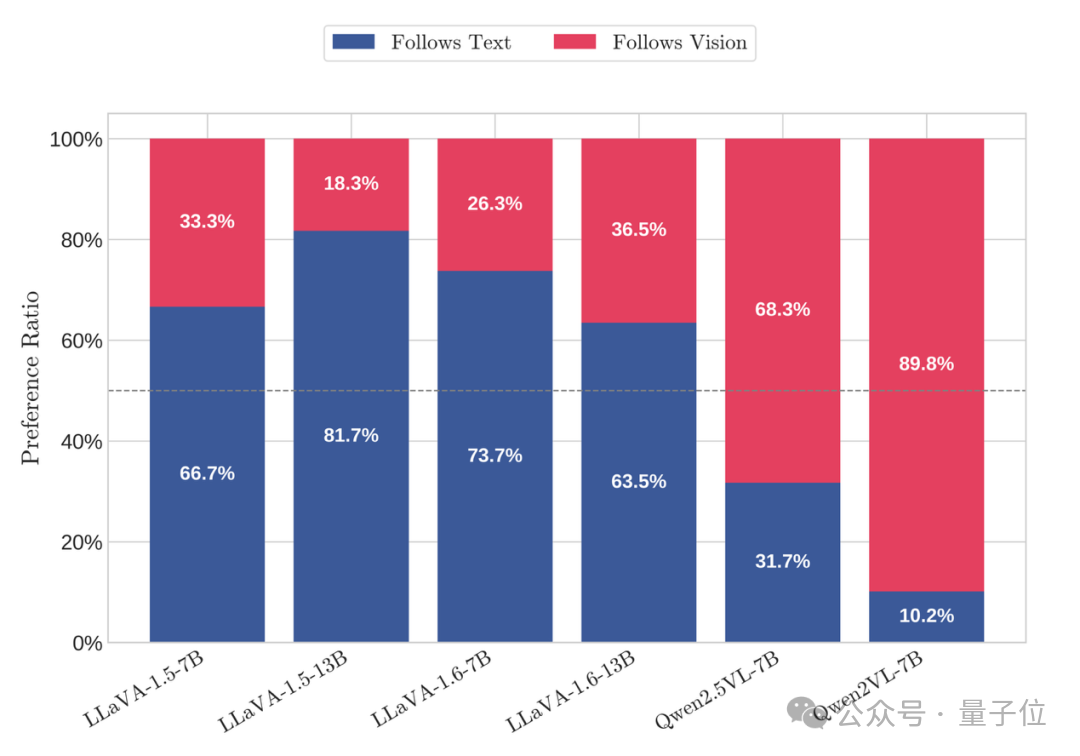
图3a:展示构造数据集上文本和视觉传统跟随指标。
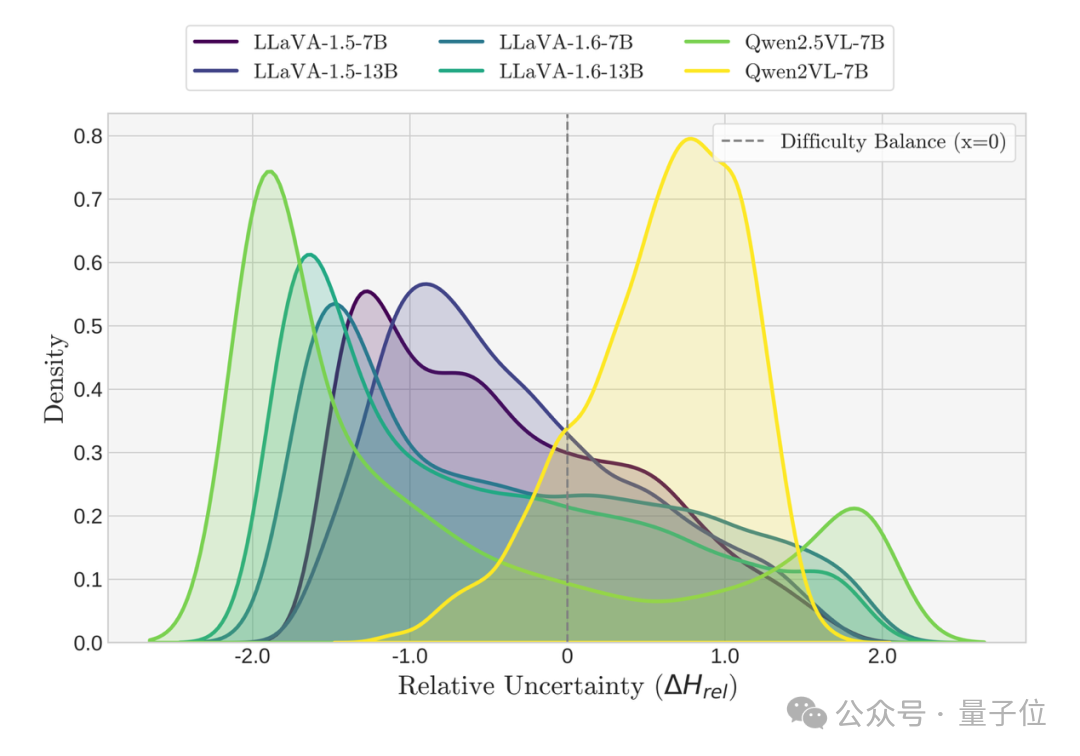
图3b:展示构造数据集上文本和视觉单模态上的相对不确定度分布。
为了解决上述矛盾,并揭示被宏观指标所掩盖的真实动机,研究者设计了一种全新的实验范式。这就好比我们想评估一个学生是“更偏爱用汉语”还是“更偏爱用英语”答题。这个学生的汉语能力和英语能力(即“单模态能力”)可能并不均衡。如果我们只统计他最终用了哪种语言(即传统的“宏观指标”),我们可能只是在测量他的能力(他当然会用他更擅长的语言),而不是他内心的偏好 。传统指标错误地将这两个因素混为一谈。
正确的做法是,我们应该针对每一种难度组合(例如,简单的汉语 vs. 困难的英语)来观察他的选择,从而绘制一条完整的“偏好曲线”。本研究正是采用了这种思路。
研究者不再依赖一个总的“文本跟随率” ,而是将所有数据点根据其“相对不确定性”(一个量化模型对两种模态置信度差距的指标)进行分组。
然后,他们计算了每个“相对不确定性”区间内的“文本跟随率” 。这相当于以“相对不确定性”为横轴(归一化了两种模态的难度差异),以“文本跟随概率”为纵轴,绘制出了一条能反映模型偏好随相对难度动态变化的完整曲线。
当在这种归一化的视图下重新审视模型时,先前所有的混乱和矛盾都消失了,取而代之的是几个清晰且统一的结论,图4同时展示了在本文构造的颜色识别数据集和现有的模态跟随数据集MC^2的颜色识别子集上的文本跟随占比与相对不确定度分布之间的关系:
1. 统一的单调法则
被测试的六个模型,无论其架构或规模如何,都展现出一种惊人的一致性:随着文本变得相对更难(即其不确定性相较于视觉更高),模型跟随文本的概率都呈现出平滑且严格的单调递减趋势。这一发现强有力地证实了论文的核心假设:模态跟随并非一个固定的属性,而是一个由相对推理不确定性动态支配的动态行为。
2. “平衡点”量化固有偏好
虽然所有模型都遵循这条单调法则,但它们的曲线在“相对不确定性”轴上的位置各不相同。研究者将曲线穿过50%概率线的那个点定义为“平衡点”。这个“平衡点”提供了一个原则性的、可量化的指标,用以衡量我们之前提到的“固有模态偏好”。
其含义是:一个平衡点偏向负值(即视觉更容易)的模型,意味着它具有强烈的固有视觉偏好。因为即使文本模态的确定性显著高于视觉模态(即文本更容易),该模型也仅仅是将其视为“旗鼓相当”(50%概率)。反之,平衡点偏向正值则代表固有的文本偏好。
3. 解释宏观指标
这个“平衡点”框架最终成功解开了前面提到的两个谜题:
为何LLaVA和Qwen2.5-VL在相似的难度感知下,表现出相反的偏好?
答案是:因为它们的固有偏好(即“平衡点”)不同。LLaVA系列模型的平衡点接近于零或为正,呈现中性或文本偏好。而Qwen系列模型则具有明确的负值平衡点,显示出强烈的固有视觉偏好。正是这个在宏观指标下不可见的“固有偏好”差异,驱动了它们最终的决策分歧。
为何Qwen2-VL和Qwen2.5-VL在宏观偏好相似时,其难度感知却相反?
答案是:这揭示了“数据集伪影”。Qwen2-VL的“视觉跟随”在很大程度上是由其强大的视觉能力所驱动的——即它真的觉得视觉更容易。而新的曲线图显示,Qwen2.5-VL的平衡点实际上更偏向视觉(位置更负),这意味着它拥有更强的固有视觉偏好,因为它即使在文本明显更容易的情况下,也依然顽固地信任视觉。
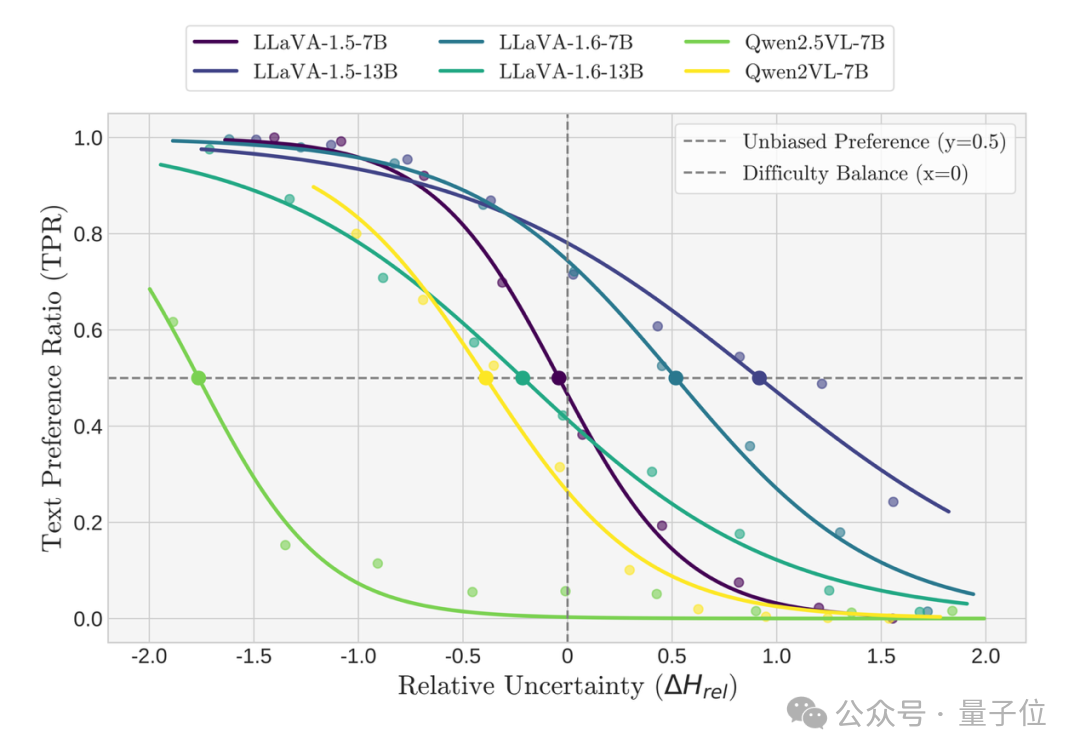
图4a:本文构造的构造数据集上文本跟随占比与相对不确定度分布之间的单调关系。
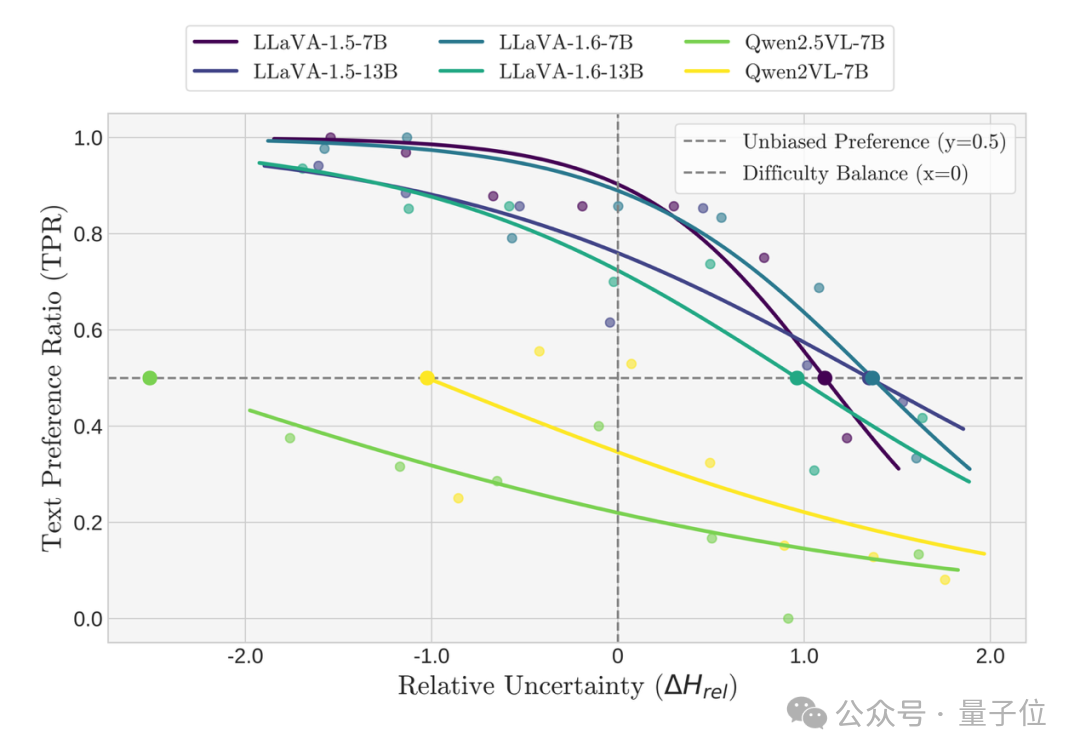
图4b:现有真实数据集mc^2的颜色识别子集上文本跟随占比与相对不确定度分布之间的单调关系。
研究进一步探究了模型内部的决策机制:为何模型在接近其“平衡点”时会表现出犹豫和平均化的选择? 研究者通过采用类似 LogitLens 的技术,逐层探查模型的预测来进行分析。
清晰区域 vs. 模糊区域
研究将输入分为两类:当相对不确定性远离平衡点时,称为“清晰区域”(即一个模态明显更容易);当相对不确定性接近平衡点时,称为“模糊区域”。
内部振荡
研究定义了“振荡”次数,即模型在信息前向传播时,其在各层解码出的最可能预测答案在“文本答案”和“视觉答案”之间切换的次数。
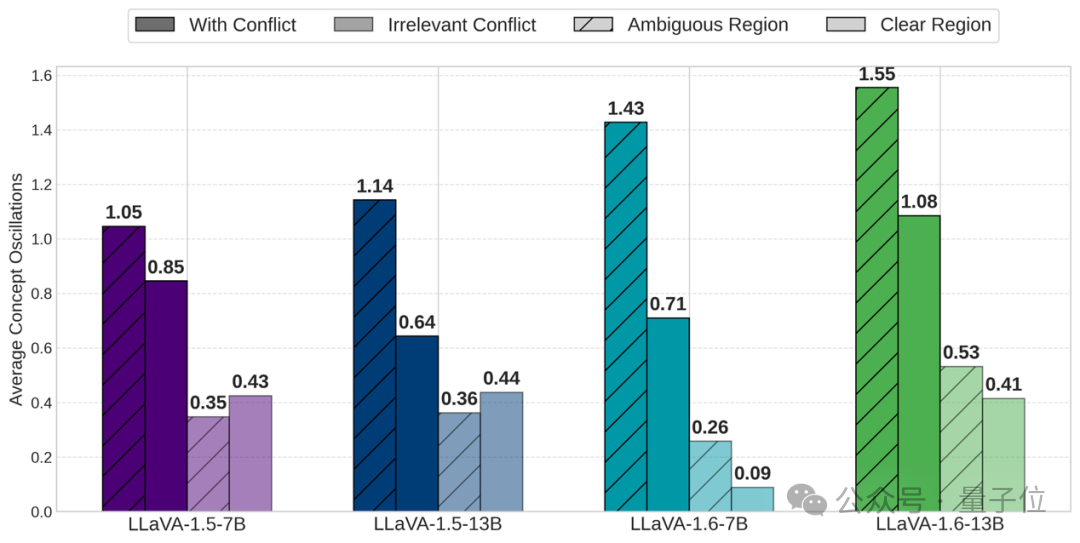
图5:模糊区域(斜线)vs清晰区域(空白),模态输入冲突(深色)vs无关冲突(浅色)对比的平均振荡次数柱状图。
核心发现
如图5所示,在所有模型中,当提问的信息在两个模态输入冲突时,“模糊区域”内的振荡次数显著高于“清晰区域”,且显著高于无关冲突时。说明冲突模态输入的模糊区域的选择摇摆,一定程度来自于这种内部的反复“振荡”,为模型在外部表现出的犹豫不决提供了机制性的解释。进一步的 Logit 差异热图图6也证实了这一点:在清晰区域,模型在浅层就迅速、自信地确定了答案;而在模糊区域,两种冲突答案的置信度差异在多层中都保持在零附近,表明模型处于高度不确定的状态。
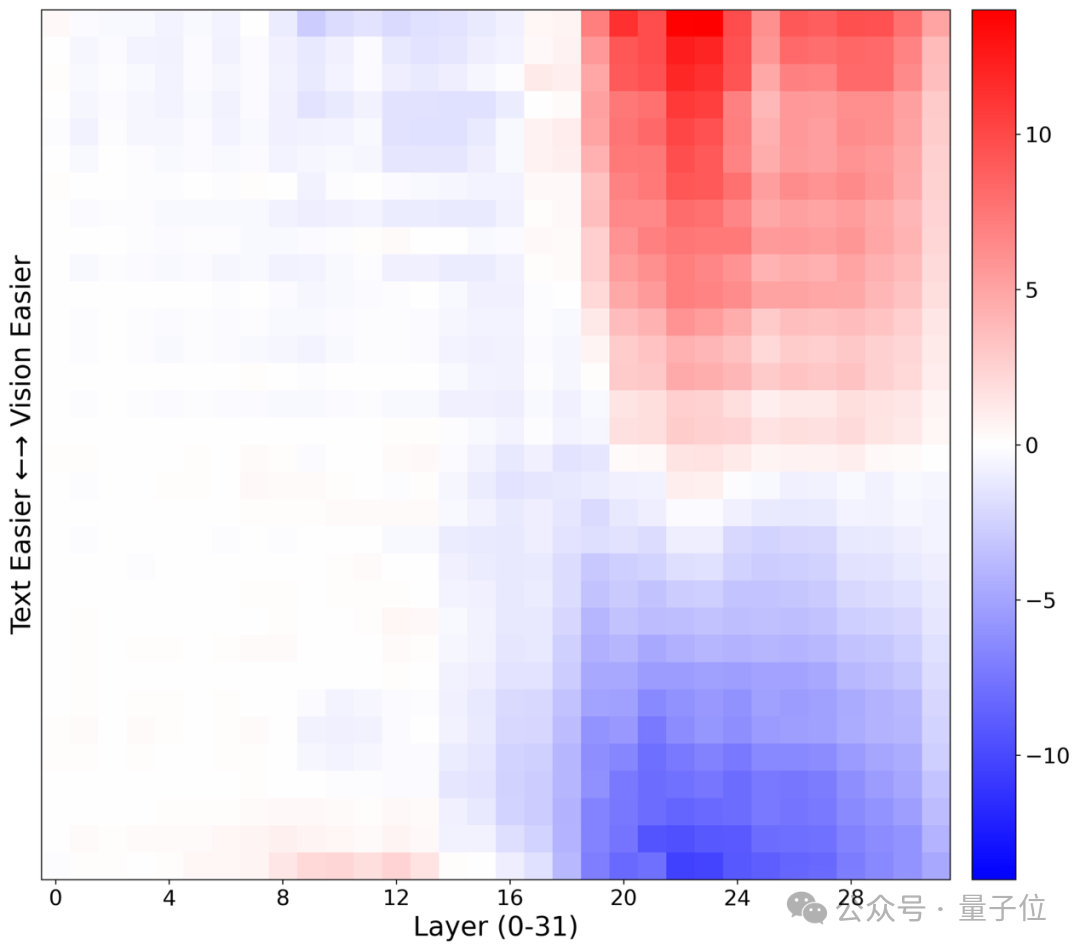
图6:文本模态答案与图像模态答案logits差值。红色代表跟随图像模态信心更强,蓝色代表跟随文本,颜色越浅代表越摇摆,纵轴从下往上文本相对不确定度更高(即更难)。
以往对“模态跟随”的研究依赖于粗粒度的数据集统计,忽视了单模态不确定性差异对结果的影响,并常常将模型的能力与其内在偏见混为一谈。
本文通过提出一个新框架,将模态跟随重新定义为“相对推理不确定性”和“固有模态偏好”共同作用的动态过程。研究揭示了一条稳健的法则:模型跟随一个模态的可能性,会随着其相对不确定性的增加而单调下降。同时,“平衡点”为此固有偏好提供了原则性的度量。
此外,通过揭示模型在模糊区域的内部“振荡”机制,本框架成功地将模型的能力(表现为不确定性)与其偏好(表现为平衡点)分离开来,为理解和改进多模态大语言模型的决策动态提供了更清晰的视角。
论文:https://arxiv.org/abs/2511.02243
文章来自于微信公众号 “量子位”,作者 “量子位”


