# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
最近不论是在学术圈还是产业实践中,对于RLVR和传统SFT之间的区别与联系,以及RL本身基于奖励建模反馈机制并结合不同的策略优化算法过程中对模型显性知识的学习和隐参数空间的变化的讨论热度一直很高。
我想基于当下LLMs所取得的“成功”,也为我们进一步打开模型“黑盒”以探究模型分别对其显性知识学习与隐参数结构变化间的联系和背后的理论机制匹配到了一个适时的研究窗口。
如近期一篇来自meta的论文:「The Path Not Taken: 2RLVR Provably Learns Off the Principals」则尝试对其背后的理论机制进行探索并进行了相关实验验证。

我想这篇论文的核心出发点在于尝试找寻一种来自模型内在原生的参数优化过程中的约束机制,即:“Model-Conditioned Optimization Bias”,以对上述提到的模型隐参数空间与结构的变化或扰动进行探索。同时进一步衍生出了“3-Gate Theory”,即分别从“KL Anchor(KL散度约束)”、“Model Geometry(模型几何结构)”、“Precision(精度过滤)”给出了数学上的理论证明。

不过看起来上述“3-Gate Theory”的理论证明也仅是分别在数学上进行了证明并实验验证,如:① 证明了KL散度<或某些策略优化算法隐含于ratio clipping下的参数约束>对模型ΔW在数学变换上的等价或约束;② 证明依据经典的矩阵扰动理论中小参数更新对保持奇异值分布、曲率方向、模型参数谱结构的数值变化近似约束关系;③ 证明了bfloat16精度下真实数值权重的更新幅度与精度本身所表示的数量级存在的过滤与隐藏现象;
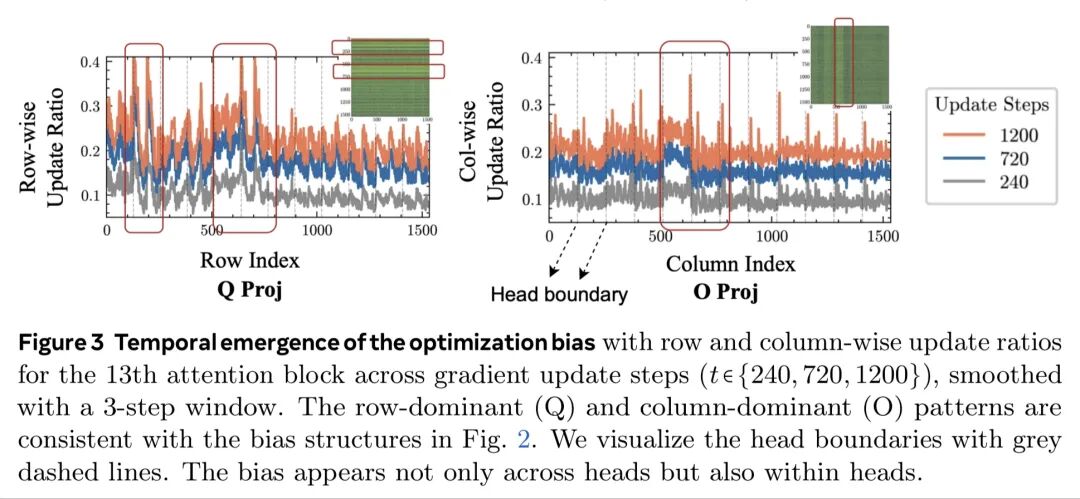
然而这些数学上的证明或实验未能呈现出模型内隐参数结构空间的不同变化幅度或结构性差异对应于模型训练过程中对显性新知识及推理pattern演进的本质关系和底层机制。不过论文还是给出了一个「被牵着绳子的探险家在迷雾山脉寻宝」的形象化解释。
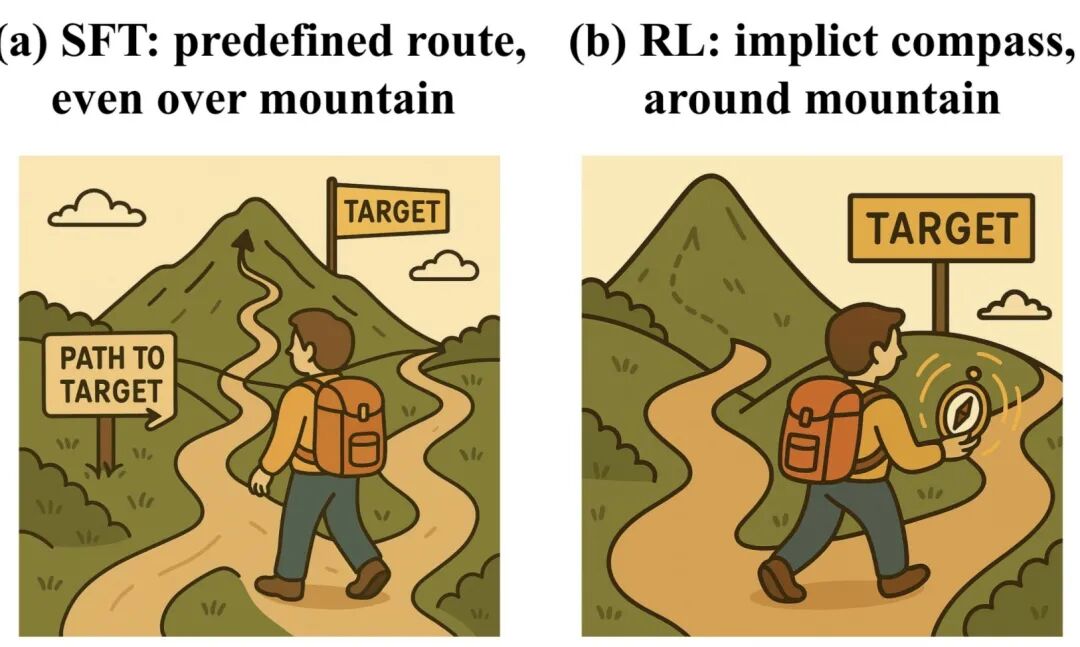
随着RL方法为模型在复杂推理边界扩展带来的价值普世以及研究者们对模型本身在推理pattern空间中持续探索与利用下其隐参数结构演进的探索,围绕RLVR与SFT的热议也逐步打开了模型在不同训练过程背后一些复杂的隐性和显性机制。
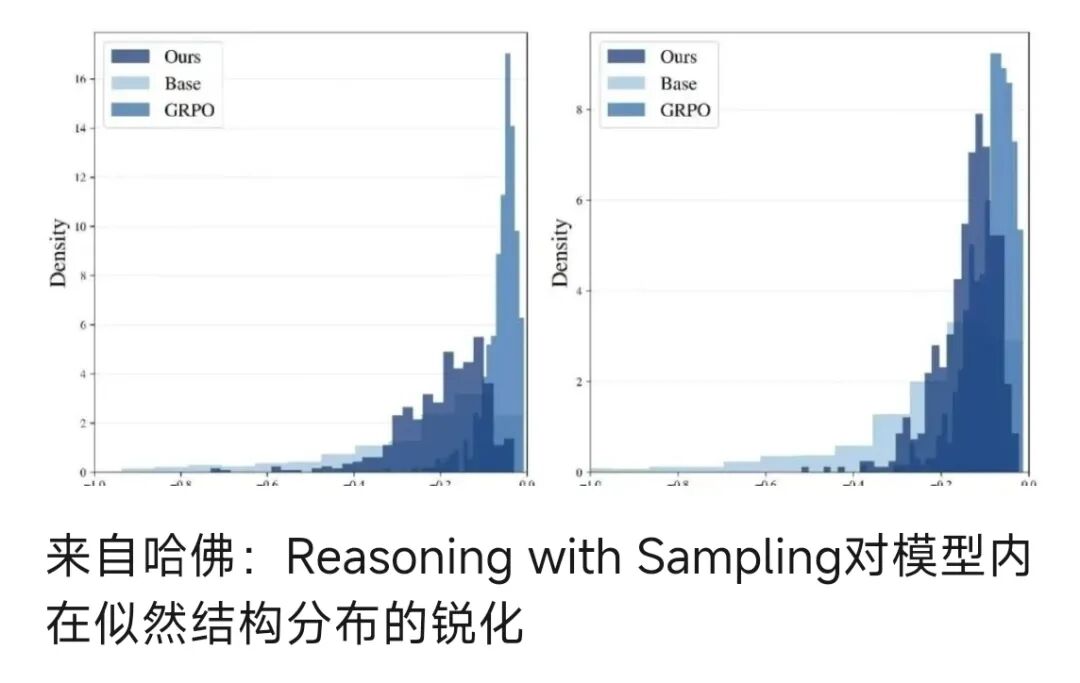
一些论文也都尝试从不同角度进行相关理论证明和实验验证,如上述来自meta的这篇论文以Model-Conditioned Optimization Bias角度出发,以及前不久写的一篇文章对来自哈佛大学「Reasoning with Sampling: Your Base Model is Smarter Than You Think」论文中所阐述的新观点即“仅通过改进推理阶段的采样策略,对基础模型做幂变换以实现等效于RL过程中对模型高似然分布的锐化,从而实现在不依赖任何额外的训练、奖励模型或强化学习,显著提升大语言模型在推理任务上的表现,甚至达到或超越经过强化学习后训练模型的水平”的分析。
不过对于来自哈佛这篇原论文中将「基础模型做幂变换完全等效于RL过程中对模型高似然分布的锐化」这一观点,我还是有着不同的看法,正如原文章所述:我想对于一些更复杂推理路径的探索、反直觉的一些创新以及泛化迁移等方面,结合RL探索与利用的本质还是有着很大本质不同的,也与其它test-time scaling方法有着较大差异,不过这并不失于一种简单高效的方法,也可以作为未来模型对于复杂推理任务或后训练中的数据合成打开一定的思路。
即在探索某些看起来“当前反直觉但后续正确”的潜在长推理路径上,由于这些潜在的正确且突破现有推理模式的推理路径可能在基础模型中似然极低(如反证法、非直观构造、错误路径先验...)幂分布则会天然放大抑制这些路径,从而失去对潜在全局创新pattern的探索和发现,而RL则有“机会”可以通过完备的奖励机制“精准捕捉”并“重点提升”这些路径的似然估计及概率分布,以为持续发现颠覆式的推理pattern埋下一颗种子(就像DS R1 zero出现的aha moment那样),尽管这里未来仍还需要涉及更多复杂的奖励机制和模型训练过程中的诸多策略优化方法的挑战。
详细内容分析请参考原文章:来自哈佛:Reasoning with Sampling对模型内在似然结构分布的锐化
当然在曾经通过对其它诸如TRM从两篇独作论文引出「叠加递归循环→深度推理涌现」到「Attention is NOT All You Need」和HRM探究计算复杂性理论,打破模型浅层结构,重构推理建模范式|来自Hierarchical Reasoning Model的尝试等论文的分析中也会或多或少提及模型内隐参数空间内的结构变化所带来对其显式推理表现的分析和铲屎,这也引发了我进一步针对类似如“Model-Conditioned Optimization Bias”方法从基础模型内的参数化几何结构、到模型自身网络拓扑结构、甚至于不同模型pre-training阶段或不同无监督学习框架所继承并表现出的模型参数矩阵分布差异下衍生的模型内在原生参数优化过程约束偏置机制以及在梯度优化过程中这种无关算法和无关数据的模型自然优化演进主方向的差异。
就像不久前诸多机构对国内“某问”与国外“某驼”在对其同等参数规模pre-training foundation model采用相同的优化算法和数据样本进行rl或distillation post-training并最终展现出模型在梯度优化过程曲线与最终推理性能表现的差异那样...

注:非夹私或刻意商业引导,图片来自网络:)
相信未来随着对模型内隐参数结构的进一步研究探索,也许我们不仅需在pre-training → post-training间甚至在对不同模型网络拓扑结构以及模型在更细粒度的不同预训练阶段、采用不同算法和数据分布下去更进一步的探究这种源自于模型内隐参数结构下的优化演进偏置机制。
另一方面,除了对上述“源自模型内隐参数结构下的优化演进偏置机制”的持续探索外,我想也有必要建立起从模型内到外所对应的“显式知识学习与推理泛化能力演进”下的全局研究视角。如:
在不同模型网络结构下,采用相同训练算法和数据样本,探究并对比不同模型内隐参数几何分布与模型外显式的对上下文遵循、新知识更新及推理泛化等的映射关系。
对同一模型网络结构采用不同无监督/有监督学习策略所呈现的不同参数权重分布下,模型对显性知识学习、数据结构(如语言结构)泛化(压缩)的差异化表现研究。
甚至我想需要持续建立并逐步探索对“知识”、“推理”、“泛化”等模型外在的这些显性本质内涵和结构,与对应模型内在latent space结构间的态射关系与机制的研究,从而尝试去逐步探明诸如SFT下的catastrophic forgetting,overfitting,underfitting等内涵;不同PEFT方法对模型结构、反向传播优化策略的影响;基础模型与推理模型内外隐性与显性表现结构下的认知流形分布所呈现出的本质...从而更进一步加深我们对模型在不同阶段“学习什么”、“如何推理”、“泛化的本质”上的理解与洞察。
在这里也顺带为大家推荐一下自己曾经写的一篇文章解读大型推理模型的 “思维奥秘”:从“推理图”视角看模型的「啊哈时刻」中对外部真实世界显性的复杂思维链(如 CoT 或 long reasoning pattern)与模型内部隐空间(Latent Space)统一看待视角,并提出过的一个观点:不论模型经过何种ground truth有信号监督还是 RL(强化学习)自探索反馈训练方法,其外部任何显式的step by step next token predict所隐含于其中的规划、分解、反思等抽象pattern,都能在模型内隐状态空间中找到神经元激活pattern的某种映射。这种映射或许就像文中所提及到的一篇论文中的 “推理图”或“拓扑环”,亦或是其他隐状态空间可视化方法,而这也许就是模型具备系统2慢思考能力的奥秘。
另外,在去年9月份OpenAI o1模型发布不久甚至更早时,当时写的一篇文章OpenAI o1碎片化推理过程中的探索与利用的泛化中,曾尝试对system2·慢思考模型的推理泛化进行“碎片化知识流形拼接”并提出“泛化集合”的解释,但始终未曾找到更好的数学形式解释,也许未来随着对模型显性知识学习和隐参数空间结构的进一步规律探索,我们将发现对模型“知识”、“推理”、“泛化”等更本质的数学解释与完备的理论研究体系,下面列出了自己曾经对这一领域更多早期不成熟的探索与思考记录,大伙有兴趣可以回顾:
文章来自于“塔罗烩”,作者 “吕明”。


【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
