# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
该团队的新模型在多个基准测试中都与 Gemini Pro 、GPT-3.5 相媲美。
如果你经常读 AI 大模型方向的论文,Yi Tay 想必是一个熟悉的名字。作为前谷歌大脑高级研究科学家,Yi Tay 为许多知名的大型语言模型和多模态模型做出了贡献,包括 PaLM、UL2、Flan-U-PaLM、LaMDA/Bard、ViT-22B、PaLI、MUM 等。
根据 Yi Tay 个人资料统计,在谷歌大脑工作的 3 年多的时间里,他总共参与撰写了大约 45 篇论文,是其中 16 篇的一作。一作论文包括 UL2、U-PaLM、DSI、Synthesizer、Charformer 和 Long Range Arena 等。
和大多数离开谷歌自主创业的 Transformer 作者一样,Yi Tay 在去年 3 月份宣布离开谷歌,并参与创办了一家名为 Reka 的公司,Yi Tay 担任该公司的首席科学家,主攻大型语言模型。
随着时间的推移,刚刚,Yi Tay 宣布他们发布了新模型:
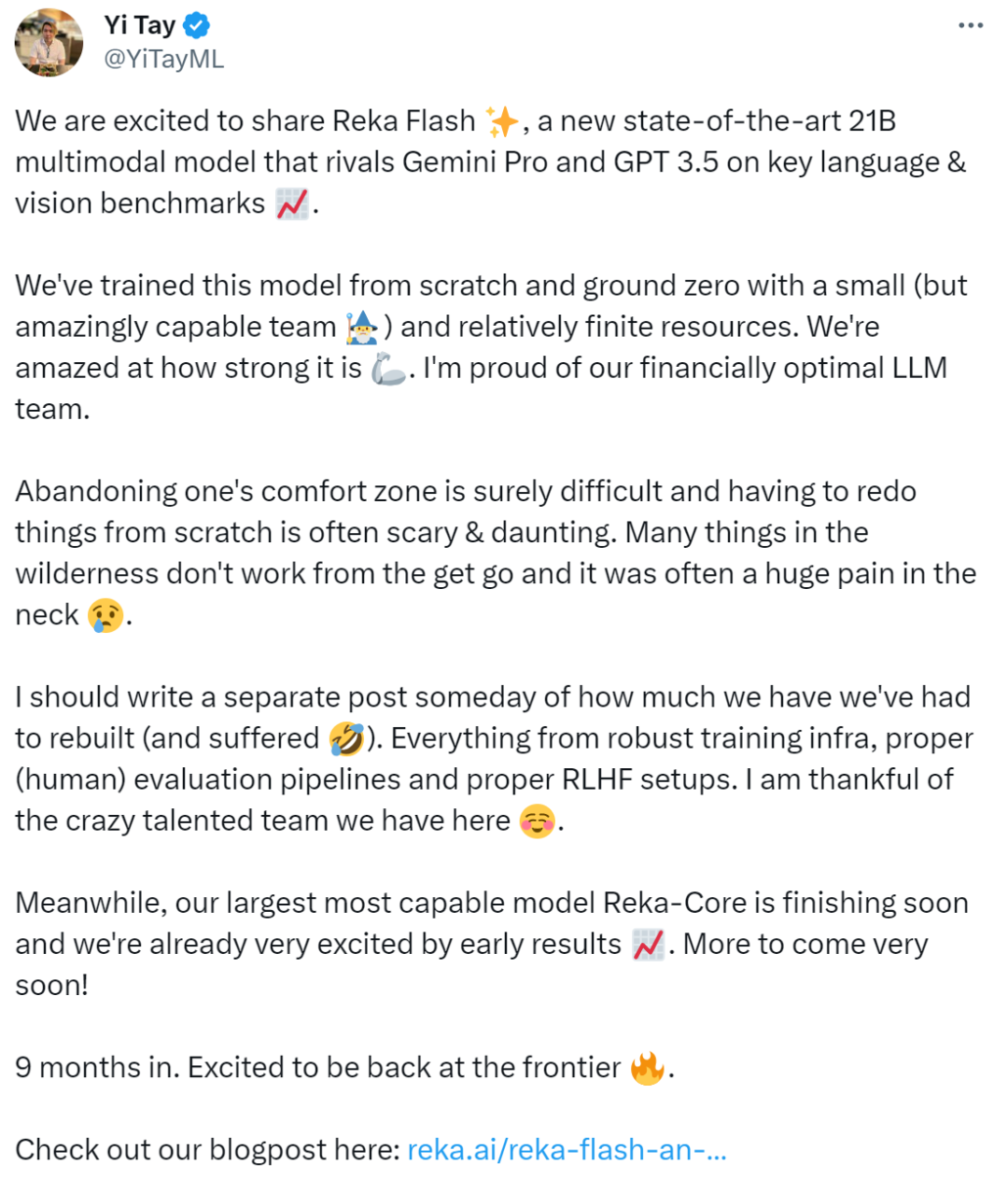
「很高兴与大家分享 Reka Flash,这是一种具有 SOTA 性能的、全新的 21B 多模态模型,该模型在语言和视觉基准方面可与 Gemini Pro 和 GPT 3.5 相媲美。我们用相对有限的资源从零开始训练这个模型…… 与此同时,我们规模最大、功能最强的模型 Reka-Core 也即将完成,大家可以对我们接下来的工作期待一下。」
Reka Flash 参数量为 21B,完全从头开始训练,其性能可与更大规模的模型相媲美,在众多语言和视觉基准测试中,Reka Flash 与 Gemini Pro 和 GPT-3.5 具有竞争力。
此外, Reka 团队还提出了一个更紧凑的模型变体 Reka Edge,该模型参数量更少,只有 7B,并且效率更高,使其在资源受限(例如,在设备上、本地)的场景下也能运行。
值得一提的是,这两种模型均处于公开测试阶段,感兴趣的读者可以前去尝试。
试用地址:https://chat.reka.ai/auth/login
与此同时,Reka 团队宣布他们最大、功能最强的 Reka Core 模型将在未来几周内向公众推出。
至于开源问题,该团队表示还在考虑当中。
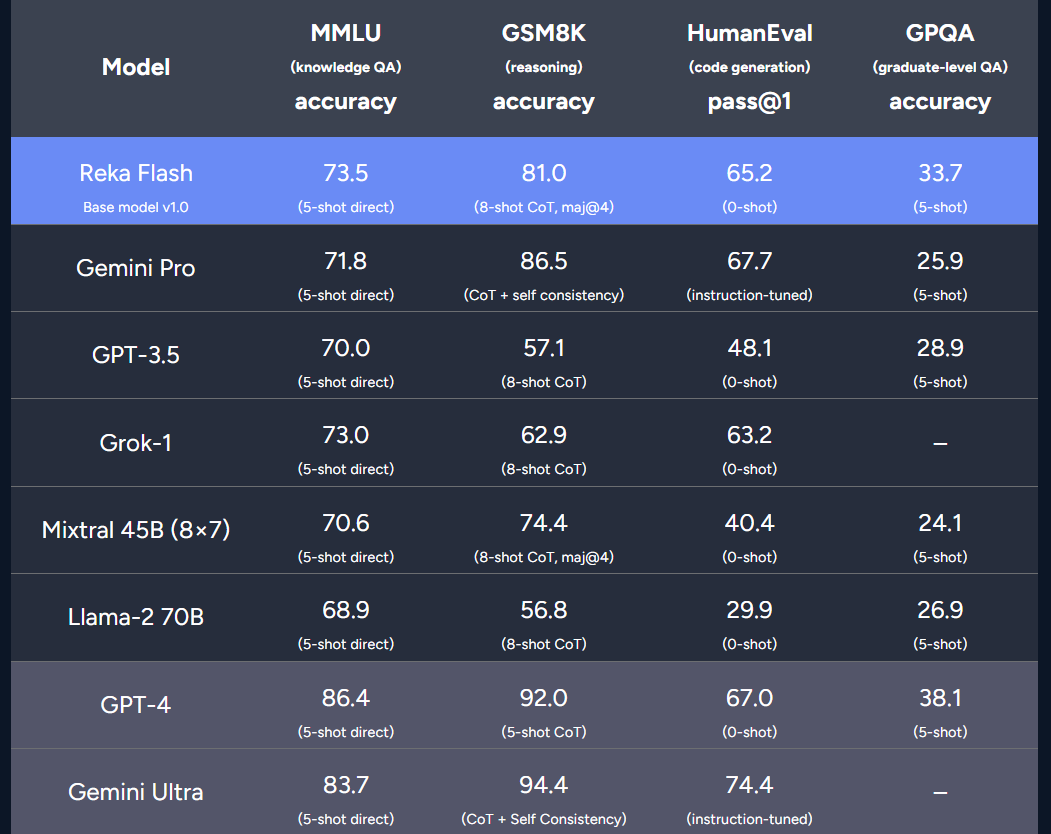
评估:语言
评估基准包括 MMLU(基于知识的问答)、GSM8K(推理和数学)、HumanEval(代码生成)和 GPQA(Google-proof graduate-level question answering)。
结果显示,Reka Flash 在这些基准测试中取得了非常出色的成绩:在 MMLU 和 GPQA 上优于 Gemini Pro,在 GSM8K 和 HumanEval 上取得了具有竞争力的结果。此外,在这些评估中,Reka Flash 明显优于许多较大的模型(例如 Llama 2 70B、Grok-1、GPT-3.5)。
评估:多语言推理
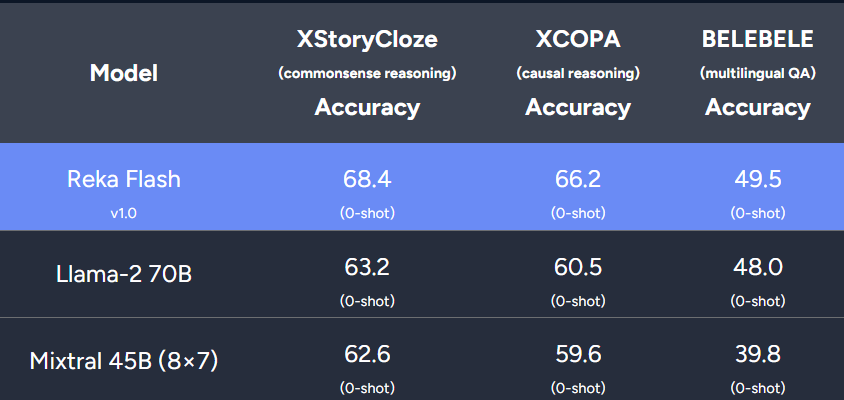
Reka Flash 在超过 32 种语言(包括英语,德语,中文,日语,法语,韩语,西班牙语,意大利语,阿拉伯语等)的文本上进行了预训练,因此 Reka Flash 可以看做是一个强大的多语言模型。研究者比较了不同模型在多语言基准上的性能,包括多语言常识推理、因果推理和问答。结果表明,Reka Flash 在所有这些任务上均优于 Llama-2 70B 和 Mixtral。
评估:视觉和视频
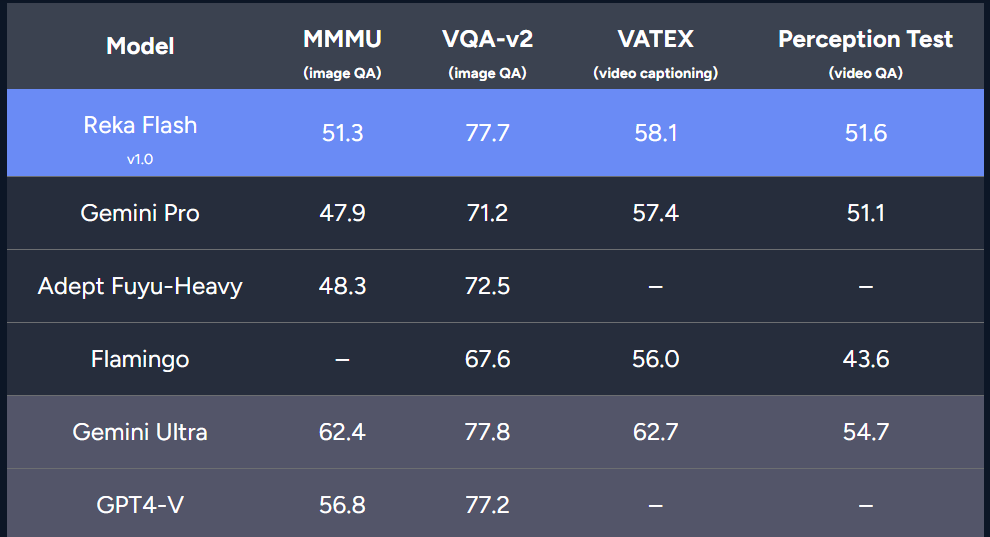
此外,该研究还在多模态基准上对 Reka Flash 进行了评估,包括视觉问答(MMMU、VQA-v2)、视频字幕(VATEX)和视频问答(Perception Test)。结果表明 Reka Flash 在所有四个基准测试中都比 Gemini Pro 具有竞争力。
该研究还进行了一系列人工评估来评估基于 Reka Flash 的聊天模型。研究者考虑了两种设置,1)纯文本聊天模型和 2)多模态聊天模型。评估过程中他们按照 Askell 等人的方法计算 ELO 分数和总体胜率。
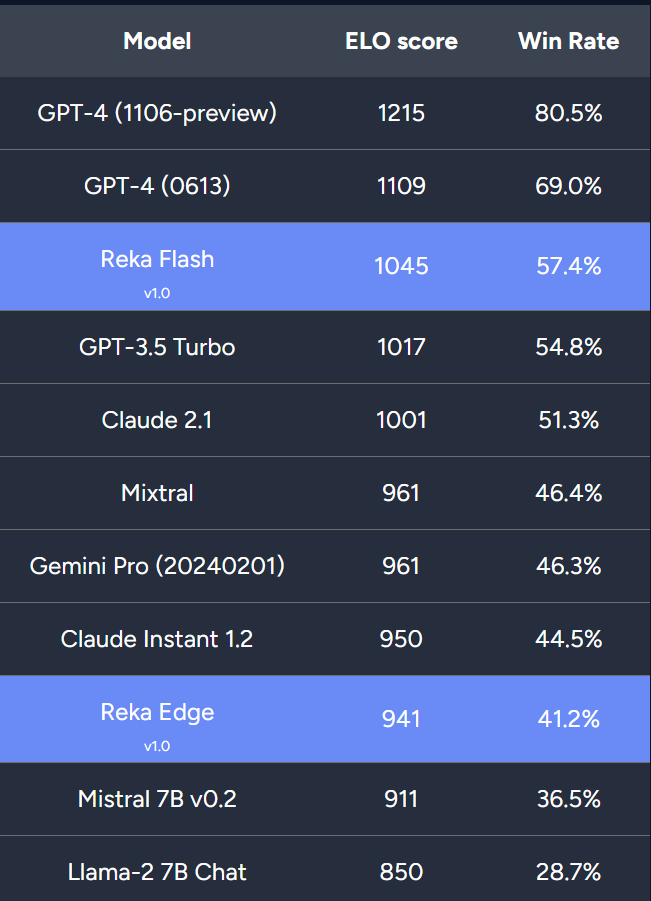
纯文本聊天:研究者以 GPT-4、Claude 2.1 和 Gemini Pro(API 版本)等领先模型为基准。此外研究者还比较了 Reka Edge、Mistral 7B 和 Llama 2 7B 聊天模型的性能。
人工评估结果表明,Reka Flash 取得了具有竞争力的结果,优于 GPT-3.5 Turbo、Claude、Mixtral 和 Gemini Pro。Reka Edge 领先于另外两款 7B 模型,接近 Claude Instant 1.2 的性能。
评估:多模态
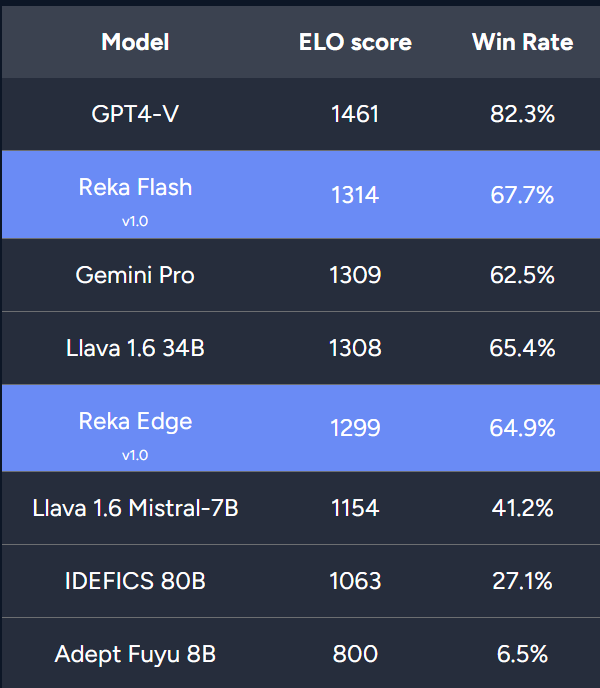
该研究还将 Reka Flash 与 GPT4-V、Gemini Pro、Llava-1.6、IDEFICS 80b 和 Adept Fuyu-8B 等多模态语言模型进行了比较。结果表明,Reka Flash 的性能优于除 GPT4-V 之外的所有模型。Reka Edge 也取得了不错的排名,超越了基于 Mistral 7B 的 Llava 1.6 7B,并接近 Gemini Pro 的性能。
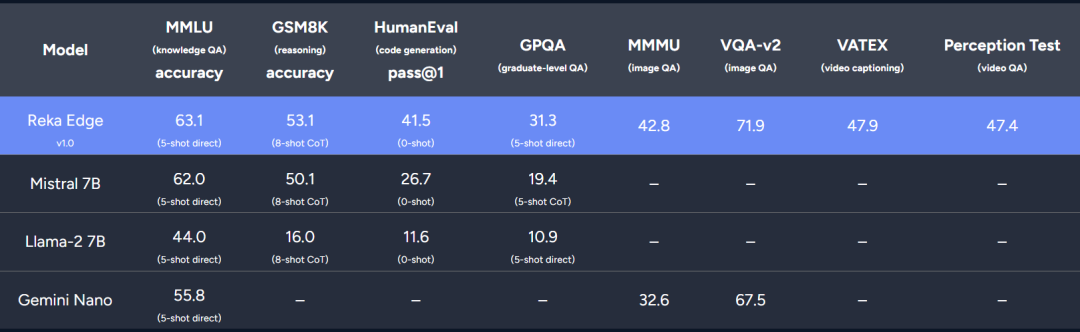
7B 参数的 Reka Edge 模型
Reka Edge 是更为紧凑的 7B 模型,专为本地部署和延迟敏感应用程序而设计。在语言评估任务上,该研究报告了其与类似规模模型(即 Mistral 7B 和 Llama-2 7B)的比较。结果表明,Reka Edge 在标准语言基准测试中优于 Llama 2 7B 和 Mistral 7B。
总结
Reka 团队表示他们旨在构建最先进的多模态语言模型,随着 Reka Flash 和 Reka Edge 的发布,他们 AI 蓝图中的最初里程碑已经实现。大家可以期待他们接下来的研究。
参考链接:https://reka.ai/reka-flash-an-efficient-and-capable-multimodal-language-model/



