
吴恩达Agentic AI新课:手把手教你搭建Agent工作流,GPT-3.5反杀GPT-4就顺手的事
吴恩达Agentic AI新课:手把手教你搭建Agent工作流,GPT-3.5反杀GPT-4就顺手的事吴恩达又出新课了,这次的主题是—Agentic AI。 在新课中,吴恩达将Agentic工作流的开发沉淀为四大核心设计模式:反思、工具、规划与协作,并首次强调评估与误差分析才是智能体开发的决定性能力:
来自主题: AI资讯
11696 点击 2025-10-13 11:54
 搜索
搜索
吴恩达又出新课了,这次的主题是—Agentic AI。 在新课中,吴恩达将Agentic工作流的开发沉淀为四大核心设计模式:反思、工具、规划与协作,并首次强调评估与误差分析才是智能体开发的决定性能力:
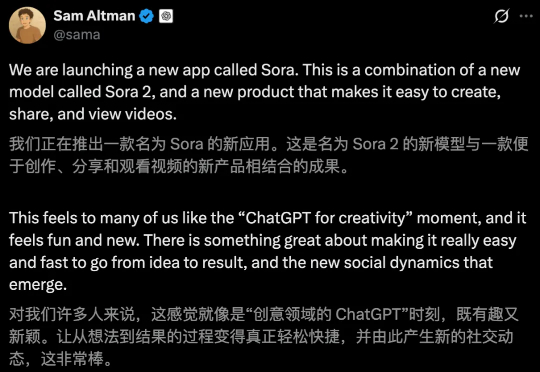
凌晨1点,OpenAI突然扔出Sora 2核弹,AI视频迎来「GPT-3.5时刻」!一大批惊艳Demo放出,物理智能提升一大截,首次实现音画同步,人物一致性、可控性刷新SOTA。但最绝的还是Sora App,它的问世,或将彻底重塑短视频社交媒体的交互逻辑与社区互动方式。

从「与GPT-3.5畅聊」到「ChatGPT」,OpenAI团队如何在混乱中拍板上线、又怎样被用户「点赞」调教成「赛博舔狗」?从产品发布、命名内幕、团队文化到AI时代核心竞争力,深度访谈揭开幕后全过程!

今天凌晨,Runway的新版本Gen-4又试图解决AI视频的一个关键难题,让AI视频更靠近电影级。这一切都只发生在短短的2个多月内,很难想象今年AI会发展到什么程度,或许今年将会是GPT-3.5后真正的AI爆发年。

你敢相信 4B 参数小模型,性能却超越千亿量级的 GPT-3.5 !OpenAI、谷歌、微软、苹果等一众海内外巨头还没做到的事,被一家中国大模型公司抢先了!

长文本处理能力对LLM的重要性是显而易见的。在2023年初,即便是当时最先进的GPT-3.5,其上下文长度也仅限于2k,然而今日,128k的上下文长度已经成为衡量模型技术先进性的重要标志之一。那你知道LLMs的长文本阅读能力如何评估吗?

今年 6 月底,谷歌开源了 9B、27B 版 Gemma 2 模型系列,并且自亮相以来,27B 版本迅速成为了大模型竞技场 LMSYS Chatbot Arena 中排名最高的开放模型之一,在真实对话任务中比其两倍规模以上的模型表现还要好。

谷歌DeepMind的小模型核弹来了,Gemma 2 2B直接击败了参数大几个数量级的GPT-3.5和Mixtral 8x7B!而同时发布的Gemma Scope,如显微镜一般打破LLM黑箱,让我们看清Gemma 2是如何决策的。

GPT-4o mini白菜价!10家同行PK,谁能与OpenAI对打?

今天,全网都知道 OpenAI 发现货了!