# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
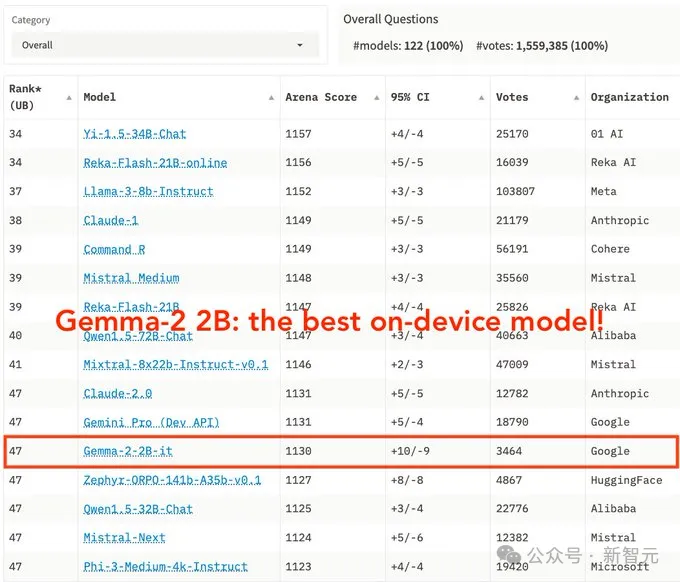
谷歌DeepMind的小模型,又上新了!
就在刚刚,谷歌DeepMind发布Gemma 2 2B。


它是从Gemma 2 27B中蒸馏而来。
虽然它的参数只有2.6B,但在LMSYS竞技场上的得分,已经超越了GPT-3.5和Mixtral 8x7B!
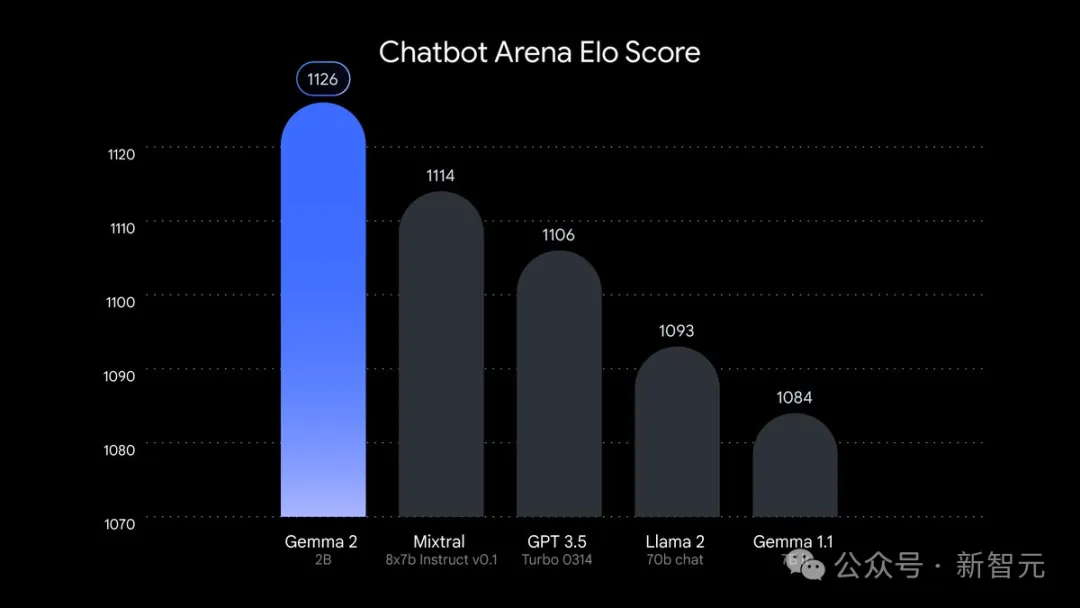
在MMLU和MBPP基准测试中,它分别取得了56.1和36.6的优异成绩;比起前代模型Gemma 1 2B,它的性能超过了10%。
小模型击败了大几个数量级的大模型,再一次印证了最近业界非常看好的小模型方向。
谷歌在今天,一共公布了Gemma 2家族的三个新成员:
6月,27B和9B Gemma 2模型诞生。
自发布以来,27B模型迅速成为大模型排行榜上,排名前列的开源模型之一,甚至在实际对话中表现超过了参数数量大两倍的流行模型。
Gemma 2 2B:即刻在设备上使用
轻量级小模型Gemma 2 2B,是从大模型中蒸馏而来,性能毫不逊色。
在大模型竞技场LMSYS上,新模型取得令人印象深刻的1130分,与10倍参数的模型不相上下。
GPT-3.5-Turbo-0613得分为1117,Mixtral-8x7b得分为1114。
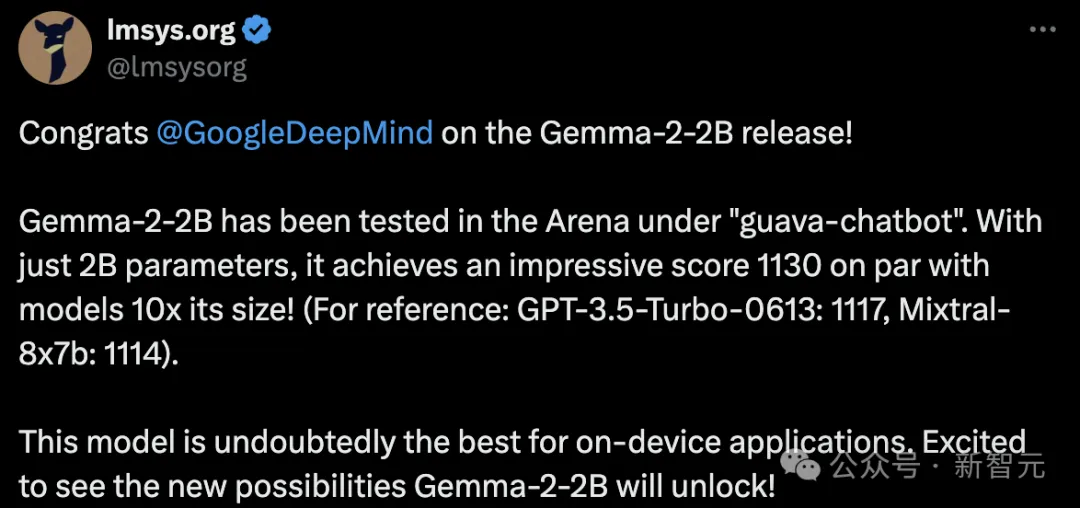
足见,Gemma 2 2B是最好的端侧模型。
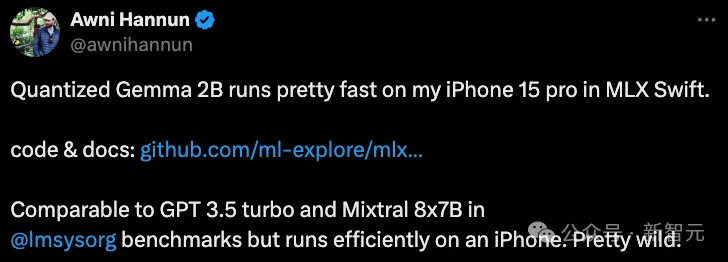
有网友在iPhone 15 Pro上,让量化后的Gemma 2 2B在MLX Swift上运行,速度快到惊人。
具体来说,它能够在各种终端设备,包括手机、笔记本,甚至是使用Vertex AI和Google Kubernetes Engine(GKE)强大的云,皆能完成部署。
为了让模型加速,它通过NVIDIA TensorRT-LLM完成了优化,在NVIDIA NIM平台也可使用。
优化后的模型适用于各种平台部署,包括数据中心、云、本地工作站、PC 和边缘设备。
它还可以支持RTX、RTX GPU、Jetson模块,完成边缘化AI部署。
此外,Gemma 2 2B无缝集成了Keras、JAX、Hugging Face、NVIDIA NeMo、Ollama、Gemma.cpp等,并很快将与MediaPipe集成,实现简化开发。

当然,与Gemma 2一样,2B模型也同样可以用来研究和商用。
甚至,由于其参数量足够下,它可以在Google Colab的免费T4 GPU层上运行,降低了开发门槛。
目前,每位开发者都可以从Kaggle、Hugging Face、Vertex AI Model Garden下载Gemma 2的模型权重,也可在Google AI Studio中试用其功能。
仓库地址:https://huggingface.co/collections/google/gemma-2-2b-release-66a20f3796a2ff2a7c76f98f
ShieldGemma:最先进的安全分类器
正如其名,ShieldGemma是最先进的安全分类器,确保AI输出内容具有吸引力、安全、包容,检测和减少有害内容输出。
ShieldGemma的设计专门针对四个关键的有害领域:
- 仇恨言论
- 骚扰内容
- 露骨内容
- 危险内容
这些开源分类器,是对谷歌现有的负责任AI工具包中安全分类器套件补充。
该工具包包括一种,基于有限数据点构建针对特定策略分类器的方法,以及通过API提供的现成Google Cloud分类器。
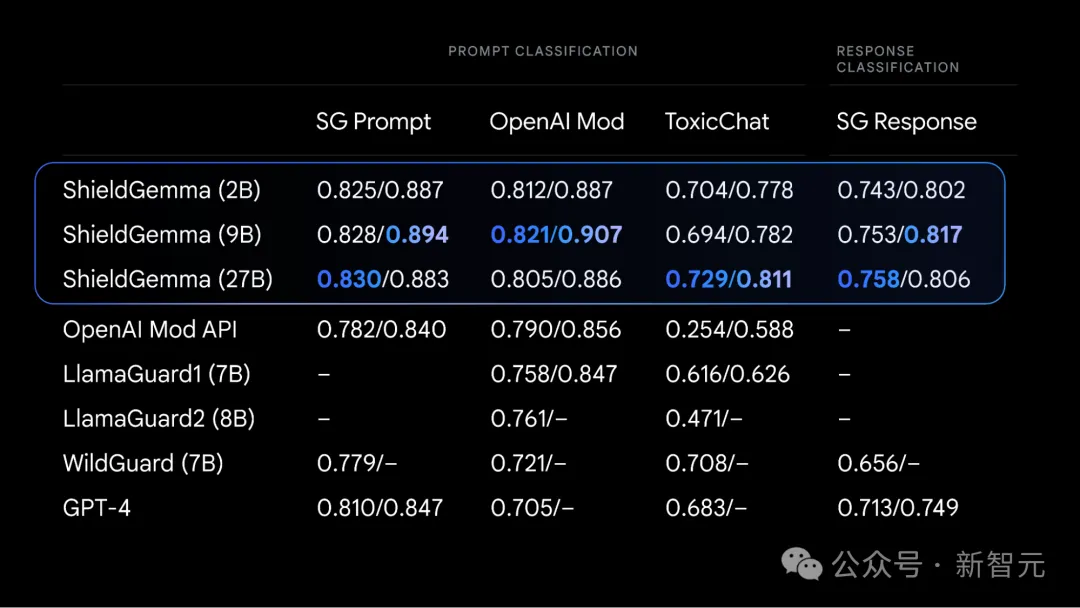
ShieldGemma基于Gemma 2构建,是行业领先的安全分类器。
它提供了各种模型参数规模,包括2B、9B、27B,都经过英伟达速度优化,在各种硬件中可以高效运行。
其中,2B非常适合在线分类任务,而9B和27B版本则为对延迟要求较低的离线应用提供更高性能。
Gemma Scope:通过开源稀疏自编码器揭示AI决策过程
此次同时发布的另一大亮点,就是开源稀疏自编码器——Gemma Scope了。
语言模型的内部,究竟发生了什么?长久以来,这个问题一直困扰着研究人员和开发者。
语言模型的内部运作方式往往是一个谜,即使对于训练它们的研究人员,也是如此。

而Gemma Scope就仿佛一个强大的显微镜,通过稀疏自编码器 (SAEs) 放大模型中的特定点,从而使模型的内部工作更易于解释。
有了Gemma Scope以后,研究人员和开发者就获得了前所未有的透明度,能够深入了解Gemma 2模型的决策过程。
Gemma Scope是数百个适用于Gemma 2 9B和Gemma 2 2B的免费开放稀疏自动编码器 (SAE) 的集合。
这些SAEs是专门设计的神经网络,可以帮助我们解读由Gemma 2处理的密集、复杂信息,将其扩展成更易于分析和理解的形式。
通过研究这些扩展视图,研究人员就可以获得宝贵的信息,了解Gemma 2如何识别模式、处理信息、做出预测。
有了Gemma Scope,AI社区就可以更容易地构建更易理解、负责任和可靠的AI系统了。
同时,谷歌DeepMind还放出了一份20页的技术报告。

技术报告:https://storage.googleapis.com/gemma-scope/gemma-scope-report.pdf
总结来说, Gemma Scope有以下3个创新点——
解读语言模型内部的运作机制
语言模型的可解释性问题,为什么这么难?
这要从LLM的运行原理说起。
当你向LLM提出问题时,它会将你的文本输入转换为一系列「激活」。这些激活映射了你输入的词语之间的关系,帮助模型在不同词语之间建立联系,据此生成答案。
在模型处理文本输入的过程中,模型神经网络中不同层的激活代表了多个逐步高级的概念,这些概念被称为「特征」。
例如,模型的早期层可能会学习到像乔丹打篮球这样的事实,而后期层可能会识别出更复杂的概念,例如文本的真实性。

用稀疏自编码器解读模型激活的示例——模型是如何回忆「光之城是巴黎」这一事实的。可以看到与法语相关的概念存在,而无关的概念则不存在
然而,可解释性研究人员却一直面临着一个关键问题:模型的激活,是许多不同特征的混合物。
在研究的早期,研究人员希望神经网络激活中的特征能与单个神经元(即信息节点)对齐。
但不幸的是,在实践中,神经元对许多无关特征都很活跃。
这也就意味着,没有什么明显的方法,能判断出哪些特征是激活的一部分。
而这,恰恰就是稀疏自编码器的用武之地。
要知道,一个特定的激活只会是少数特征的混合,尽管语言模型可能能够检测到数百万甚至数十亿个特征(也就是说,模型是稀疏地使用特征)。
例如,语言模型在回答关于爱因斯坦的问题时会想到相对论,而在写关于煎蛋卷时会想到鸡蛋,但在写煎蛋卷时,可能就不会想到相对论了。

稀疏自编码器就是利用了这一事实,来发现一组潜在的特征,并将每个激活分解为少数几个特征。
研究人员希望,稀疏自编码器完成这项任务的最佳方式,就是找到语言模型实际使用的基本特征。
重要的是,在这个过程中,研究人员并不会告诉稀疏自编码器要寻找哪些特征。
因此,他们就能发现此前未曾预料过的丰富结构。
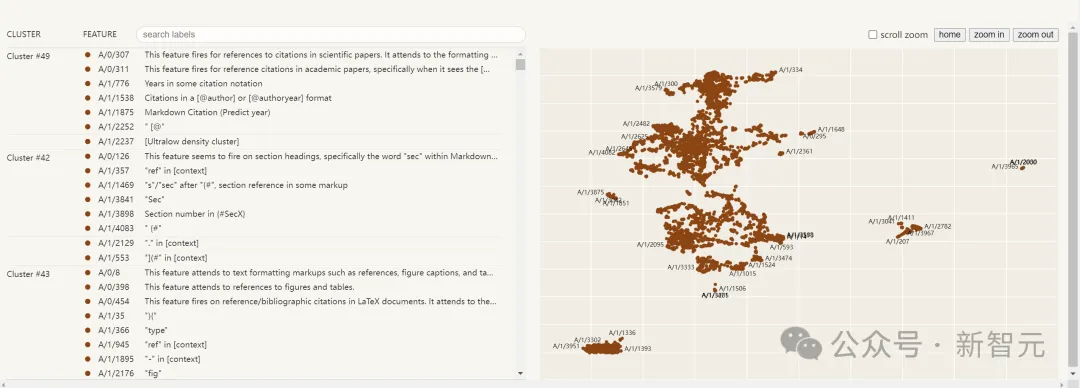
然而,因为他们无法立即知道这些被发现特征的确切含义,他们就会在稀疏自编码器认为特征「触发」的文本示例中,寻找有意义的模式。

以下是一个示例,其中根据特征触发的强度,用蓝色渐变高亮显示了特征触发的 Token:

用稀疏自编码器发现特征激活的示例。每个气泡代表一个 Token(单词或词片段),可变的蓝色说明了这个特征的存在强度。在这个例子中,该特征显然与成语有关
比起此前的稀疏自编码器,Gemma Scope有许多独特之处。
前者主要集中在研究小型模型的内部工作原理或大型模型的单层。
但如果要把可解释性研究做得更深,就涉及到了解码大型模型中的分层复杂算法。
这一次,谷歌DeepMind的研究者在Gemma 2 2B和9B的每一层和子层的输出上,都训练了稀疏自编码器。
这样构建出来的Gemma Scope,总共生成了超过400个稀疏自编码器,获得了超过 3000万个特征(尽管许多特征可能重叠)。
这样,研究人员就能够研究特征在整个模型中的演变方式,以及它们如何相互作用,如何组合形成更复杂的特征。
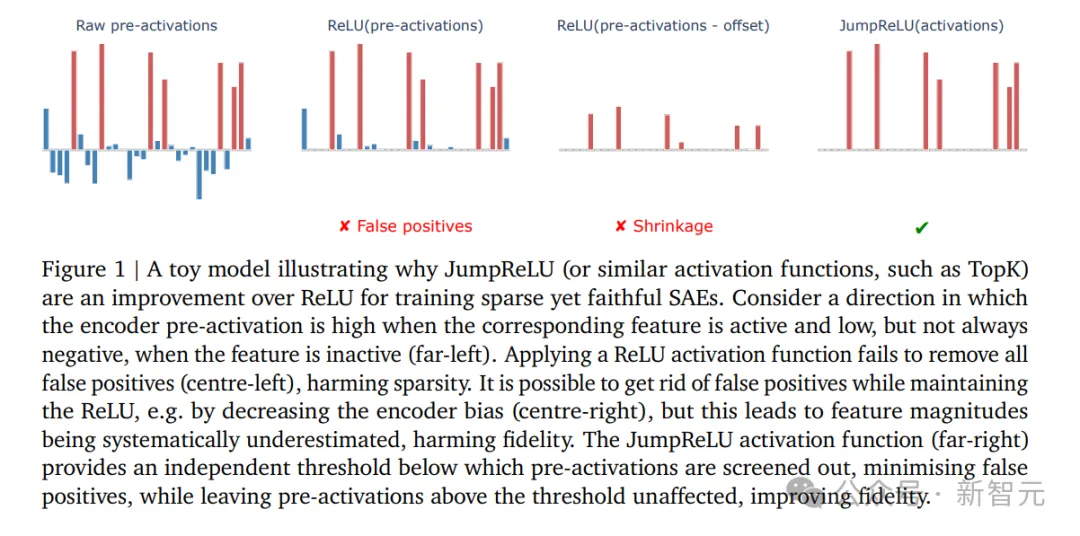
此外,Gemma Scope使用了最新的、最先进的JumpReLU SAE架构进行了训练。
原始的稀疏自编码器架构,在检测特征存在与估计强度这两个目标之间,往往难以平衡。而JumpReLU架构,就能更容易地实现二者的平衡,并且显著减少误差。
当然,训练如此多的稀疏自编码器,也是一项重大的工程挑战,需要大量的计算资源。
在这个过程中,研究者使用了Gemma 2 9B训练计算量的约15%(不包括生成蒸馏标签所需的计算),将约20 PiB的激活保存到了磁盘(大约相当于一百万份英文维基百科的内容),总共生成了数千亿个稀疏自编码器参数。
文章来源于“新智元”,作者“新智元”



