# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在人工智能快速发展的今天,大语言模型已经深入到我们工作和生活的方方面面。然而,如何让AI生成的内容更加可信、可追溯, 一直是学术界和工业界关注的焦点问题。想象一下,当你向ChatGPT提问时,它不仅给出答案,还能像学术论文一样标注每句话的信息来源——这就是"溯源大语言模型"要解决的核心问题。
北邮百家AI团队联合小米大模型团队提出的溯源大模型C²-Cite,首创上下文感知的归因生成技术,不仅能让大模型在生成内容时自动标注精准的信息来源,更能确保生成内容与引用的外部知识高度语义对齐,实现每一处表述都有溯源依据、与参考来源深度协同,从根本上解决大模型生成内容的可信度问题。该工作已被国际顶级会议WSDM 2026收录。C²-Cite针对现有归因模型存在的关键缺陷, 通过引入"上下文感知"机制, 让引用标记从被动的占位符转变为带有上下文语义的特殊令牌, 显著提升了引用质量和模型回答准确性。

C²-Cite:Contextual-Aware Citation Generation for Attributed Large Language Models
https://github.com/BAI-LAB/c2cite/blob/main/paper_wsdm_c2cite.pdf
https://github.com/BAI-LAB/c2cite
在信息爆炸的时代,大语言模型虽然能够生成流畅的文本,但"幻觉"问题(即生成虚假或不准确的内容)始终困扰着研究者。为了增强模型输出的可信度,研究人员提出了归因技术——在生成内容中添加明确的引用标记(如[1]、[2]),将每句话链接到具体的信息源。然而现有归因模型存在显著缺陷:
1.技术路径存在固有局限:上下文学习归因(P-ICL/I-ICL)依赖提示工程或迭代检索,耗时且泛化性弱;指令微调归因过度依赖高质量训练数据,缺乏对引用上下文的主动关联,大大削弱大模型的溯源能力;事后归因(Post-Hoc)采用两阶段处理,难以精确到句子级别,缺乏内在归因能力。
2.引用标记沦为“通用占位符”:现有模型未赋予引用标记(如 [i])上下文语义,仅将其视为无意义符号,导致引用与所指内容脱节、知识整合效果差;
3.引用质量与回答准确性失衡:部分模型虽能提升引用精准度,但会破坏回答的语义连贯性和正确性;另一部分模型则因引用混乱,难以支撑回答可信度;
这些问题导致现有模型要么引用错误 / 虚构、溯源失效,要么回答逻辑断裂、准确性下滑,难以同时满足 “引用可信” 与 “回答有效” 的核心需求。
为解决上述缺陷,北邮百家AI团队联合小米提出上下文感知的溯源大模型框架(C²-Cite),核心思路是通过“上下文语义融入” 让引用标记从被动占位符转变为带有明确语义指向的主动知识指针,具体包含三大关键组件:
1.上下文感知嵌入机制(Contextual-Aware Embedding):将多令牌引用标记(如“[i]”)标准化为单一引用符号令牌(如“<cᵢ>”),并通过均值池化计算对应检索文档的语义嵌入,替换传统无意义占位符嵌入,使引用标记携带所指文档的语义信息;
2.上下文引用对齐机制Contextual Citation Alignment:引入引用路由器(二进制分类器)区分默认令牌与引用令牌,分别优化两类令牌的损失函数—— 默认令牌采用交叉熵损失保证回答流畅性,引用令牌通过语义相似度匹配实现与检索文档的精准对齐;
3.上下文注意力增强机制:通过距离衰减系数和注意力约束,放大后续生成令牌对先前引用令牌的关注度,维持引用与内容的语义连贯性,避免因引用插入导致回答逻辑断裂。
模型最终损失函数为默认损失、引用对齐损失、路由器损失与注意力增强损失的加权和,确保引用质量与回答准确性的协同优化。

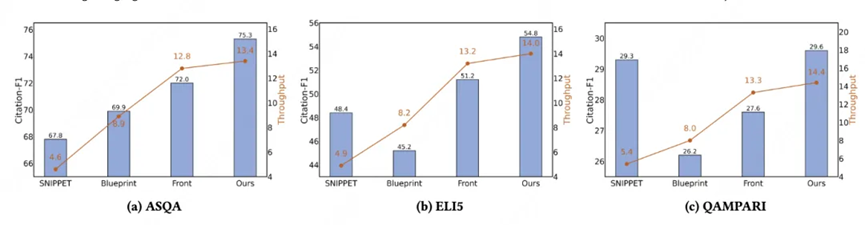
研究团队在ALCE基准测试的三个数据集(ASQA、ELI5、QAMPARI)上进行了全面评估,对比了多种主流归因方法

实验结果令人振奋:
在保证效果的同时,C²-Cite++还展现出卓越的计算效率。吞吐量(每秒处理样本数)测试显示,相比需要多轮迭代的方法(如Blueprint),C²-Cite++实现了最高的处理速度,在实际应用中具有明显优势。
注意力热力图可视化,直观展示了C²-Cite的工作机制。在原生LLM中,引用符号前后的句子几乎没有交互;而在C²-Cite中,后续句子对前文的注意力显著增强,形成了紧密的语义连接。这种"跨引用的语义桥梁"正是模型生成高质量溯源内容的关键。

C²-Cite框架通过"上下文感知"这一核心理念,成功解决了现有归因大语言模型的关键痛点:
最后,仅仅优化训练数据是不够的, 大模型的溯源能力需设计有效的学习机制。相比于复杂的数据合成流程, C²-Cite通过其"上下文感知"的设计思想, 在内容生成的过程依赖可靠的引用知识库,为构建更加可靠、透明的AI溯源系统提供了重要的技术路径。
文章来自于“机器之心”,作者 “机器之心”。



【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
