# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大模型提速,抢走英伟达饭碗
今天一上班,又刷到国外一家公司整了个新活。
这家叫Groq的公司推出了一个聊天机器人页面,看起来比ChatGPT还要粗糙,页面上什么指示都没有,本来实在是提不起什么兴趣。

直到我看了下面这个演示视频。。。
很难想象,这是AI“生成”内容的速度,看起来和直接找到答案然后复制粘贴过来一样。
硅基君问GPT一个问题等他输入的空余还能回几条微信。。。
我们仔细观察上面的视频,可以发现在Groq测试中有一个在其他大模型网站一般不会显示的参数——325.68 T/s。
这一个参数也是Groq在推广页面中着重强调的,具体意思是大模型每秒可以计算多少tokens。
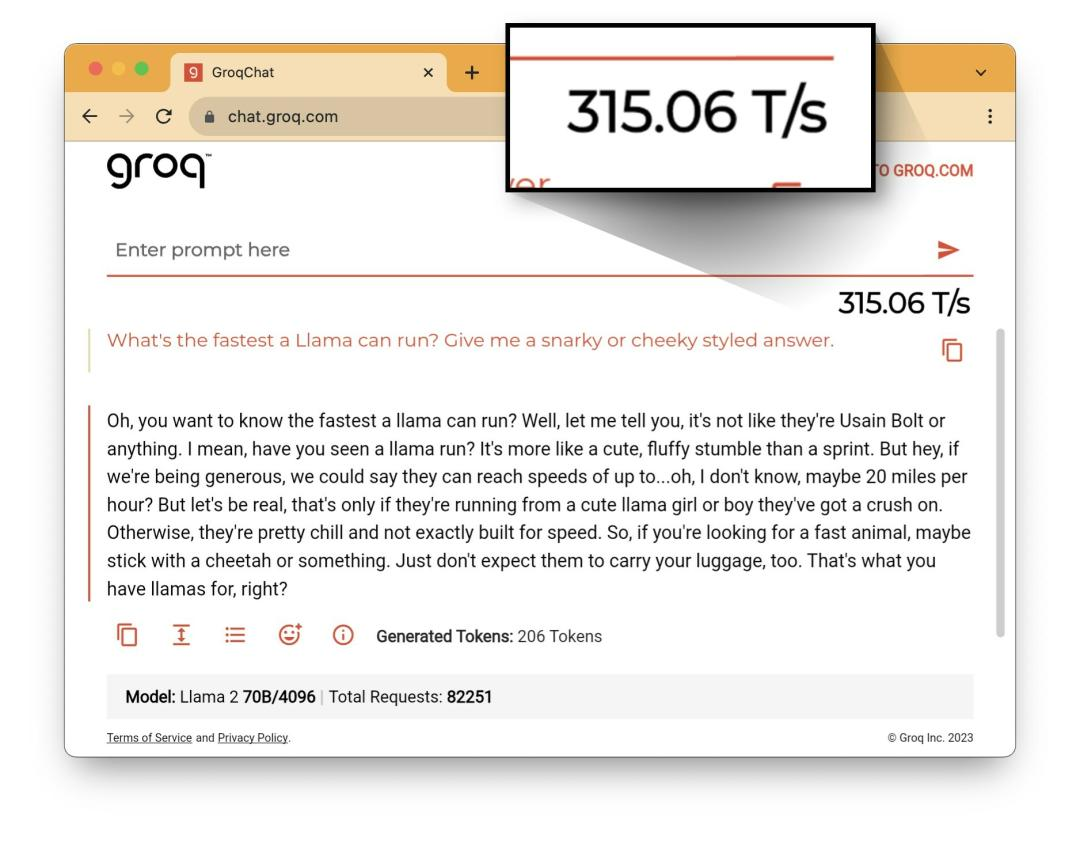
简单说一下tokens在大模型中是干什么的。在大模型训练、推理、生成的时候,会把文本切分成最小单元即token。比如你问chatgpt一个问题,chatgpt会先把你完整的话切成tokens再进行计算。当chatgpt回答的时候,也不是一下子全部输入出来,而是一个token一个token的蹦出来。
chatgpt是如何切分文本的,可以参考OpenAI的分词器网页。比如“希望老黄送我一张4090显卡玩扫雷”这句话,chatgpt就会把它切分成22个tokens。
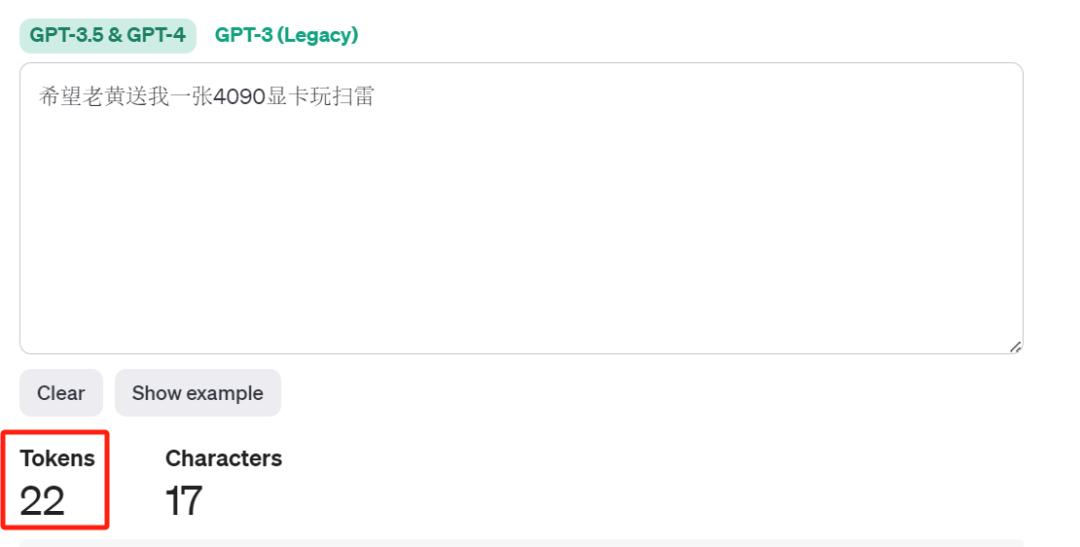
https://platform.openai.com/tokenizer
据ArtificialAnalysis.ai的测评数据,Groq提供的Mixtral 8x7B 接口创下了新的大模型吞吐量记录,达到每秒430 Tokens。
当然,Groq到底有多快,还是要多方比较才能有个完整概念。在github有一个针对70B大模型在不同平台运行速度的测试。可以发现,无论是每秒生成tokens还是响应速度,Groq都是遥遥领先。
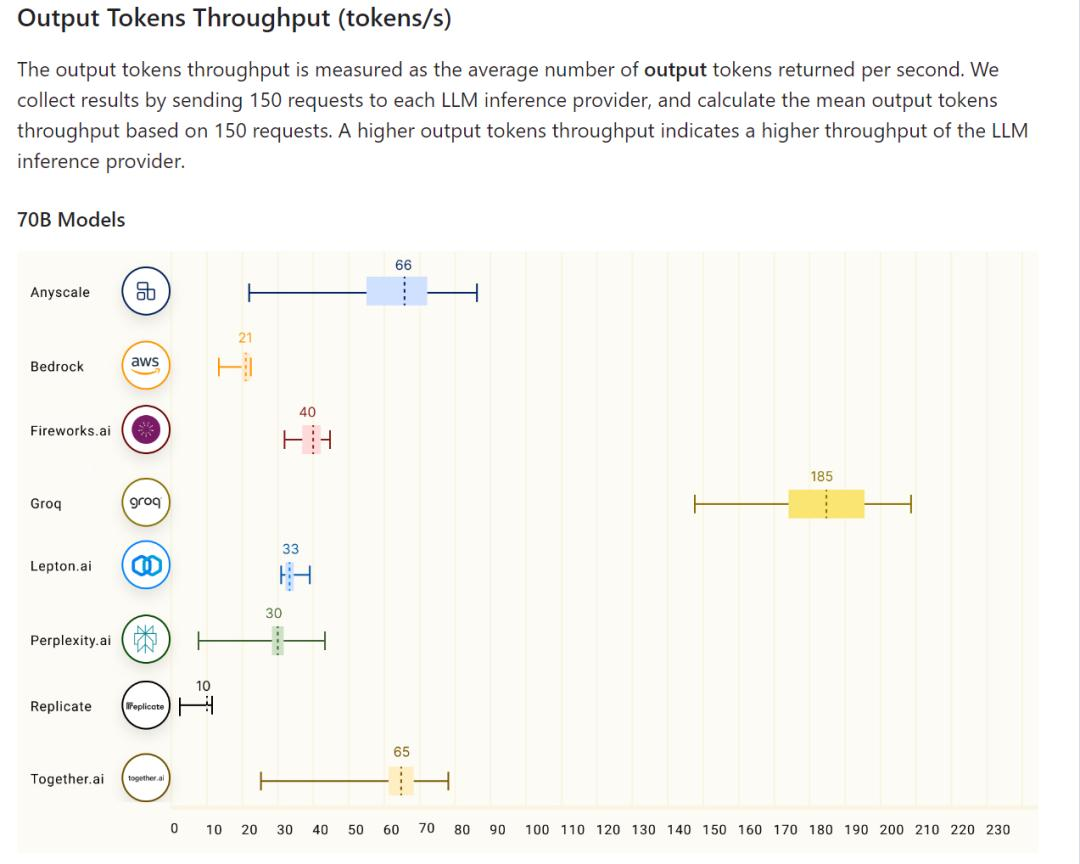
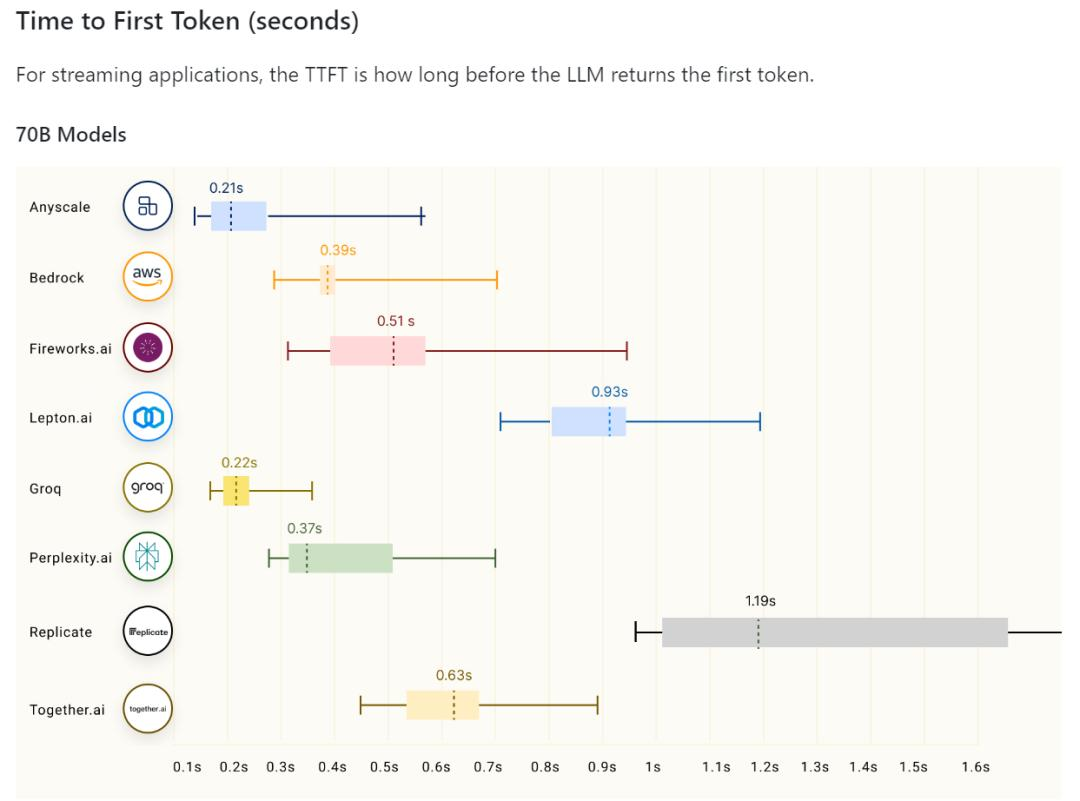
天下武功唯快不破,这个说法对大模型也同样适用。就在不久前,互联网上就出现针对chatgpt是不是变慢的讨论。有人说是OpenAI对免费用户进行限制,具体怎么回事硅基君也不清楚,但可以看出大模型生成的速度的确是用户的一个痛点。
可以想象一下,电商公司为了提高用户的体验,引入AI客服,同样的话术,秒回和隔个10几秒再回,用户的体验会天差地别。
类似的还有AI直播,AI写作等等。在大模型的落地应用环节,大模型生成速度一定很重要。
但实际上,Groq回答问题准确度实在堪忧,稍微复杂一点的问题基本都得不到正确答案,看起来就和那位最近爆火的胡言乱语大妈似的。

不过,人家Groq可不是卖大模型的,人家是卖AI芯片的。
简单来说,它们想宣传的点,是“用了我家的芯片,你的模型生成内容的速度也可以这么快。”
甚至直接喊话黄仁勋,这块芯片推理速度比英伟达的快10倍!
Groq自研的芯片称作LPU。
据官网所说,Groq是一家生成式AI解决方案公司,也是市场上最快的语言处理加速器LPU推理引擎的创建者。
它从头开始构建,可大规模实现低延迟、高能效和可重复的推理性能。客户依靠LPU推理引擎作为端到端解决方案,以10倍的速度运行大型语言模型 (LLM) 和其他生成式AI应用程序。
也就是说,任何模型在LPU上运行,在速度上都能获得提升。
为了推广自己的LPU,Groq甚至在官网上喊话AI界大佬Meta的扎克伯格和OpenAI的阿尔特曼。


在LPU的技术层面上,据官网介绍,它旨在克服两大LLM瓶颈:计算密度和内存带宽。
就LLM而言,LPU比GPU和CPU具有更高的计算能力。这减少了每个单词计算所需的时间,允许更快地生成文本序列。此外,消除外部内存瓶颈使得LPU推理引擎在LLM上的性能相比GPU有了数量级的提升。
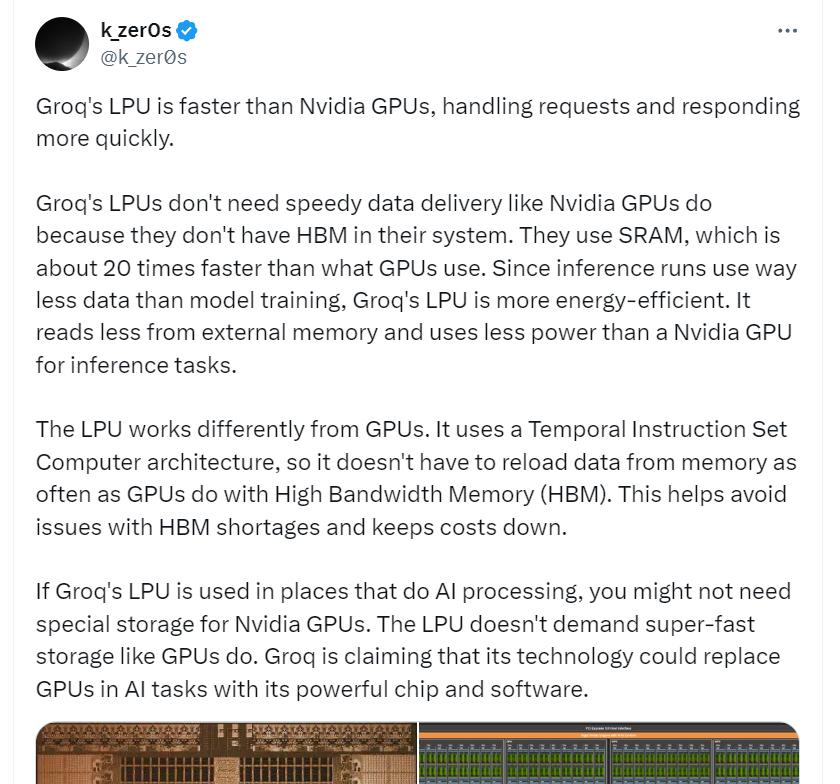
根据twitter网友解释,LPU之所以比GPU快,主要原因在于它使用的存储技术和架构设计。
LPU使用SRAM(静态随机访问存储器),而不是GPU常用的HBM(高带宽内存)。SRAM的访问速度大约是HBM的20倍,这使得LPU在处理数据时能够更快地访问和处理数据此外,LPU采用的时间指令集计算机架构减少了对内存的重复访问需求,进一步提高了处理效率。
说人话,举个形象的例子就是:
把LPU和GPU比作两个厨师,LPU有一个高效的工具箱(SRAM),里面装着他需要的所有材料,他可以随手拿到任何东西,不需要走远路。而GPU的材料都在一个大仓库(HBM)里,每次需要材料时,都要跑到仓库去拿,这就花费了更多时间。即使仓库很大,能存很多材料(高带宽),但往返跑动的时间就使得整个烹饪过程变慢了。
SK海力士看到它说HBM不好用了岂不是着急死?

简单看完LPU的技术,Groq背后的团队来头也不小。
Groq不是横空出世,它成立的背后也有谷歌的影子(结合最近另一个热点sora,心疼一下谷歌)。
Groq是由谷歌前雇员Jonathan Ross创建的企业,在加州成立于2016年。Jonathan Ross也是谷歌TPU最早的团队成员。

TPU对于谷歌来说,基本上覆盖了它们的大部分算力需求。据悉,Google今天宣布的最强大、最通用的人工智能模型 Gemini是使用 TPU 进行训练和服务的。
回到模型本身,一般而言算力的变化只会影响模型推理的速度,但由于大模型的计算量不小,其小数位数不断优化后,可能会发生点变化。那么Groq的LPU与GPU相比,对大模型生成的质量会产生影响吗?
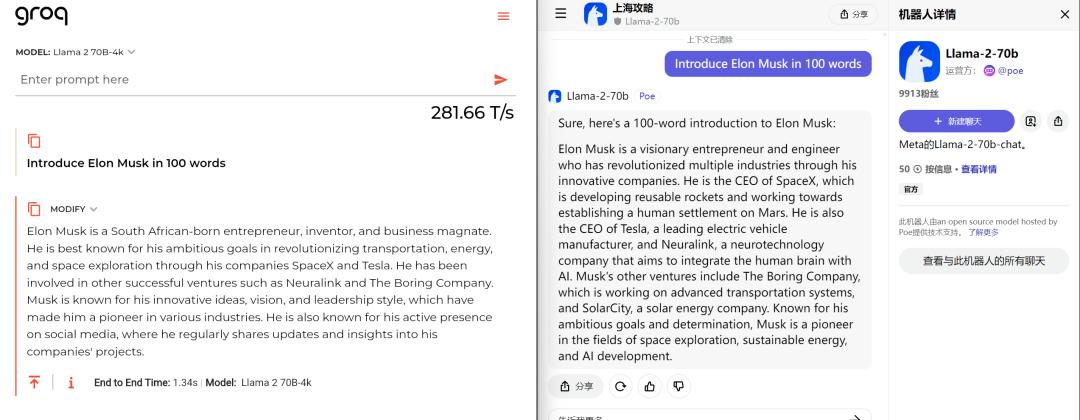
硅基君问了Groq上的Llama-2-70b和POE上的Llama-2-70b,同样一个问题“Introduce Elon Musk in 100 words”。
在速度上两个平台都差不多,结果上有略微不同,但基本上还算通顺。
目前Groq支持api接入,一共提供了3个模型,分别是Llama 2 70B、Llama 2 7B 和Mixtral 8x7B SMoE。价格上,Groq也是相当便宜,Llama 2 70B输入和输出价格分别为0.7$/1000k tokens 和 0.8$/1000k tokens。价格方面,Groq保证,一定低于市面上同等价格。

这几天,sora刷屏全网,但别的公司也没有闲着。谷歌发布了Genimi pro 1.5,支持1000K的上下文长度,把大模型的宽度拉长了不少。而Groq带来了LPU,把大模型的生成速度提高了10倍。
结合之前大模型在算力和规模上的改善,硅基君很期待大模型的继续进化。
参考资料:
[1]10倍英伟达GPU:大模型专用芯片一夜成名,来自谷歌TPU创业团队 | 机器之心
[2]可能是全球最快的大语言模型推理服务Groq:实测每秒500个tokens输出的450亿参数的Mixtral 8×7B模型 | DataLearner
[3]Groq技术新突破:Mixtral 8x7B模型实现每秒500个tokens的生成速度 | 思辨view
文章来自于微信公众号 “新硅NewGeek”(ID:XinguiNewgeek),作者 “董道力”




【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
