# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
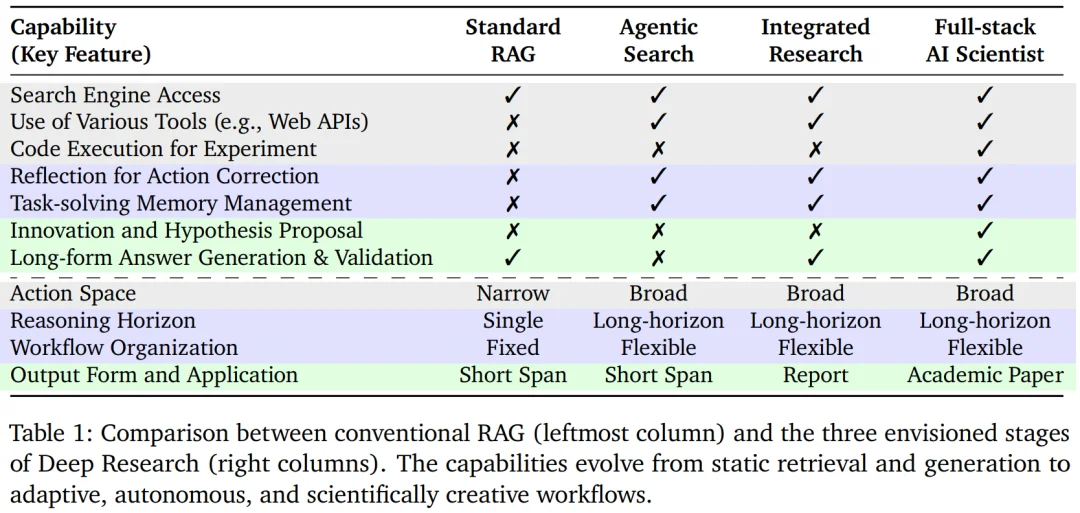
近年来,大模型的应用正从对话与创意写作,走向更加开放、复杂的研究型问题。尽管以检索增强生成(RAG)为代表的方法缓解了知识获取瓶颈,但其静态的 “一次检索 + 一次生成” 范式,难以支撑多步推理与长期研究流程,由此催生了 Deep Research(DR)这一新方向。
然而,随着相关工作的快速涌现,DR的概念也在迅速膨胀并趋于碎片化:不同工作在系统实现、任务假设与评价上差异显著;相似术语的使用进一步模糊了其能力边界。
正是在这一背景下,来自山东大学、清华大学、CMU、UIUC、腾讯、莱顿大学等机构共同撰写并发布了目前最全面的深度研究智能体综述《Deep Research: A Systematic Survey》。文章首先提出一条由浅入深的三阶段能力发展路径,随后从系统视角系统化梳理关键组件,并进一步总结了对应的训练与优化方法。

什么是 Deep Research
DR 并非某一具体模型或技术,而是一条逐步演进的能力路径。综述刻画了研究型智能体从信息获取到完整科研流程的能力提升过程。基于对现有工作的梳理,可将这一演进划分为三个阶段。
阶段 1:「Agentic Search」。模型开始具备主动搜索与多步信息获取能力,能够根据中间结果动态调整查询策略,其核心目标在于持续地找对关键信息。这一阶段关注的是如何高效获取外界信息。
阶段 2:「Integrated Research」。模型不再只是信息的收集者,而是能够对多源证据进行理解、筛选和整合,最终生成逻辑连贯的报告。
阶段 3:「Full-stack AI Scientist」。模型进一步扩展到完整的科研闭环,具备提出研究假设、设计并执行实验,以及基于结果进行反思与修正的能力。这一阶段强调的不仅是推理深度,更是自主性与长期目标驱动的科研能力。
Deep Research 的四大核心组件
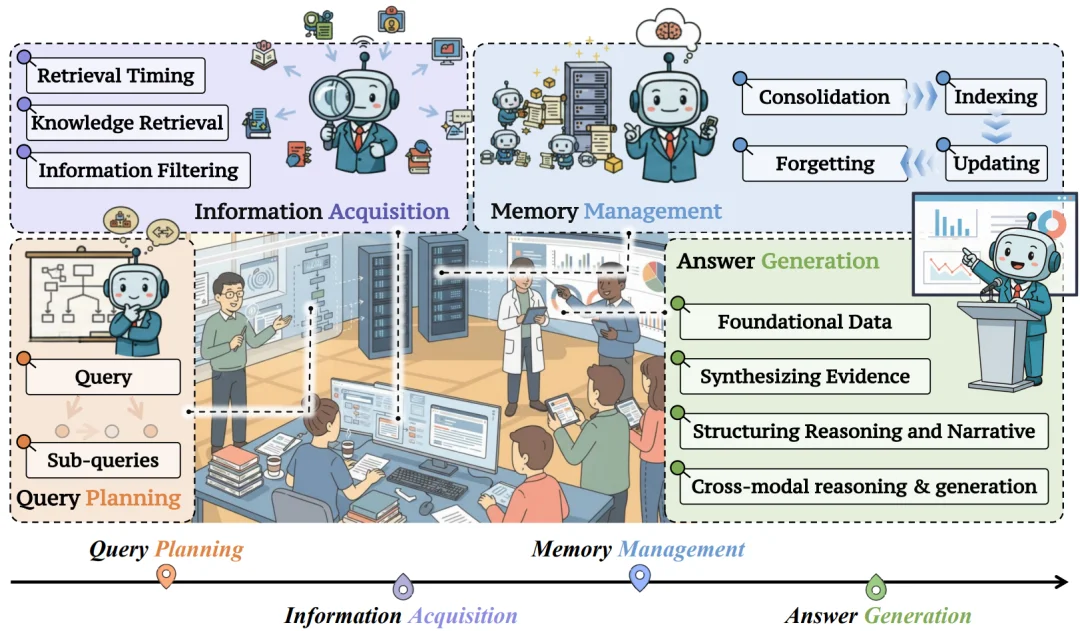
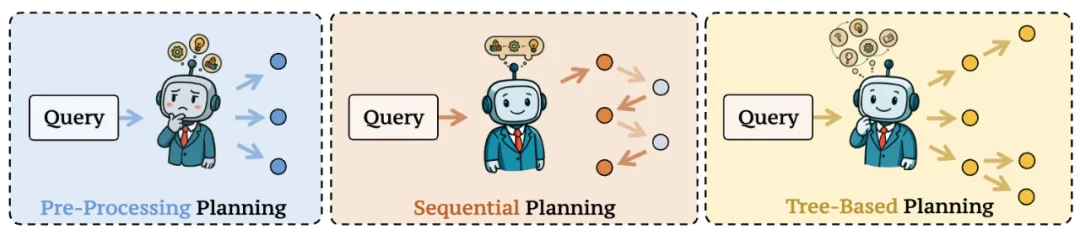
1. 查询规划
查询规划主要负责在当前状态下,决定下一步应该查询什么信息。具体分为三类规划策略:
相比传统 RAG 中一次性生成查询的做法,DR 将 “如何提问” 本身纳入推理过程,使模型能够在多轮研究中动态调整推理路径。
2. 信息获取
论文从三个维度对现有的信息获取方法进行归纳。
(1)何时检索:不同于固定步数或每轮必检索的策略,DR 智能体需要根据当前不确定性与信息缺口,动态判断是否触发检索,以避免冗余查询或过早依赖外部信息。
(2)检索什么: 在确定检索时机后,从 Web 或外界知识库中做检索,包括多模态和纯文本信息。
(3)如何过滤检索信息:面对噪声较高的检索结果,系统通常引入相关性判断、一致性校验或证据聚合机制,对外部信息进行筛选与整合。
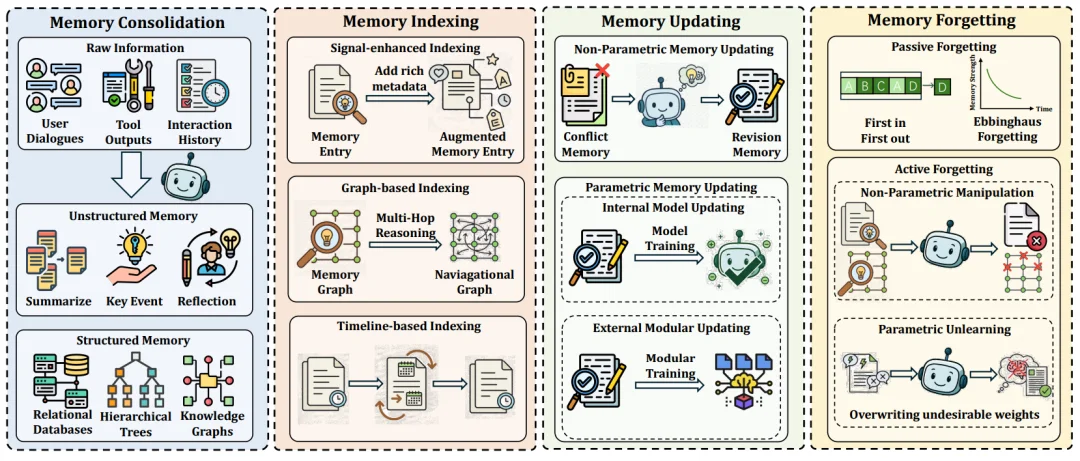
3. 记忆管理
在开放任务中,智能体往往需要跨越多轮交互、多个子问题与不同信息源。记忆模块是支撑 DR 系统长期运行与持续推理的核心基础设施,为系统提供状态延续和经验累积,使模型能够使用长期长线推理任务。现有工作通常将记忆管理过程拆解为四个相互关联的阶段:记忆巩固、记忆索引、记忆更新与记忆遗忘。
4. 答案生成
与传统生成任务不同,DR 场景的问答更强调结论与证据之间的对应关系,以及整体论证过程的逻辑一致性。因此,通常需要智能体显式整合多源证据与中间推理结果,使输出不仅在语言层面连贯,还能够支持事实核验与过程回溯。
如何训练与优化 Deep Research 系统?
文中总结了三类具有代表性的方法:
提示工程:通过精心设计的多步提示构建研究流程,引导模型执行规划、检索与生成等步骤,适合快速构建原型。其效果高度依赖提示设计,泛化能力有限。
监督微调:利用高质量推理轨迹,对智能体进行监督微调。该方法直观有效,但获取覆盖复杂研究行为的标注数据成本较高。
智能体强化学习: 通过强化学习信号直接优化 DR 智能体在多步决策过程中的行为策略,无需复杂人工标注。主要细分为两种做法:
Deep Research 真正难在哪里?
Deep Research 的核心挑战并不在于单一能力的提升,而在于如何在长期、开放且不确定的研究流程中,实现稳定、可控且可评估的系统级行为。现有工作主要面临以下几方面的关键难题。
(1)内部知识与外部知识的协同: 研究型智能体需要在自身参数化知识与外部检索信息之间做出动态权衡,即在何时依赖内部推理、何时调用搜索工具。
(2)训练算法的稳定性:面向长线任务的训练往往依赖强化学习等方法,但优化过程中容易出现策略退化或熵坍缩等问题,使智能体过早收敛到次优行为模式,限制其探索多样化的推理路径。
(3)评估方法的构建: 如何合理评估研究型智能体仍是开放问题。综述系统梳理了现有 benchmark。
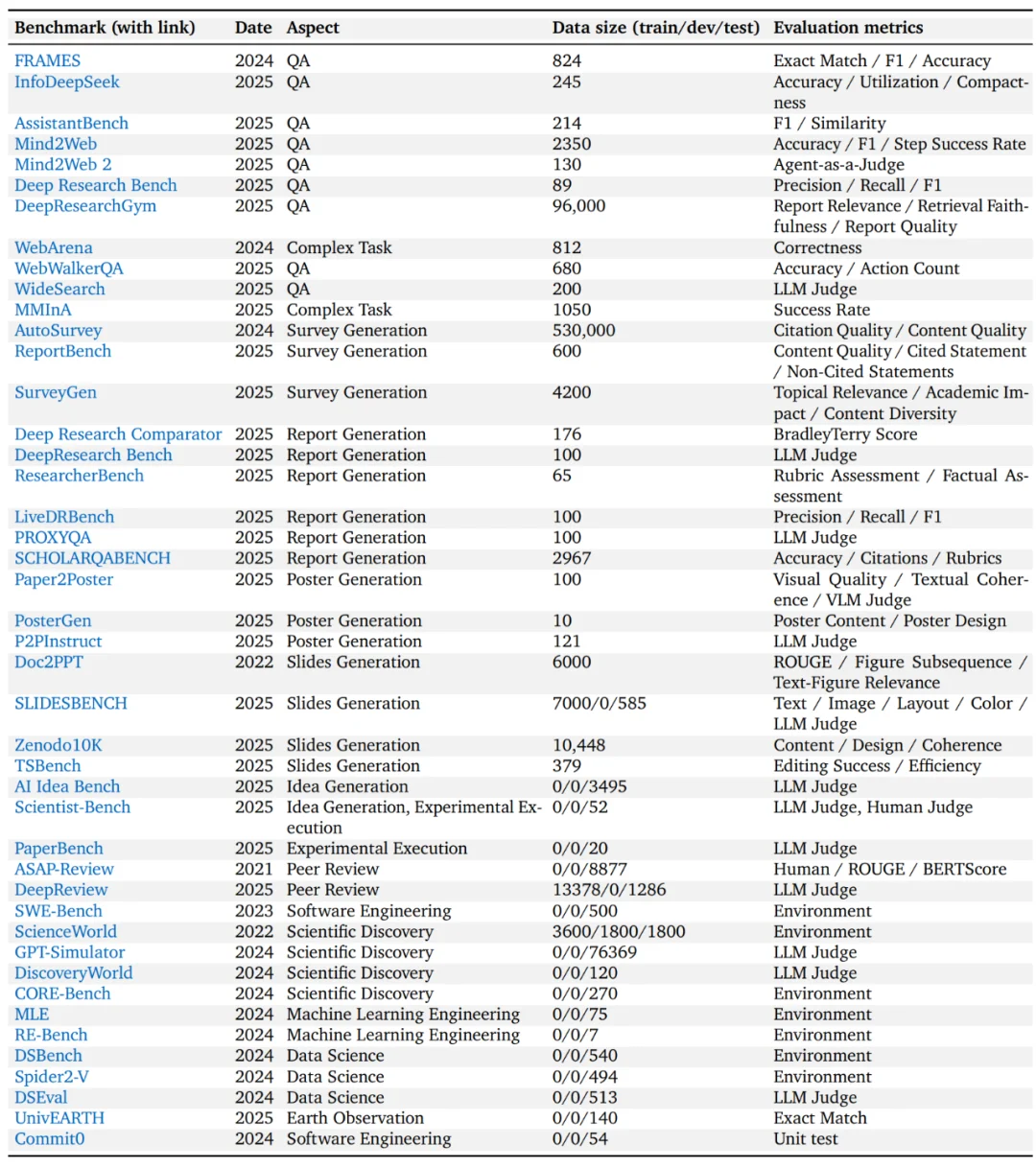
尽管相关数据集不断涌现,构建可靠且高效的评估方法仍有待深入探索,尤其是在开放式任务中如何对 report-level 的模型输出进行全面评估。当前广泛采用的 LLM-as-a-judge 范式在实践中展现出便利性,但仍不可避免地受到顺序偏差,偏好 hacking 等问题的影响,限制了其作为测评方法的可靠性。
(4)记忆模块的构建:记忆模块的构建是 DR 系统中最具挑战性的部分之一。如何在记忆容量、检索效率与信息可靠性之间取得平衡,并将记忆机制稳定地融入端到端训练流程,仍是当前研究中的关键难题。
结语 Deep Research
Deep Research 并非对现有 RAG 的简单扩展,而是智能体在能力、动作空间以及应用边界上的一次转变:从单轮的答案生成,走向面向开放问题的深度研究。目前,该方向仍处于早期阶段,如何在开放环境中构建既具自主性、又具可信性的 Deep Research 智能体,仍是未来值得持续探索的重要问题。本文的 survey 也会持续更新,总结最新的进展。
文章来自于微信公众号 “机器之心”,作者 “机器之心”



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
