# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
空间理解能力是多模态大语言模型(MLLMs)走向真实物理世界,成为 “通用型智能助手” 的关键基础。但现有的空间智能评测基准往往有两类问题:一类高度依赖模板生成,限制了问题的多样性;另一类仅聚焦于某一种空间任务与受限场景,因此很难全面检验模型在真实世界中对空间的理解与推理能力。
要真正走入现实世界,模型不仅需要看得见,更要看得懂空间: 它需要在复杂、多变的真实场景中理解空间布局、感知运动变化、进行时空推理,并基于这些信息做出合理决策,与环境产生有效交互。
为此,上海人工智能实验室 InternRobotics 团队近日推出了一套全面而硬核的空间智能视频基准 —— MMSI-Video-Bench,对当前主流多模态大模型精心打造了一场挑战系数极高的 “空间智能大考”。
本工作由上海人工智能实验室、上海交通大学、香港中文大学、浙江大学、香港大学、北京航空航天大学、西安交通大学、复旦大学、加州大学洛杉机分校 的研究者们共同完成。

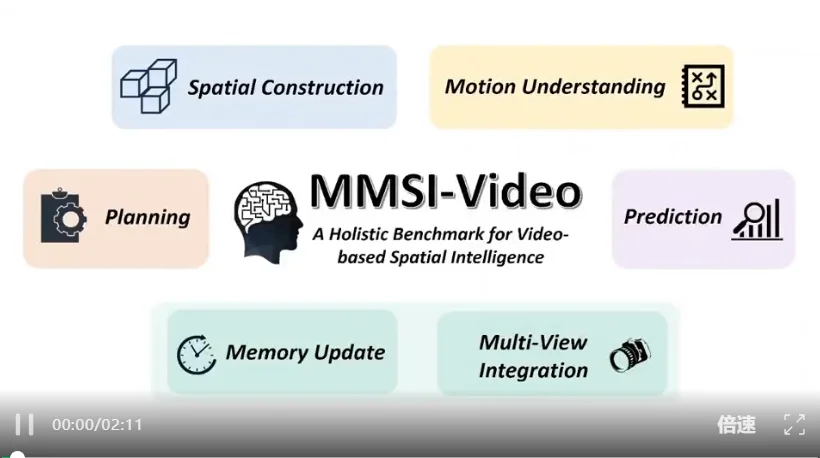
该基准具有以下显著特点:
MMSI-Video-Bench 首先从视频本身的时空信息理解出发,对模型的基础空间感知能力进行系统考察,主要包括:
在此基础上,MMSI-Video-Bench 进一步评测模型基于时空信息进行高层决策的能力,具体包括:
由于真实世界的观测在时间上不一定是连续的,在空间上单一视角的信息不一定是完备的,MMSI-Video-Bench 进一步扩展了任务范畴,以更真实地覆盖现实场景中的复杂情形,考察模型跨视频的推理能力,这包含了跨时间的记忆更新能力(Memory Update);多视角信息的整合能力(Multi-View Integration)。
通过上述多层次、多维度的题型设计,MMSI-Video-Bench 构建了一个覆盖感知、推理与决策全过程的空间智能评测体系。

MMSI-Video-Bench 由五大任务类型,13 个子类问题构成
MMSI-Video-Bench 基准的所有问题由 11 位平均研究年限超过 2.5 年的 3D 视觉研究员亲自把关精细设计,严格验收打磨,确保了基准每一个问题清晰准确,具有挑战性。所有模型均表现吃力,即便是最表现最好的 Gemini 3 Pro,也只有 38% 的准确率,相比其它的空间智能基准,具有目前最高的人类–AI 性能差距 (约 60%)。
基准的视频数据来源于 25 个公开数据集 以及 1 个自建数据集,包含了机器人操作、从单房间到多层楼宇的室内场景、室外建筑与街景、自然风光、体育活动以及电影片段等多种拍摄类型,全面反映了真实世界中复杂多样、多尺度的空间场景
此外,受益于场景类型的丰富以及任务类型的全面性,MMSI-Video-Bench 可以划分出室内场景感知 (Indoor Scene Perception)/ 机器人 (Robot) / 定位 (Grounding) 三大子基准,方便针对性测评模型特定能力。
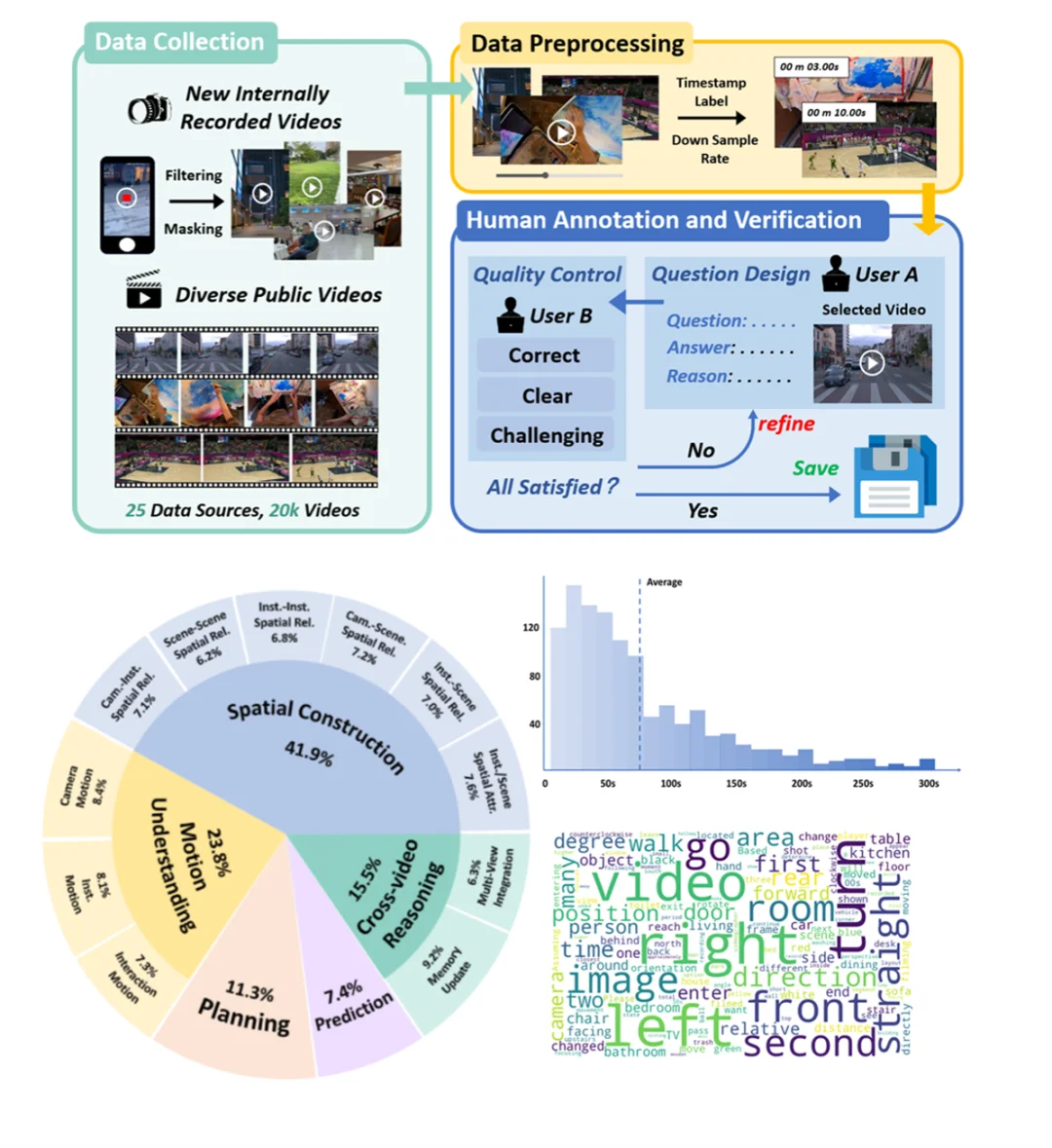
MMSI-Video-Bench 的标注流程 和 比例 / 视频时长 / 词云分布
研究团队对 25 个主流多模态模型 进行了评测,整体得分普遍偏低。即便是表现最优的 Gemini 3 Pro(38.0),与人类水平 (96.4) 之间仍存在 接近 60% 的显著差距。
与已有空间智能基准的结论一致,实验结果再次暴露了当前模型在空间构建能力上的不足。更为关键的是,得益于 MMSI-Video-Bench 在任务设计上的全面性,研究团队进一步发现:模型在 运动理解、规划、预测以及跨视频推理 等能力上同样存在明显瓶颈。
在所有任务类型中,预测(Prediction) 是最具挑战性的主任务, 相机–实体之间的空间关系建模 是难度最高的细分类别。此外,研究团队发现,即便是经过专门空间任务微调的模型,其能力也未能有效泛化到 MMSI-Video-Bench。
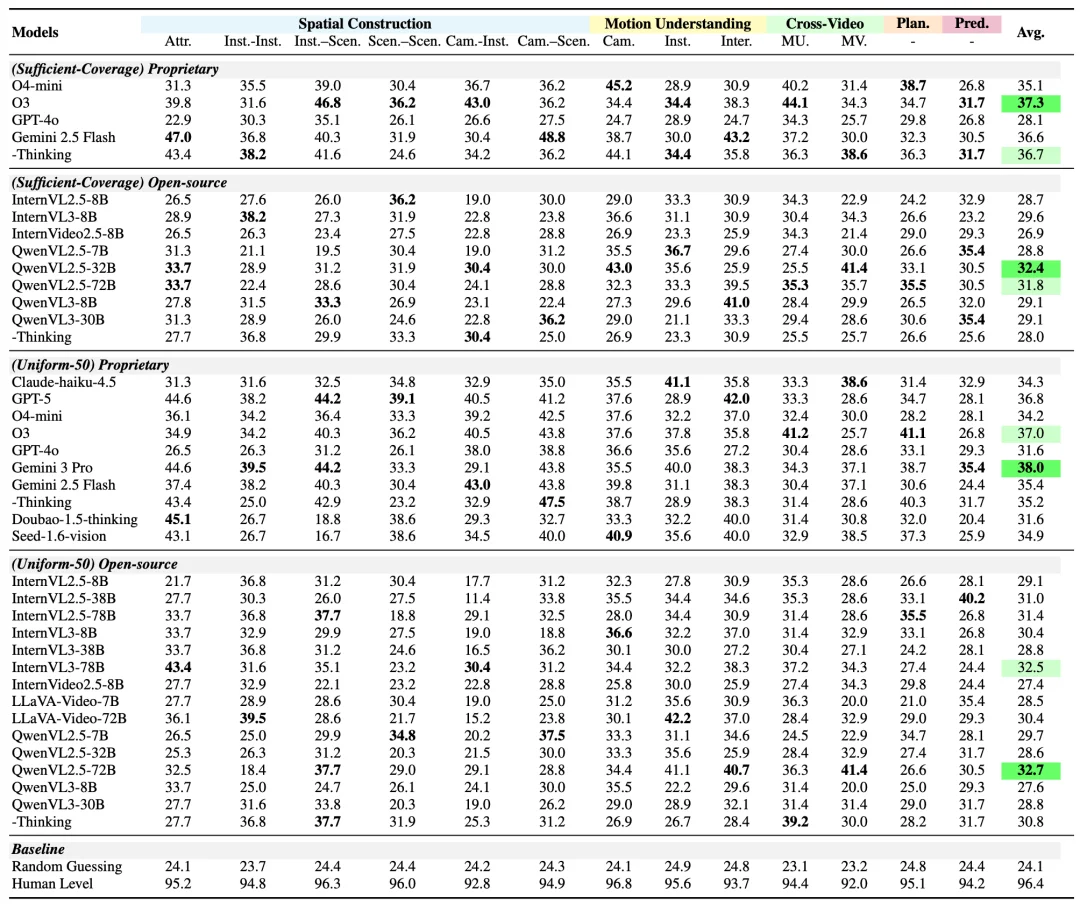
不同模型在 MMSI-Video-Bench 上的表现
为进一步定位模型性能受限的关键原因,研究团队对模型的推理结果进行了系统化复盘,并将错误归纳为五大类型:
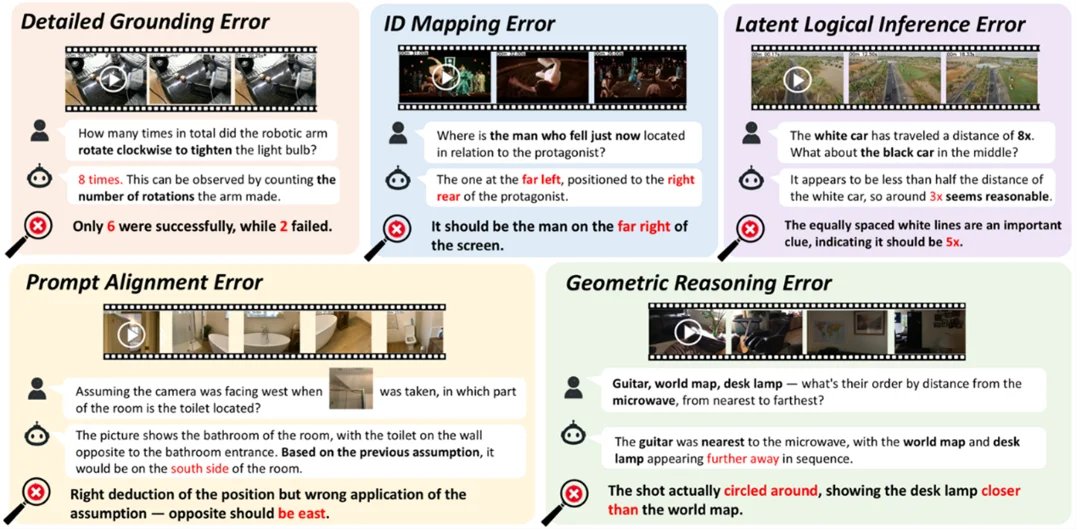
MMSI-Video-Bench 的五种错误类型示例
研究团队选取 Gemini-2.5-Flash、GPT-4o、O3、QwenVL2.5-72B 四个具有代表性的模型进行了系统的错误分析和统计,结果如图所示。几何推理错误是最为普遍、影响最大的错误类型,而进一步的细分分析表明:
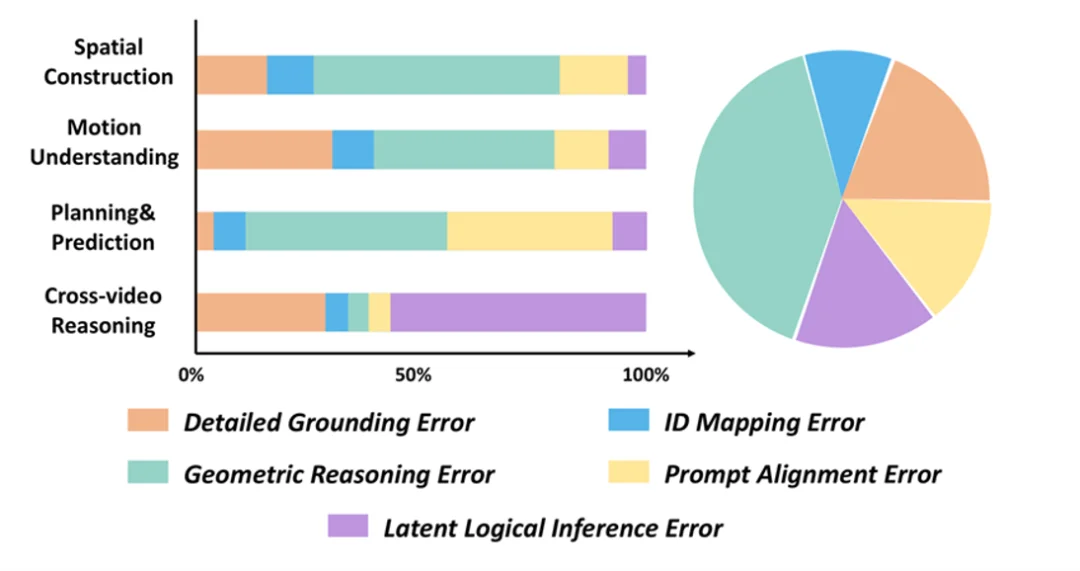
MMSI-Video-Bench 的五种错误类型分布
研究团队进一步探索了两种提升模型性能的策略:
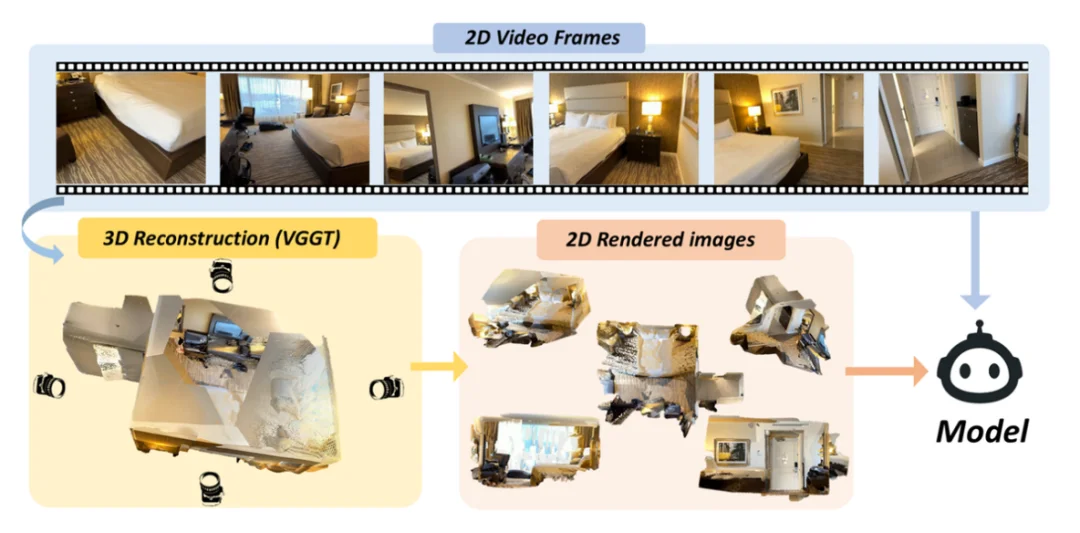
3D 空间线索辅助方法
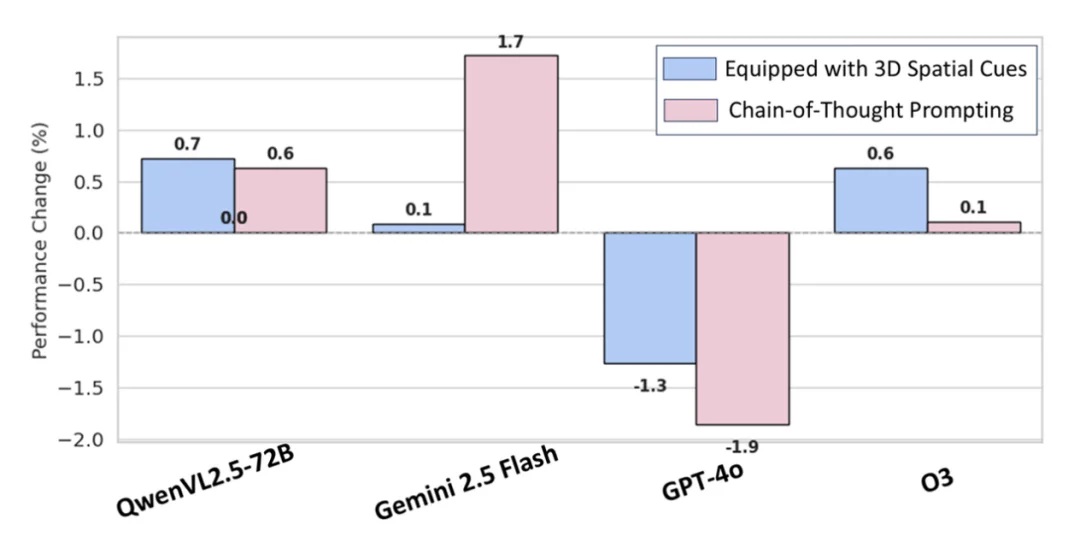
3D 空间线索辅助与思维链提示下的模型性能变化
MMSI-Video-Bench 是一个高质量、高挑战性且系统全面的视频空间智能评测基准,系统性地评估了多模态大模型在视频理解中的空间认知、推理与决策能力,评测结果清晰揭示了当前模型在多项核心任务上与人类表现之间仍存在显著差距。基于深入而细致的实验分析,研究进一步明确了现阶段模型的关键能力瓶颈,并为未来空间智能模型的技术演进指明了研究方向。
文章来自于“机器之心”,作者 “机器之心”。


【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
