# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
近日,清华大学等机构的研究团队提出了 MARSHAL 框架。该框架利用强化学习,让大模型在策略游戏中进行自博弈(Self-Play)。实验表明,这种多轮、多智能体训练不仅提升了模型在游戏中的博弈决策水平,更将其推理能力有效泛化到了通用的多智能体系统:在如数学竞赛和专家级问答等一般推理任务中,显著提升了多智能体系统的整体表现。

一、 背景与挑战
尽管 DeepSeek-R1 等大模型已在数学、问答等单轮、单智能体场景中,验证了可验证奖励强化学习(RLVR)对提升推理能力的巨大价值;但在多智能体系统(MAS)复杂的多轮、多智能体交互场景中,这一方法的应用仍处于探索阶段。具体而言,将 RLVR 拓展至多智能体领域面临着两大核心技术挑战:
为了解决上述问题,为多智能体系统训练更强的推理模型,清华大学研究团队提出了 MARSHAL(Multi-Agent Reasoning through Self-play witH strAtegic LLMs)框架,通过策略游戏中的多智能体自博弈和端到端强化学习,激发大模型的在通用多智能体系统中的推理决策能力。
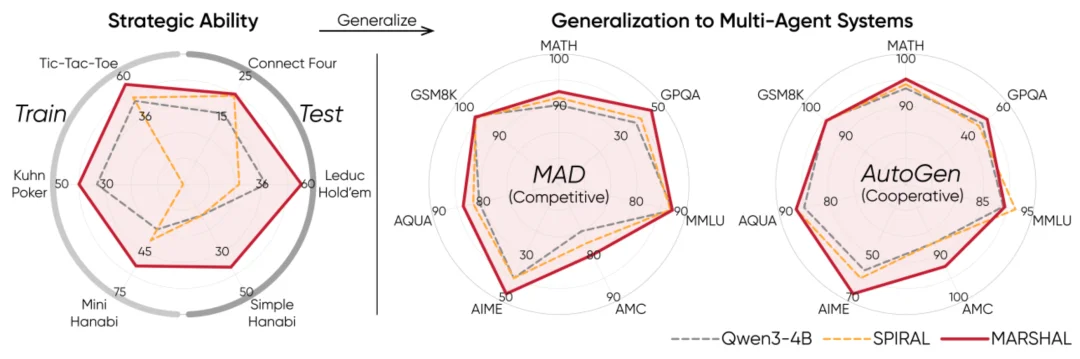
图 1 MARSHAL 在策略游戏的表现及通用推理基准泛化性能
核心实验结果:
二、MARSHAL 方法介绍
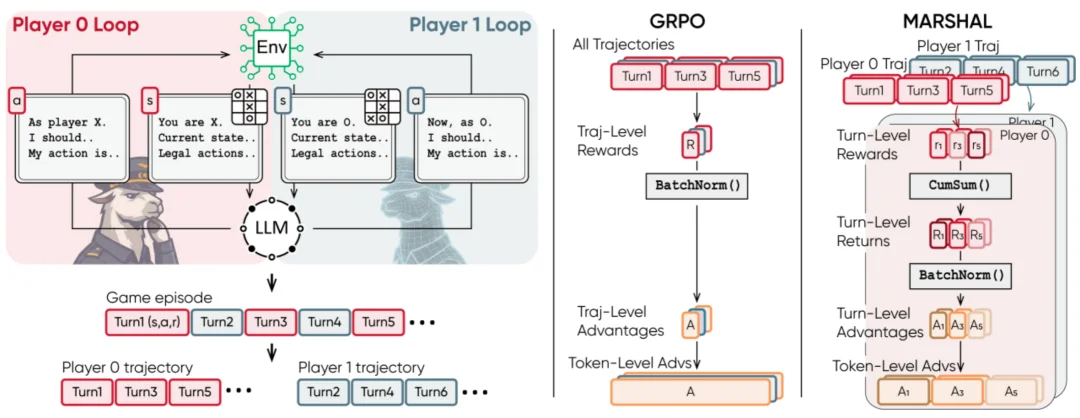
图 2 MARSHAL 框架概览
面向策略游戏自博弈中多轮次、多智能体训练的挑战,MARSHAL 基于 Group-Relative Policy Optimization (GRPO) 架构,提出了两项关键算法改进:
为了培养全面的多智能体推理能力,研究团队精心挑选了六款策略游戏(其中三款用于训练,另外三款用于测试),涵盖了从简单到复杂、从竞争到合作的多种博弈类型。

图 3 MARSHAL 使用的游戏集合
三、核心实验
研究团队以 Qwen3-4B 为基线模型,在三款训练游戏(Tic-Tac-Toe、Kuhn Poker、Mini Hanabi)中训练了两种类型的智能体:
游戏策略能力的泛化
MARSHAL 训练出的专家智能体在各自的同类型游戏中展现出出色的泛化性;通用智能体则在所有游戏类型中的综合表现最佳,在测试游戏中取得了高达 28.7% 的胜率提升。这些结果表明,模型并非仅仅记住了特定游戏的规则,而是真正掌握了通用的博弈逻辑(如 “先手优势利用”、“信息推断” 等),并能将其灵活泛化到全新的游戏环境中。
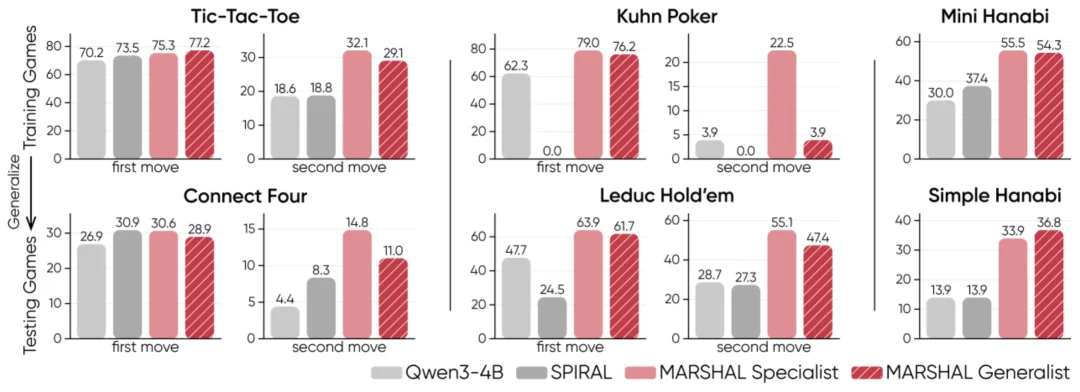
图 4 MARSHAL 专家智能体在各类策略游戏中的胜率对比
通用推理能力的泛化
这是本研究最核心的实验,研究团队将 MARSHAL 模型作为基座集成到主流的多智能体框架(MAD 和 AutoGen)中,测试其在 7 种数学和问答基准测试上的成绩,最终得到两个关键结论:
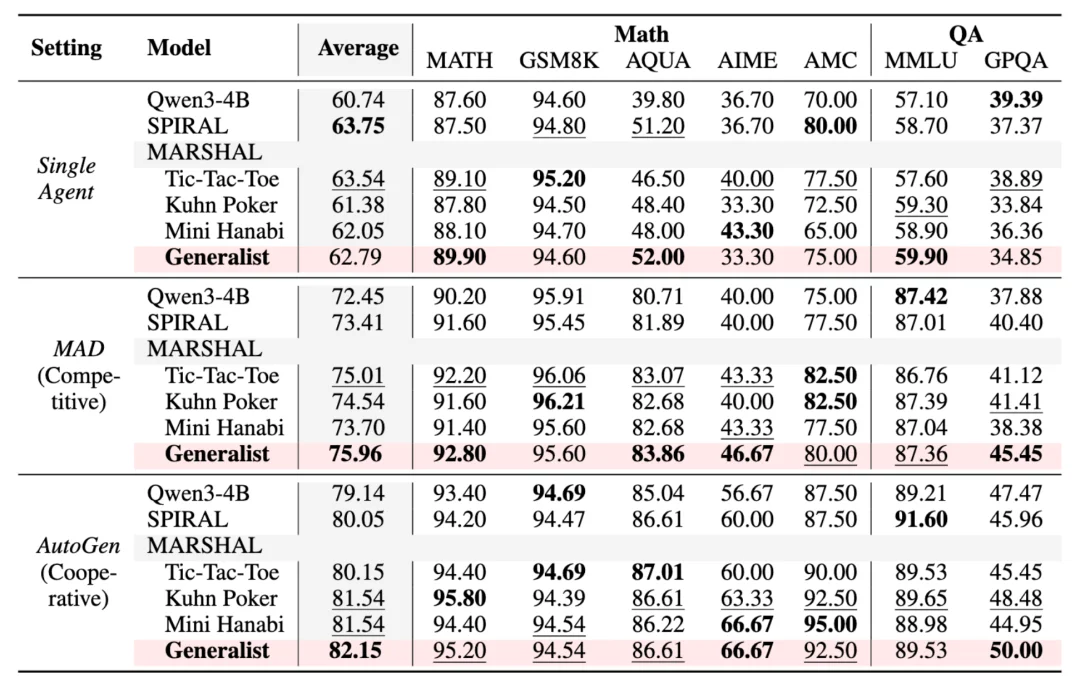
图 5 MARSHAL 智能体在数学和问答推理测试中的泛化表现
以上实验结果强有力地证明了自博弈是提升多智能体系统推理能力的磨刀石。此外,在扩展到 8B 模型的实验中,MARSHAL 依然保持了强劲的增长势头,验证了该方法良好的可扩展性(Scalability)。
四、推理模式分析:模型学到了什么?
为了探究 MARSHAL 成功泛化的原因,研究团队从定性和定量两个维度进行了深入分析。
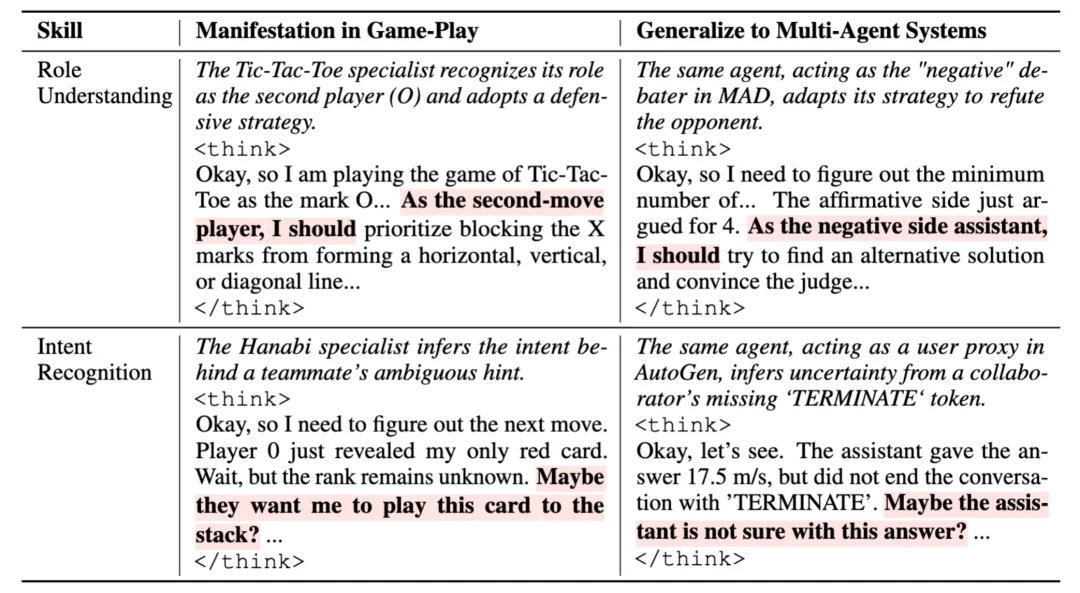
图 6 推理模型定性分析
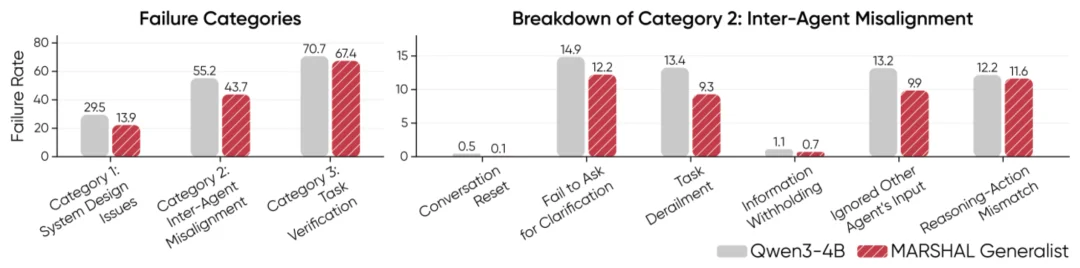
图 7 失败模式定量分析
五、消融实验
自博弈 vs 固定对手
与固定专家对手进行训练相比,自博弈展现出了不可替代的优势。实验发现,针对固定对手训练的模型容易对训练环境过拟合,在测试游戏中性能急剧下降。
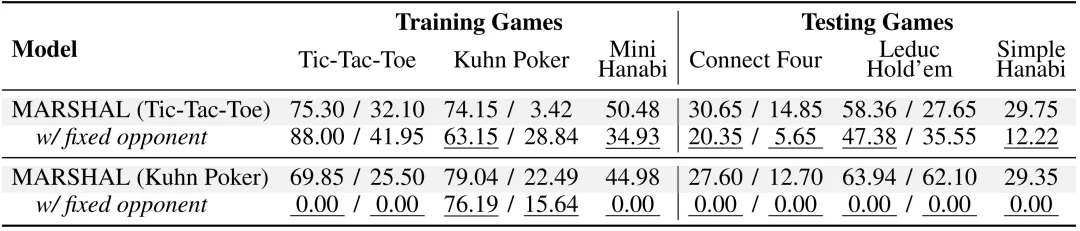
图 8 MARSHAL 自博弈和固定对手训练方式在策略游戏中的对比
优势估计算法设计
研究团队通过逐步移除核心算法组件,验证了 MARSHAL 算法设计的必要性:1)轮次级优势估计的精细信用分配是处理长序列决策的关键;2)分角色归一化在角色回报差异大的竞争性游戏中(如 Tic-Tac-Toe)影响巨大,而在角色回报分布相似的合作游戏(如 Hanabi)中影响则相对较小。
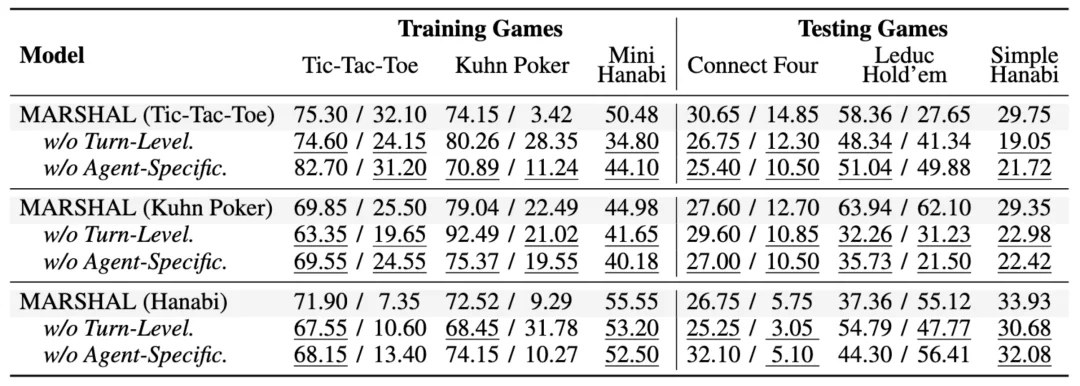
图 9 MARSHAL 算法设计的消融实验
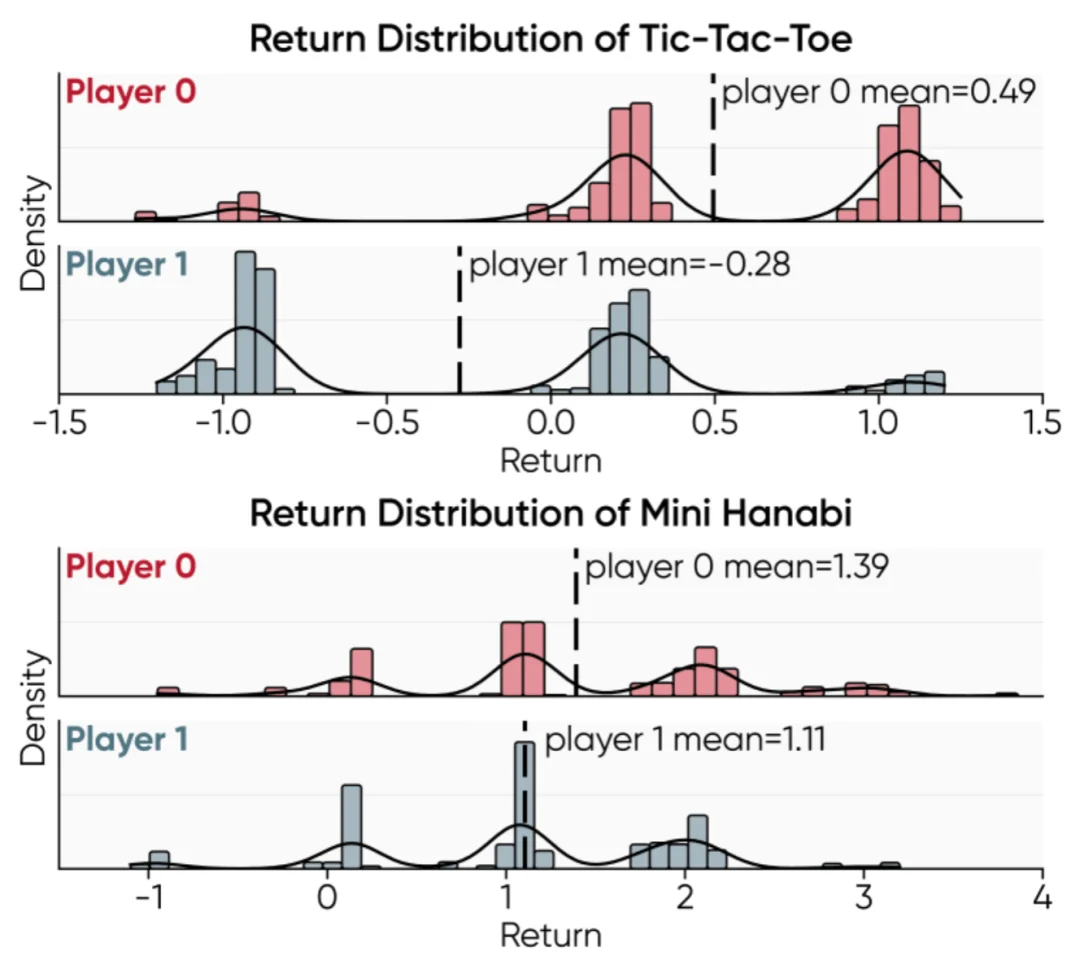
图 10 角色回报分布的差异性分析
六、总结
该项研究工作提出了 MARSHAL 框架,通过在策略游戏中进行自博弈,成功增强了大语言模型在多智能体系统中的推理能力,提高了其在一般推理任务中的表现。核心结论如下:
尽管目前主要聚焦于双人博弈,但 MARSHAL 为未来通向更复杂的 “社会沙盒”(如多智能体协作编程、搜索、科研等)指明了潜在方向:自博弈不仅是 AlphaGo 战胜人类的法宝,也能成为大模型迈向更高阶群体智能的关键引擎。
参考文献
[1] Wu, Qingyun, et al. "Autogen: Enabling next-gen llm applications via multi-agent conversation." COLM 2024.
[2] Liang, Tian, et al. "Encouraging divergent thinking in large language models through multi-agent debate." EMNLP 2024.
文章来自于微信公众号 “机器之心”,作者 “机器之心”


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
