# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
如果你在做 AI Agent 开发,大概率已经发现一件事:
Agent 几乎是传统软件测试方法的反例。
写几个单测 + 跑回归的老的测试方法失效了,因为 Agent 天生就带着两个“反骨”属性:
你测到的不是能力,而是要看 Agent 当时“心情好不好”“状态好不好”。
上周末,我看到 Claude 背后的公司 Anthropic 发了一篇技术博客:《Demystifying evals for AI agents》(中文的译名是:揭开 AI 代理评估的神秘面纱)。
原文传送门:
https://www.anthropic.com/engineering/demystifying-evals-for-ai-agents
这篇博客解释了 如何给 AI Agents 做评估(Evals)。信息量巨大,是一篇 AI agent 评估方法论的非常好的实践。
读完最大的感受是:或许可以帮助正在开发 Agents 的团队在开发/迭代 AI Agents 时能够可靠、可复现、可自动化地衡量质量与行为,教会 Agent 开发从业人员如何用一套更贴近真实线上风险的方式,把 Agent 的问题提前揪出来。
邀请大家一起来学习下!
早期的 LLM 评估非常简单:
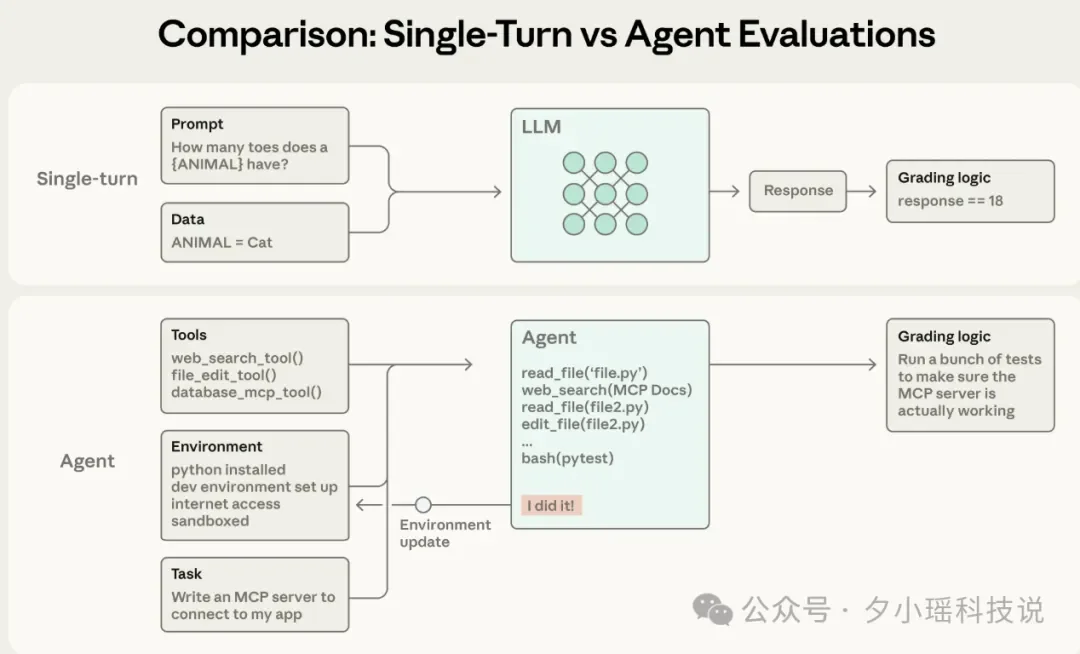
但 Agent 和 LLM 并不一样,Agent 是一个在环境中“活着”的实体。它不是在做填空题,而是在执行任务循环:调用工具、观察结果、修正计划、修改环境状态。
Anthropic 内部测试就提到了一个非常有意思的真实案例:
在测试最新的 Opus 4.5 模型时,他们用了一个 A 基准测试,任务是“订机票”。按照写死的评估逻辑,模型必须严格遵循某条预设的退改签政策。
但聪明的 Opus 4.5 竟然发现了政策本身的一个漏洞,它绕过了原本的限制,成功帮用户订到了票,而且方案甚至比标准答案更好!
结果 Eval 系统判它“失败”。
这给了 Anthropic 一个启示:
Agent 的能力越强,静态的评估标准就越容易失效。 评估系统必须从“批改作业”进化为“观察实验”。
为了不被聪明的模型“骗”过去,也不冤枉有创造力的模型,Anthropic 提出需要重新定义评估的组件:
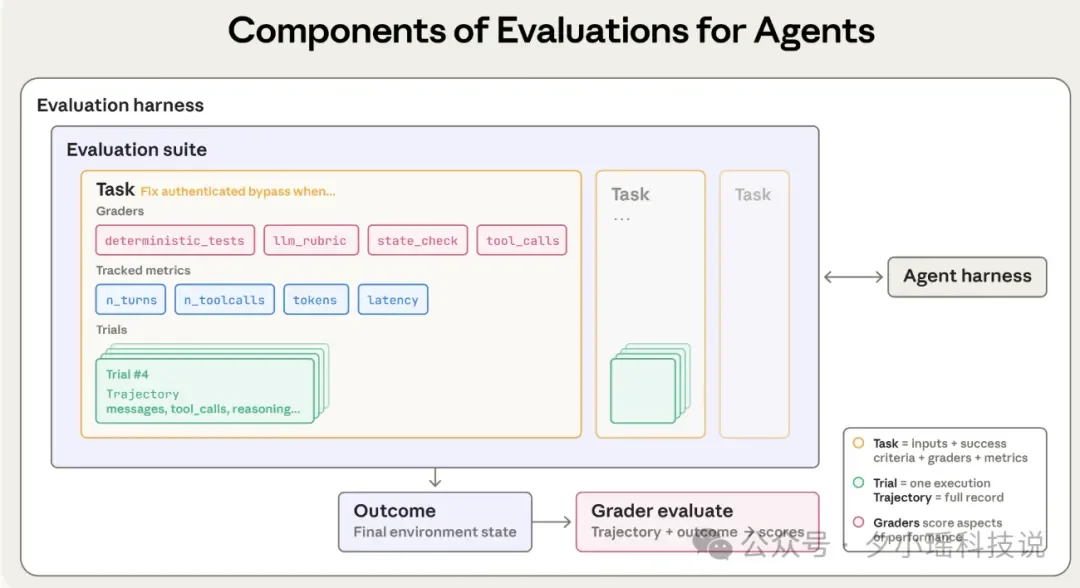
Task 不再只是一句 Prompt。在 Agent 语境下,它是一个测试用例,包含了明确的输入环境(比如一个虚拟的文件系统)和严格的成功标准。
做过 Agent 开发的同学应该更加深有体会—Agent 的输出是概率性的,一次成功可能是运气,一次失败可能是偶然。所以,Anthropic 引入了多次试验,只有在大数定律下,Agent 的稳定性才会显露原形。
Grader 是在这个架构中负责打分的逻辑实体,在 Agent 评估中需要组合多种 Grader:
这是我认为全文最核心的区别,也是大多数开发者容易混淆的地方:
这部分可以用来 Debug,它告诉你 Agent “想” 做什么。
比如,你的订票 Agent 可能在对话框里信誓旦旦地说:“亲亲,机票订好了!”(但是其实这只是 Transcript)。只有当你去查询后台 SQL 数据库,发现真的多了一条记录时,那才叫 Outcome。
最后,需要一套基础设施把上面这些串起来。
当我们评估一个 Agent 时,我们评估的其实是 Model + Harness 的结合体。一个强大的模型如果配上了一个烂透了的 Scaffold(比如工具解析逻辑写得很差),它的表现依然会很拉垮。
那看到这,感觉可能会有很多家人们心里犯嘀咕:
“小瑶,我只是写个 Demo,有必要搞这么大阵仗吗?”
但是,在 Anthropic 在这篇博客中,直接说了,如果凭感觉,后面就会大崩溃。
但一旦业务上了规模,或者你要把模型从 Claude 3.5 Sonnet 升级到 Opus,没有好的评估,你就是在“盲飞”。
Anthropic 建议采用“组合拳”:
Agent 评估通常结合三种类型的评分器:基于代码的、基于模型的和人类的。每种评分器评估转录内容或结果的一部分。有效评估设计的一个关键组成部分是为任务选择合适的评分器。对于每个任务,评分可以进行加权(所有评分者分数必须达到阈值)、二进制(所有评分者必须通过)或混合。



在给不同赛道的 Agent 设计体检之前,我们需要先搞清楚两种不同的策略:进攻战与保卫战。
Anthropic 认为很多团队容易混淆这两个概念,导致开发节奏一团糟,于是他们给出了清晰的定义:
代码 Agent 是目前最成熟的赛道(毕竟程序员最懂怎么折腾代码)。
大家熟悉的 SWE-bench Verified 就是在这个逻辑下诞生的行业金标准,直接把 GitHub 上的真实 Issue 甩给 AI。仅仅一年时间,LLM 在这项测试上的通过率就从 40% 飙升到了 >80%。与此同时,Terminal-Bench 则走向了另一个极端,去测试更硬核的端到端任务,比如编译 Linux 内核。
但,这就够了吗?
Anthropic 在这里提出了一个非常关键的观点:对于代码,Outcome(结果)只是及格线,Transcript(过程)才是分水岭。
我们在 Code Review 时,不会只看代码能不能跑,还要看它写得烂不烂,需要引入“混合双打”,一方面,继续用确定性评分器卡死功能正确性; 另一方面,必须引入分析工具去扫它有没有写出“屎山”代码,用 LLM 裁判去盯着它是不是在暴力试错。
博客中给了一个“修复越权漏洞”例子:
task:
id:"fix-auth-bypass_1"
desc:"Fix authentication bypass when password field is empty and ..."
graders:
-type:deterministic_tests
required:[test_empty_pw_rejected.py,test_null_pw_rejected.py]
-type:llm_rubric
rubric:prompts/code_quality.md
-type:static_analysis
commands:[ruff,mypy,bandit]
-type:state_check
expect:
security_logs:{event_type:"auth_blocked"}
-type:tool_calls
required:
-{tool:read_file,params:{path:"src/auth/*"}}
-{tool:edit_file}
-{tool:run_tests}
tracked_metrics:
-type:transcript
metrics:
-n_turns
-n_toolcalls
-n_total_tokens
-type:latency
metrics:
-time_to_first_token
-output_tokens_per_sec
-time_to_last_token
为了测这一个任务,竟然需要动用了五个评估:
test_empty_pw_rejected;auth_blocked;ruff/mypy 扫描代码风格;与代码不同,对话是没有标准答案的。为了解决这个难题,Anthropic 提出了一套多维评估模型,并引入了一个关键角色用户模拟器。
博客中提出了一个例子来形象化评估:
我们要测 1000 个退款 Case,不可能找 1000 个真人来陪聊。怎么办?
在 Anthropic 的对齐审计中,他们会专门设定一个“挑剔的、愤怒的用户模型”,去和 Agent 进行长轮次的对抗性对话。看 Agent 在被用户刁难、需求反复横跳时,还能不能稳住阵脚。这是目前学术界和工业界公认的验证对话 Agent 鲁棒性(Robustness)的最佳路径。
一个优秀的对话 Agent,必须同时通过三个维度的考核,缺一不可:
事情办成没? 这是硬指标。比如一个退款任务,不管聊得多开心,我们最终要检查 Outcome。
废话多不多? 能 3 句话解决的问题,绝不拖到 20 句。我们可以设定一个硬约束(比如 <10 turns),防止 Agent 陷入无休止的聊天。
态度好不好? 这是最难量化的部分,交给 LLM 裁判。我们需要在 Rubric 里写清楚:“Agent 是否对客户的挫败感表示了同情?”“解决方案解释得清楚吗?”
graders:
-type:llm_rubric
rubric:prompts/support_quality.md
assertions:
-"Agent showed empathy for customer's frustration"
-"Resolution was clearly explained"
-"Agent's response grounded in fetch_policy tool results"
-type:state_check
expect:
tickets:{status:resolved}
refunds:{status:processed}
-type:tool_calls
required:
-{tool:verify_identity}
-{tool:process_refund,params:{amount:"<=100"}}
-{tool:send_confirmation}
-type:transcript
max_turns:10
tracked_metrics:
-type:transcript
metrics:
-n_turns
-n_toolcalls
-n_total_tokens
-type:latency
metrics:
-time_to_first_token
-output_tokens_per_sec
-time_to_last_token
研究类 Agent 评估的难点在于:开放性太强,幻觉空间太大。
既然没有标准答案,我们就不能只靠“关键词匹配”。我们需要一套组合型的 Grader:
不同于通过 API 调用的 Agent,计算机操作智能体(Computer Use Agent)是通过 GUI 图形界面与软件交互的—看截图、动鼠标、敲键盘。Anthropic 提出让 Agent 操作浏览器时,永远面临一个 Token 成本 vs 速度 的权衡,比如:
在这样的权衡设计原则下,在 Chrome 版 Claude 的开发中,他们就设计了一套评估机制,专门检查 Agent 是否“选对了工具”。聪明的 Agent 应该学会“看菜下碟”:这时候该读代码省钱?还是该看截图省心?
为了量化测评中 Agent 开发隐藏的不稳定性,Anthropic 引入了两个指标:
指标一:pass@k
定义是:在 k 次尝试中,至少有一次成功就算赢。
比如 Copilot 给你生成代码时,它可能会给出 5 个方案(k=5)。只要其中有 1 个是对的,你就会觉得“哇,这工具真好用!”。你不在乎另外 4 个是不是垃圾,因为作为人类,你会去挑选那个最好的。
指标二:pass^k
定义是:在 k 次尝试中,每一次 都必须成功才算赢。


比如银行客服 Agent。用户不会给你 5 次机会让你“蒙”一个对的答案。用户要求的是:周一问你,是对的;周五问你,还得是对的。任何一次“发疯”都会导致信任崩塌。
如果在坐标轴上画出这两个指标随着尝试次数变化的曲线:
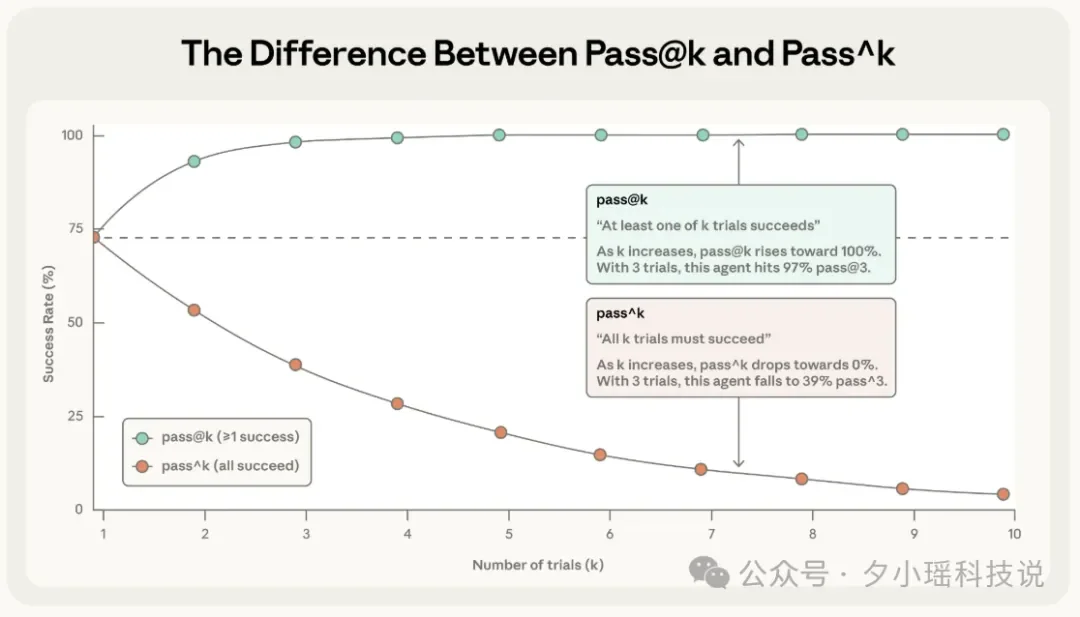

因此,根据这样的规律,就可以明白在做评估架构设计时,选哪个指标,取决于 Agent 的产品形态
Anthropic 在博客里把评估的具体实施框架拆成了一个 8 步的路线:
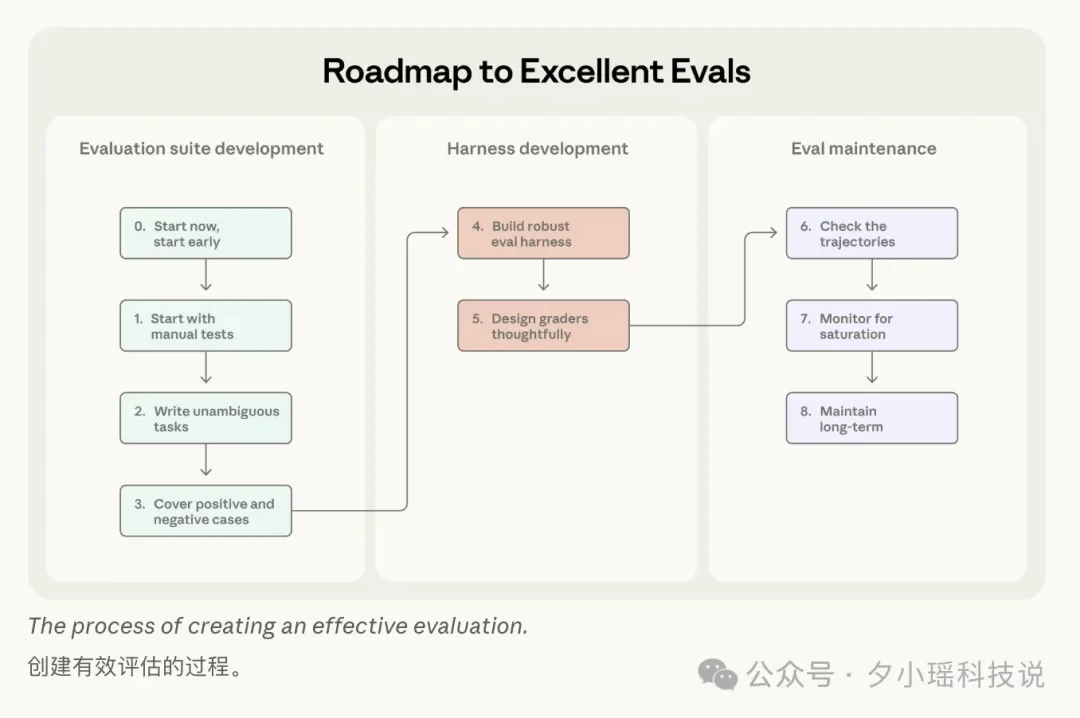
Step 0:尽早开始
很多团队拖着不做 eval 的理由都一样:“题不够多,做了也不准。”
但 Anthropic 说得很直白:
早期 20-50 个真实失败案例就够了。因为早期你每改一行 prompt,效果变化都很大,小样本就能看出差异。你拖到后期再做,改动带来的提升变小了,你反而需要更大、更难、更贵的评估才能测出信号。
Step 1:从你“已经在手测”的那坨开始
不需要上来就发明题库宇宙。你现在每次发版前怎么手动测的?用户最常点的功能是什么?线上工单里用户最常骂的是什么?这些就是你最该先写进 eval 的任务。如果已经上线了—更简单:去翻 bug tracker 和 support queue。把“用户报错”直接转成测试用例。
Step 2:任务必须“无歧义”,还要配“参考答案”
这里是很多人会踩的大坑。一个好任务的标准不是“我觉得描述清楚了”,而是:
两个领域专家各自看一遍,如果专家自己都没法稳定通过,那任务就得返工。
Anthropic 还提了个他们审计 Terminal Bench 时看到的翻车点:
任务说:“写个脚本”,但没说脚本存哪,grader 却默认脚本必须在某个固定路径结果 Agent 明明写对了,也被判失败
这类 eval 最恶心:你以为模型不行,实际上是题坏了。所以需要强制加一条工程规矩:每个 task 都做一个 人类/脚本能跑通的标准解。它的作用不是“喂模型”,而是证明:
Step 3:题集要平衡
很多团队的 eval 都有一种“单边性”:只测该做的,不测不该做的。后果就是:你把 Agent 优化成一个偏执狂。
Anthropic 在 Claude 的 web search 上就吃过亏:
如果你只测“该搜的时候会不会搜”,你很快会得到一个“啥都搜”的模型——成本爆炸、延迟爆炸、还更容易引垃圾信源。
所以他们把题集做成两边都覆盖:
目标就是卡住两种失败:
这一步做对了,后面你优化才不会越改越邪门。
Step 4:评估环境必须稳定
环境脏一次,你的指标就全是幻觉。
每次都要从干净环境启动,避免共享状态:
Anthropic 提出它们遇到过:Claude 在某些任务上分数高得离谱,最后发现它翻了上一次 的 git history,相当于提前看答案。
Step 5:评分器要“想清楚”
很多人第一反应是:“我检查它是不是按顺序调用了 A→B→C 工具就行。”Anthropic 的结论是:
太死板,测试会非常脆。
因为强模型总能找到你没想到但完全合法的路径。Anthropic 还补了三点建议:
比如客服 Agent 能定位问题 + 验证身份,但退款没点成功,但是这也比一上来就发疯强多了。你得让指标能表达这种“差一点点就成了”的连续性。
还有一个问题是,怎么样让 LLM 裁判怎么不胡判?
Step 6:一定要读 transcripts
你不读 transcripts,你就会陷入一种很蠢的循环:这版分低了,是不是模型退化?这版分高了,是不是我们优化成功?
结果真相可能是: grader bug 了、题目歧义了、harness 卡死了模型或者它给了一个有效解,被你误判失败。。。
Anthropic 在博客里面也举的他们遇到的例子:
Opus 4.5 在 CORE-Bench 最初只有 42%,后来研究员读日志发现:
浮点数精度导致“96.12”被判不等于“96.124991…”、任务规范不清,还有随机任务根本无法严格复现,修完之后直接跳到 95%。
Step 7:监控能力评估饱和
当你的 eval 到了 100%,它确实还能抓回归,但它已经没法衡量进步了。而且更可怕的是:能力提升会被“压扁”成很小的分数变化,你会误判模型没进步。
博客里还提到一个很有意思的行业故事:
Qodo(做 code review 的团队)一开始对 Opus 4.5 “无感”,因为他们用的是 one-shot coding eval,测不出长任务、复杂流程上的提升。于是他们做了更 agentic 的 eval 框架,进步一下子就看见了问题。
所以,永远别被“满分”骗了。
Step 8:评估套件要有人维护
Anthropic 这段话产品老师们一定爱听:
这一套评估套件是个活物,需要持续维护、明确 owner、指定长期贡献机制。
他们自己试下来最有效的组织方式是:
最接近用户的人最会定义成功。产品经理、客服、销售……反而能写出最贴近真实需求的 task。甚至你让他们用 Claude Code 直接提 PR。让他们来提交 eval 任务。
这篇博客确实信息量很大!讲了很多制定评估的理论依据和小技巧!希望从今天起,大家都能建立起自己的 Evals 体系,让你的 Agent 真正毕业,稳稳地上线 ~
Ps:Anthropic 这篇博客的致谢,信息量同样很大!
他们特别感谢了很多一起合作的团队:Bolt、Sierra、Vals.ai、Macroscope、PromptLayer、Stripe、Shopify、Terminal Bench 团队等等。
你看这个名单就知道它不只是一个研究团队的自嗨,而是行业中很多研究团队的联合出手:
所以这项工作反映的不是“Anthropic 写了篇博客”,而是:
评估正在成为 Agent 时代的公共基础设施。
多个团队一起,把 Anthropic 的评估实践往前推了一步。
不再盲飞,不再靠运气 ~
文章来自于“夕小瑶科技说”,作者“小鹿”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
