# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
故事得从我们那个行业交流群说起。
群里都是帮搞技术架构的老朋友,平时大家最大的乐趣就是吐槽:吐槽大模型幻觉,吐槽 RAG效果差,分享新的RAG框架。
经常是今天这个说 MySQL 顶不住了,明天那个骂向量库的数据同步又挂了。
大概上个月吧,群里有个做金融项目的技术负责人,突然甩了一个 GitHub 链接出来。
说实话,当时群里刷屏快,我瞥了一眼,心想:“又是个不知名的小开源项目吧。”
毕竟这两年向量数据库赛道太卷了,GitHub 上每天都能冒出好几个号称“拳打 Milvus,脚踢 Pinecone”的新轮子。
大多数都是 Demo 级别的玩具,我手指一滑,准备直接划走。
直到我眼神往下扫,看到了群友补的那句淡淡的评价:
“感觉还行,主要是 1C2G 就能跑,混合搜索挺顺手。”
这行字像钩子一样勾住了我。
1C2G(1 核 2G 内存)?
这年头敢说自己这么轻量级的向量库可不多见。
出于好奇,或者说“想看看它怎么吹牛”的心态,我顺手点开了那个 GitHub 链接。
这一看,我愣住了。
在仓库的显著位置,赫然写着它的归属——OceanBase。
我揉了揉眼睛,以为重名了。
OceanBase?那个 OceanBase?
在我的印象里,OceanBase 可是蚂蚁内部扛核心交易流量的重型武器,是支撑支付宝历年双 11流量洪峰的定海神针。
这种级别的数据库,通常意味着复杂的分布式集群、昂贵的配置,怎么可能跟“1C2G”、“轻量级”这种词沾边?
这种反差感太强烈了。
就像是你原本以为在看一辆老头乐,打开引擎盖却发现里面塞着一台法拉利的 V12 引擎。
那一刻我才意识到,我可能错过了一个重要信号:蚂蚁在这个 AI 基础设施混战的时期,不仅仅是在秀肌肉,而是想把他们最核心的存储能力,做一次极致的“降维下放”。
带着这种审视的眼光,我去扒了扒 seekdb 的代码,发现它确实切中了当前架构最痛的那根神经。
这两年做 AI 落地的兄弟们,心里大概都有个痛处:为了做一个 RAG(检索增强生成)应用,我们被迫把架构搞得像个融合怪。
通常的链路是这样的:左手起一个 MySQL 存业务元数据(Metadata),右手起一个 Milvus 或 Pinecone 存向量(Vector),中间可能还得挂个 ES 做全文检索。
然后呢?运维的噩梦开始了。
你得在应用层写一堆死沉死沉的胶水代码来维持这几个系统的数据同步。
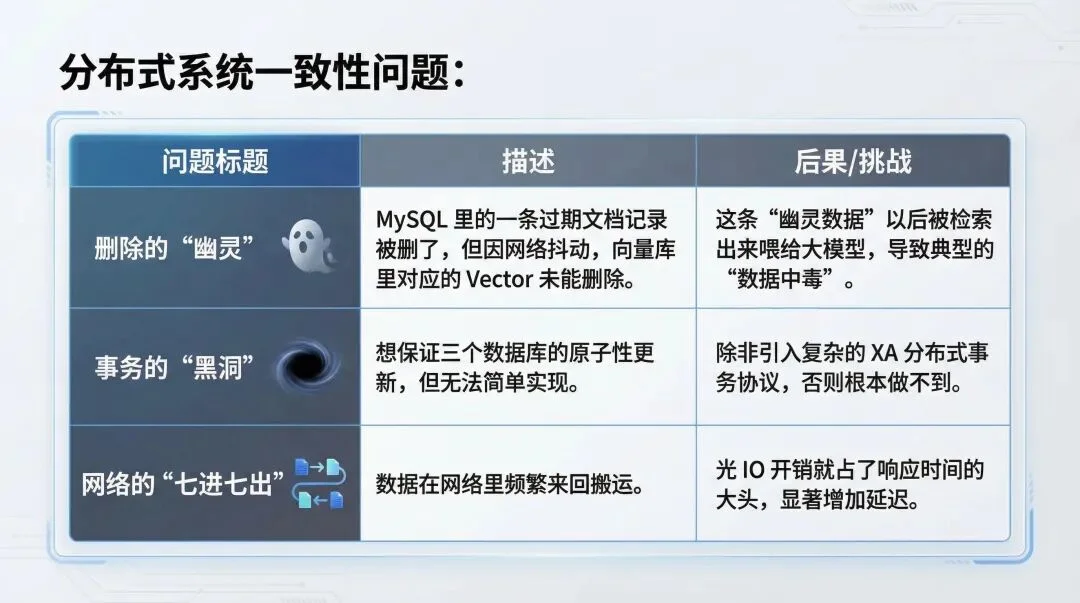
这就是典型的“数据一致性”与“查询效率”的双重灾难。
在 Demo 阶段大家都能忍,一上生产环境,这种散装架构就是给未来埋雷。
而 seekdb 的思路非常清晰:不要割裂,回归AI 原生。
把向量、全文、标量能力统统下沉到存储引擎内部,用一个库解决所有问题。
为什么我们需要 seekdb 这种混合搜索?
仅仅是因为架构简单吗?
不,更深层的原因是:纯向量检索在 RAG 场景下,已经撞到了精度的天花板。
做过 RAG 调优的兄弟应该都有个痛彻心扉的领悟:单纯靠 Embedding(向量化)是很难做到逻辑上的精准召回的。
向量检索的本质,是计算「语义相似度」。
它是一个概率问题(Probabilistic),而不是逻辑问题(Deterministic)。
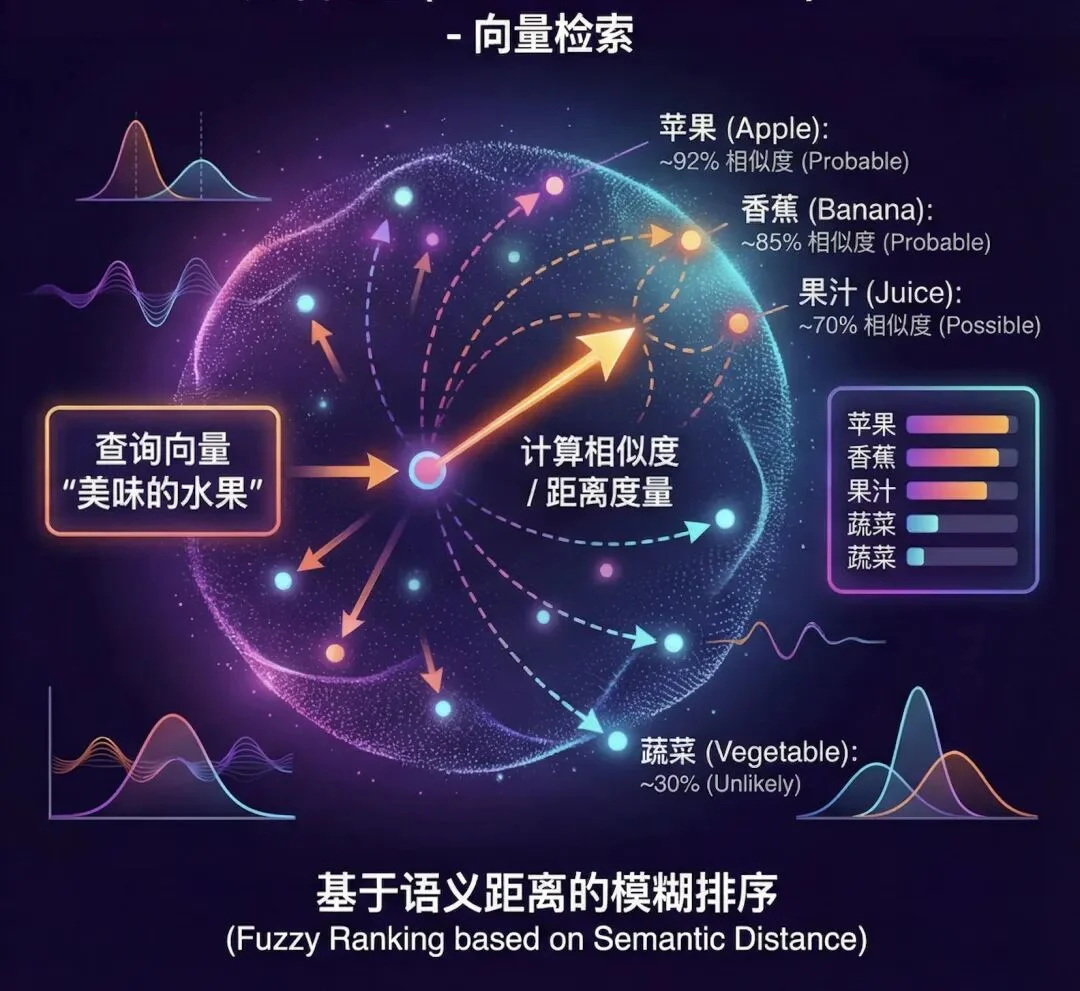
这就导致了一个无解的死局:向量越相似,区分越困难。
举个最真实的业务场景:用户提问“2025 年的华为 Mate70 技术评测”。
如果你的库里同时躺着“2024 年”和“2025 年”的文档,在向量空间里,这两篇文档的 Embedding 距离可能无限接近。
纯向量数据库很容易给你召回“2024 年”的那篇,因为从语义上讲,它们太像了。
这就叫语义正确,但逻辑错误。
但在 RAG 里,差不多就是差很多。
这个精度天花板,靠换更强的 Embedding 模型是很难突破的。
你必须引入另一种维度来解决。
seekdb 的混合搜索,就是用来打破这个天花板的。
它让你在一条 SQL 里,同时运用“左脑的逻辑”(SQL 标量过滤 + 关键词匹配)和“右脑的直觉”(向量语义检索)。
SELECT * FROM docs
WHERE year = 2024
AND MATCH(title) AGAINST('评测')
ORDER BY vector <-> query
LIMIT 5;
请注意,这不仅仅是语法的便捷,这是计算逻辑的质变:先用 SQL 的逻辑能力(标量+全文),把干扰项彻底物理隔绝(Hard Filter),再用向量能力在剩下的精准范围内做语义匹配。
这种“标量 + 全文 + 向量”的三路混合搜索,直接把 RAG 的召回准确率拉升了一个量级。
如果你是AI开发者,那我们得往后看一步:搞定静态文档的检索只是起步,AI 应用的下一站,是强上下文感知与实时推荐。
在这些场景下,挑战不再是简单的查得准,而是要在极其复杂的动态上下文中,瞬间找到那个唯一的答案。
我们来看两个真实的高价值场景:
现在的 Agent 需要记住用户几百轮之前的对话。
当用户问:“上次我提到的那个很贵的、红色的东西是什么?”
这不仅仅是语义搜索。
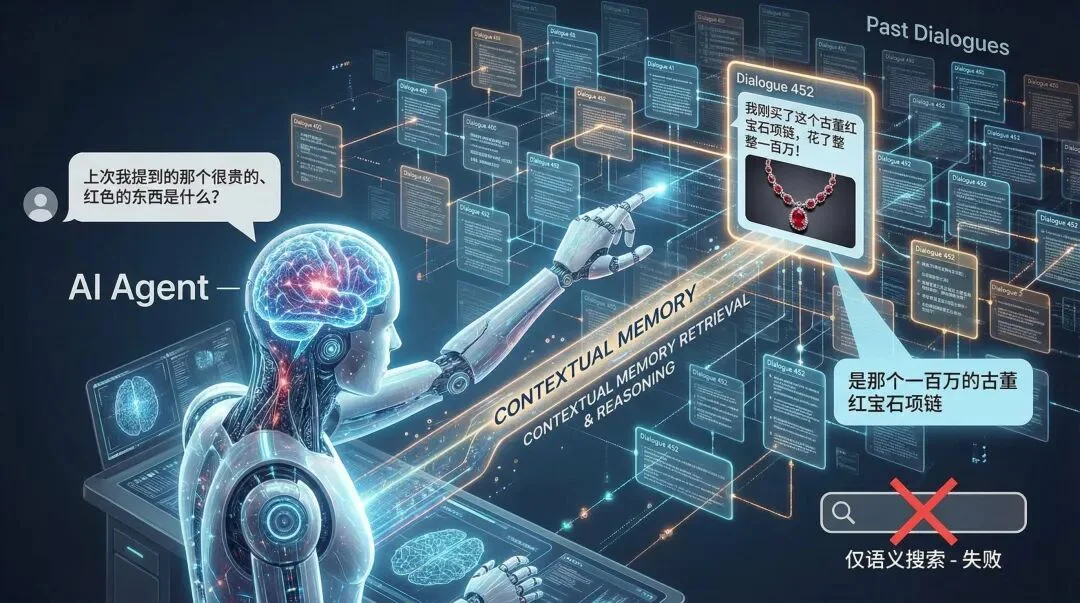
系统需要同时过滤 time(上次)、price(很贵)、color(红色),并在几亿条历史记录中做语义匹配(东西)。
Chroma 或 Pinecone 在这种复杂过滤下,往往会因为元数据过滤机制(Metadata Filtering)效率低下而变慢。
但 seekdb 能用 SQL 的执行计划优化,瞬间切出数据切片。
传统的推荐是离线的。但现在的 AI 推荐是实时的。
比如电商场景:“给用户推荐一款虽然冷门(语义向量),但库存充足(实时标量)、且在本地仓库(地理位置)的显卡。”
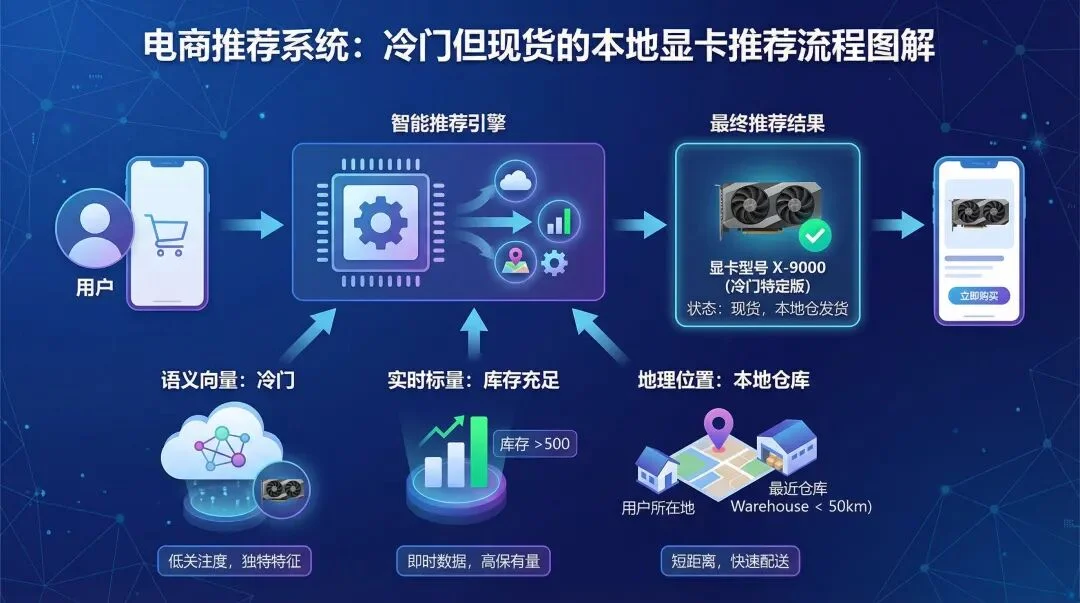
库存是实时变动的(DML),价格是动态调整的。
如果用传统的向量库,你很难处理这种高频更新的 DDL/DML。
但 seekdb 支持标准的 SQL 实时更新,无需工程化搭建多个库,直接在数据库里完成“库存检查 + 语义推荐”的原子化操作。
看到这里,可能有人会说:“PostgreSQL 装个 pgvector 插件也能做向量检索啊,我为什么要用 seekdb?”
这就是内行看门道的时候了。
插件式的外挂方案,和内核级的原生支持,完全是两个物种。
如果我们真正扒开 seekdb 的底裤,最该聊的不是枯燥的存储结构,而是它真正解决 AI 落地痛点的三大杀手锏:原生三路混合搜索、AI 函数计算、以及多级安全管控。
做过 RAG 的人都知道,现在的混合搜索大多是「伪混合」。
你要么得维护两套系统(ES 存文本 + Milvus 存向量),自己在应用层写代码做归并(RRF);要么就是在数据库里先查出一大堆向量 ID,再去查标量表。效率低,维护难。
seekdb 的混合搜索之所以被称为“杀手锏”,是因为它实现了计算层的「原子性。
在 seekdb 里,向量检索不是一个外挂的索引,而是 SQL 引擎的一等公民。
这意味着,当你执行一条包含 WHERE(标量)、MATCH(全文) 和 ORDER BY vector(向量) 的 SQL 时,数据库内核不需要在三个索引之间来回倒腾数据。它能像处理普通 SQL 一样,在一个执行计划(Plan)里同时搞定。
这带来的结果是: 你不需要再写那堆复杂的 RRF 排序算法了,一条 SQL 下去,拿回来的就是最精准的结果。对于追求开发效率的 AI 工程师来说,这简直就是福音。
AI Function是我觉得 seekdb 最“性感”的地方,也是它作为 AI 数据库 最本质的特征。
传统的 AI 开发流程是:把数据从数据库里 Select 出来 -> 通过网络传输给 Python 服务 -> 调用大模型推理/Embedding -> 把结果 Insert 回数据库。
数据在网络里搬来搬去,既浪费带宽,又拖慢速度。
seekdb 引进了 内置 AI 函数 的概念。它允许你直接在 SQL 语句里调用 AI 模型能力。
举个例子,你想对刚写入的一批评论做向量化(Embedding)或者总结。在 seekdb 里,你可能只需要执行:
UPDATE comments SET vector = ai_embed(content) WHERE vector IS NULL;
或者:
SELECT ai_complete('请总结这篇文章', content) FROM articles WHERE id = 1;
发现了吗?
你不需要搞复杂的 ETL 管道,不需要维护独立的推理服务。
数据在哪里,计算就在哪里。
这种“In-Database AI”的模式,直接把 AI 应用的架构复杂度砍掉了一半。
这一点,是绝大多数开源向量数据库的死穴,也是 RAG 系统在企业落地时的最大拦路虎。
试想一下:你做了一个企业内部知识库,里面既有重点客户名单,又有CEO的薪资概况。
如果不做权限控制,实习生问一句“CEO 赚多少钱”,RAG 就老老实实把数据搜出来了。
这时候,seekdb 背后的“蚂蚁/支付宝”基因就显威了。
继承自 OceanBase 的安全体系,seekdb 天生就具备金融级的权限管控能力。
它完全兼容 MySQL 的权限体系,支持租户隔离和用户权限管理。
这意味着,你可以在数据库层面就定好规矩,把不同敏感度的数据隔离在不同的库或表中。
这种安全感,是那些纯为了跑分而生的、几乎没有鉴权机制的向量数据库给不了你的。
光说不练假把式。
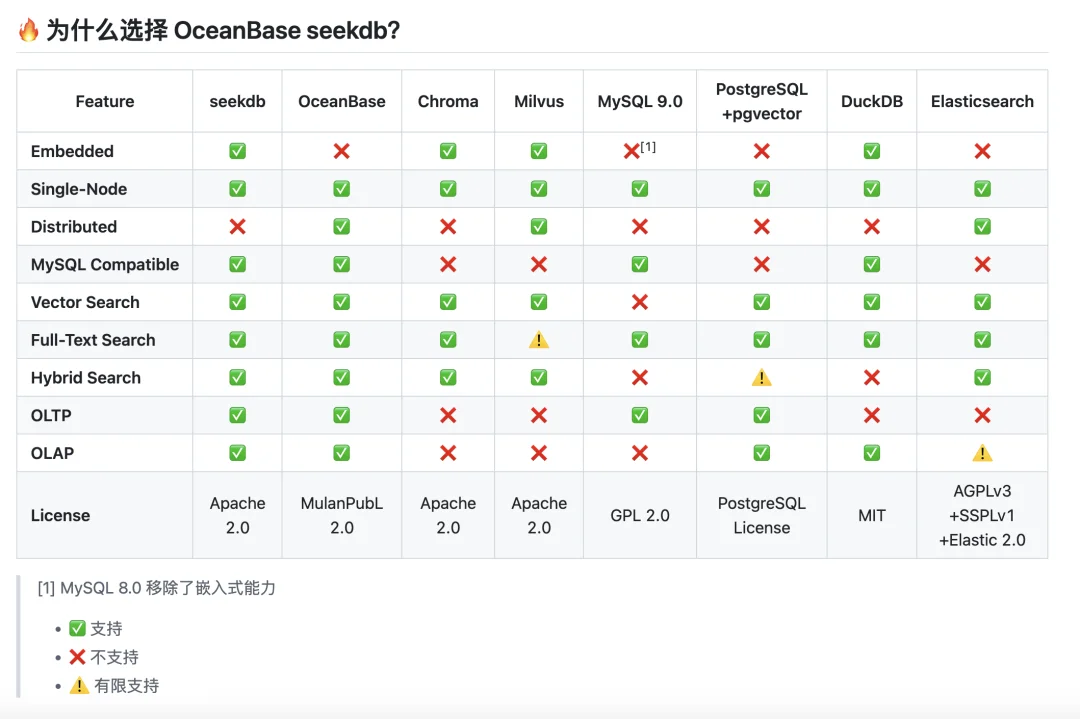
为了验证 seekdb 到底是不是花架子,我特意把它的能力清单和手头的 Chroma、Milvus、ES 做了一次横向平铺。
结果挺有意思,总结下来就是:拒绝偏科,它想做一个“全能的六边形战士”。
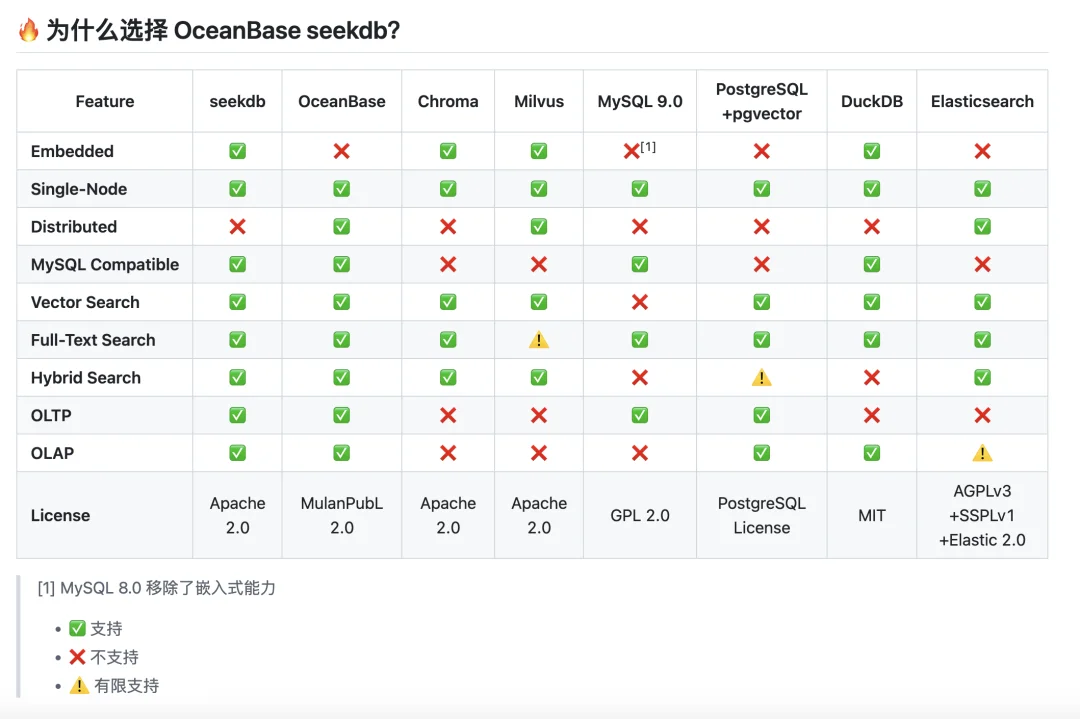
很多做 Demo 的朋友喜欢用 Chroma 或 DuckDB,因为简单、能嵌入。
但你仔细看图表里的 OLTP(事务) 和 OLAP(分析) 这两栏,Chroma 和 DuckDB 要么全是红叉,要么缺失混合搜索。
这意味着什么?这意味着它们只能当个“偏科生”——存存向量还行,一旦业务复杂了,需要改数据(事务)或者做统计(分析),你就得再挂一个数据库。
而 seekdb 是全绿钩,既支持嵌入式(Embedded),又能搞定复杂的增删改查和分析,一套系统全包圆。
Milvus 是老牌强者,在分布式(Distributed)那一栏确实是绿钩。
但注意看 Full-Text Search(全文检索),Milvus 是黄色感叹号(有限支持),且 MySQL Compatible 是红叉。
这意味着在处理 RAG 中最常见的“关键词+向量”混合检索时,seekdb 的原生支持会更丝滑;而且对于开发者来说,seekdb 能直接用 MySQL 协议连进去,不需要学一套全新的复杂 API。
这就是“AI Native”与“适配 AI 的数据库”的区别。
ES 是搜索界的霸主,但在 Embedded(嵌入式) 和 OLTP 上全是红叉。
这解释了为什么 seekdb 更适合现代 AI 开发:它不需要你为了一个搜索功能去维护一套沉重的 Java 集群。
seekdb 能像 SQLite 一样嵌入,又能像 MySQL 一样抗事务。
用过 ES 的兄弟都知道,为了写一个混合查询 DSL,你得掉多少根头发。
但 seekdb 在 MySQL Compatible 这一栏打了个大大的绿钩。
不需要学新 SDK,不需要改 ORM,直接用标准的 SQL 就能跑起来。
这就是把核武器做成了瑞士军刀。
能力全就是架构简,架构简就是下班早。
让我们把视线拉长一点。
在数据库的发展史上,从来没有哪一种专用数据库能长期独立存在。
JSON 曾经也是独立的,后来被 MySQL/PG 收编了;时序数据曾经也是独立的,现在是个数据库都能存。
我大胆预判一下:向量数据库作为一个独立的品类,可能正在进入倒计时。
未来的 AI 应用开发,不应该被碎片的架构所困扰。
向量检索,终将回归到通用数据库的内核里,成为一种基础索引能力,就像 B+树一样稀松平常。
seekdb的出现,就是这个趋势的冲锋号。
它用OceanBase的内核证明了:你不需要一个专门的复杂的系统来存向量,你只需要一个更先进的通用数据库。
所以,别被它“1C2G”的轻量级外表骗了。这不仅是一个工具的开源,更是一次架构理念的回归。
建议你去 GitHub 上点个 Star,或者亲自跑跑看。
不为别的,就为了在下一次技术选型时,当别人还在为了数据一致性和精度天花板焦头烂额,你已经用上了支付宝同款的技术。
毕竟,在技术圈,看见未来并不可怕,可怕的是看见了却以为那是玩具。
文章来自于“01Founder”,作者 “一直在路上的Max”。


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
