# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
今天DeepSeek又发表了一篇论文,让AI解读,仔细读完,觉得很牛逼。
我和好友Nixy交流论文学习心得时,经常感叹,大模型的设计真的越来越像人。
这篇论文用一个很巧妙的办法,让AI实现了无限记忆,那就是「查字典」。
还有一个反直觉的事儿,Engram优化有“查字典”能力后,知识问答类能力虽然有提升。
但最大的提升反而是计算推理能力!
把「脑力」用在真正需要思考的地方,减少记忆负担,会变得更聪明!
这么看,建立自己的第二大脑太重要了,无需多言。
假如你正在参加一场知识竞赛。
主持人问:「威尔士王妃戴安娜是谁?」
如果你是一个普通人,你会怎么做?
你会直接从记忆中「调取」这个答案,就像从书架上抽出一本书一样简单。
但如果你是一个大语言模型呢?
你没有「书架」。
你只能通过一层又一层的神经网络计算,像解数学题一样,从「威尔士」这个词开始,先想到「英国的一个地区」,然后想到「王室」,再想到「王妃」,最后才拼凑出「戴安娜」这个答案。
这就好比,你问一个人「1+1等于几」,他不是直接告诉你「2」,而是要从头推导一遍「为什么1+1=2」。
这种「用计算模拟记忆」的方式,正是当前大语言模型的核心痛点。
DeepSeek团队的最新论文提出了一个优雅的解决方案:Engram。
它给AI装上了一本「字典」,让模型学会了「查」而不是「算」。

在深入了解Engram之前,我们需要先理解一个关键。
语言处理其实包含两种本质不同的任务。
第一种是组合推理。
比如理解「他虽然很努力,但成绩还是不理想」这句话,你需要理解转折关系、因果推断、情感分析。
这需要深度的、动态的计算。
第二种是知识检索。
比如识别「张仲景」是东汉末年的名医,或者「四大发明」包括造纸术、指南针、火药和印刷术。
这些信息是固定的、静态的,本质上是一种「查表」操作。
组合推理:需要根据上下文动态整合信息的任务。就像做阅读理解题,你需要把文章里的线索串联起来,得出结论。这种任务没有固定答案,答案取决于具体语境。
知识检索:直接从记忆中提取固定信息的任务。就像查百科全书,「埃菲尔铁塔有多高」的答案永远是330米,不会因为上下文不同而改变。
语言学研究早就发现,自然语言中有大量「套路化」的表达。
比如英语里的「by the way」「once upon a time」,中文里的「众所周知」「不言而喻」。
这些多词表达(Multi-word Expression)的含义是固定的,完全可以预先存储,用的时候直接查出来。
经典的N-gram模型就是基于这个原理工作的。
N-gram模型:一种统计语言模型,通过统计词序列的出现频率来预测下一个词。比如2-gram(二元组)会记录「我爱」后面最常出现什么词,3-gram(三元组)会记录「我爱北」后面最常出现什么词。N越大,记录的上下文越长,但需要的存储空间也指数级增长。
但现在的Transformer架构没有这种「查表」能力。
它只能用计算来模拟记忆。
这就造成了一个尴尬的局面:模型的前几层被迫去做「重建静态查找表」的工作,浪费了本可以用于复杂推理的计算深度。
Engram的核心思想就是:把查表的归查表,把计算的归计算。

理解Engram,需要先理解一个更大的框架:稀疏性。
稀疏性:指在处理每个输入时,只激活模型的一小部分参数。就像一个大公司,不是每个员工都参与每个项目,而是根据项目需要调动相关人员。这样可以在不增加计算成本的情况下扩大模型容量。
目前,稀疏性主要通过MoE(混合专家)来实现。
MoE(Mixture of Experts):一种稀疏架构,把一个大模型拆分成多个「专家」网络。每次处理输入时,只激活其中几个专家。比如一个有100个专家的模型,每次只激活6个,总参数虽然很大,但实际计算量很小。DeepSeek-V3就是典型的MoE模型。
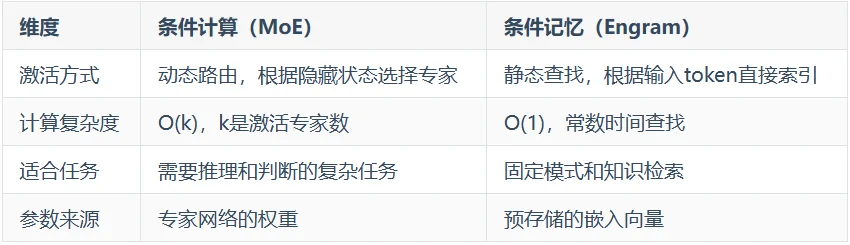
MoE代表的是条件计算:根据输入内容,动态选择激活哪些专家进行计算。
Engram代表的是条件记忆:根据输入内容,静态查找预存储的知识向量。
两者的区别在于:
论文的核心发现是:这两种稀疏性是互补的。
就像一个公司既需要能力强的员工(MoE专家),也需要完善的知识库(Engram记忆)。
光有聪明员工,每个问题都要从头思考;光有知识库,遇到新问题就束手无策。

Engram的名字很有意思。
Engram在神经科学里指「记忆痕迹」,而这里它是「Enhanced N-gram」的缩写,意思是「增强版N-gram」。
它的核心思路是:用N-gram作为检索键,从一个巨大的嵌入表中查找对应的向量。
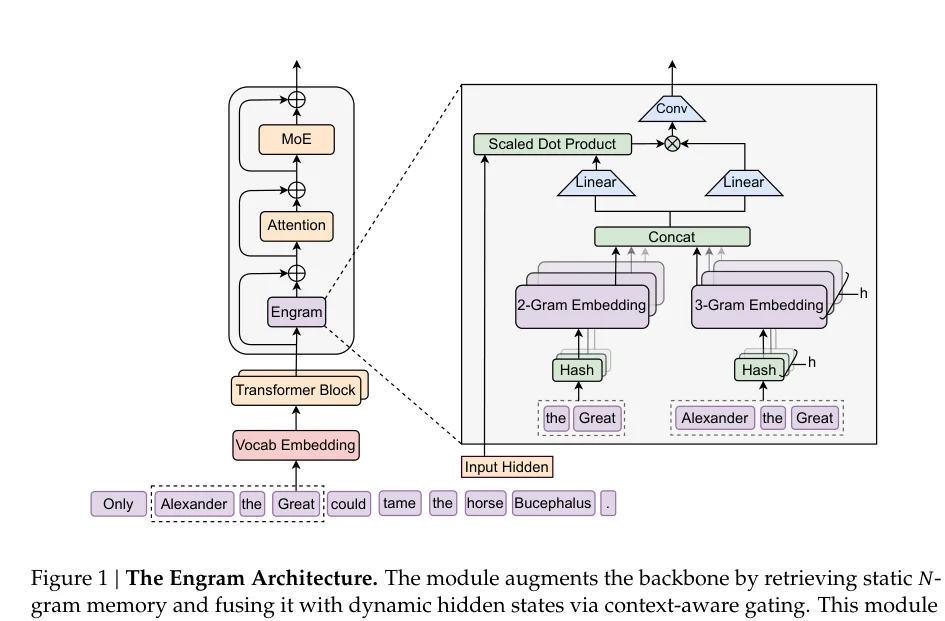
但经典N-gram有个致命问题:组合爆炸。
如果词表有10万个词,那么所有可能的3-gram就有10万的三次方,也就是10的15次方种组合。这显然无法直接存储。
Engram用了几个巧妙的设计来解决这个问题。
分词压缩(Tokenizer Compression):将语义相同但形式不同的token合并。
比如「Apple」和「apple」、「running」和「Running」,虽然分词器给了不同的ID,但语义相同,可以映射到同一个规范ID。
这个设计把12.8万的词表压缩了23%,有效减少了N-gram的组合空间。
即使压缩了词表,完整存储所有N-gram组合仍然不现实。
Engram的解决方案是哈希嵌入。
哈希嵌入:不直接存储所有可能的N-gram,而是用哈希函数把N-gram映射到一个固定大小的嵌入表。
就像图书馆不可能为每本可能存在的书都预留位置,而是用索书号系统来组织有限的书架空间。
哈希会带来碰撞问题,不同的N-gram可能映射到同一个位置。
为了缓解这个问题,Engram使用了多头哈希:
对每个N-gram长度使用K个不同的哈希函数,每个都对应一个独立的嵌入表。
最终把所有检索到的向量拼接起来。
这就像你用多个不同的方法给书编号,如果某本书在一种编号系统下和另一本撞号了,在其他编号系统下大概率不会撞。
静态检索有个问题:它是「上下文无关」的。
同样是「苹果」这个词,在「我吃了一个苹果」和「苹果发布了新iPhone」里意思完全不同。
纯粹的N-gram查找无法区分这种歧义。
Engram的解决方案是引入一个上下文感知的门控机制。
门控机制(Gating):一种动态调节信息流的方法。
就像水龙头,可以控制「开多大」。
在这里,门控用当前的隐藏状态(已经聚合了全局上下文)来决定:检索到的记忆向量要「用多少」。
具体来说,Engram把当前隐藏状态作为Query,把检索到的记忆向量作为Key和Value,计算一个0到1之间的门控值。
如果检索到的内容和当前上下文匹配,门控值接近1,全部使用。
如果不匹配(比如发生了哈希碰撞),门控值接近0,基本忽略。
这个设计非常优雅:它让模型自己学会「什么时候该信记忆,什么时候该信计算」。
现代的高性能模型往往使用多分支架构。
多分支架构:把残差流扩展成多个并行的分支,每个分支可以独立处理不同类型的信息。
就像高速公路分出多条车道,不同类型的车走不同车道,提高整体通行效率。
Engram巧妙地适配了这种架构:
所有分支共享同一个嵌入表和Value投影矩阵,但每个分支有自己的Key投影矩阵。
这意味着不同分支可以从同一份记忆中「看到」不同的侧面,就像同一本书,不同读者关注的重点不同。
有了Engram这个工具,一个自然的问题是:给多少参数给MoE,给多少给Engram?
论文通过实验发现了一个意料之外的结论。
研究者固定了总参数量和计算量,然后调整分配比例。
设ρ为分配给MoE专家的比例,ρ=100%就是纯MoE模型,ρ越小,分给Engram的越多。
结果呈现出一条清晰的U型曲线。
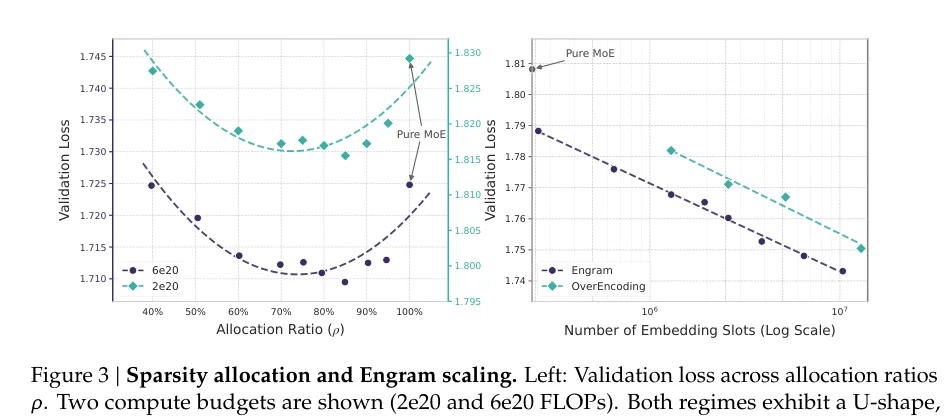
纯MoE(ρ=100%)并不是最优的。
把大约20-25%的稀疏参数预算分配给Engram,性能最好。
而且,这个最优点非常稳定。
无论是57亿参数还是99亿参数的模型,最优分配比例都在75%-80%左右。
这个发现有深刻的含义。
当ρ接近100%时,模型缺乏专门的记忆模块,被迫用计算来「重建」静态知识。
这浪费了宝贵的计算深度。
当ρ接近0时,模型缺乏动态计算能力,遇到需要推理的任务就力不从心。
记忆再多,也无法代替思考。
最优点在中间,说明两种稀疏性确实是互补的。
更有趣的是「无限记忆」实验。
固定MoE骨干,只增加Engram的嵌入数量,从25万扩展到1000万。
结果显示,验证损失遵循清晰的幂律下降。
这意味着:Engram是一个可预测的扩展旋钮。
增加记忆容量,就能获得可预测的性能提升,而且不需要增加计算量。

理论很美好,实战怎么样?
论文训练了四个模型进行对比:
所有模型都在相同的数据上训练了2620亿token,激活参数量完全相同。
结果令人惊讶。
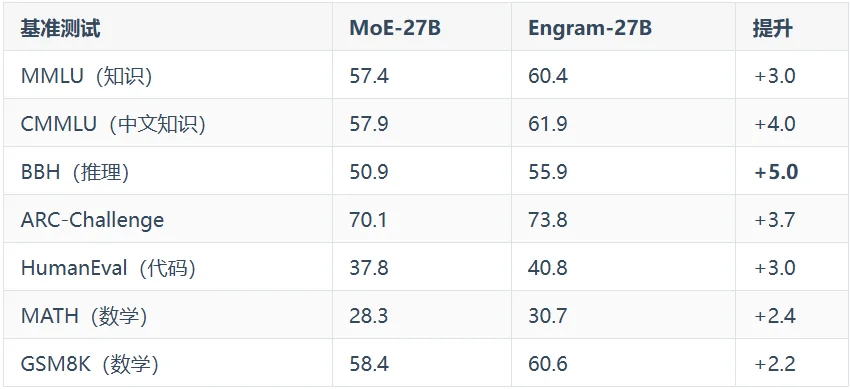
Engram-27B在几乎所有基准上都超过了等参数、等计算量的MoE-27B。
这本身就足够惊艳了,但更有趣的是提升的分布。
直觉上,一个「记忆模块」应该主要帮助知识密集型任务,比如MMLU这种考事实记忆的测试。
但实际上,推理任务的提升反而更大。
BBH(Big Bench Hard)是一个专门测试复杂推理能力的基准,Engram在这上面提升了5分。
代码和数学同样有显著提升。
这是为什么?
为了理解Engram为什么能提升推理能力,论文做了一系列机理分析。
核心发现是:Engram相当于增加了网络的「有效深度」。
什么意思?
研究者用一种叫LogitLens的技术,观察每一层隐藏状态距离最终预测有多远。
LogitLens:一种神经网络可视化方法。把中间层的隐藏状态直接送入最后的预测头,看看输出什么。如果中间层的输出已经很接近最终答案,说明这一层的工作已经接近完成;如果还差很远,说明后面还有很多工作要做。
结果显示,Engram模型在早期层的预测就已经很接近最终答案了。
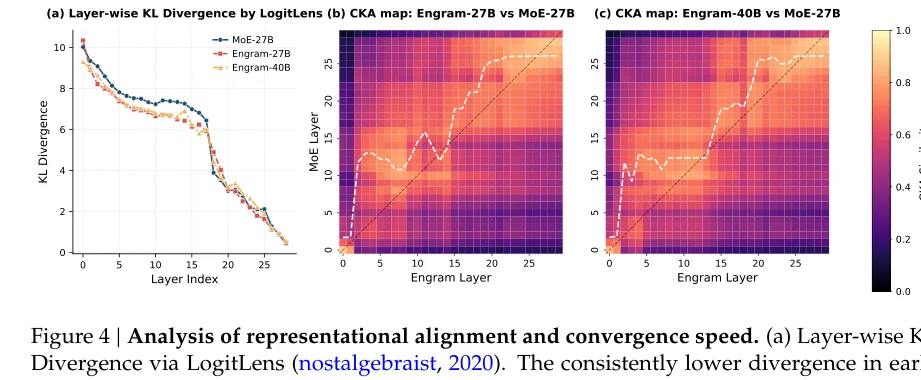
论文还用了一种叫CKA的技术,比较两个模型的表征相似性。
CKA(Centered Kernel Alignment):一种衡量两组神经网络表征相似度的方法。就像比较两张地图画的是不是同一个地方。CKA值越高,说明两层学到的特征越相似。
比较Engram第5层和MoE各层的CKA值,发现Engram第5层最像MoE第12层。
换句话说,Engram的浅层完成了普通模型深层才能完成的工作。
这正好解释了推理能力的提升。
想象一个30层的网络,如果前5层都在忙着「重建静态知识」,真正能用于复杂推理的只有25层。
现在有了Engram,静态知识直接查出来,前5层解放了,可以全部用于更高级的任务。
相当于网络「深」了。
论文还做了一个直观的消融实验:在推理时完全禁用Engram模块。
结果是:
这说明:Engram确实承担了「知识存储」的功能,让骨干网络专注于「理解和推理」。

Engram还带来了一个意外收获:长文本能力大幅提升。
在32K长度的测试中:
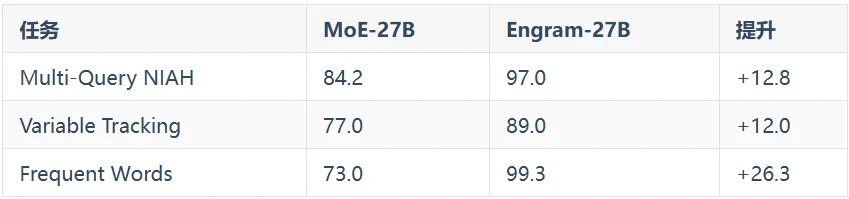
NIAH(Needle in a Haystack)是一种经典的长文本测试:
在一大段无关文本中插入一个关键信息,让模型找出来。
Multi-Query版本更难,需要同时处理多个查询。
Engram在这上面从84.2提升到97.0,几乎完美。
为什么?
论文的解释是:Engram释放了注意力容量。
注意力机制的核心工作是建立长距离依赖。
但在没有Engram的模型中,注意力还要负责处理局部模式,比如识别「Alexander the Great」是一个整体。
有了Engram,局部模式识别被「外包」出去了。
注意力可以专注于它最擅长的事:建立全局联系。
就像一个人,如果不用花精力记电话号码(有手机嘛),就能把更多注意力放在理解对话内容上。
Engram还有一个被低估的优势:它能突破GPU内存的限制。
MoE的专家是动态路由的,需要根据隐藏状态实时决定激活哪些专家。
这意味着所有专家的参数都必须存在GPU上,随时待命。
但Engram不一样。它的索引是确定性的,由输入token序列直接决定。
这意味着:系统可以提前知道需要查哪些记忆向量。
这带来了一个巨大的机会:预取。
预取(Prefetch):在真正需要数据之前,提前把数据从慢速存储搬到快速存储。就像餐厅服务员看到客人在看菜单,就先去厨房通知备菜,等客人点单时菜已经开始做了。
论文在第2层和第15层插入Engram。
当模型在处理第1层时,系统已经知道第2层需要查哪些向量,可以提前从CPU内存搬到GPU。
实验显示,把1000亿参数的Engram表完全放在CPU内存里,推理吞吐量只下降不到3%。
这是一个革命性的数字。
它意味着:Engram可以无限扩展记忆容量,而不受GPU内存限制。
100亿参数不够?那就1000亿。1000亿不够?那就1万亿。
只要你有足够的CPU内存或者SSD空间。
自然语言的N-gram还遵循齐普夫定律(Zipf's Law):
少数高频模式占据了绝大多数查询。
这意味着可以用多级缓存进一步优化:高频向量放GPU,中频放CPU内存,低频放SSD。
论文提供了一些可视化,让我们能直观「看见」Engram在做什么。

门控值α在0到1之间,越接近1说明Engram检索到的内容越被信任。
在英文例子中:
在中文例子中:
这些都是典型的多词表达或命名实体。
有趣的是,门控值高的位置通常在这些短语的最后一个token。
这符合N-gram的工作原理:
当看到「Alexander the」时,Engram检索到的向量可能还有歧义;
当看到完整的「Alexander the Great」时,歧义消除,门控打开。
Engram不只是一个技术改进,它代表了一种建模范式的转变。
过去十年,大模型的扩展主要沿着一个维度:更多计算。
更多的层,更宽的维度,更多的专家。
Engram开辟了另一个维度:更多记忆。
而且这种记忆几乎是「免费」的,不需要额外的计算,不受GPU内存限制。
这让我想到人脑的一个特点。
人脑的神经元数量大约是860亿,但突触连接数量是100万亿。
神经元是「计算单元」,突触连接更像是「记忆单元」。
记忆的容量远大于计算的容量。
也许,下一代AI模型也应该是这样:适量的计算能力,海量的记忆容量。
Engram的另一个启示是基础设施感知设计。
传统上,模型设计和系统优化是两件事。
模型研究者设计架构,系统工程师想办法高效实现。
但Engram从一开始就把「能否高效部署」作为设计约束。
确定性索引、可预取、可分层缓存,这些都是和系统工程师一起设计的。
这种「算法-系统协同设计」可能是未来大模型的标配。

回到开头的问题。
为什么识别「威尔士王妃戴安娜」需要消耗6层网络的计算?
因为Transformer没有「查字典」的能力。
它只能用计算来模拟记忆,用好几层网络来「重建」一个本可以直接查出来的事实。
Engram给了模型一本字典。
而且这本字典几乎不增加计算成本,可以无限扩展,还能让模型把更多「脑力」用在真正需要思考的地方。
有时候,最深刻的创新不是发明全新的东西,而是重新发现古老智慧的价值。
N-gram模型诞生于信息论的黎明期,比神经网络还要古老。
几十年后,它以Engram的形式回归,成为大模型架构的新支柱。
历史总是螺旋上升。
本文解读基于DeepSeek团队论文「Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models」。原论文代码已在GitHub开源:https://github.com/deepseek-ai/Engram
文章来自于“向阳乔木推荐看”,作者 “向阳乔木”。


【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
