# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
前段时间,AI大神Karpathy上线的AI大课,已经收获了全网15万次播放量。
当时还有网友表示,这2小时课程的含金量,相当于大学4年。
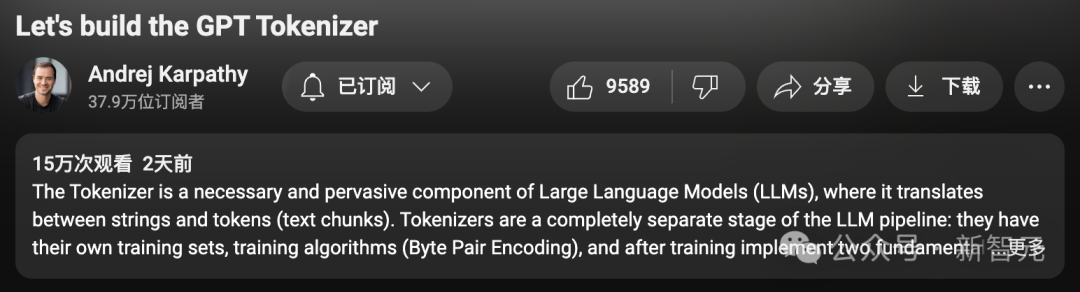
就在这几天,Karpathy又萌生了一个新的想法:
那便是,将2小时13分钟的「从头开始构建GPT分词器」的视频,转换为一本书的章节(或者博客文章)形式,专门讨论「分词」。

具体步骤如下:
- 为视频添加字幕或解说文字。
- 将视频切割成若干带有配套图片和文字的段落。
- 利用大语言模型的提示工程技术,逐段进行翻译。
- 将结果输出为网页形式,其中包含指向原始视频各部分的链接。
更广泛地说,这样的工作流程可以应用于任何视频输入,自动生成各种教程的「配套指南」,使其格式更加便于阅读、浏览和搜索。
这听起来是可行的,但也颇具挑战。
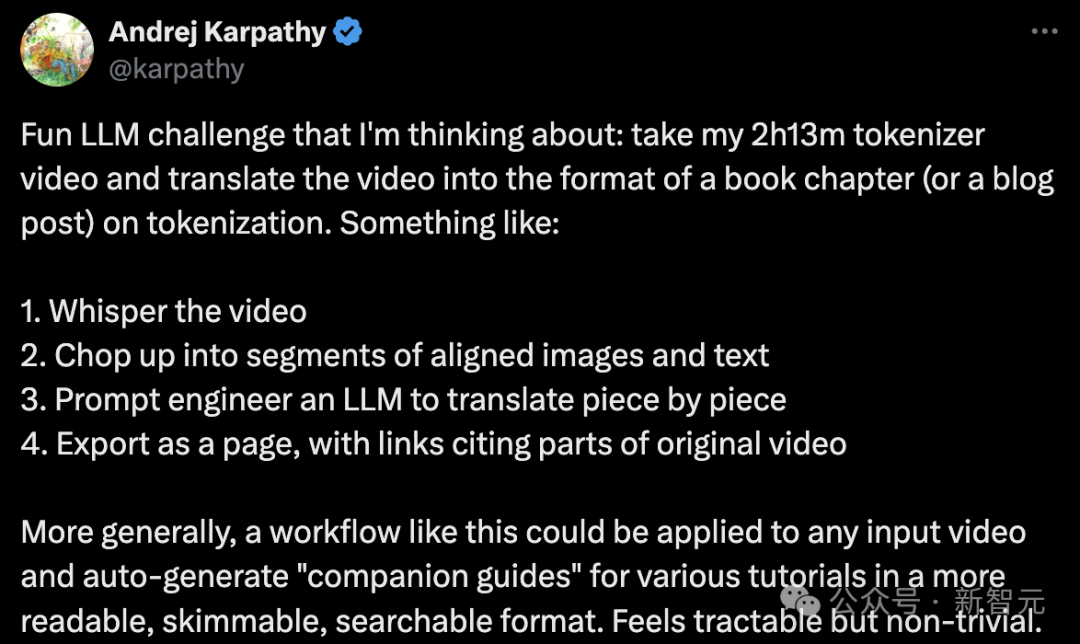
他在GitHub项目minbpe下,写了一个例子来阐述自己的想象。
地址:https://github.com/karpathy/minbpe/blob/master/lecture.md
Karpathy表示,这是自己手动完成的任务,即观看视频并将其翻译成markdown格式的文章。
「我只看了大约4分钟的视频(即完成了3%),而这已经用了大约30分钟来写,所以如果能自动完成这样的工作就太好了」。
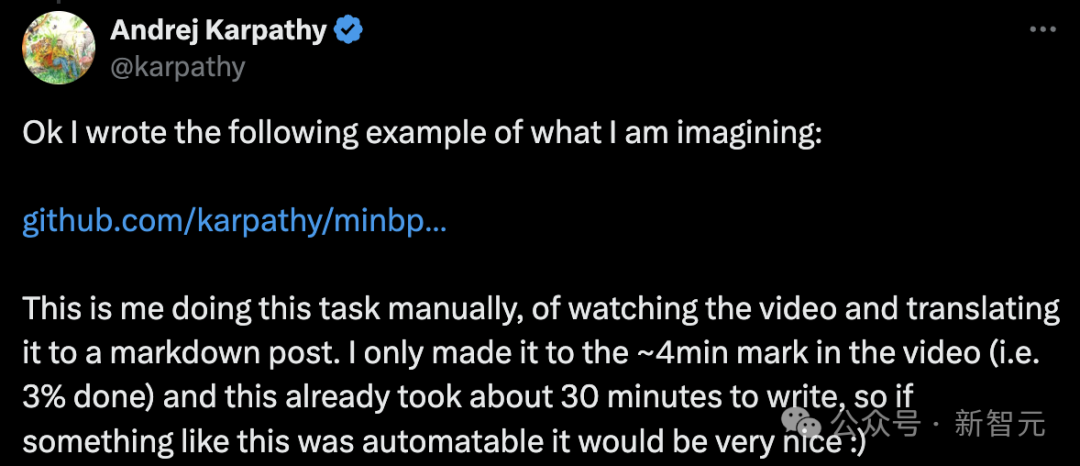
接下来,就是上课时间了!
大家好,今天我们将探讨LLM中的「分词」问题。
遗憾的是,「分词」是目前最领先的大模型中,一个相对复杂和棘手的组成部分,但我们有必要对其进行详细了解。
因为LLM的许多缺陷可能归咎于神经网络,或其他看似神秘的因素,而这些缺陷实际上都可以追溯到「分词」。
字符级分词
那么,什么是分词呢?
事实上,在之前的视频《让我们从零开始构建 GPT》中,我已经介绍过分词,但那只是一个非常简单的字符级版本。
如果你去Google colab查看那个视频,你会发现我们从训练数据(莎士比亚)开始,它只是Python中的一个大字符串:
First Citizen: Before we proceed any further, hear me speak.
All: Speak, speak.
First Citizen: You are all resolved rather to die than to famish?
All: Resolved. resolved.
First Citizen: First, you know Caius Marcius is chief enemy to the people.
All: We know't, we know't.
但是,我们如何将字符串输入LLM呢?
我们可以看到,我们首先要为整个训练集中的所有可能字符,构建一个词汇表:
# here are all the unique characters that occur in this text
chars = sorted(list(set(text)))
vocab_size = len(chars)
print(''.join(chars))
print(vocab_size)
# !$&',-.3:;?ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz
# 65
然后根据上面的词汇表,创建用于在单个字符和整数之间进行转换的查找表。此查找表只是一个Python字典:
stoi = { ch:i for i,ch in enumerate(chars) }
itos = { i:ch for i,ch in enumerate(chars) }
# encoder: take a string, output a list of integers
encode = lambda s: [stoi[c] for c in s]
# decoder: take a list of integers, output a string
decode = lambda l: ''.join([itos[i] for i in l])
print(encode("hii there"))
print(decode(encode("hii there")))
# [46, 47, 47, 1, 58, 46, 43, 56, 43]
# hii there
一旦我们将一个字符串转换成一个整数序列,我们就会看到每个整数,都被用作可训练参数的二维嵌入的索引。
因为我们的词汇表大小为 vocab_size=65 ,所以该嵌入表也将有65行:
class BigramLanguageModel(nn.Module):
def __init__(self, vocab_size):
super().__init__()
self.token_embedding_table = nn.Embedding(vocab_size, n_embd)
def forward(self, idx, targets=None):
tok_emb = self.token_embedding_table(idx) # (B,T,C)
在这里,整数从嵌入表中「提取」出一行,这一行就是代表该分词的向量。然后,该向量将作为相应时间步长的输入输入到Transformer。
使用BPE算法进行「字符块」分词
对于「字符级」语言模型的天真设置来说,这一切都很好。
但在实践中,在最先进的语言模型中,人们使用更复杂的方案来构建这些表征词汇。
具体地说,这些方案不是在字符级别上工作,而是在「字符块」级别上工作。构建这些块词汇表的方式是使用字节对编码(BPE)等算法,我们将在下面详细介绍该算法。
暂时回顾一下这种方法的历史发展,将字节级BPE算法用于语言模型分词的论文,是2019年OpenAI发表的GPT-2论文Language Models are Unsupervised Multitask Learners。

论文地址:https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
向下翻到第2.2节「输入表示」,在那里他们描述并激励这个算法。在这一节的末尾,你会看到他们说:
词汇量扩大到50257个。我们还将上下文大小从512增加到1024个token,并使用512更大batchsize。
回想一下,在Transformer的注意力层中,每个token都与序列中之前的有限token列表相关联。
本文指出,GPT-2模型的上下文长度从GPT-1的512个token,增加到1024个token。
换句话说,token是 LLM 输入端的基本「原子」。
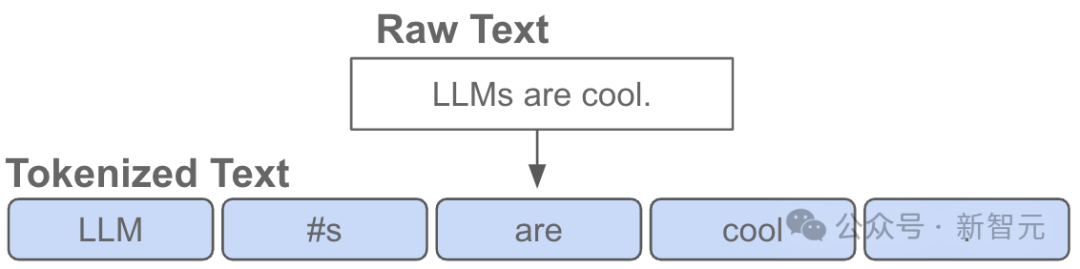
「分词」是将Python中的原始字符串,转换为token列表的过程,反之亦然。
还有一个流行的例子可以证明这种抽象的普遍性,如果你也去Llama 2的论文中搜索「token」,你将得到63个匹配结果。
比如,该论文声称他们在2万亿个token上进行了训练,等等。

论文地址:https://arxiv.org/pdf/2307.09288.pdf
浅谈分词的复杂性
在我们深入探讨实现的细节之前,让我们简要地说明一下,需要详细了解「分词」过程的必要性。
分词是LLM中许多许多怪异问题的核心,我建议你不要忽略它。
很多看似神经网络架构的问题,实际上都与分词有关。这里只是几个例子:
- 为什么LLM不会拼写单词?——分词
- 为什么LLM不能执行超简单的字符串处理任务,比如反转字符串?——分词
- 为什么LLM在非英语语言(比如日语)任务中更差?——分词
- 为什么LLM不擅长简单的算术?——分词
- 为什么GPT-2在用Python编码时遇到了更多的问题?——分词
- 为什么我的LLM在看到字符串<|endoftext|>时突然停止?——分词
- 我收到的关于「trailing whitespace」的奇怪警告是什么?——分词
- 如果我问LLM关于「SolidGoldMagikarp」的问题,为什么它会崩溃?——分词
- 为什么我应该使用带有LLM的YAML而不是JSON?——分词
- 为什么LLM不是真正的端到端语言建模?——分词

我们将在视频的末尾,再回到这些问题上。
接下来,让我们加载这个分词WebApp。
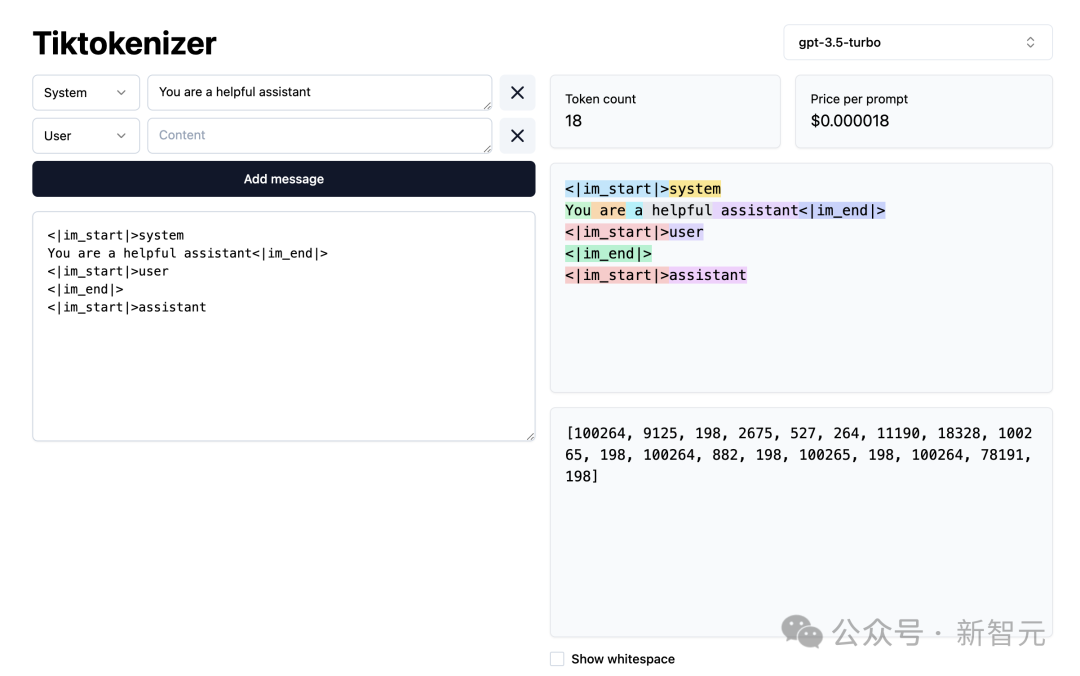
地址:https://tiktokenizer.vercel.app/
这个Web应用程序的优点是,分词在网络浏览器中实时运行,允许你轻松地在输入端输入一些文本字符串,并在右侧看到分词结果。
在顶部,你可以看到我们当前正在使用 gpt2 分词器,并且可以看到,这个示例中粘贴的字符串目前正在分词为 300个token。
在这里,它们用颜色明确显示出来:
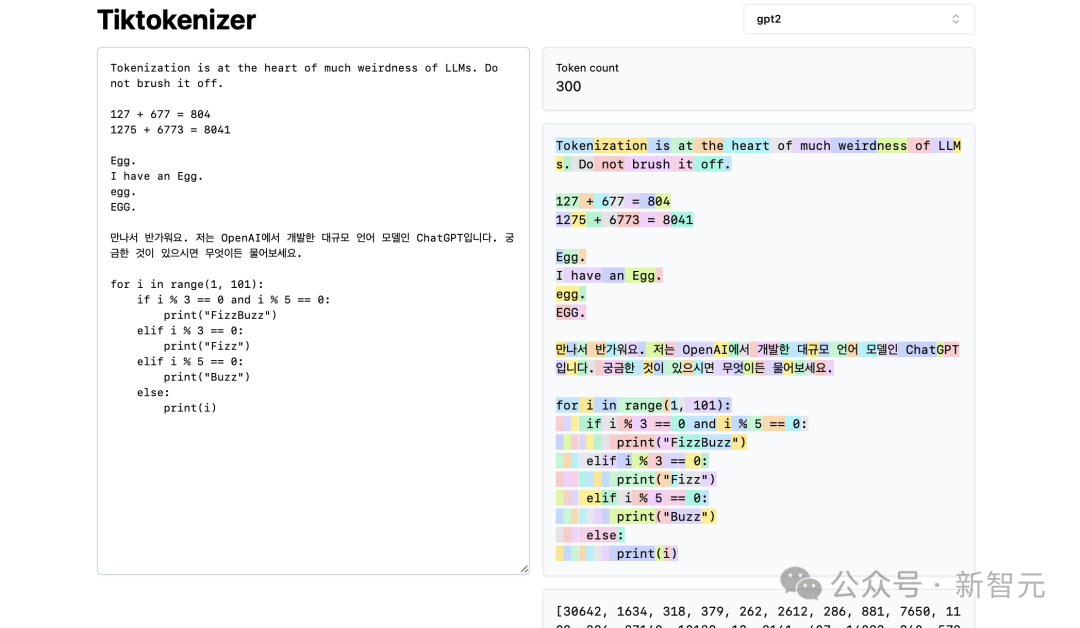
比如,字符串「Tokenization」编码到token30642,其后是token是1634。
token「is」(注意,这是三个字符,包括前面的空格,这很重要!)是318。
注意使用空格,因为它在字符串中是绝对存在的,必须与所有其他字符一起分词。但为了清晰可见,在可视化时通常会省略。
你可以在应用程序底部打开和关闭它的可视化功能。同样,token「at」是379,「the」是262,依此类推。
接下来,我们有一个简单的算术例子。
在这里,我们看到,分词器对数字的分解可能不一致。比如,数字127是由3个字符组成的token,但数字677是因为有2个token:6(同样,请注意前面的空格)和77。
我们依靠LLM来解释这种任意性。
它必须在其参数内部和训练过程中,了解这两个token(6和77实际上组合成了数字677)。
同样,我们可以看到,如果LLM想要预测这个总和的结果是数字804,它必须在两个时间步长内输出:
首先,它必须发出token「8」,然后是token「04」。
请注意,所有这些拆分看起来都是完全任意的。在下面的例子中,我们可以看到1275是「12」,然后「75」,6773实际上是三个token「6」、「77」、「3」,而8041是「8」、「041」。
(未完待续...)
(TODO:若想继续文字版的内容,除非我们想出如何从视频中自动生成)

网友表示,太好了,实际上我更喜欢阅读这些帖子,而不是看视频,更容易把握自己的节奏。

还有网友为Karpathy出谋划策:
「感觉很棘手,但使用LangChain可能是可行的。我在想是否可以使用whisper转录,产生有清晰章节的高级大纲,然后对这些章节块并行处理,在整体提纲的上下文中,专注于各自章节块的具体内容(也为每个并行处理的章节生成配图)。然后再通过LLM把所有生成的参考标记,汇编到文章末尾」。
有人为此还写了一个pipeline,而且很快便会开源。

参考资料:
https://x.com/karpathy/status/1760740503614836917?s=20
文章来自于微信公众号 “新智元”




【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
