# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
如果人类的大脑像现在的LLM Agent一样工作,记住每一句今天明天的废话,我们在五岁时就会因为内存溢出而宕机。真正的智能,核心不在于“存储”,而在于高效的“遗忘”与“重组”。
这一仿生学理念正是SimpleMem的灵魂。这项由UNC-Chapel Hill、UC Berkeley和UCSC学者提出的最新研究,并未堆砌更长的Context Window,而是引入了一套模拟生物“海马体-新皮层”交互的记忆代谢系统。

SimpleMem通过熵感知过滤和递归巩固机制,证明了高质量的记忆可以是流动的、结构化的。它不仅解决了长期交互中的“记忆膨胀”难题,更以SOTA的姿态证明:在长时记忆领域,精密的算法设计远比暴力堆砌显存更有效。
项目地址:https://github.com/aiming-lab/SimpleMem
SimpleMem的设计基于一个核心假设:记忆如果不进行结构化处理和主动遗忘,就是数据垃圾。
传统的RAG(检索增强生成)系统倾向于“只存不改”,随着时间推移,索引库会变得臃肿且充满噪声。SimpleMem引入了类似生物大脑的“互补学习系统(CLS)”理论
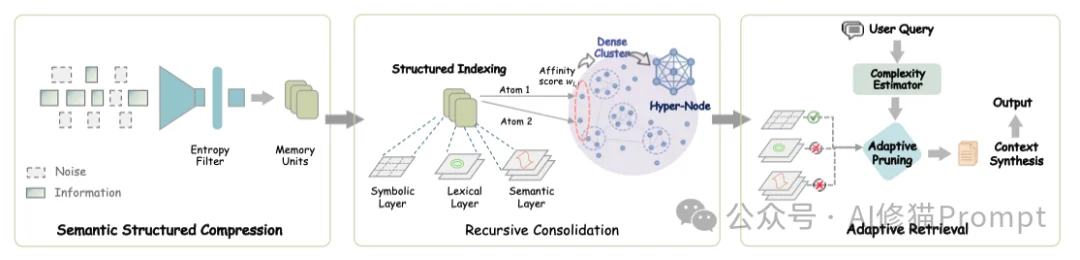
将记忆处理分为三个动态阶段:
接下来的章节,我们将深入每一个环节的技术细节。
在长期的交互中,用户产生的对话包含大量低价值信息(如“你好”、“嗯嗯”、“明天见”)。如果不加处理地存入数据库,这些噪声会稀释高价值信息。SimpleMem在这一阶段执行两个关键操作:熵感知过滤与记忆原子化。

评分公式如下:
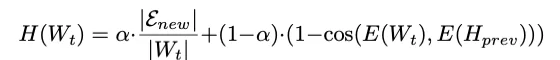

这是SimpleMem与传统RAG最本质的区别。原始对话往往充满了指代模糊和相对时间,如果直接切片存储,在脱离上下文检索时将毫无意义。
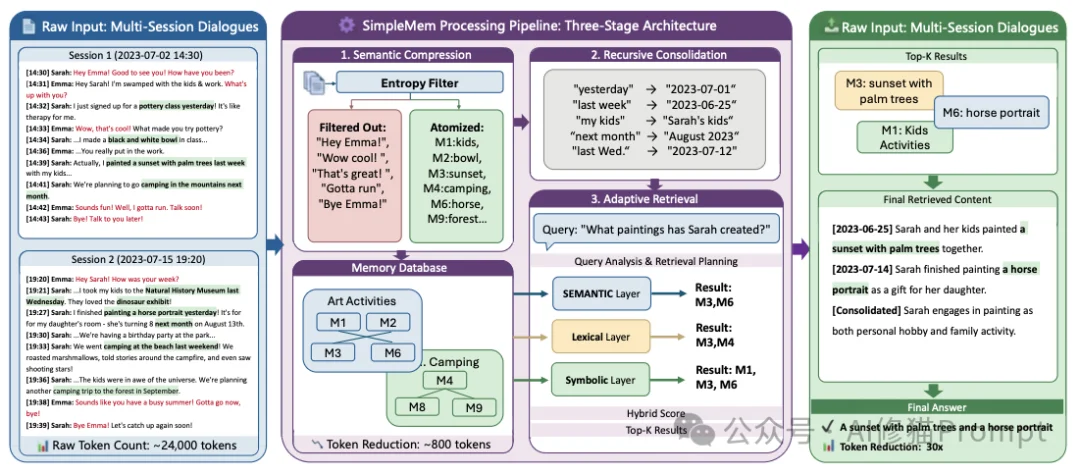
例如,原始对话片段:
"他说明天去那家店。"
如果在两天后检索这句话,您无法知道“他”是谁,“明天”是哪天,“那家店”是哪家。SimpleMem强制执行原子化(Atomization)转换:

"Bob同意在2025-11-20去星巴克(第五大道店)。"
这种处理使得每一条记忆都成为独立、自包含的事实(Self-contained Fact),彻底解决了长程推理中的时间错位问题。实验数据表明,仅此一项改进,就将时间推理任务的F1分数从25.40提升至58.62。
即使过滤了噪声,随着时间推移,大量琐碎的独立事实(如“用户周一早上喝咖啡”、“用户周二早上喝咖啡”)依然会堆积。SimpleMem引入了后台异步巩固机制。
为了支持不同类型的查询,SimpleMem为每个记忆单元构建了三层索引:
研究者设计了一个受生物学启发的亲和力评分(Affinity Score),用于判断哪些记忆应该被“合并”:
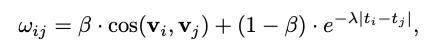

案例说明:
系统不再存储30条“用户早上8点喝咖啡”的记录,而是将其“坍缩”为一条高级抽象记忆:
[抽象记忆] 用户有晨间饮用咖啡的习惯,通常在8:00 AM左右。
原始的细节被归档,活跃内存中只保留抽象节点。这种机制保证了记忆库的拓扑结构始终保持紧凑,检索复杂度不会随时间线性增长。
这是SimpleMem实现极致Token效率的关键。
目前的RAG系统通常采用固定的 Top-K 策略(例如,无论问题多简单,都检索10个片段)。这带来了双重问题:

检索深度计算公式:
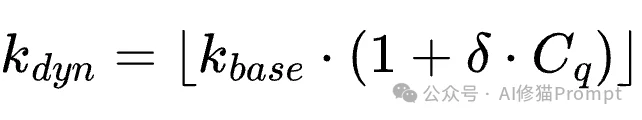

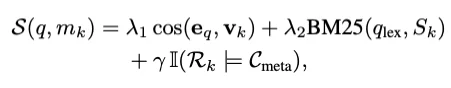
这一公式精妙地结合了向量语义、关键词匹配和SQL式的硬约束(如时间范围过滤),确保检索结果既相关又精确。
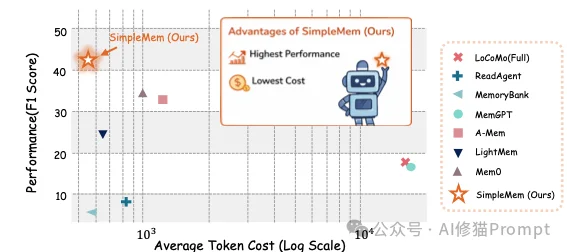
研究者在LoCoMo(Long Context, Multi-turn)基准数据集上对SimpleMem进行了全面评估。该数据集包含200-400轮的超长对话,专门测试模型处理长期依赖的能力。
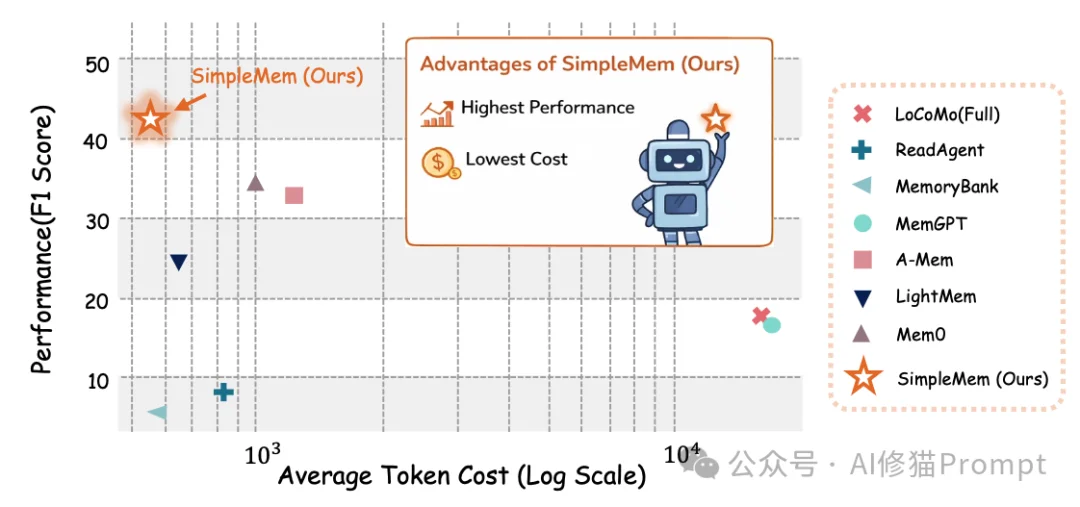
在GPT-4o-mini后端上,SimpleMem的表现超越了所有基线模型:
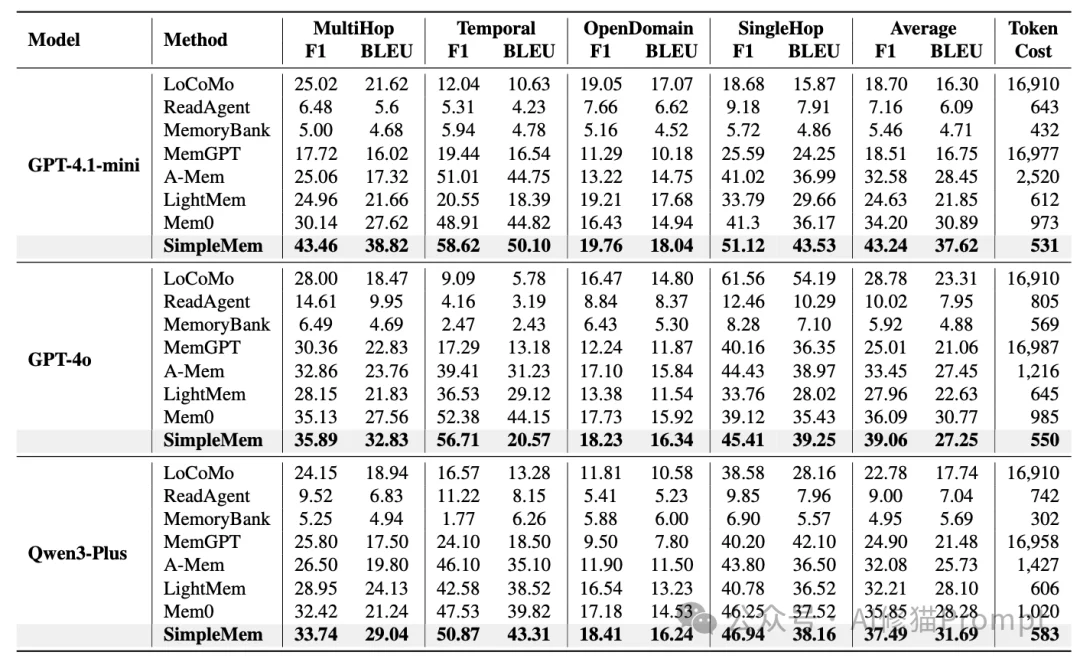
这是SimpleMem最具落地价值的数据:
这意味着,在相同的Token预算下,SimpleMem能够支持更长、更复杂的交互生命周期。
实验数据揭示了一个反直觉的现象:优质的记忆结构比模型本身的智力更重要。
这是一个很厉害的结果:搭载SimpleMem的廉价Mini模型,在长程推理任务上,击败了搭载传统记忆系统的旗舰级GPT-4o。
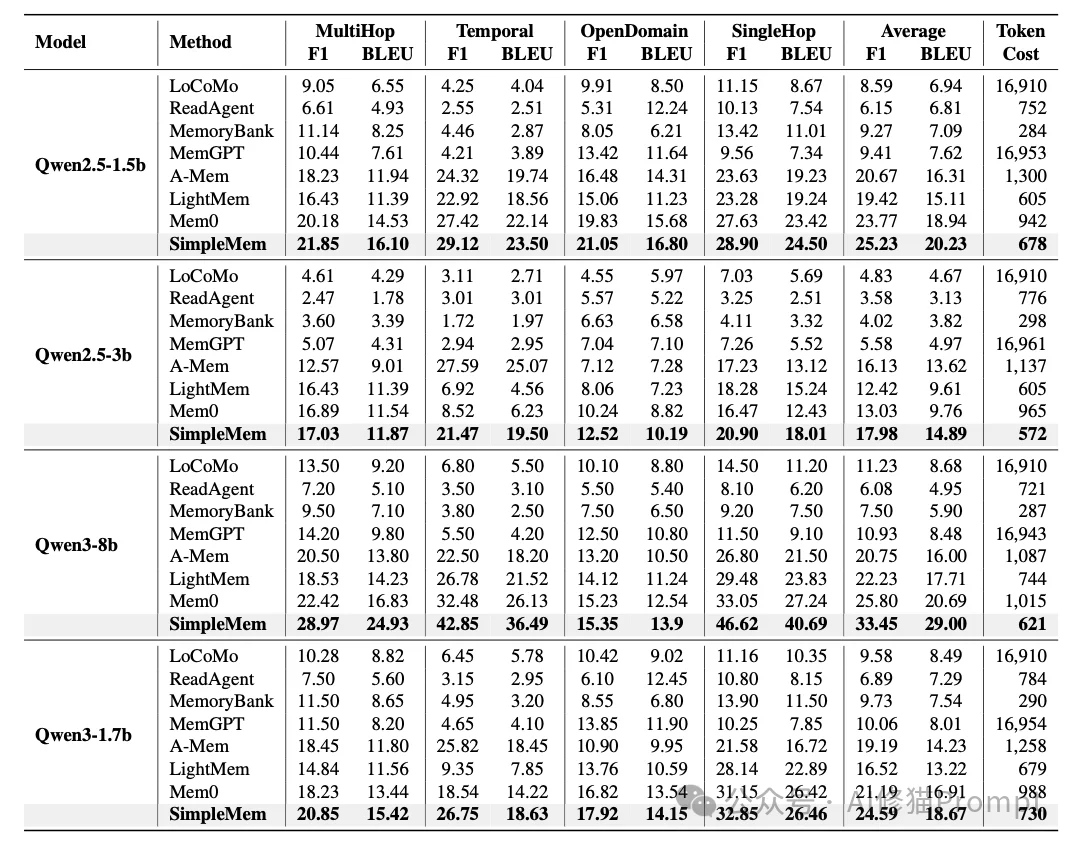
此外,在端侧小模型对比中,搭载SimpleMem的1.5B模型 (F1 20.23) 也击败了搭载Mem0的1.7B模型 (F1 16.91)。
这证明了通过算法优化记忆结构,可以显著降低对模型参数量的依赖。
研究者通过移除组件验证了架构的合理性:

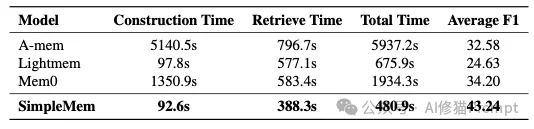
虽然SimpleMem表现优异,但在实际部署中,您需要注意一下SimpleMem的构建速度(92.6秒/样本)远快于图数据库方法(如A-Mem的5140秒),但相比纯文本追加,它依然引入了额外的计算开销(LLM调用用于原子化和摘要)。
SimpleMem的成功向我们揭示了LLM记忆系统的未来演进方向:从粗放的“存储桶”向精细的“代谢体”转变。如果您正在构建长生命周期Agent(如个人助理、长期陪伴AI、项目管理机器人),那么SimpleMem则非常值得您了解一下。
文章来自于“AI修猫Prompt”,作者 “AI修猫Prompt”。


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
