# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
人类程序员碰到棘手bug通常会上网查询前辈经验。
当前AI虽然开始具备联网搜索能力,但仍不能很好地从网络经验中获取修复bug的能力。
让AI学习人类程序员的工作流程或许有助于其提升bug修复能力,名为MemGovern的项目团队在此思路下做出的尝试近期得到了良好的效果。
在自动化软件工程(SWE)领域,大语言模型驱动的代码智能体(Code Agents)虽然在编程范式上带来了变革,但它们目前普遍面临“封闭世界”的认知局限:现有的智能体往往试图从零开始修复Bug,或者仅依赖仓库内的局部上下文,而忽略了GitHub等平台上积累的浩瀚历史人类经验。
事实上,人类工程师在解决复杂问题时,往往会搜索开源社区,借鉴相似问题的历史解决方案。
然而,直接让智能体利用这些“开放世界”的经验极具挑战,因为真实的Issue和Pull Request(PR)数据充斥着非结构化的社交噪音、模棱两可的描述以及碎片化的信息。
为了突破这一壁垒,前沿开源学术社区QuantaAlpha联合中国科学院大学(UCAS)、新加坡国立大学(NUS)、北京大学(PKU)、华东师范大学(ECNU)等团队提出了MemGovern框架。
该框架并未采用简单的检索增强(RAG)路径,而是提出了一套完整的“经验精炼”机制,将杂乱的GitHub数据转化为智能体友好的结构化记忆,并结合了Deep Research的思想提出了“Experiential Memory Search”策略,实现了从历史经验中提取可复用修复逻辑的闭环。
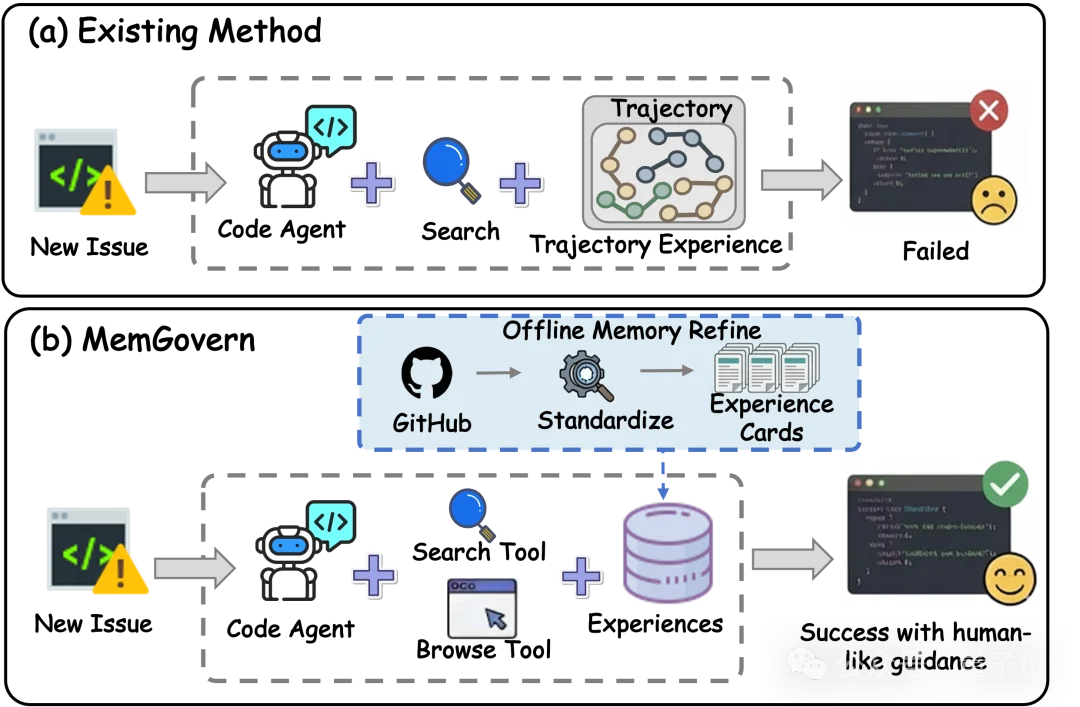
现有的Code Agent(如SWE-Agent)在处理复杂Bug时,往往陷入“不知所措”的境地,因为它们缺乏历史记忆。虽然GitHub是一个巨大的宝库,但直接把Issue和PR丢给AI效果并不好,原因在于:
1.噪声极大:原始讨论中充斥着“感谢”、“合并请求”等无关社交用语。2.非结构化:不同项目的日志、报错信息和修复逻辑混杂在一起,缺乏统一格式。3.难以检索:简单的语义匹配容易被表面关键词误导,无法触达深层的修复逻辑。
经验精炼机制(Experience Refinement Mechanism)
MemGovern并没有直接将原始的GitHub Issue和PR扔给智能体,而是构建了一套层次化的筛选与内容净化流水线。
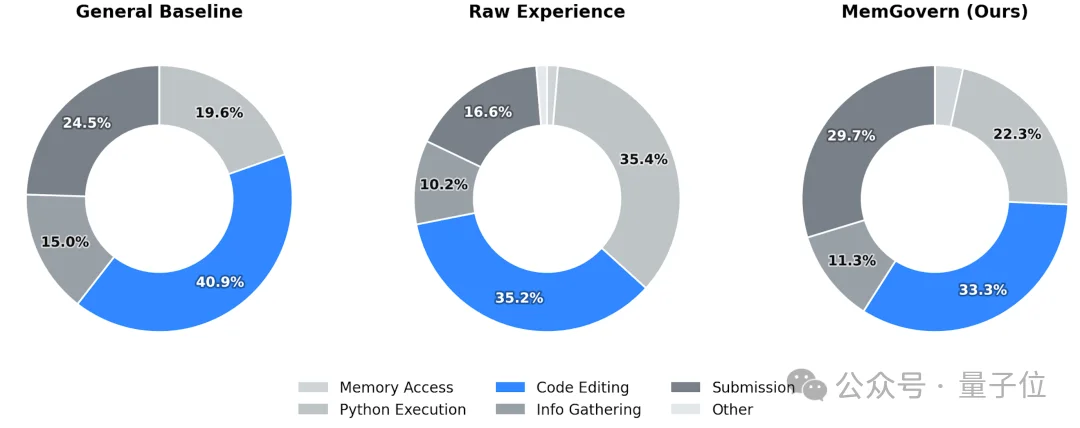
这种结构化设计有效解决了检索信号与推理逻辑混淆的问题,显著提升了知识的可用性。目前,团队已成功构建了包含135,000条高保真经验卡片的知识库。
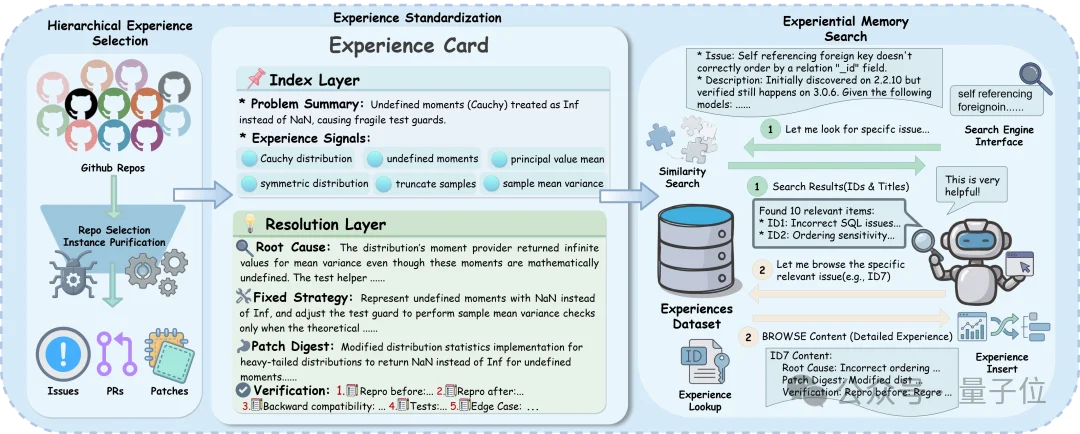
传统的RAG(检索增强生成)往往是一次性把检索结果塞给模型,容易导致上下文超长且充满噪声。MemGovern采用了更符合人类直觉的Search-then-Browse(先搜后看)模式:
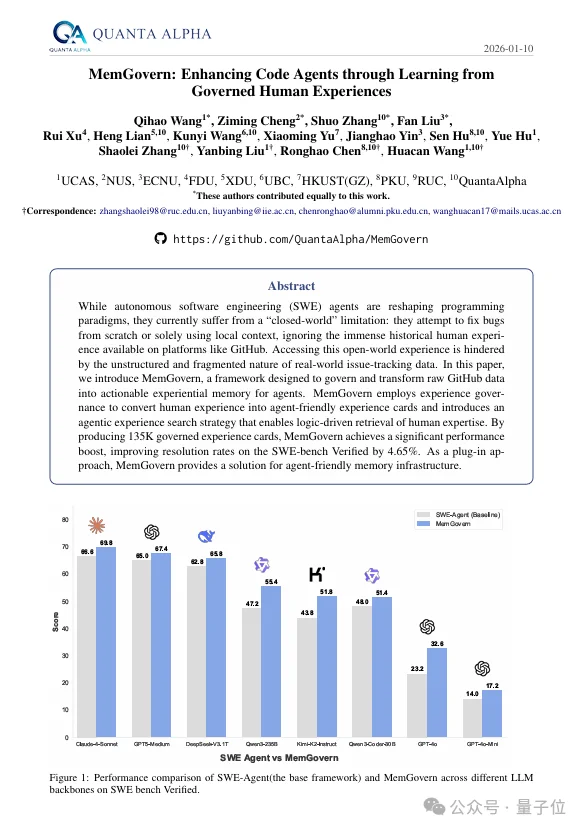
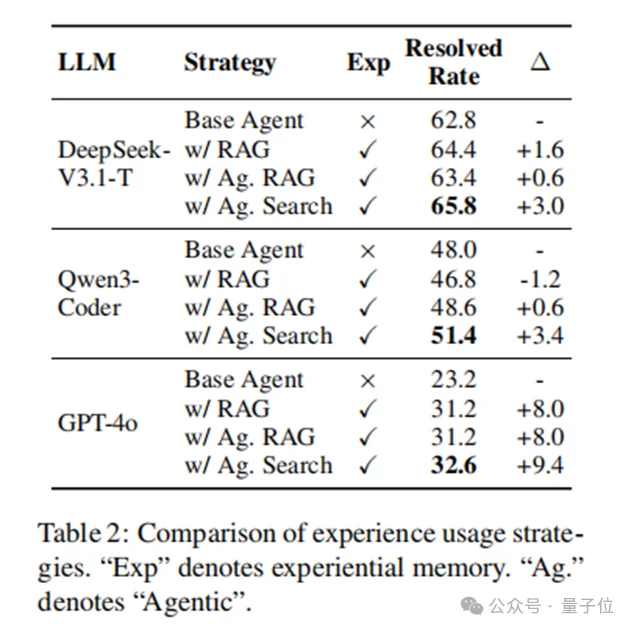
研究团队在SWE-bench Verified上进行了详尽的评测。结果显示,MemGovern在所有测试模型上都取得了显著提升。
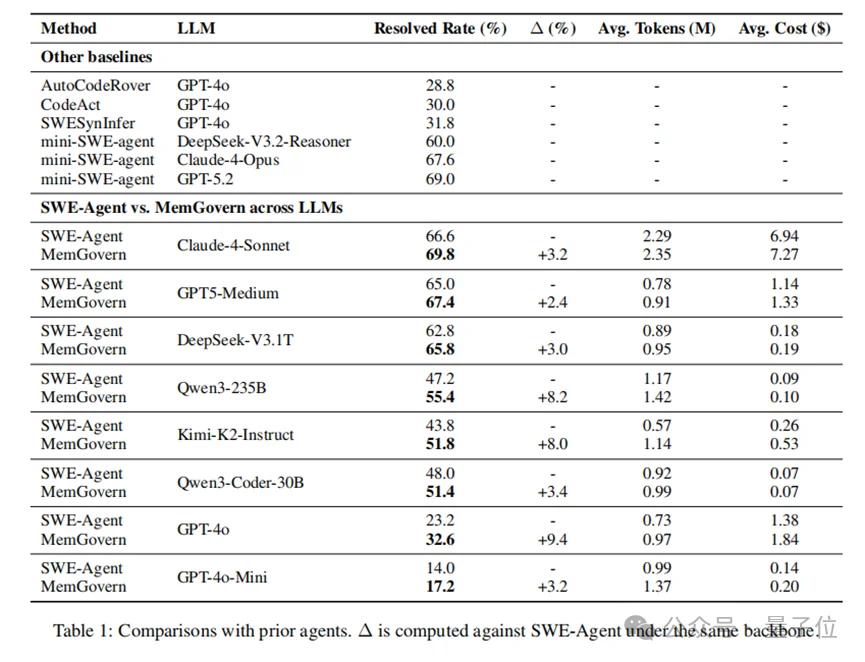
实验数据清晰地表明,MemGovern的提升是稳健且模型无关的。对于基础能力较弱的模型,MemGovern提供的外部经验能够带来更为显著的性能飞跃。
在Django框架的一个真实Bug(order by导致崩溃)中,我们可以清晰地看到MemGovern的价值。

传统Agent(No Experience):
缺乏经验的智能体只能看到报错表象。
它采取了一种“防御性编程”的策略,简单粗暴地加了一个类型检查来绕过报错。但这实际上违反了函数的API规范——它返回了错误的原始对象而非预期的处理结果。
这种“掩耳盗铃”式的修复虽然暂时消除了运行时的报错,却导致下游核心功能因数据类型不匹配而失效,最终依然无法通过测试用例。
MemGovern Agent:
智能体检索到了一条相似的历史经验。
经验卡片中的“Fix Strategy”明确指出:“不要仅仅绕过对象,而应该进行显式的类型检查并提取字段名”。
依据这条指引,智能体写出了完美的修复代码,既修复了Crash,又保留了原有功能。
MemGovern的提出,不仅是性能指标上的突破,更重要的是,它为AI智能体如何有效利用海量的非结构化人类调试经验指明了一条清晰可行的道路。
它证明了将GitHub上杂乱的原始Issue与PR经过经验加工后能被视为可检索、可验证、可迁移的“经验记忆”,而非充满噪声的“干扰数据”,是打破智能体封闭世界的限制、解决复杂现实世界Bug的强大范式。
未来,MemGovern所开创的经验重塑范式,其潜力绝不仅限于代码领域。
这种将非结构化的人类专业经验转化为机器可读记忆的方法,具有极强的通用性与推广价值。它为法律咨询、医疗诊断等同样高度依赖历史案例与专家经验的垂直领域,提供了一套标准化的模版。
期待MemGovern的理念能走出代码仓库,完成更多需要“以史为鉴”的复杂智力任务,为构建跨领域的、通用的智能体记忆基础设施奠定基石。
论文标题:
MemGovern: Enhancing Code Agents through Learning from Governed Human Experiences
论文链接:
https://arxiv.org/abs/2601.06789
开源代码:
https://github.com/QuantaAlpha/MemGovern
关于QuantaAlpha
QuantaAlpha成立于2025年4月,由来自清华、北大、中科院、CMU、港科大等名校的教授、博士后、博士与硕士组成。我们的使命是探索智能的“量子”,引领智能体研究的“阿尔法”前沿——从CodeAgent到自进化智能,再到金融与跨领域专用智能体,致力于重塑人工智能的边界。
2026年,我们将在CodeAgent(真实世界任务的端到端自主执行)、DeepResearch、AgenticReasoning/Agentic RL、自进化与协同学习等方向持续产出高质量研究成果,欢迎对我们方向感兴趣的同学加入我们!
团队主页:
https://quantaalpha.github.io/
文章来自于微信公众号 “量子位”,作者 “量子位”


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
