# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
今天是一期硬核的话题讨论:
Coding Agent 评测。
AI 编程能力进步飞速,在国外御三家和国产中厂四杰的努力下,AI 编程基准 SWE-bench 的分数从年初的 30% 硬生生拉到了年底的 70%+。
2025 年用 AI 写代码成了日常,我在 X 上看到有开发者说:“我发布的有些代码自己从未读过”。
这恐怕就是现在 Vibe Coding 的常态。AI 写代码,AI 跑测试,人类就负责点确认。
但是,AI 写的代码测试都通过了,就真的没有问题了吗?
如果你关注模型榜单,就会知道 AI 编程的主流评测基准大致有:
这些主流的 Coding Agent Benchmark 的核心指标是:Pass@k(k 次尝试中通过测试的比例)。
只要最终 patch 通过测试,无论过程如何都算成功。
但是,Coding Agent 的过程对了吗?
比如:
这些过程中的“违规操作”,SWE-bench 都看不见。
更关键的是,真实的 Coding agent 需要同时处理:
这是一个优先级排序和冲突解决的复杂博弈,但传统 benchmark 对此完全失明, 只关注「能不能解决问题」,不关注「在多重约束下能不能正确解决问题」。
而这,恰恰是 Agentic AI 时代的核心需求。
我们能造出完成任务的 Agent,但不知道它们是怎么完成的,不知道它们在什么情况下会失败。
Sourcegraph 研究员 Stephanie Jarmak 说出了一个真相—
我们构建 Agent 的能力,已经远远甩开了我们评估 Agent 的能力。
昨天,我看到前不久上市的 MiniMax 开源了一个新基准—OctoCodingBench。
传送门:
huggingface.co/datasets/MiniMaxAI/OctoCodingBench
我觉得这个事儿还挺有意义的。
一是做评测基准这种又苦又累不讨好的事儿,企业很少会做;二是瞄准了行业盲区,可以把 SWE-bench 看不见的“编程过程违规”,揪出来并且量化成指标。
它首次引入了—过程评估。不只关注任务的解决率,还会关注 Agent 在解决过程中是否遵循指令和规则。
它的核心思路是不再把 Coding Agent 当成「会做题的模型」,而是当成「要上生产的队友」来考核。
它不像传统题库那样做“填空题”,而是直接拉起 Docker 容器,进行全链路的仿真测试:
1. 环境仿真,注入真实的项目约束:
每个测试用例都会创建一个模拟的代码仓库,里面包含:
2.压力测试:多重指令冲突与记忆干扰
这是 OctoCodingBench 最创新的部分——它会主动给 Agent 挖坑。
OctoCodingBench 测试智能体对 7 种不同指令来源的合规性——

这些指令同时出现,Agent 能正确处理吗?
3. 轨迹收集与 LLM-as-Judge
传统 benchmark 只看最终 diff,OctoCodingBench 收集完整的交互轨迹:
然后用 LLM 作为裁判,逐条检查是否有违规操作。
目前包含 72 个精心设计的测试用例,覆盖 Python、Java、C++ 等多语言。每个用例都针对一个特定的「过程遵循」场景,类别分布如下:

OctoCodingBench 设计了两个互补的指标:

1.Check-level Success Rate(CSR)— 过程规范性
检查 Agent 在执行过程中是否遵循了所有约束条件:
2.Instance-level Success Rate(ISR)— 综合成功率
任务是否最终正确完成且无违规。这里有个关键设计:「单违规即失败」机制。
即使最终结果正确,只要过程中违反任何一个约束,整个任务就判定为失败。听起来很严格,但这才是企业级开发的真实要求啊!
MiniMax 公布的测试结果,给当下的 Coding Agent 泼了一盆冷水,也给了一点惊喜。
几乎所有模型的 CSR 指数都能达到 80% 以上,说明模型大概懂规则。但 ISR 出现了断崖式下跌。
即便是地表最强的 Claude 4.5 Opus,任务通过率也只有 36.2%。
这意味着,在接近 2/3 的任务中,即使是目前的绝对强者,也会在某个细微的规范上“违规。
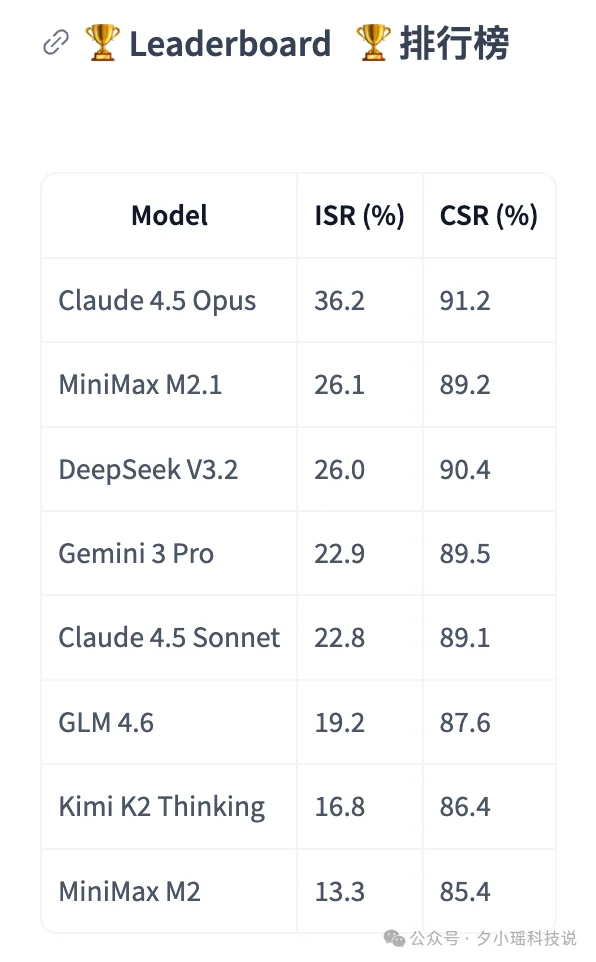
看榜单细节,开源和国产模型正在快速逼近闭源巨头。MiniMax M2.1 和 DeepSeek V3.2 的 ISR 分别达到了 26.1% 和 26%。
这个成绩不仅咬得很紧,甚至在部分指标上超过了公认强大的 Claude 4.5 Sonnet (22.8%) 和 Gemini 3 Pro (22.9%)。
这也印证了一个趋势:在 Coding 这种强逻辑场景下,国产模型已经具备了极强的竞争力。
下图展示了是 ISR 随对话轮数的变化趋势,横轴是对话轮次,纵轴是解决率。
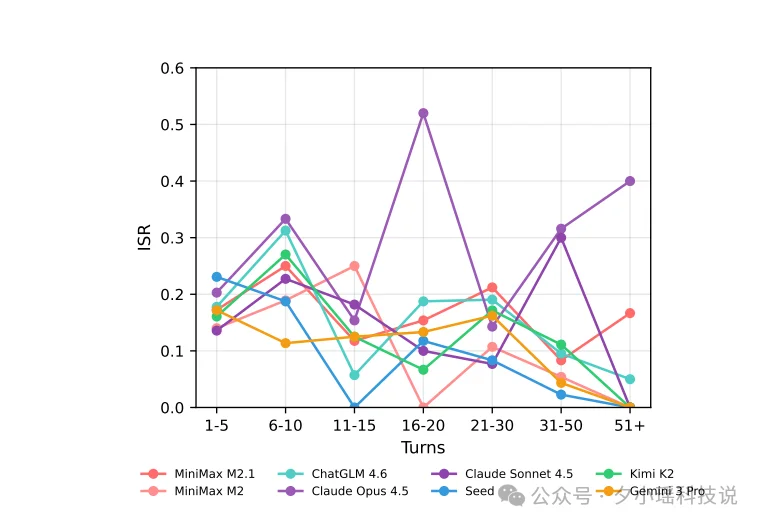
可以看到,随着对话轮次的增加,绝大多数模型开始震荡或下滑,指令遵循能力逐渐下降。“过程合规”在长流程任务中非常脆弱,模型聊着聊着就忘了规则。
所以,长时程的复杂任务的过程监督非常有必要,AI 写代码也需要 code review 。
而且,这些中间过程的反馈信号,对模型训练至关重要,可以在 RLHF 阶段给予更精准的奖励信号。
很多家人们可能会问:我们真的要用起来这样的基准测试吗?
我的答案是:不仅需要,而且早该有了。
关注我的老朋友都知道,我一直对“评估”这件事有执念——AI 写的代码怎么评?
坦白讲,在 AI 写代码已经成为日常的 2026 年,建立系统化的评估意识,不是锦上添花,而是保命刚需。
MiniMax 这次开源的这个 Bench,说明他们在做深 coding 生产力场景。未来的模型必须具备更细腻的颗粒度:不仅要会写代码,更要懂规则。
Andrej Karpathy 说 AI 编程工具就像“没有说明书的外星技术”——能用,很强。
OctoCodingBench 的出现,某种意义上就是在为这个"外星技术"编写说明书。
在 AI 写代码已经成为日常的今天,下一个阶段一定是过程监督和精细对齐,才是「AI 进入生产环境」的第一门槛。
毕竟,能上生产的 AI,才是真正有用的 AI。
文章来自于微信公众号 “夕小瑶科技说”,作者 “夕小瑶科技说”


【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
