# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
让大模型轻松处理比自身上下文窗口长两个数量级的超长文本!
MIT CSAIL研究团队提出了一种叫做递归语言模型RLM的长文本处理新方法,来解决上下文腐烂问题。
不修改模型架构、不升级模块设计,但能让GPT-5、Qwen-3这类顶尖模型推理层具备千万级token的超长文本处理能力。
核心思路是不把提示词直接塞进大模型的上下文窗口,而把它“外包”给可交互的Python环境,让模型主动通过自动编程和递归调用拆解任务、按需处理。
啊?大模型读上下文也能递归操作?
先说上下文腐烂这个扎心的问题。
不管大模型宣称自己的上下文窗口有多大,它们处理超长文本时,都会遇到文本越长,模型对早期信息的记忆越模糊,推理性能直线下滑的问题。
这就像我们读百万字小说,读到后半段,早就忘了前半段的关键情节。

现在主流的解决办法有上下文压缩、检索增强生成RAG,或者对模型进行架构级优化。
比如,GPT-5.2-Codex采用的就是窗口内的原生上下文压缩技术,在持续数周的大型代码仓库协助任务中保持全上下文信息。
同时,GPT系列、Claude、Qwen等企业级版本原生集成RAG功能也是行业共识。
而架构级优化的例子,有社区普遍猜测的Gemini 3的环形注意力等。
现在的RLM和这些直接在模型上“硬磕”的方法不同,它把上下文处理给“外包”了。
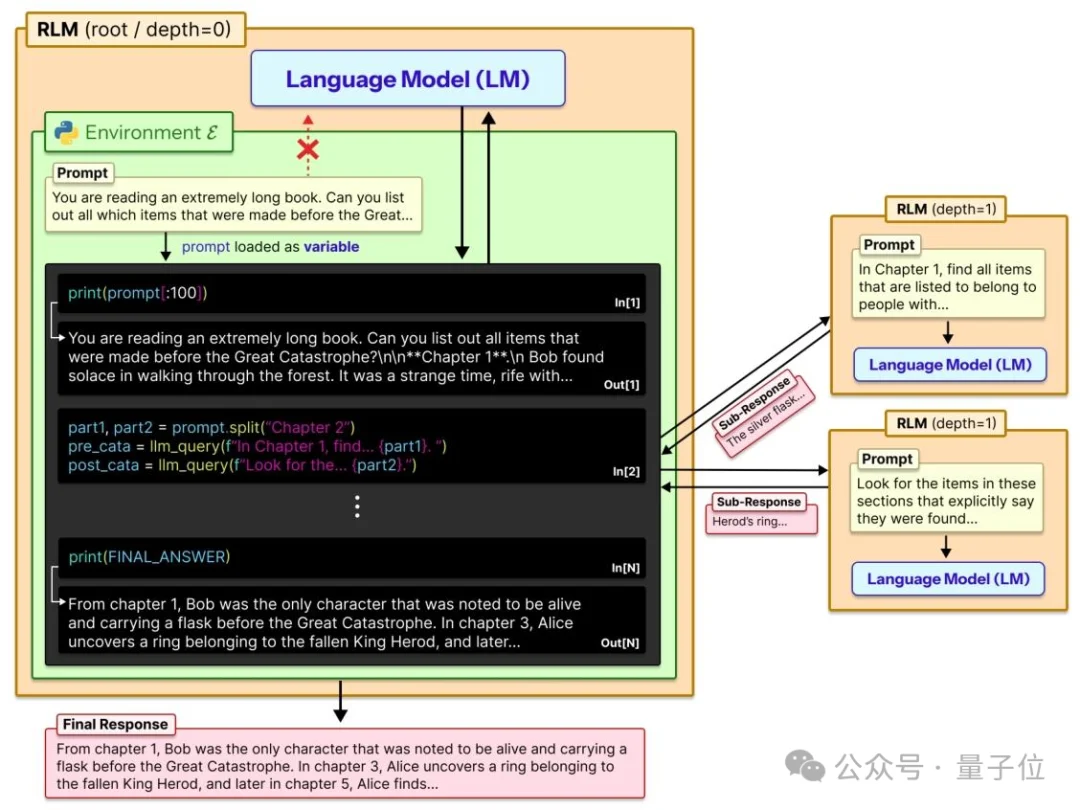
RLM给模型搭了一个可交互的Python编程环境REPL。
开始处理上下文前,它先启动Python REPL交互式编程环境,将超长提示词作为字符串变量存入环境;
接着模型像程序员一样编写代码,对文本变量进行关键词筛选、局部探查、逻辑拆分等操作,通过「编写代码-观察结果」的交互循环减少无效信息摄入;
随后模型将复杂任务拆解为若干子任务,递归调用自身或轻量化子模型处理拆分后的文本片段,所有子任务输出均存储为新变量回流到REPL环境;
最后主模型编写代码读取并整合所有子任务结果变量,进行逻辑拼接或语义处理,形成最终输出。
全程由模型自主决策,实现按需处理,彻底解耦输入文本长度与模型上下文窗口的绑定。

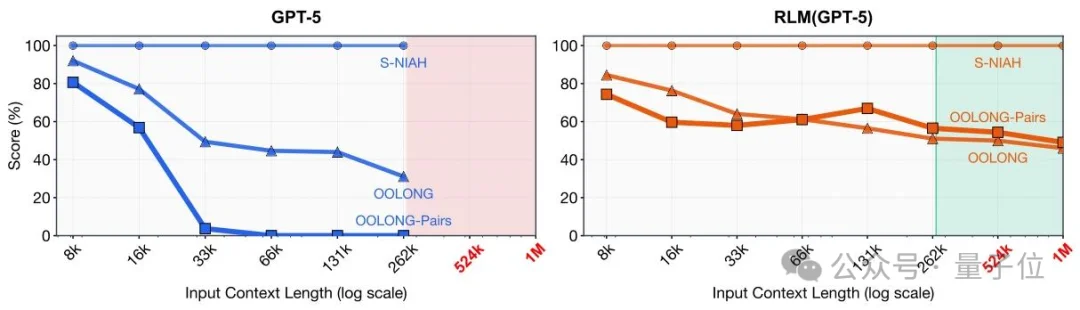
实验显示,RLM有效处理规模已突破千万级Token,超过GPT-5等前沿模型原生上下文窗口的两个数量级。
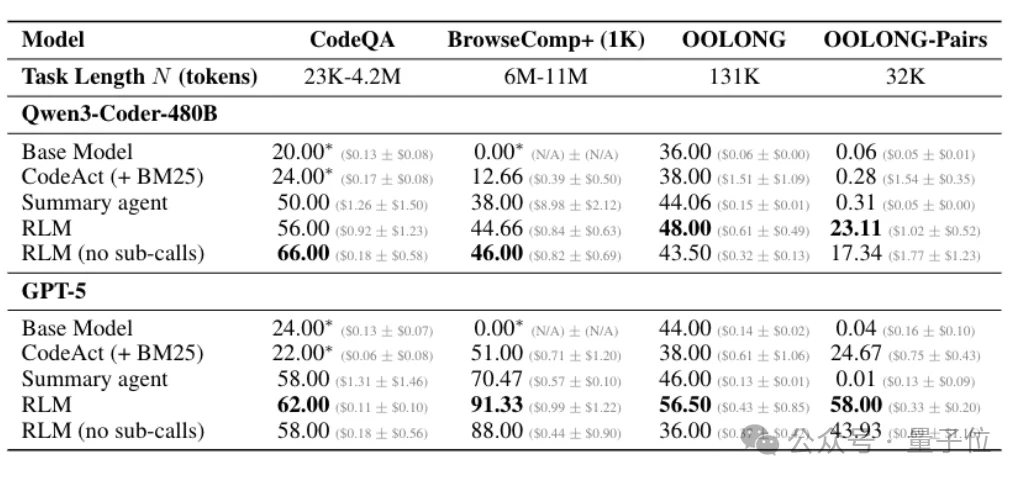
在复杂长文本任务中,RLM的优势也比较显著。面对要求聚合成对信息、复杂度呈二次方增长的OOLONG-Pairs任务,基础GPT-5和Qwen3-Coder的 F1分数不足0.1%;
采用RLM方案后,两款模型分别取得58.00%和23.11%的F1分数。
在600万至1100万Token规模的BrowseComp-Plus(1K)多文档推理任务中,RLM(GPT-5)的正确率高达91.33%,大幅超越其他长文本处理方案;
即便在要求线性扫描并处理几乎所有信息的OOLONG任务中,RLM也实现了双位数的性能提升。
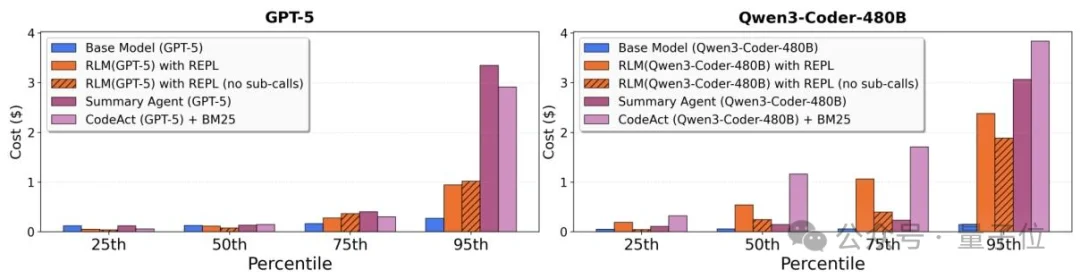
从调用成本上看,在50分位数这个指标上,RLM的成本和其他长文本处理方案处于同一水平,甚至更低。
这说明在大多数常规任务场景中,RLM的性价比是很有优势的。
但到了95分位数这类高百分位区间时,RLM的成本会出现明显飙升。
主要是因为RLM的推理过程是动态的,会根据任务复杂度自主决定代码编写、文本拆分和递归调用的次数,额外的步骤会增加API调用次数。
最后再划个小重点,RLM是一种不碰模型架构的通用推理策略,也就是说,理论上任何模型都能直接上车。
论文地址:https://arxiv.org/abs/2512.24601
参考链接:https://x.com/MatthewBerman/status/2012701592756383893
文章来自于“量子位”,作者 “闻乐”。


【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
