# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
做后端、大数据、分布式存储的同学,大概率都遇到过这样的问题:
明明带宽充足、机器性能拉满,但只是查一条数据,却要发起成千上万次的磁盘IO/对象存储API请求;明明数据量也不是很大,分布式集群的响应耗时却动辄秒级、甚至分钟级,数据查询慢到离谱。
这些问题的根源,也是所有存储系统的核心要解决的问题:寻址。
所有顶级的存储架构设计,本质上都是对寻址的极致优化。而所有最优的寻址思路设计,必然都遵循1个万能公式:
定位总成本 = 元数据访问次数 + 数据访问次数
基于这个万能公式,所有的寻址优化,只有一个终极目标:把元数据访问和数据访问的次数,同时压到最少。
接下来,我们将结合Two Sum到HashMap、HDFS、Kafka 再到Milvus与iceberg,三代数据库系统寻址的设计与演化,进行解读。
行业里所有的寻址加速手段,归纳下来只有3种通用心法:
计算:把去哪找数据的问题,变成算出来数据在哪的问题,用算术运算替代遍历查找;
缓存:把高延迟边界(磁盘/网络)的元数据/索引,搬到低延迟的内存里,规避慢介质的访问开销;
剪枝:用统计信息、分区信息做前置判断,精准跳过不可能命中的数据文件/节点,从根源减少无效访问。
(本文所有的「访问次数」,均指跨高延迟边界的动作 —— 比如一次RPC调用、一次对象存储GET/HEAD请求、一次磁盘读,这类有固定高开销的操作;CPU的纳秒级算术计算,不计入其中。我们的核心关注点只有一个:能不能减少I/O次数、把随机I/O变成顺序I/O。)
基于以上认知,所有复杂的架构设计,都能追溯到最朴素的算法思想。我们先从最经典的Two Sum问题入手,看清查找和计算的本质差距。
Two Sum 问题
给定整数数组 nums 和目标值 target,找出数组中和为target的两个整数,返回其下标。
示例:输入 nums = [2,7,11,15],target =9 → 输出 [0,1]
解法一:暴力遍历查找
最直观的解法是双层循环,遍历所有组合逐一比对,代码极简但效率极低,时间复杂度O(n²)。
public int[] twoSum(int[] nums, int target) {
for (int i = 0; i < nums.length; i++) {
for (int j = i + 1; j < nums.length; j++) {
if (nums[i] + nums[j] == target) return new int[]{i, j};
}
}
return null;
}
以上方法,我们每次要找一个数,都要从头扫一遍数组,本质是无目标的盲找。而找的过程,就是最大的开销。
解法二:通过计算,精准寻址
优化后的解法是用HashMap做存储,时间复杂度直接降到O(n):
public int[] twoSum(int[] nums, int target) {
Map map = new HashMap<>();
for (int i = 0; i < nums.length; i++) {
int complement = target - nums[i]; // 核心:计算出需要找的值
if (map.containsKey(complement)) { // 核心:直接定位,无需遍历
return new int[]{map.get(complement), i};
}
map.put(nums[i], i);
}
return null;
}
可以看到,我们的思路,从我要找数字7 ,然后 从头扫数组,一个个对比,直到找到为止的暴力查找,进化为了我要找数字7,然后先通过逻辑算出它应该在的位置,再直接去这个位置拿数据的精准计算寻址。
事实上,这也是所有顶级存储架构的核心思想——计算替代查找。
Two Sum的优化核心是HashMap,而HashMap本身,就是计算代替查找最经典的工业级实现。
理解了HashMap的寻址逻辑,就等于打通了存储系统寻址的任督二脉。
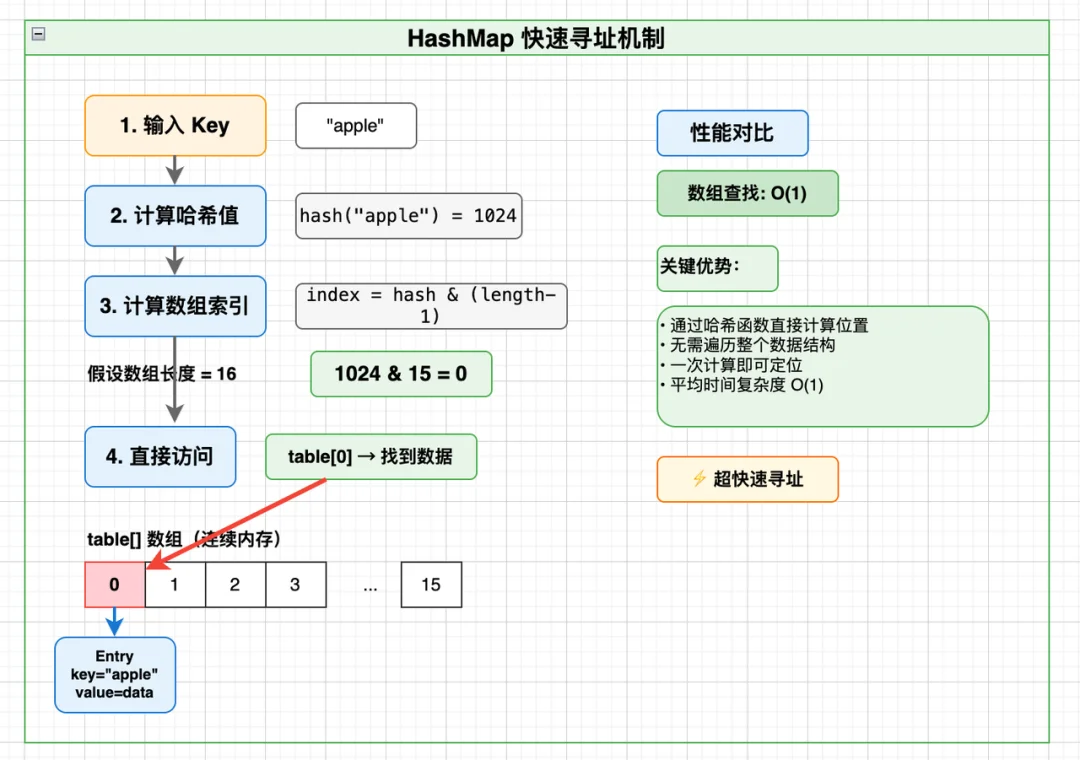
HashMap的核心数据结构只有一个:数组(Node[] table),再搭配链表/红黑树解决哈希冲突。
数组的本质是连续内存+固定大小元素,这是实现高效寻址的基石。
public class HashMap {
// 核心:数组,支持 O(1) 随机访问
transient Node[] table;
// 节点结构
static class Node {
final int hash; // 哈希值(缓存,避免重复计算)
final K key; // 键
V value; // 值
Node next; // 下一个节点(处理冲突)
}
// 哈希函数:key → 整数
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
}
以 put("apple",100) 为例,整个寻址过程只有4步,无需扫全表:
数组的寻址有一个固定公式:
element_address = base_address + index × element_size
CPU执行这个过程,只有两步:先做算术运算算出地址(纳秒级),再直接读取内存(一次访问)。
对比传统链表的差距是天壤之别:
所以HashMap的本质,把key通过哈希映射成数组下标,用1次内存随机访问,替代全量遍历;
但这也带来了一个新的问题,HashMap所有数据必须加载在内存中。那么,当数据量远超内存、分布在数百台机器的磁盘上时,我们该如何寻址?
HashMap解决的是单机内存的寻址问题,访问耗时是毫秒级,这是一个可以接受的范围;但到了大数据时代,问题开始被层层加码:
数据量级:从单机内存的MB级,飙升到分布式集群的TB/PB级,甚至跨机房的EB级;
存储介质:从高速内存,落到慢磁盘,再加上跨机器的网络链路;
访问成本:一次主内存访问是100 纳秒级,一次磁盘操作是10-20 毫秒级,跨节点访问中,同数据中心往返约0.5 毫秒,跨地域跨节点往返可达150 毫秒级。高延迟的访问动作,哪怕多一次,都是致命的性能损耗。
针对以上问题,分布式存储要解决的正是数据是GB/TB级的大文件、分布在成百上千台机器、访问链路包含「网络延迟+磁盘IO」这样的多机磁盘寻址问题。
当然,我们的核心问题没变:如何用最少的高延迟访问,快速找到数据?
我们拆解两个最经典的分布式存储系统HDFS(大文件块存储)、Kafka(消息流存储),看它们如何落地计算优于查找的思想:
HDFS是为大文件、海量数据设计的分布式存储,核心痛点是:如何快速找到一个大文件的某块数据,存在哪台机器的磁盘上?
其数据组织如下
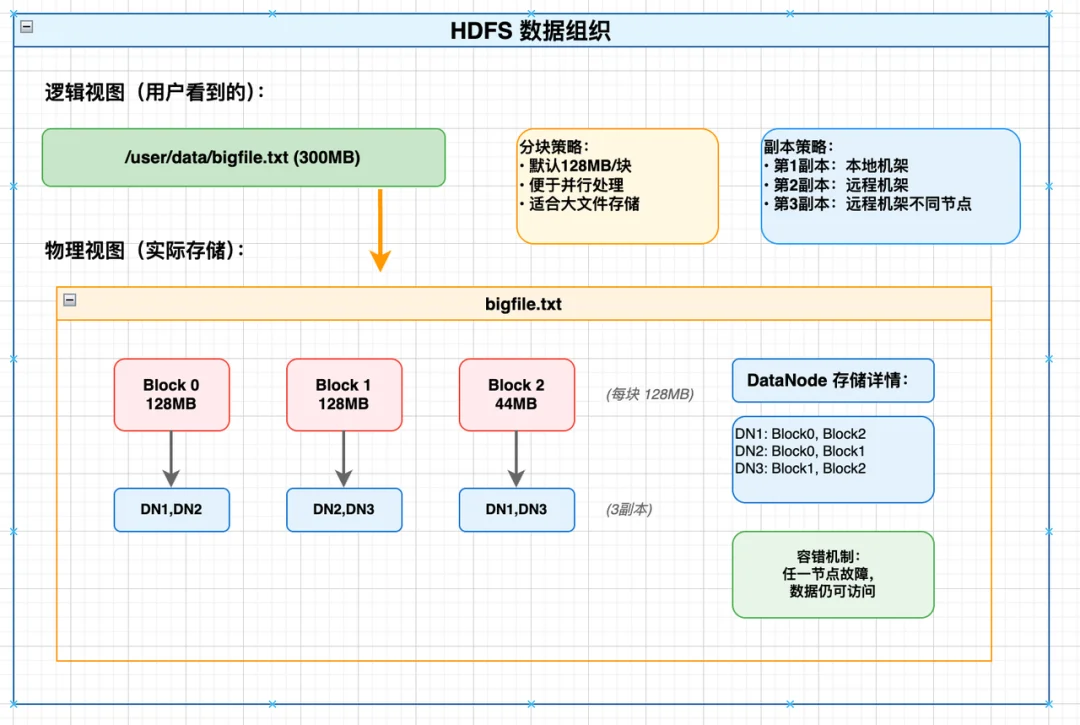
(1)HDFS的核心优化:元数据不落盘,全部放内存
HDFS的寻址核心是NameNode,它把所有文件的元数据(目录树、文件→块的映射、块→数据节点的映射)全部加载在内存中,而且这些元数据的核心存储结构,就是我们上文讲的HashMap
其核心数据结构如下:
// NameNode 内存中的数据结构
// 1. 文件系统目录树
class FSDirectory {
INodeDirectory rootDir; // 根目录 "/"
INodeMap inodeMap; // path → INode (HashMap!)
}
// 2. INode:文件/目录节点
abstract class INode {
long id; // 唯一标识
String name; // 名称
INode parent; // 父节点
long modificationTime; // 修改时间
}
class INodeFile extends INode {
BlockInfo[] blocks; // 文件包含的块列表
}
// 3. 块信息映射
class BlocksMap {
GSet blocks; // Block → 位置信息 (HashMap!)
}
class BlockInfo {
long blockId;
DatanodeDescriptor[] storages; // 存储这个块的 DataNode 列表
}
(2)HDFS的寻址过程(读取大文件某位置)
核心思想:先计算出数据块的编号,再通过内存映射找到节点,用计算+内存查表替代磁盘遍历。
比如读取 /user/data/bigfile.txt 的200MB位置,全程只有4步:
寻址成本为:1次RPC + 若干次内存查找 + 1次数据读取。过程中,所有元数据全在内存,所有查找都是内存级的O(1)操作,不落盘就是最大的优化;
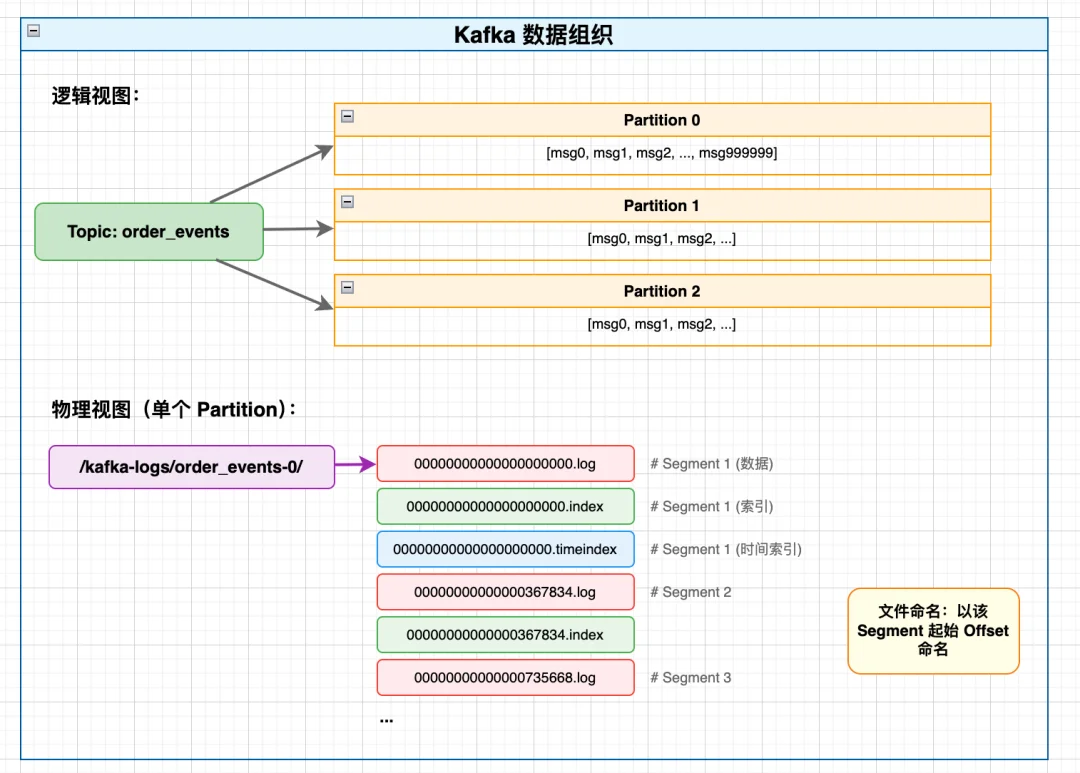
Kafka是为高吞吐消息流设计的,核心痛点是:如何根据消息的offset,快速找到对应的消息在磁盘文件的哪个位置?
Kafka 的数据组织如下:
Kafka .index 稀疏索引设计如下
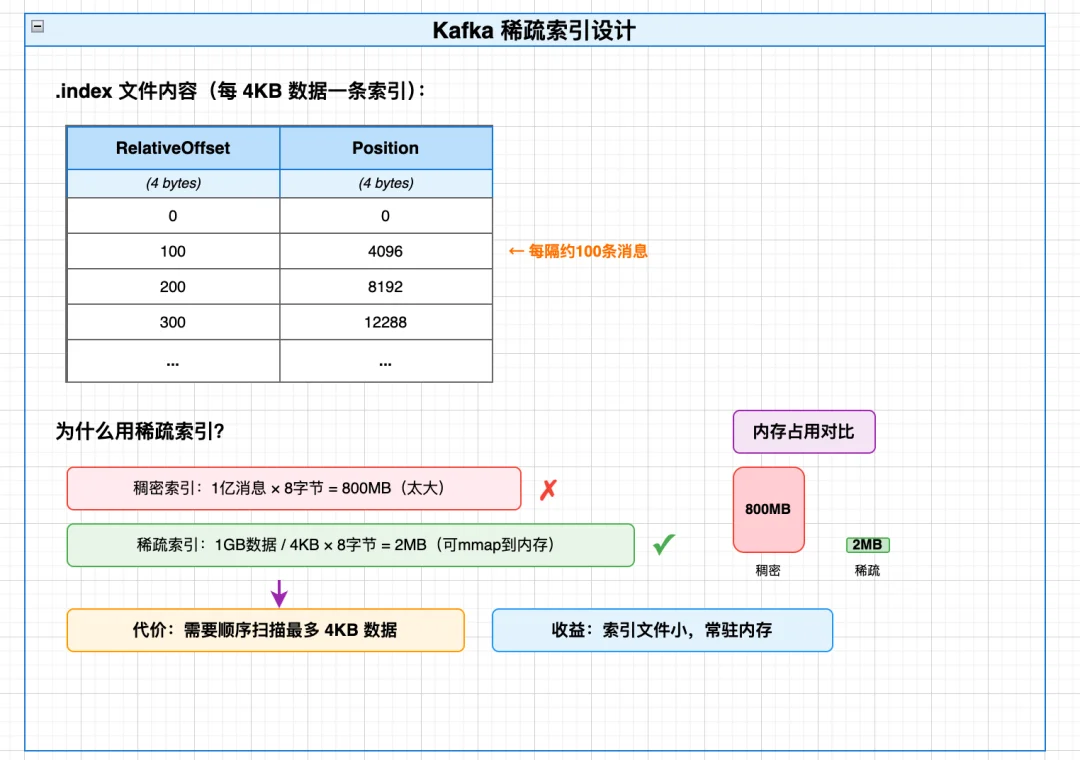
Kafka的核心优化在于:把随机查找变成计算+少量顺序扫描
Kafka的消息按Topic→Partition→Segment组织,每个Segment包含一个.log数据文件和一个.index稀疏索引文件,这个.index文件会被mmap到内存中(无磁盘IO)。
// Partition 管理所有 Segment
class LocalLog {
// 核心:TreeMap,按 baseOffset 排序
ConcurrentNavigableMap segments;
// 定位 Segment
LogSegment floorEntry(long offset) {
return segments.floorEntry(offset); // O(log N)
}
}
// 单个 Segment
class LogSegment {
FileRecords log; // .log 文件(消息数据)
LazyIndex offsetIndex; // .index 文件(稀疏索引)
long baseOffset; // 起始 Offset
}
// 稀疏索引条目(每条 8 字节)
class OffsetPosition {
int relativeOffset; // 相对于 baseOffset 的偏移 (4 bytes)
int position; // 在 .log 文件中的物理位置 (4 bytes)
}
(1)Kafka的寻址过程
示例:读取 offset = 500000 的消息
1.定位 Segment(TreeMap 查找)
2. 索引二分查找(.index)
3. 顺序扫描(.log)
总文件访问:1 次索引 + 1 次数据
(2)Kafka的寻址效率核心
寻址成本:1次内存索引访问 + 1次磁盘数据读取,总共2次高延迟操作;
核心思想:用稀疏索引把「全文件随机查找」,转化为「计算定位+少量顺序扫描」,而顺序读是磁盘的最优访问方式;
核心结论:有序段+内存索引,是流式存储的最优寻址组合。
从HashMap到HDFS/Kafka,我们解决了单机内存和分布式基础存储的寻址问题,但大数据时代的需求还在升级:
在这个过程中,很多同学会有误区:存储系统的性能瓶颈是带宽。但实际情况是:在对象存储场景下,瓶颈永远是「高延迟的API调用次数」。
比如一次S3的GET请求,固定延迟约50ms,哪怕只读取1KB的数据,耗时也是50ms;如果一次查询要发起10000次这样的请求,串行耗时就是500秒——这就是小文件爆炸的致命问题。
这一部分,我们拆解Milvus(向量数据库)、Iceberg(湖仓一体)两个现代存储系统的演进,看它们如何解决行业核心痛点,这也是当前存储架构设计的最优实践,所有优化都没有脱离我们开篇的核心公式和三大心法。
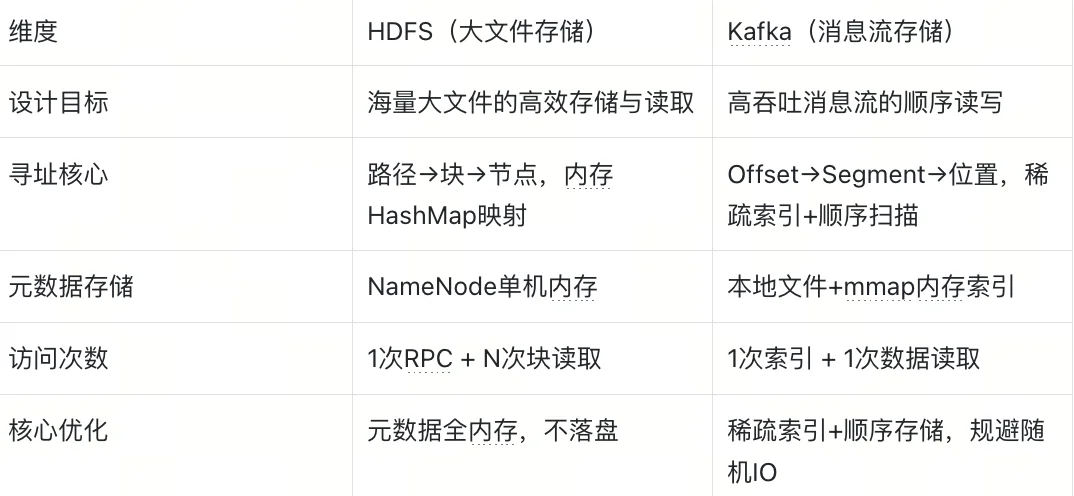
Milvus是主流的向量数据库,V1版本的设计如下
V1 寻址过程如下:
查询:SELECT id, vector FROM collection WHERE id = 123
1.元数据查询
从 etcd/MySQL 获取 Segment 列表 → [Segment 12345, 12346, 12347, ...]
2.读取每个 Segment 的 id 字段
12345/insert_log/100/*.binlog12346/insert_log/100/*.binlog3.定位目标行
在内存中找到 id=123 所在的行号
4.读取 vector 字段对应行
总文件访问:N × (F1 + F2 + ...)(N = Segment 数,F = 每个字段的 binlog 文件数)
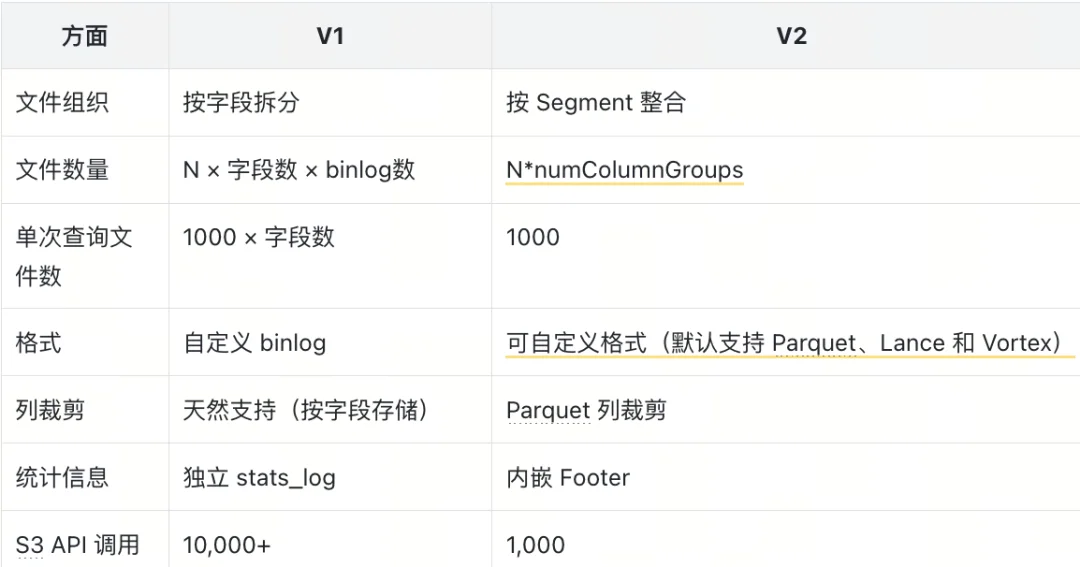
这是一个在当时来看比较高效的系统,但存在一个核心问题:按字段拆分存储。比如一个集合有100个字段、1000个Segment,每个字段有5个binlog小文件,那么总文件数就是 1000×100×5=50万个!一次查询3个字段,就要发起15000次S3 API调用,考虑到 S3 延迟 50ms/次,那么整体的串行 = 750 秒!也就是说,一次查询,需要花费至少12-13分钟。
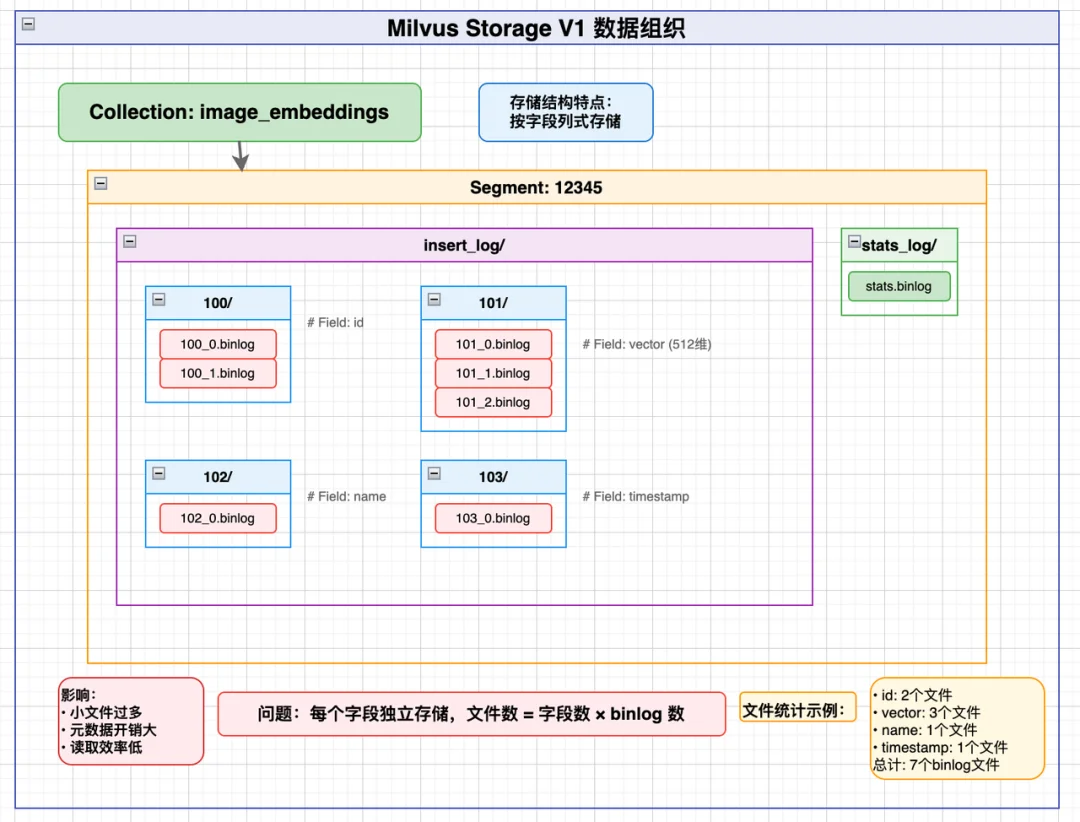
因此,到了Milvus V2,我们做的核心优化就是按Segment整合,从根源减少文件数量,整体数据组织如下:
V2核心结构如下
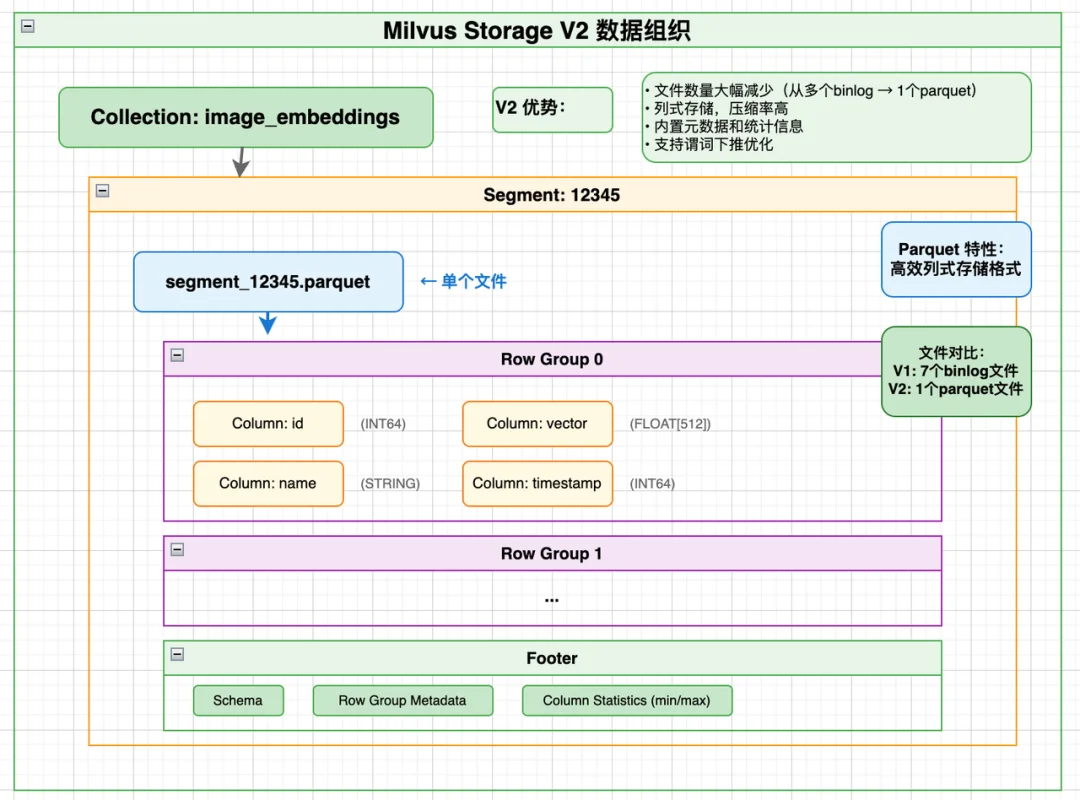
V2版本把字段拆分的小binlog文件,整合成「按Segment划分的Parquet列存大文件」,核心变化只有一个:
文件数量从「N×字段数×binlog数」,直接降到「N(Segment数)」。
V2 寻址过程如下:
查询:SELECT id, vector FROM collection WHERE id = 123
【核心设计说明】V2 并非单一个 Parquet 文件存储所有字段,而是按照字段数据体量做拆分存储,小体积标量字段归为一类文件,大字段(如向量 vector)会单独拆分为独立的专属文件,各拆分文件同属对应 Segment,字段间通过行索引精准关联。
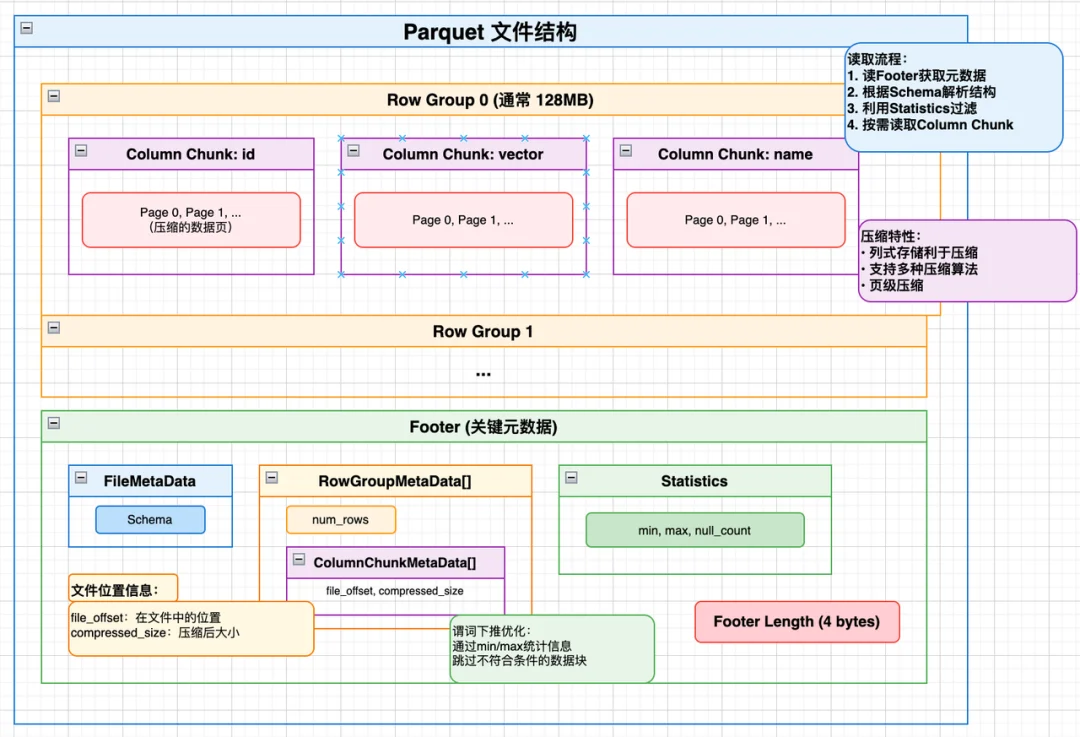
1.元数据查询
2.读取对应拆分文件的 Parquet Footer(每个文件末尾)
3.只读取相关 Row Group 的 id/vector 列
查询时,只需读取对应 Segment 下拆分后的指定 Parquet 文件,结合字段拆分存储+Parquet 的列裁剪特性,只读取业务需要的字段,无需读取全量数据,也无需加载无关字段的文件。
这种拆出大字段的核心价值,主要针对性解决两大核心问题:
优化效果:减少文件数量 10x+,结合字段拆分 + Parquet 优化读取,API 调用次数减少 10 倍以上,查询耗时从分钟级降到秒级。
核心结论:减少高延迟的文件访问次数,是性价比最高的优化手段;而按字段大小拆分存储、将大字段独立拆分,是该优化落地的核心支撑。
V2与V1的对比如下
Iceberg是当前湖仓一体的事实标准,它解决的是海量数据的复杂条件查询问题,核心痛点是:如何在数千个数据文件中,快速找到符合查询条件的少量文件,避免全量扫描。
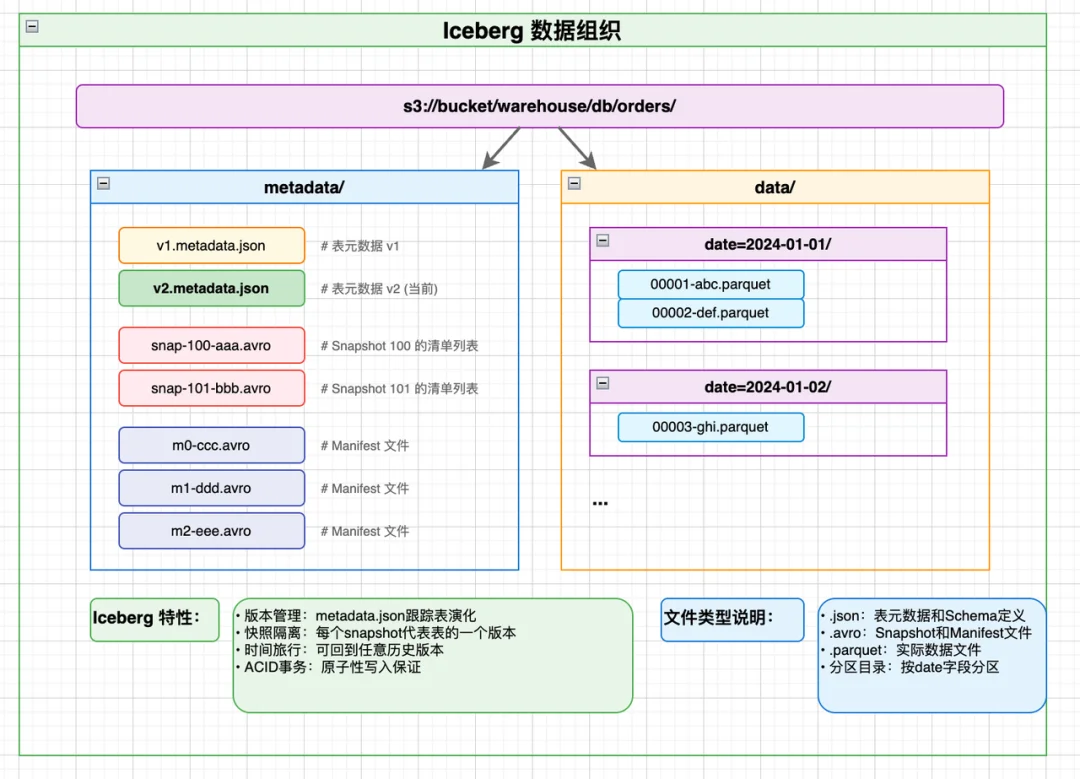
其核心数据结构如下
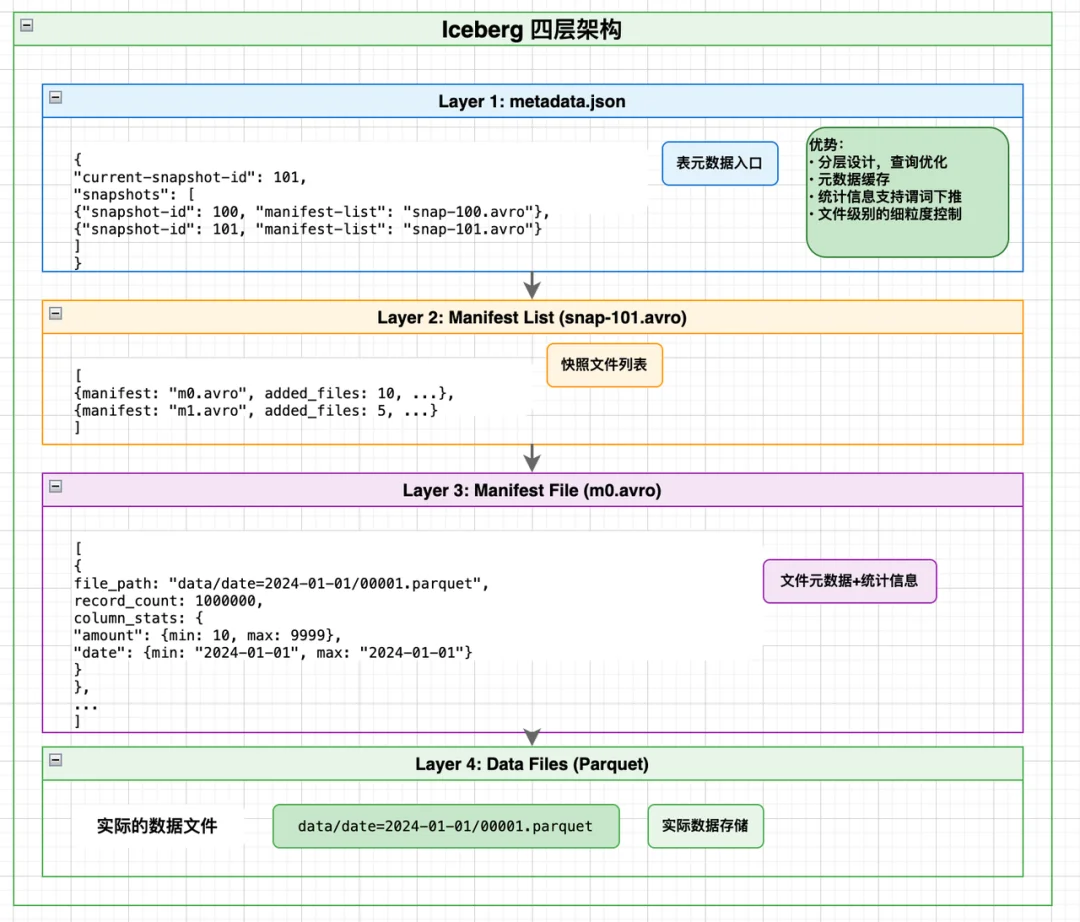
Iceberg的核心创新,是分层元数据+文件级统计信息,完美落地了我们开篇的剪枝心法,核心逻辑是:在读取数据前,先通过元数据算出「哪些文件需要读、哪些文件可以直接跳过」,从根源减少无效IO。
(1)Iceberg的寻址过程(精准剪枝)
比如查询:SELECT * FROM orders WHERE date='2024-01-15' AND amount>1000,全程只有4步,层层过滤:
与此前的要读取全部1000个文件,IO次数1000的方式比,有了Iceberg:我们仅需7次IO,直接减少94%的无效访问。
核心思想:统计信息是最好的剪枝刀。写入时花少量成本收集文件的min/max、分区等统计信息,读取时就能用这些信息做前置判断,精准跳过不可能命中的文件,这是计算的极致体现。
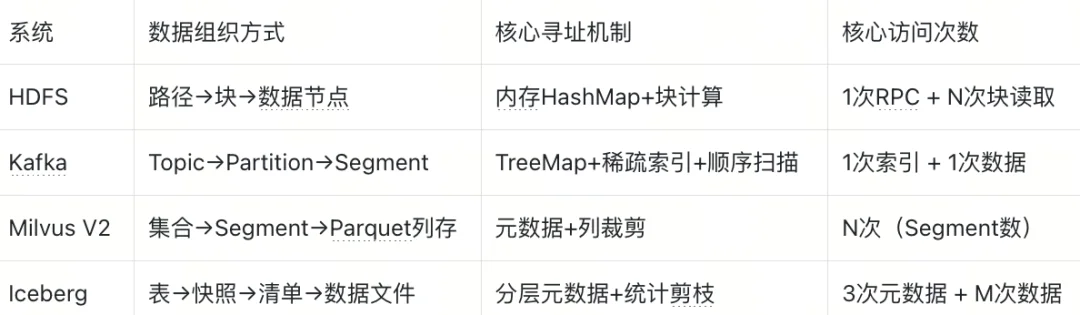
事实上,从一道算法题,到HashMap,再到分布式存储、现代湖仓一体系统,我们看遍了寻址的演进,但所有的优化都没有脱离3个核心原则:
原则一:计算永远优于查找,这是寻址的第一性原理
这是本文的核心核心,没有之一。
HashMap:用hash(key)计算下标,替代全表遍历;
HDFS:计算数据块编号,替代磁盘文件查找;
Kafka:计算Segment和索引位置,替代全文件扫描;
Iceberg:用统计信息+查询条件,计算出需要读取的文件列表,替代全量文件扫描。
其本质在于,计算是算术运算,耗时纳秒级;查找是遍历比对,耗时随数据量线性增长。能用计算解决的寻址问题,永远不要用查找。
原则二:最小化高延迟访问次数
回到我们开篇的核心公式:定位总成本 = 元数据访问次数 + 数据访问次数。
所有的优化手段,最终都指向一个结果:减少RPC、磁盘IO、对象存储API这类高延迟的访问动作。
常见的落地手段:减少文件数量(Milvus V2);用统计信息跳过无关文件(Iceberg);把元数据/索引缓存到内存(HDFS、Kafka);用合理的索引设计平衡空间与性能(Kafka稀疏索引)。
原则三:统计信息,是性价比最高的剪枝利器
没有统计信息,你必须读取文件才能知道有没有数据命中;有了统计信息,你可以在读取前就判断这个文件一定没有命中,直接跳过。
这是一个极小投入、极大回报的优化:写入时只需要额外收集文件的min/max、分区、行数等基础信息,读取时就能跳过大量无关文件,让IO次数呈数量级下降。

陈彪
Zilliz Senior Staff Software Engineer
文章来自于“Zilliz”,作者 “陈彪”。


【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
