# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
引
现实世界(物理世界)存在大统一理论吗?
这是爱因斯坦一辈子都在追寻的目标。
无数人类天才穷尽一生才合伙建立残缺的大统一理论(GUT):它只统一了强相互作用、弱相互作用和电磁力,引力至今无法统一到模型之中。
同理,AI世界存在大统一模型吗?
这也是很多AI工程师也在追求的目标。
此次OpenAI发布Sora,官方对它的定义就是:世界模拟器。
并且认为它是构建物理世界通用模拟器的一个可能方法。

那么,AI世界也会存在“基本粒子”吗?
为什么Sora发布会引发对AGI的思考和争议。
人类的大统一理论与AI大统一模型如何比照参考?
物理引擎和数学原理又将扮演什么角色?
随着Sora的DEMO推出,人类似乎触手可及“AI创世纪”!
1
人类的终极目标之一,
就是寻找物理世界的“基本粒子”。
只有找到“基本粒子”,才有可能理解这个宇宙。
AI世界则不一样,人类现在是创世者,我们设定“基本粒子”。只有制造出“基本粒子”,才能去生成一个新世界。
回到AI人工智能的“奇点大爆炸”时代,ChatGPT作为第一个真正意义的人工通用智能,它的工作原理是什么:
ChatGPT借助Embedding将人类语言“编码”成AI能够计算的“语言颗粒”,也就是Token化,将自然语言转换为高维向量空间中的数值,通过自注意力机制权衡不同语言元素的相对重要,最终“解码”回自然语言。
大语言模型处理和生成文本的过程步骤:
1.文本Tokenization ➔ 2. Embedding映射 ➔ 3. 加入位置编码 ➔ 4. 通过自注意力机制处理 ➔ 5. 利用前馈网络进一步处理 ➔ 6. 生成预测并“解码”
具体步骤如下:
①文本Tokenization:
将原始文本分解为更小的单元(Tokens)。
"Hello, world!" ➔ ["Hello", ",", "world", "!"]
②Embedding映射:
将每个Token转换为高维空间中的向量。
["Hello", ",", "world", "!"]
➔ [向量Hello, 向量,, 向量world, 向量!]
③加入位置编码:
为每个向量加上位置信息,保留序列中词的顺序。
[向量Hello, 向量,, 向量world, 向量!] ➔ [向量Hello_pos, 向量,_pos, 向量world_pos, 向量!_pos]
④通过自注意力机制处理:
模型计算每个词对序列中其他词的“注意力”,从而调整每个词的表示,使其包含更丰富的上下文信息。
[向量Hello_pos, 向量,_pos, 向量world_pos, 向量!_pos] ➔ [向量Hello_context, 向量,_context, 向量world_context, 向量!_context]
⑤利用前馈网络进一步处理:
对每个词的向量进行进一步的非线性变换,以学习更复杂的表示。
[向量Hello_context, 向量,_context, 向量world_context, 向量!_context] ➔ [向量Hello_final, 向量,_final, 向量world_final, 向量!_final]
⑥生成预测并“解码”:
基于最终的向量表示,模型生成下一个词的预测,并将其转换回人类可读的文本。
[向量Hello_final, 向量,_final, 向量world_final, 向量!_final] ➔ 预测下一个Token ➔ "Language"】
从以上步骤可以看出,ChatGPT技术原理的起点是将“自然语言”Token化,也就是给大语言模型提供了一个可计算可理解的“基本粒子”,然后用这些“基本粒子”去组合文本语言新世界。
不仅仅是ChatGPT,其它语言大模型基本上都将“Token”视为基本粒子,在文本大模型这个领域,创世粒子已经“尘埃落定”。
2
与ChatGPT的技术原理很相似,Sora模型技术栈也是先将视频数据“基本粒子”化。
A、文字语言基本粒子“Token化”
B、视频数据基本粒子“ spacetime patches化”
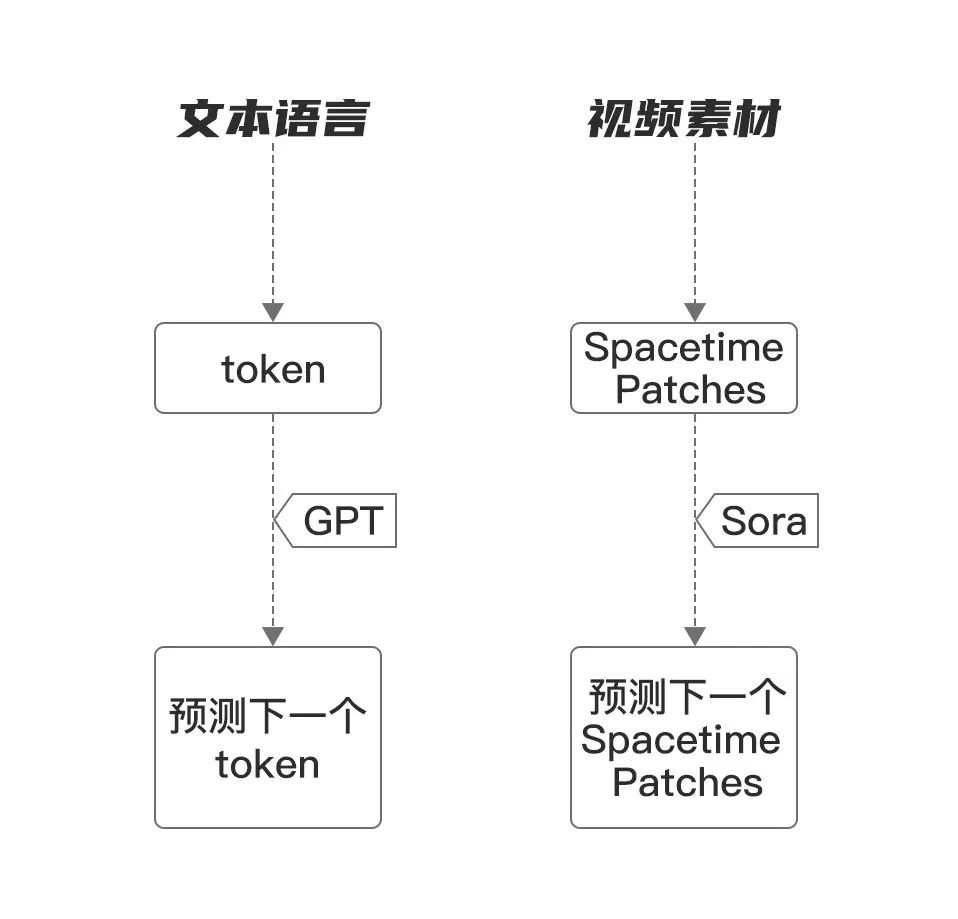
与ChatGPT采用Token Embedding方法以实现文本数据相似,Sora模型将视频数据压缩至一个低维的潜空间(Latent Space),再将这些压缩后的数据细分为时空碎片(Spacetime Latent Patches)。
视频大模型的工程师一直都在创造基本粒子,但并不是每个基本粒子都能成为“创世粒子”。
能够得到众生认可的“创世粒子”应该具有以下特点:
1、能够高效继承原生世界的信息;
2、可以自由组合创造(生成)新世界。
这次Sora模型的视频数据“时空碎片”(spacetime patches)已经被证实是一种高效且可扩展的数据块,它能够捕捉和表征各类视频数据的关键信息。成为AI时空数据建模的基石,和Token一样时空碎片spacetime patches成为AI时空建模的关键,成为视频大模型的“基本粒子”。
Sora模型处理和生成视频的过程步骤:
1.视频数据输入 ➔ 2. 压缩到低维潜变量空间(Latent Space) ➔ 3. 拆解为时空碎片(Spacetime Patches) ➔ 4. AI时空建模

通过这一系列步骤,视频数据被转换成时空碎片spacetime patches,这为深入理解视频内容提供一种统一方法。
AI创世纪的一些基本粒子好像慢慢被创造出来了:
语言大模型的基本粒子创造出来了:Token;
视频大模型的基本粒子也创造出来了:spacetime patches。
3
Sora 的技术原理猜想
Sora模型官方只出了一个技术报告,并没有公布具体技术细节。
看来创世者也不是无私的,OpenAI从原生世界的开源技术和公开论文中获取灵感,但却不愿意公开自己的技术。
以上我们对Sora进行了一个总体的总结,现在来解构一下它的产品脉络,以下内容是对Sora模型的技术猜想:
步骤1:
压缩原始视频,提取特征信息
在Sora模型的训练初期,第一步是将原始视频数据转化为低维度潜空间(Latent Space)中的特征。这个过程可以视为一个高维数据压缩和特征提炼的数学操作。
现存的4K或高清视频拥有极高分辨率,需要一个“压缩”步骤,旨在从原始视频中提取特征信息,简化描述:
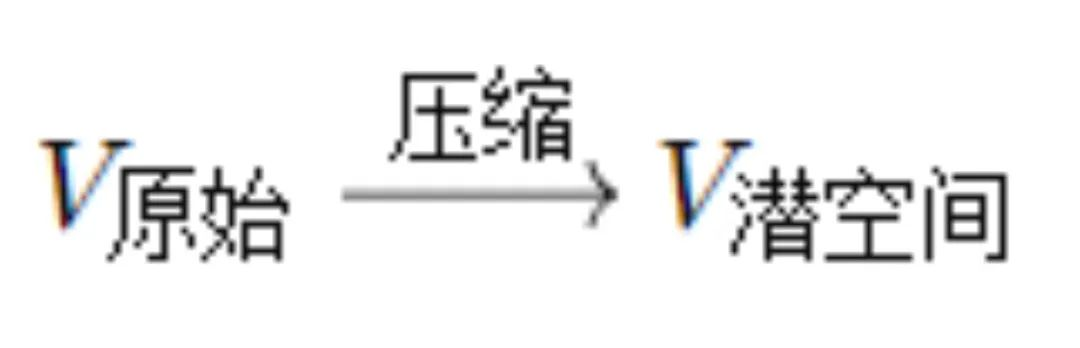
OpenAI参考了Latent Diffusion的研究成果——将原图像数据转换成潜空间特征,降低处理数据量,且能有保留核心信息。
经过压缩后的数据存在以下特征:
1.有损压缩与重建
通过在潜在空间中进行扩散和逆扩散过程,模型能够在有损的基础上重建出与原始数据相似但又新颖的样本。
2.效率与灵活性
在低维潜在空间中进行操作使得模型更加高效,同时提供了更大的创造性灵活性。也就是说,虽然数据经过压缩,在Latent Diffusion技术加持下对大模型训练影响不大。
步骤2:
将压缩视频拆解成时空碎片(spacetime patches)
视频数据被压缩到潜空间,再拆解成基本单位,也就是时空碎片Spacetime Patches。
Patch的原始的意义是一个独立的图像块,在图像训练的Vision Transformer (ViT)的原始论文中,研究者提出以处理大型图像的训练方法——方法的思想在于将大图像分割为等面积的图像块,也就是Patch,将每个图像块视为序列化数据的一部分,在这一序列化过程中,每个图像块的位置信息也被编码进去,这就是图片生成的基本原理。但如果要生成视频的话,则要将对应位置图像块的时间帧编码进去,形成时空图像块,简称时空碎片(Spacetime Patches),这些时空碎片不仅携带空间信息,还包含时间序列上的变化信息。
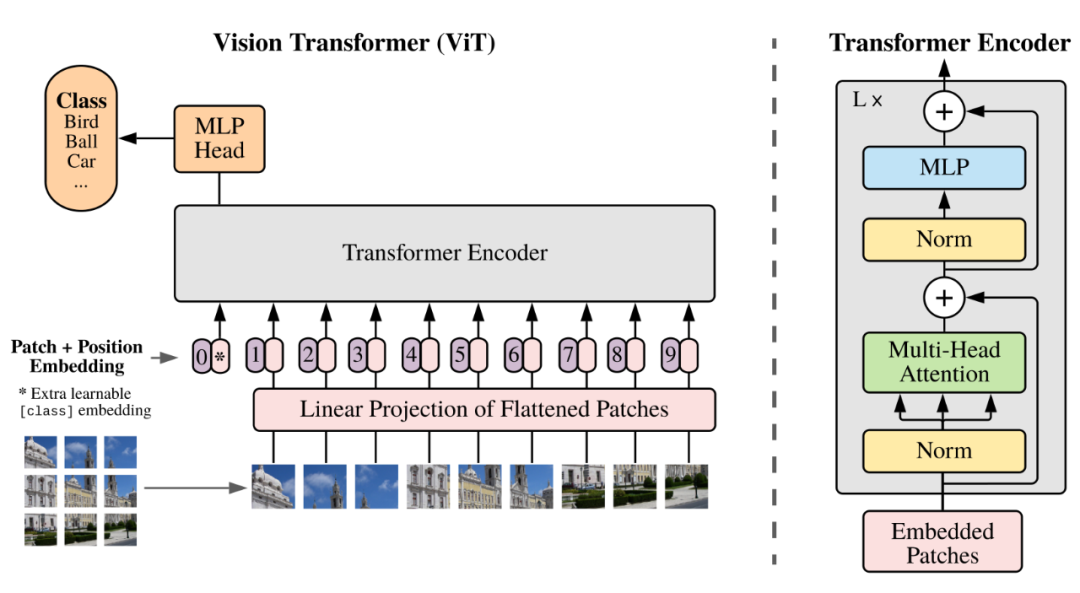
1、图像生成
训练时由面到点(平面),生成时由点到面;
2、视频生成
训练时由立体到点(立本),生成时再由点到立体。

数学上可以将视频视为一个由时空碎片(Spacetime Patches)组成的复杂矩阵。
假设视频V是一个连续的时空信号,可以表示为一个四维张量V∈RT×H×W×C,其中T代表时间维度上的帧数,H和W分别代表每帧图像的高度和宽度,而C是位置信息。当然这里还包括一些技术细节:
例如不同视频尺寸捕捉信息参考Navit的“Pack”的技术,编码器VAE的改进支持各种视频格式。
视频数据被拆解为一系列可管理的基本单位时空碎片(Spacetime Patches),下一步就是要将这些时空碎片输入到到模型中进行训练。
步骤3
“字幕重排技术”对时空向量的准确描述
在将时空碎片输入到到模型训练之前,OpenAI公司还引入了“字幕重排技术”。
Betker, James, et al. "Improving image generation with better captions." Computer Science. https://cdn.openai.com/papers/dall-e-3. pdf 2.3 (2023): 8
这是一种全新的工程能力,OpenAI将DALL·E 3引入的字幕重排技术应用于视频的训练。
DALL·E 3也是OpenAI的产品,使用起来驾轻就熟。
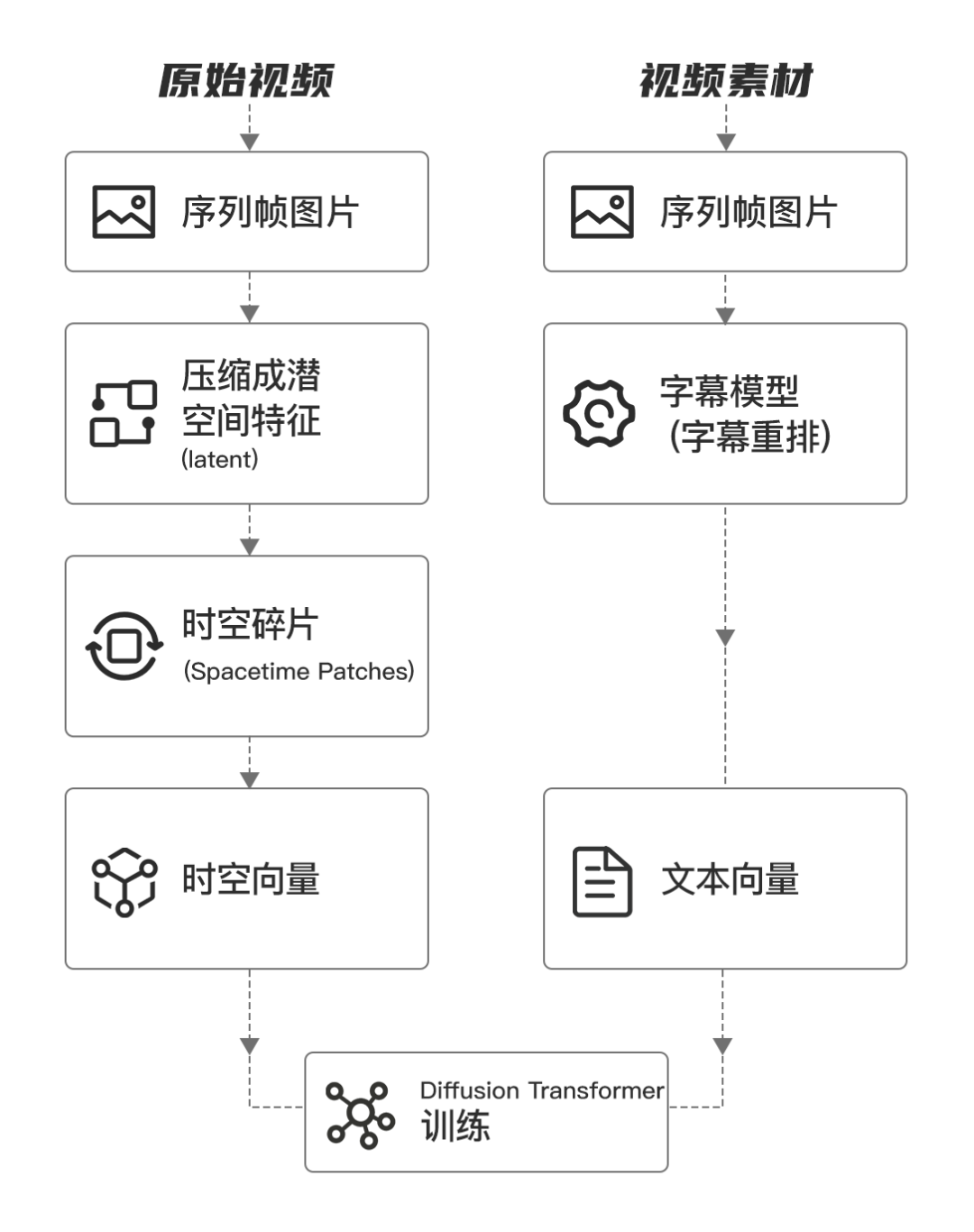
“字幕重排技术”工程上非常重要,它在训练视频和生成视频两个环节上都有极大作用。
正向训练:
训练一个字幕模型,然后使用它训练视频产生文本字幕。高度描述性的视频字幕可以提高文本的准确性以及视频的整体训练质量。
逆向生成:
利用GPT大语言模型将用户简短提示扩展为详细字幕,提高视频生成的细节度和质量。使Sora能够根据用户提示生成高质量、内容丰富的视频。
从工程上来讲这里使用到了OpenAI的三大模型的技术能力:
语言大模型GPT4.0➕图片大模型DALL·E 3➕视频大模型Sora
这个环节技术突破不大,但工程影响甚巨,OpenAI手握三大模型(文+图+视频),其它公司想要突破这样的工程栈并不容易。
步骤4:
扩散模型Diffusion Transformer对潜空间数据进行处理
潜变量的向量信息已经准备好了,现在进入到处理数据和生成视频环节。
OpenAI采用了Diffusion Transformer(DiT)架构,这是基于伯克利学者在论文"Scalable diffusion models with transformers"中提出的工作。
该架构有效地结合了扩散模型和Transformer技术,构建了一个强大的信息提取器,专门用于处理和生成视频内容。
整体架构如下:
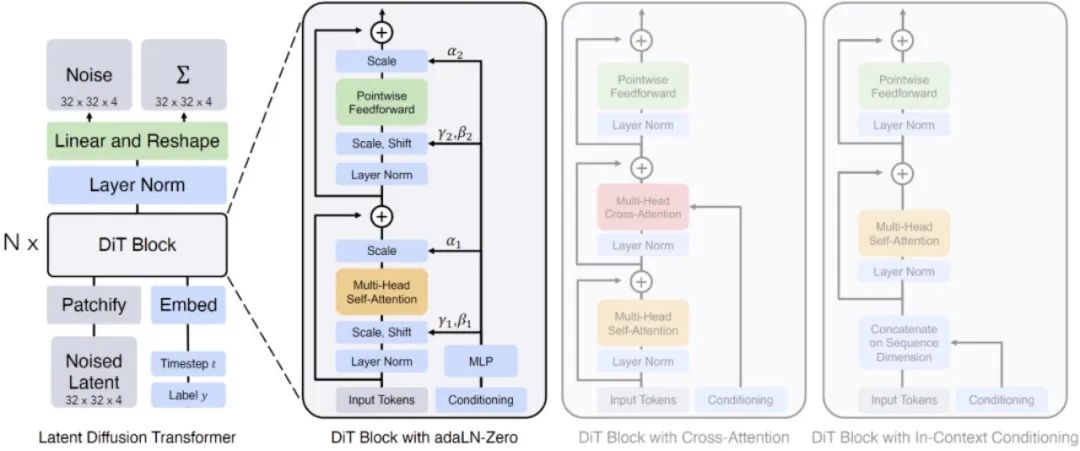
No.1
潜变量与Patch的处理
将输入视频表示为一系列潜在变量,这些潜在变量进一步被分解成多个Patch。
每个Patch由多个DiT块串联处理,增强了模型对视频内容的理解和重构能力。
No.2
DiT块的优化设计
对标准Transformer架构进行了修改,引入了自适应层归一化(Adaptive Layer Normalization)、交叉注意力(Cross Attention)和额外的输入Token进行调节,以优化性能。实验表明,自适应层归一化在提高模型效果方面表现最佳。

这里最内核的两大核心技术是扩散模型Diffusion和Transformer框架!
高斯噪声的逐步添加与去噪过程:
● 通过连续添加高斯噪声破坏训练数据的结构,使信息熵增加,逐渐掩盖原始结构信息。学习逆转加噪过程,即去噪,从而恢复数据。
● 这一过程可以通过训练概率分布q(xt∣xt-1)来实现,其中x0,...,xT是逐步加噪的潜变量序列。


深入探索Diffusion Transformer(DiT)架构时,理解Transformer的数学原理很重要。Transformer模型依赖于自注意力机制和多头注意力机制,以实现对输入数据的高效处理和深层次理解。
● 自注意力(Self-Attention)机制
自注意力机制允许模型在处理一个序列的每个元素时,考虑到序列中的所有其他元素,其数学表示为:
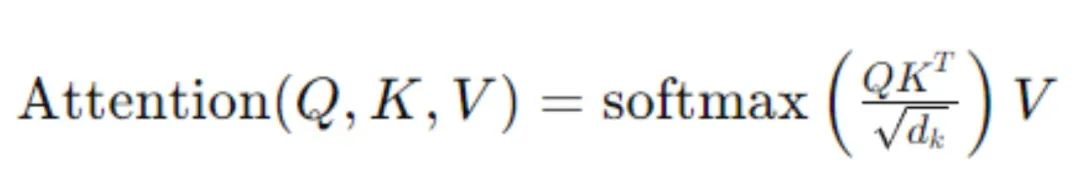
其中Q,K,V分别代表查询(Query)、键(Key)和值(Value),dk是键的维度。这个机制通过计算输入元素之间的权重分布,使模型能够捕捉序列内部的复杂关系。
● 多头注意力(Multi-Head Attention)机制
多头注意力机制是对自注意力的扩展,它并行地执行多次自注意力操作,每次使用不同的权重集,然后将所有头的输出合并:
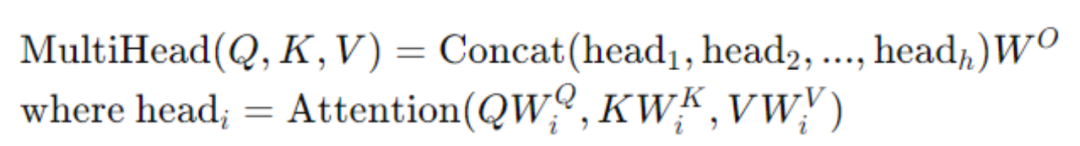
以上机制中W是可学习的权重矩阵,ℎ是头的数量允许模型同时从不同的表示子空间中学习信息,提高了其理解和表达能力。
关于TRANSFORMER的技术细节,量子学派在《ChatGPT幕后的真正大佬……》有过详细的介绍和学习!
扩散模型与Transformer的结合:
● DiT通过引入Transformer架构,实现了对视频内容的深层分析与理解。多层多头注意力和归一化带来了降维和压缩,扩散方式下的信息提取过程更加高效。
● 此过程与大型语言模型(LLM)的重整化原理相似,通过参数化潜变量的概率分布,并使用KL散度来计算分布之间的差异,从而优化模型性能。
通过这种方式,Sora不仅可以准确地提取和理解视频内容的深层信息,还能根据用户的简短提示生成高质量、内容丰富的视频。
这一创新的方法为视频生成领域带来了新的可能性,展示了数学原理和AI技术结合的强大力量。
步骤5
与Sora产品交互,用户逆向生成世界
Sora能够精确理解用户的意图,并将这些意图扩展成完整故事,这为视频生成提供了蓝图。
以下是扩展过程详解:
● 接收用户提示
Sora首先收集用户的简短提示,这可能是一个场景描述、情感表达或者任何想要在视频元素。
● 提示扩展
利用GPT模型,Sora将这些简短的提示转换成详细的字幕。这个过程涉及到复杂的自然语言理解和生成,确保扩展后的字幕不仅忠实于原始提示,还补充大量的细节,如背景信息、角色动作、情感色彩等,使得提示变得生动且具体。

Sora模拟时尚女士走在东京街头,效果极其逼真
● 生成视频内容
有了这些字幕作为指导,Sora接着将字幕转化为视觉内容。这个过程包括选择场景、角色设计、动作编排和情感表达,确保生成视频与字幕保持一致。
● 优化与调整
在视频生成的过程中,Sora还会优化和调整确保视频的质量达到最高。这可能包括对视频细节的微调、色彩的校正、以及确保视频流畅性和视觉吸引力。
以上是对Sora技术原理的猜想,Sora模型可以生成高质量和视频,用OpenAI工程师的话来表述:构建物理世界通用模拟器。
4
工程师的“创世纪”:镜像世界
工程师们眼中的Sora可不是为了给你生成一部电影,而是在虚拟环境中重现物理现实,提供不违反“物理规律”的镜像世界。
那到底该如何创世呢?这可是大神们的工作。
宇宙存在许多规则,例如能量守恒定律、热力学定律、万有引力牛顿定律等。
万事万物不能违背这些规则,苹果不能飞向月球,人类在阳光下有影子。那这些规律是如何形成的呢?存在两种可能:
1、混沌第一性原理:定律是在宇宙的发展过程中形成的;
2、定律第一性原理:宇宙从按照这些定律才发展到现在。
以上是两种“创世”规则,也决定着“镜像世界”的两种方法。
技术上现在有两种方式可以实现这样的世界模型:
基于物理运动的模拟(Sora)
物理规律学习:Sora通过分析大规模视频数据,使用机器学习算法提炼出物理互动的模式,如苹果落地而非悬浮,遵循牛顿的万有引力定律。
基于数学规则的模拟(虚幻引擎)
数学建模:虚幻引擎通过手工编码物理世界的数学模型(如光照模型、动力学方程),来精确“渲染”物理现象和互动。
很明显,基于物理运动的模拟(Sora)认可的是“混沌第一性原理”,在混乱中学习。基于数学规则的模拟(虚幻引擎)认可的是“定律第一性原理”,存在更高设计者。
以上两者都存在争议,那么这两者可以结合吗?
5
创世背后,可能的“数学漏洞”
Sora是否是“世界模型器”,数学家有自己的看法。
在很多科学家眼中,宇宙的本质是数学。
如果Sora能以模拟方式最终逼近数学本质,那它也可能被视为“创世纪”。
Sora模型中用到了很多数学原理,举例如下:

但从Sora模型生成的视频来看,仍然存在明显“数学漏洞”。
1 因果性的区分
Transformer模型训练过程中的统计方法无法精确捕捉数学积分。
2 局部合理性与整体合理性
要求模型能够整合更高层次数学理论,以实现整体的一致性(例如蜡烛被吹灭)。
3 临界态的识别和模拟
无法通过几何方法的最优传输理论来精确探测数据流形的边界(从量变到质变)。
Sora模型展示了通过深度学习模拟复杂物理世界的潜力,但也存在明显“数学漏洞”,如果能真正模拟物理世界,需要更高层次的数学理论并且探索新的模型结构。
6
AI世界存在大统一模型吗?
很明显,OpenAI试图建立AI大统一模型。
它通过GPT-4.0、DALL·E 3和Sora等模型的开发,试图在语言、图像和视频等不同模态之间建立桥梁,完成大统一。
但很多人并不买账,深度学习三巨头的Yann LeCun提出的非生成式V-JEPA模型试图通过结合视觉感知和物理推理来构建更为精确的世界模型。
AI大统一模型并非没有可能,一种新的方向已经出现:
将不同模态的数据转化为一种或多种统一的基本粒子形式,以便使用同一套算法框架进行处理和分析。
文字语言的Token基本粒子化,视频数据的Spacetime Patches基本粒子化让人看到了希望。
Sora模型其实已经让两种基本粒子Token和Spacetime Patches在进行交互,最后能统一成一种基本粒子吗?也不是不可能。
除了数据“基本粒子”化,同时也看到了四大理论逐渐成形:
1、基于Transformer架构的交互关系:
利用自注意力机制(Self-Attention Mechanism)使得模型能够捕获长距离依赖,为跨模态数据的序列对齐和时间依赖性建模提供数学框架。
2、Diffusion模型的逐步细化过程:
Diffusion模型通过渐进式去噪进行连续随机的离散化表达,嵌入了随机微分方程展现了模型在处理不同数据类型时的灵活性和多样性。
3、生成对抗网络(GAN)的创新应用:
生成器生成逼真的数据样本,而判别器则努力区分真实数据和生成数据,推动模型在生成质量、多样性以及对复杂数据分布的捕捉能力方面的进步。
4、模态转换的编解码器:
通过映射和逆映射的数学操作,实现了从具体数据到统一表示空间的转换。
物理世界的大统一理论是统一四种力,以上是AI世界的四种重要理论。
AI世界会存在大统一模型吗?
如果是,那现实物理世界是不是同样如此。
如果AI世界不存在大统一模型。
那么这么多年来科学家寻找的大统一理论是不是镜花水月?
也许,人类只有去创造一个世界,才能理解创世者。
结
AI背后,藏着一个创世梦想
一直以来,人类在探索宇宙起源,叩问创世者。
但今天,自己有力量可以成为创世者了。
千年回顾,这是不是人类文明史划时代时刻?
这一年来,目睹了Token化的大统一设计,见证了Transformer架构开疆拓土、理解了Diffusion模型底层意义、即将体验Spacetime Patches的革命创新。
这一年来,各种大模型纷至沓来,天才创意层出不穷。产品迭代惊心动魄,一年之间可谓覆地翻天。
可对于人类天才来说,这些还不够,他们要建立一个“世界模型”,创造一个数字宇宙。同时还希望这个世界完全遵循F = ma、E=MC2这样的物理规律。
如果真能做到,那它和现实世界有何区别。
再想一想,现实世界有没有可能也是一种模拟?
如果是,你是兴奋,还是担忧?
文章来自于微信公众号 “ 量子学派”,作者 “十七进制”



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
