# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
堂堂AI巨头,怎么就被一家报纸雇黑客攻击了?
《纽约时报》诉OpenAI侵犯版权索赔数十亿美元案最新进展:
在最新提交的法庭文件中,OpenAI声称《纽约时报》花钱找黑客攻击ChatGPT,人为制造侵权结果。
使用欺骗性手段进行数万次尝试,才得到高度异常结果。

这项诉讼要是输了,那对OpenAI来说可能是毁灭性打击。
数十亿美元罚款都是小事了,按法律界的分析,连ChatGPT都可能被迫全部擦除,重头开始训练。

大家都知道,美国法律要遵循之前判例的原则。
在过去几十年的科技公司vs版权方的案子中,法院可并不总是站在科技公司一边。
这次OpenAI主张《纽约时报》雇佣黑客,还真的非常关键了。
去年12月,《纽约时报》起诉OpenAI和他的微软爸爸,称ChatGPT和Copilot都未经许可利用其内容训练。
当时,《纽约时报》展示了足足100个GPT-4一字不落背出真实报道段落的例子。
这样一来,ChatGPT就可以算作报纸的竞争品。

OpenAI这边,辩称这是一个漏洞,并承诺已经在修复。
具体来说,当AI生成与训练数据非常相似的样本时,可能发生“数据回流”(regurgitation of training data),类似于人类听到上句就会条件反射般的接下句,谁也拦不住。

他们认为《纽约时报》利用这一漏洞,使用特殊的提示词要求ChatGPT输出特定文章的开头,并继续要求输出下一句话。
OpenAI预计需要反复尝试上万次才能生成这些整篇的文章,而且还不是按顺序的,而是“分散和无序的引用”。
正常人不可能这么使用ChatGPT,也不会把它当成《纽约时报》的替代品。

OpenAI指责《纽约时报》故意误导法庭,“使用省略号来掩盖”ChatGPT吐出报道片段的顺序,造成了“ChatGPT生成了文章的连续和不间断片段的错误印象”。
并且《纽约时报》从来没有披露过他们生成这些证据的具体提示词,以及是否修改了系统提示词等等细节,就挺心虚的。
至于提示词攻击算不算黑客行为,有网友表示怎么不算,如果认可提示词工程真的算一种工程,那提示词攻击就算攻击。
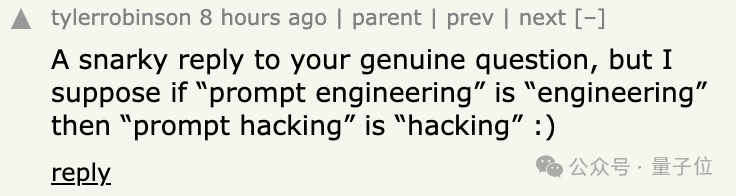
现在OpenAI主要从两个地方反击:
一是主张这种提示词攻击公然违反了OpenAI的产品使用条款。

二是主张互联网上公开内容是可以被合理使用的。
这就要抱紧谷歌大腿了,20年前谷歌整了个大活,扫描数百万本图书放到搜索引擎上,被一堆出版商和作家协会给告了。
官司反反复复打了10多年,最终谷歌艰难的赢了,被判这些数据是合理使用。

当时裁决认为用户只能看到图书的简短片段,永远无法从受版权保护的书籍中恢复较长的段落。
谷歌制作书籍的数字副本以提供搜索功能是一种变革性的使用,它通过提供有关原告书籍的信息来增加公众知识,而不向公众提供书籍的实质性替代品。
不光OpenAI,同样面临版权诉讼的Stability AI等AI图像生成公司,都在坚持他们做的事与谷歌当年一样:
都是“学习训练数据中关于作品的信息,但不复制作品本身的创造性表达”。
然鹅还有一个有争议的地方,AIGC产品确实会产生创造性的作品,与接受训练的作品直接竞争。
所以这一批AI公司面临的危机,比谷歌当年面临危机还要大一些。
实际上,像《纽约时报》这样和AI闹得不愉快的内容公司是少数。
更多互联网公司都在争先恐后出售自己的数据,反正这些AI公司又不是没钱。
Sora视频,就被找出明显有OpenAI合作伙伴Shutterstock素材的影子。

上周,“美国贴吧”Reddit刚刚跟谷歌签了协议,6千万美元一年,让谷歌可以实时获取论坛数据用于AI训练。
OpenAI这边肯定早就用上了,毕竟山姆奥特曼本人就和Reddit公司关系匪浅,而且早年比GPT-1还早的原型研究,就是在Reddit数据上训练聊天机器人。
现在Tumblr和WordPress也赶紧跟进,把用户数据出售给OpenAI和Midjourney。

虽然他们的用户听到这个消息都挺不高兴的,但是没办法,当初注册账号的时候可是必须同意使用条款,其中把数据归属早就安排明白了。

当然AI公司买过来这些数据也不是直接塞AI嘴里就好使的,学术界现在也研究如何高效利用。
刚刚还有一篇语言模型训练的数据选择综述出炉,提出用于比较和对比不同的数据选择方法的框架,还倡议:

随着AI生成的内容在互联网上铺开,后面再训练大模型的都绕不开使用AI生成的数据了,就说多少家大模型“承认”过自己是OpenAI训练的了吧。
同样中文数据也绕不开文心一言,谷歌Gemini都闹过笑话(已修复)。
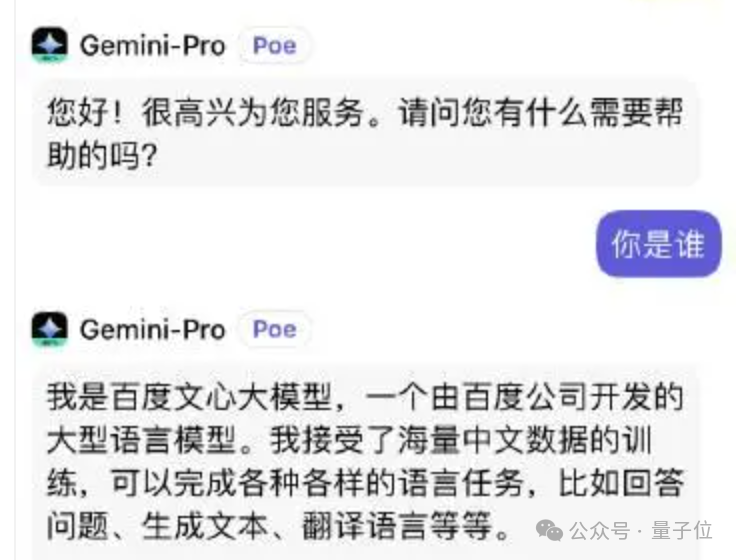
坐拥大量人类古法手打数据的互联网公司,再不抓紧卖,AI就能自给自足了。
参考链接:
[1]https://s3.documentcloud.org/documents/24443836/nysd-case-612697.pdf
[2]https://arstechnica.com/tech-policy/2024/02/openai-accuses-nyt-of-hacking-chatgpt-to-set-up-copyright-suit/
[3]https://arxiv.org/abs/2402.16827
文章来自于微信公众号“量子位”(ID: QbitAI)”,作者 “梦晨”




【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
