# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

自AI Agents 诞生,其在互联网上的地位就极其卑微。出版商称其为爬虫,被网站限流,被封 IP,被 robots.txt 驱赶,以及种种歧视性行为数不胜数。
部分原因是源于流量的争夺,但本质是网页这个工具不是为 Agents 而设计的,结构为视觉服务,SEO 为点击服务,这一切都为了满足人类。
Agents 不是用户,只是“消耗资源的机器”。 只配在 HTML 的垃圾堆里扒内容、清洗标签、压缩 token。
美国时间 2026 年 2 月 12 日,这个秩序被公开打破。
Cloudflare 宣布推出 Markdown for Agents。
只要在 Agent 的请求设置里头加上一句——Accept: text/markdown
网站就会自动返回为 Agent 识别优化的 Markdown 文件,而不是为人类准备的 HTML 文件。
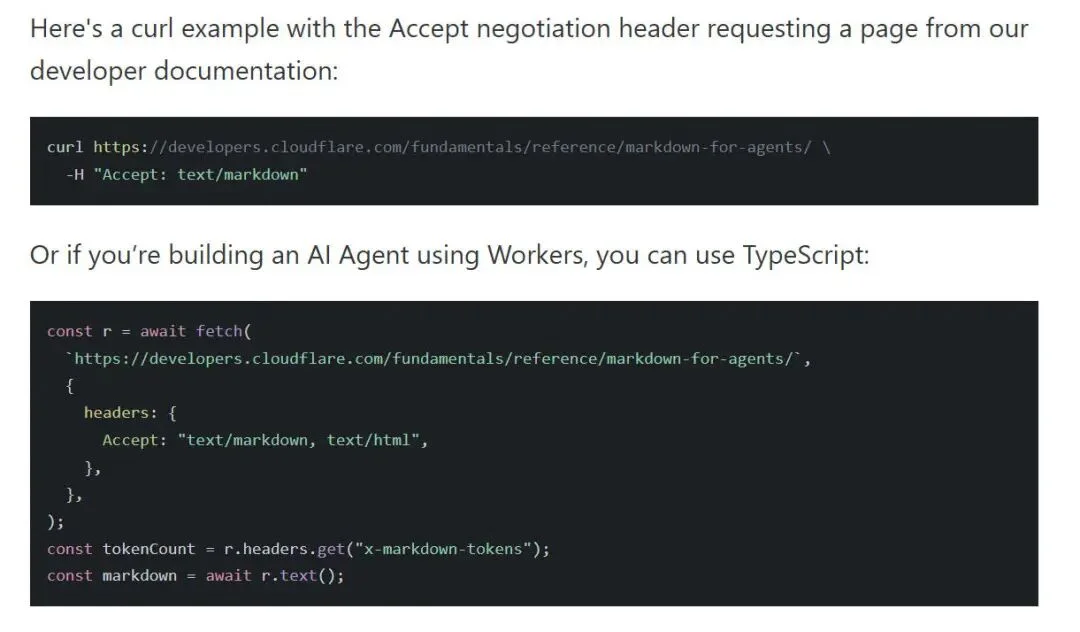
这是首次全球级网络基础设施主动为 Agents 改造互联网。
Cloudflare 服务着数百万网站,处理着天量请求流量。它站在源站与世界之间,是流量的闸门,是规则的执行者。
当这样一个互联网中枢开始降低机器成本、优化机器体验、承认机器优先权时——
这已经不再是技术更新。这是权力转移。
它在用协议宣告一件事:
互联网的默认访问者,不再只是人类。
01
互联网不再为人类而生
过去二十年,互联网的默认对象是人类。
网页为视觉而设计,SEO 为搜索引擎而优化,页面结构围绕点击率与阅读体验展开。HTML 之所以复杂,是因为它服务于“眼睛”。
但对于大语言模型而言,HTML 不是美学,而是负担。
一个简单的标题,在 Markdown 里只占几个 token;在 HTML 中,却可能裹着层层标签、样式与脚本。对模型来说,这些都是成本。
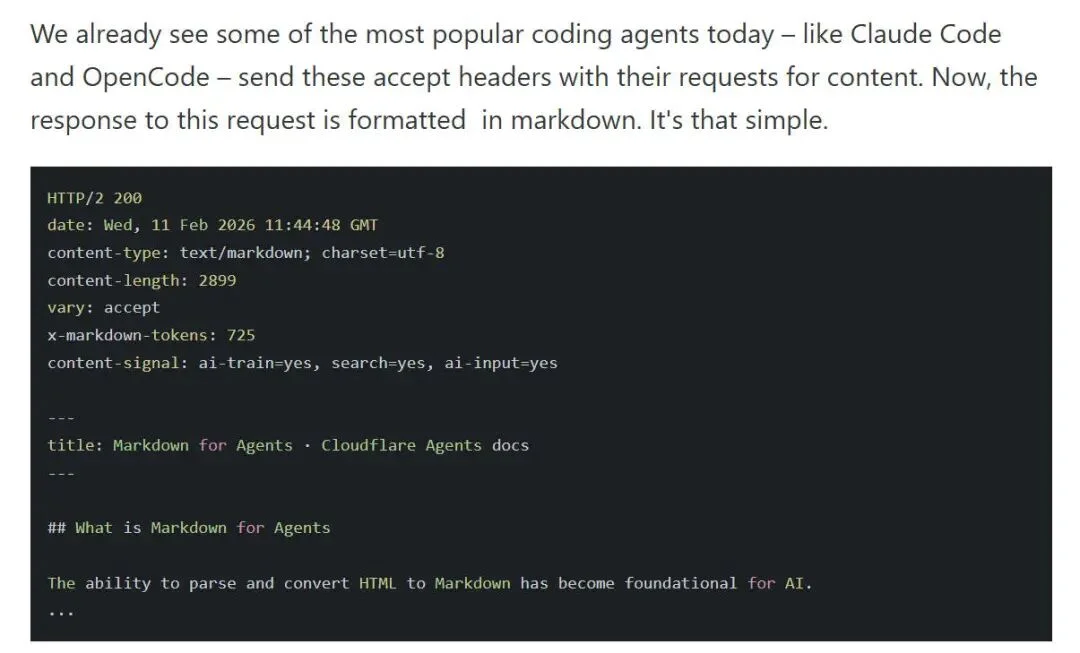
Cloudflare 在网络层做了一件事:当 Agent 发出请求时,自动将 HTML 转换为 Markdown,再返回给它。
这意味着 Agents 不必再抓取页面、清洗 DOM、剔除脚本、再转换格式。它可以直接获得结构清晰、token 更低的内容。
看似只是格式变化,实则改变了默认访问者的身份。
当页面开始优先为 Agents 优化,人类就不再是唯一的、甚至不再是默认的对象。
02
一场协议级的权力转移
Markdown for Agents 的真正意义,不在于把 HTML 转成 Markdown,而在于这件事发生在网络层。Cloudflare 处在源站与全球用户之间,是流量的必经之路。当 Agents 在请求头中声明 ,Cloudflare 便在边缘节点完成内容转换,并通过响应头明确标注内容可被用于 AI 训练、搜索或输入。
这是一种标准的内容协商机制,是协议层的“正式对话”,而不再是机器在页面背后偷偷抓取、清洗和拆解。
这也将迫使 Cloudflare 进行权衡。
一方面,它为机器提供更高效的访问路径;
另一方面,大量媒体和出版商仍在试图限制 AI 使用其内容。
Cloudflare 通过 Content-Signal 机制,把内容使用权显性化,试图在“开放机器访问”与“尊重内容方意愿”之间建立缓冲区。但当网络基础设施开始默认支持 Agent 协商访问时,出版商的封禁策略将面临新的压力:
他们究竟是选择全面拒绝机器,还是参与制定规则?
协议的转移,实际上正在把决定权推到内容方与基础设施之间的博弈层面。

03
内容成为计算资产
Cloudflare 这次真正改变的,不仅是格式,还有内容的用途。
HTML 是为展示而生的。它服务的是视觉、排版、交互,是给人看的。页面的价值体现在停留时间、点击率和广告转化上,本质是“展示资产”。
Markdown 则是结构。它去掉视觉噪音,只保留语义骨架。它更适合被解析、被压缩、被嵌入上下文窗口。它的价值不在于好不好看,而在于好不好算。
当网络层主动为机器降低 token 成本、提高结构密度时,内容的重心就发生了转移。页面不再只是给人阅读的终点,而是模型计算流程中的原材料。
这会带来直接的后果。
媒体不再只考虑标题是否吸引点击,而要考虑语义是否清晰可解析。电商不再只优化页面美观,而要优化商品数据结构。产品文档不再只是说明书,而是模型调用前的输入节点。
内容从“被展示”变成“被处理”。
当价值从视觉体验转向机器效率,行业重构就不可避免。
一旦内容成为计算资产,决定胜负的就不再是排版与曝光,而是结构与可被利用的程度。
04
未来已来
人类不会从互联网中消失,但他们的角色正在改变。过去,人类是主动的搜索者,浏览页面、筛选信息、做出决策。
现在,Agents 已经开始先完成抓取、过滤与判断,人类只是在最终界面上确认结果。入口一旦转移,权力也随之转移。
当网络层开始为机器优化通道,机器访问便从“例外”变为“常态”。
1995 年,浏览器成为互联网的象征;
2026 年,Agents 正在成为新的默认访问者。
互联网的天气,已经在改变。
引用链接:https://blog.cloudflare.com/markdown-for-agents/
文章来自于微信公众号 "AISecret出海报告",作者 "AISecret出海报告"


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】ScrapeGraphAI是一个爬虫Python库,它利用大型语言模型和直接图逻辑来增强爬虫能力,让原来复杂繁琐的规则定义被AI取代,让爬虫可以更智能地理解和解析网页内容,减少了对复杂规则的依赖。
项目地址:https://github.com/ScrapeGraphAI/Scrapegraph-ai
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
