# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
视频生成进入大规模时代,但计算成本也炸了。
10秒视频,token数超5万,自注意力复杂度O(n²)——跑不动,根本跑不动。
换线性注意力O(n)?理想很丰满,现实是:一换就崩。
为了解决这一难题,来自香港科技大学、北航、南洋理工等单位的研究团队提出:LINVIDEO:一个无需数据、无需重新预训练的后训练框架,实现视频扩散模型的高比例线性化替换,同时保持生成质量。

△ 14B模型视频生成效果:(上)wan2.1;(中)LINVIDEO 【1.71倍加速】;(下)4步蒸馏LINVIDEO【20.9倍加速】。
论文已被CVPR接收。在Wan 14B上,LINVIDEO实现1.71×端到端加速;结合4-step蒸馏后,可达到20.9×加速,且视频质量几乎无损。

LINVIDEO先回答了一个关键问题:为什么线性注意力在一些任务上可行,但在视频扩散模型上常常“替换就崩”?原因并不只是“linear attention近似误差更大”,而是替换过程本身很敏感:不同层的注意力对最终生成质量的作用并不均衡,某些层替换会造成明显退化,而另一些层替换影响较小;如果用手工规则或启发式策略去选替换层,很容易出现“替得越多越掉点”,或者为了不掉点而不敢替换太多层,最终加速不明显。
△ 层敏感性/不同层替换影响的分析
此外简单使用MSE做输出对齐,会引入明显的时序抖动与闪烁问题。

△ 使用MSE做对齐的生成效果
而few-step蒸馏类的distribution matching方法,仅对最终分布对齐,忽略中间时刻分布,导致性能明显下降。更严重的是,传统方法还需要额外训练一个辅助模型来估计score function,训练成本极高。因此,视频模型的线性化不仅是结构问题,更是优化目标问题。
LINVIDEO的整体思路可以概括为:
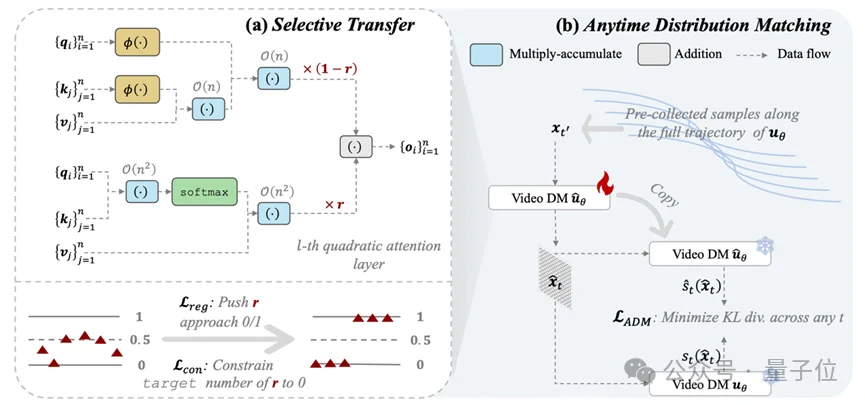
△ LINVIDEO框架图。
先把“替哪几层”变成可学习问题,再把“怎么训回来”换成更适合视频的对齐目标。
在“替换层选择”上,LINVIDEO不走手工挑层或经验规则,而是把layer selection视为一个二分类决策问题,提出selective transfer:让模型在后训练过程中自动、渐进地把一部分注意力层迁移到线性形式,尽量把性能损失压到最小。
直观理解就是:不是“一刀切”全换,而是让模型自己学会“哪些层可以安全线性化、哪些层要保留”,并且逐步完成迁移,避免瞬间替换带来的分布突变。
LINVIDEO还提出anytime distribution matching(ADM):不是只对齐某个固定时刻,而是沿着采样轨迹,在任意timestep上对齐样本分布,从而更有效地把线性化后的模型“拉回”原模型行为。论文强调这个目标不仅能恢复性能,而且更高效(无需像传统分布匹配方法一样需要训练辅助模型),能避免一些既无效又低效的优化过程。
LINVIDEO在【Wan 1.3B】与【Wan 14B】上做了系统评测,采用VBench的8个维度进行综合评估,同时也报告了VBench-2.0(带增强提示)来衡量物理规律、常识一致性等更难的能力。
对比方法覆盖了主流稀疏注意力与动态注意力方案,包括SVG、SVG2、DFA以及动态方法XAttention;延迟测试在单卡【H100】上完成,并只使用各方法的fast attention实现保证公平性。
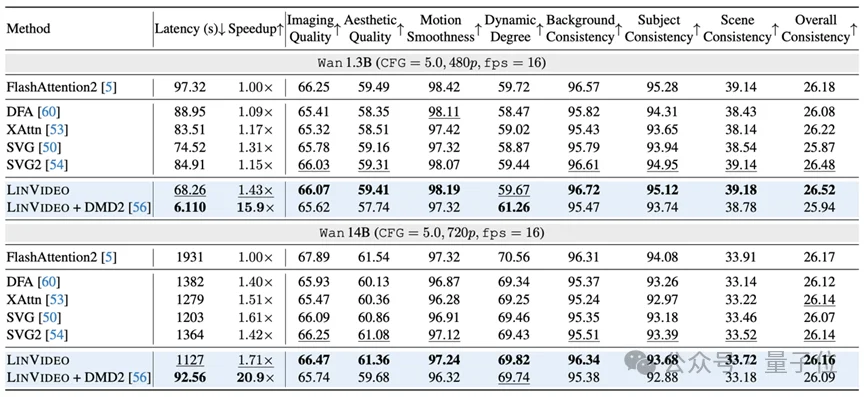
△ VBench性能对比
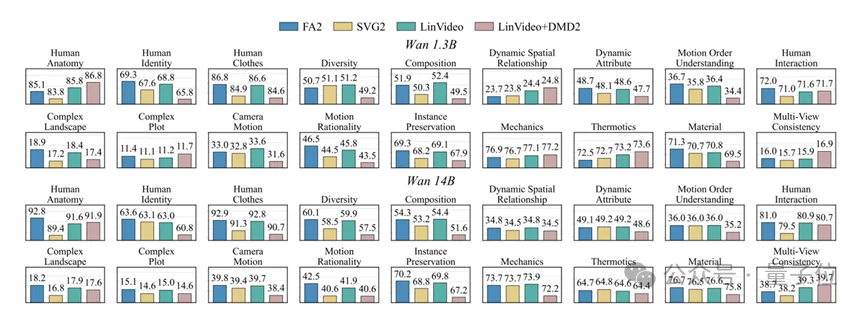
△ Vbench-2.0性能对比
论文给出的核心结论是:在同等评测下,LINVIDEO能在尽量保持生成质量的前提下,把视频扩散模型的推理速度推到一个更实用的位置。整体上,LINVIDEO报告了1.43–1.71×的加速,同时质量保持稳定;在进一步结合4-step蒸馏后,端到端延迟可达15.9–20.9×的降低,而主观视觉质量仅有轻微下降。
这意味着LINVIDEO不只是“把注意力换成线性”这么简单,而是提供了一套能落地的迁移与对齐方案,让视频扩散模型的大比例线性化变得可行。


△ 1.3B模型视频生成效果:(上)wan2.1;(中)LINVIDEO 【1.71倍加速】;(下)4步蒸馏LINVIDEO【20.9倍加速】。


△ 14B模型视频生成效果:(上)wan2.1;(中)LINVIDEO 【1.71倍加速】;(下)4步蒸馏LINVIDEO【20.9倍加速】。
LINVIDEO传递的信息很明确:视频扩散模型的线性化难点,不在于“有没有线性注意力”,而在于“怎么把模型迁移过去还能把质量训回来”。
它用selective transfer解决“替换层选择”的敏感性,用ADM解决“视频场景对齐目标”的有效性与效率问题,从而在不重新预训练的前提下,推进了视频扩散模型从O(n²)走向更可扩展的O(n)推理路径。
论文地址:
https://arxiv.org/pdf/2510.08318
文章来自于“量子位”,作者 “LinVideo团队”。


