# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
随着 Sora 的爆火,人们看到了 AI 视频生成的巨大潜力,对这一领域的关注度也越来越高。
除了视频生成,在现实生活中,如何对视频进行编辑同样是一个重要的问题,且应用场景更为广泛。以往的视频编辑方法往往局限于「外观」层面的编辑,例如对视频进行「风格迁移」或者替换视频中的物体,但关于更改视频中对象的「动作」的尝试还很少。

UniEdit 视频编辑结果(动作编辑、风格迁移、背景替换、刚性 / 非刚性物体替换)
本文中,来自浙江大学、微软亚洲研究院、和北京大学的研究者提出了一个基于文本描述的视频编辑统一框架 UniEdit,不仅涵盖了风格迁移、背景替换、刚性 / 非刚性物体替换等传统外观编辑场景,更可以有效地编辑视频中对象的动作,例如将以上视频中浣熊弹吉他的动作变成「吃苹果」或是「招手」。
此外,除了灵活的自然语言接口和统一的编辑框架,这一模型的另一大优势是无需训练,大大提升了部署的便捷性和用户使用的方便度。

a) 对象动作编辑

编辑指令:一只正在趴着的柯基
b) 风格化

编辑指令:上海,码头,油画风格
c) 背景替换

编辑指令:钢铁侠在公园,冬季
d) 对象刚性编辑

编辑指令:一位男士穿着红色西装
e) 对象非刚性编辑

编辑指令:马里奥正在享用晚餐
可以观察到,UniEdit 在不同编辑场景中 1)保持了较好的时序一致性,2)较好的保留了原视频的结构及纹理细节,3)生成符合文本描述的编辑视频,展现出了强大的视频编辑能力。
2.UniEdit 独特之处与技术创新点
研究者表示,UniEdit 相较于其他视频编辑方法,其独特之处体现在:
UniEdit 技术上的核心创新点为:
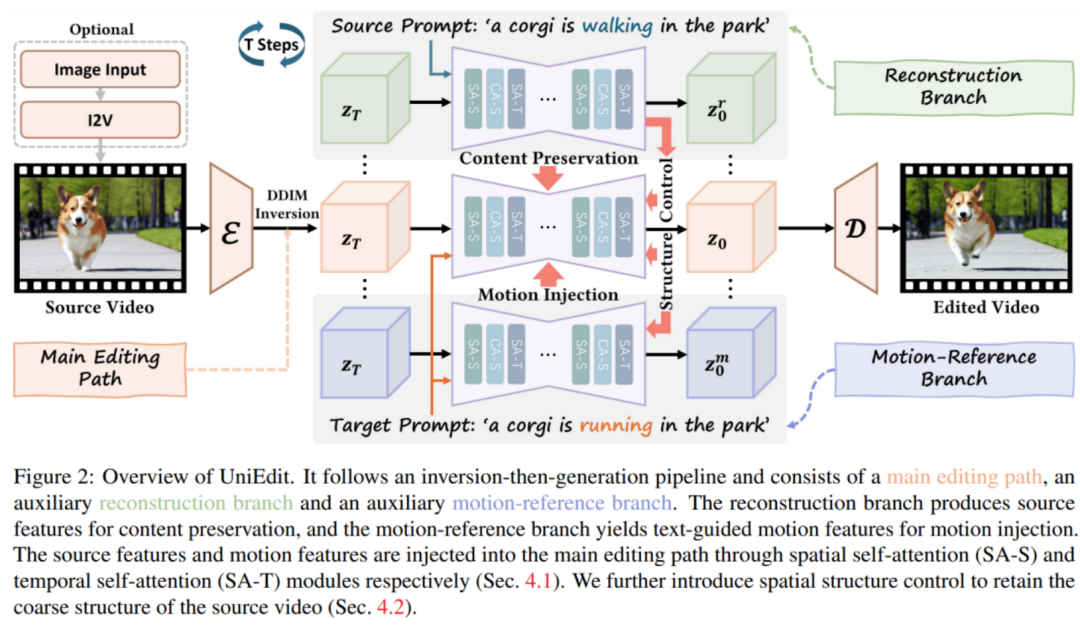
方法概述。如上图所示,UniEdit 主编辑路径遵循反演 - 生成流程:使用 DDIM 反演后的潜变量作为初始噪声![]() ,然后以目标提示
,然后以目标提示![]() 为文本条件,使用预训练的 UNet 进行去噪处理。进行动作编辑时,为了实现源内容保留和动作控制,研究者提出加入一个辅助视频重建分支和一个辅助动作参考分支,以提供所需的源视频内容和动作特征,这些特征被注入到主编辑路径中,以实现内容保留和动作编辑。
为文本条件,使用预训练的 UNet 进行去噪处理。进行动作编辑时,为了实现源内容保留和动作控制,研究者提出加入一个辅助视频重建分支和一个辅助动作参考分支,以提供所需的源视频内容和动作特征,这些特征被注入到主编辑路径中,以实现内容保留和动作编辑。
对象动作编辑 — 内容保留。编辑任务的关键挑战之一是继承源视频中的原始内容(例如纹理和背景)。如图像编辑中所验证的,重建过程中去噪模型的注意力特征包含了源视频的内容信息。因此,UniEdit 将视频重建分支中的注意力特征注入到主编辑路径的空间自注意(SA-S)层中,以保留原视频内容。
在去噪步骤 t,主编辑路径中第![]() 个 SA-S 模块的注意力机制操作如下:
个 SA-S 模块的注意力机制操作如下:
其中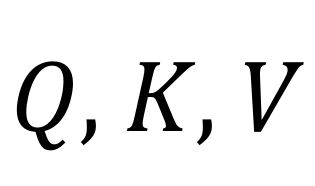 是主编辑路径中的特征,
是主编辑路径中的特征,![]() 是重建分支中对应 SA-S 层的值(value)
是重建分支中对应 SA-S 层的值(value)![]() ,和
,和![]() 为超参数。通过替换空间自注意力层的 value 特征,主编辑路径合成的视频保留了源视频的未编辑特征(例如背景)。与之前的视频编辑工作使用的跨帧注意力机制不同,研究者采用逐帧替换的操作,以更好地处理包含大幅度动作的源视频。
为超参数。通过替换空间自注意力层的 value 特征,主编辑路径合成的视频保留了源视频的未编辑特征(例如背景)。与之前的视频编辑工作使用的跨帧注意力机制不同,研究者采用逐帧替换的操作,以更好地处理包含大幅度动作的源视频。
对象动作编辑 — 动作注入。为了在不牺牲内容一致性的情况下获得所需的动作,研究者提出用参考动作指导主编辑路径。具体来说,在去噪过程中涉及一个辅助动作参考分支。与重建分支不同,动作参考分支以包含所需动作描述的目标提示![]() 为条件。为了将动作转移到主编辑路径,研究者的核心洞察是时间层模拟了合成视频剪辑的帧间依赖性(如下图所示)。受上述观察的启发,研究者设计了在主编辑路径的时间自注意层上注入注意力图:
为条件。为了将动作转移到主编辑路径,研究者的核心洞察是时间层模拟了合成视频剪辑的帧间依赖性(如下图所示)。受上述观察的启发,研究者设计了在主编辑路径的时间自注意层上注入注意力图:
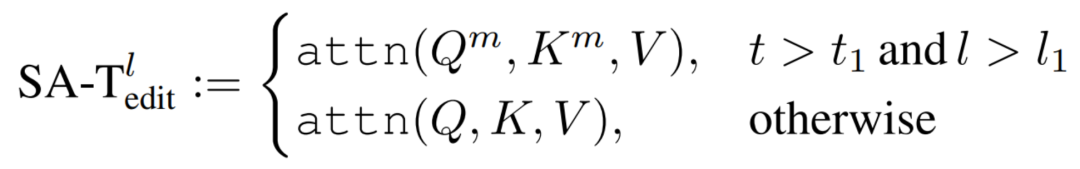
其中![]() 和
和![]() 指的是动作参考分支的查询(query)和键值(key),并在实践中将
指的是动作参考分支的查询(query)和键值(key),并在实践中将![]() 和
和![]() 设置为零。研究者观察到,时间注意力图的注入可以有效地帮助主编辑路径生成与目标提示一致的动作。为了更好地将动作与源视频中的内容融合,研究者还在早期去噪步骤中对主编辑路径和动作参考分支实施空间结构控制。
设置为零。研究者观察到,时间注意力图的注入可以有效地帮助主编辑路径生成与目标提示一致的动作。为了更好地将动作与源视频中的内容融合,研究者还在早期去噪步骤中对主编辑路径和动作参考分支实施空间结构控制。
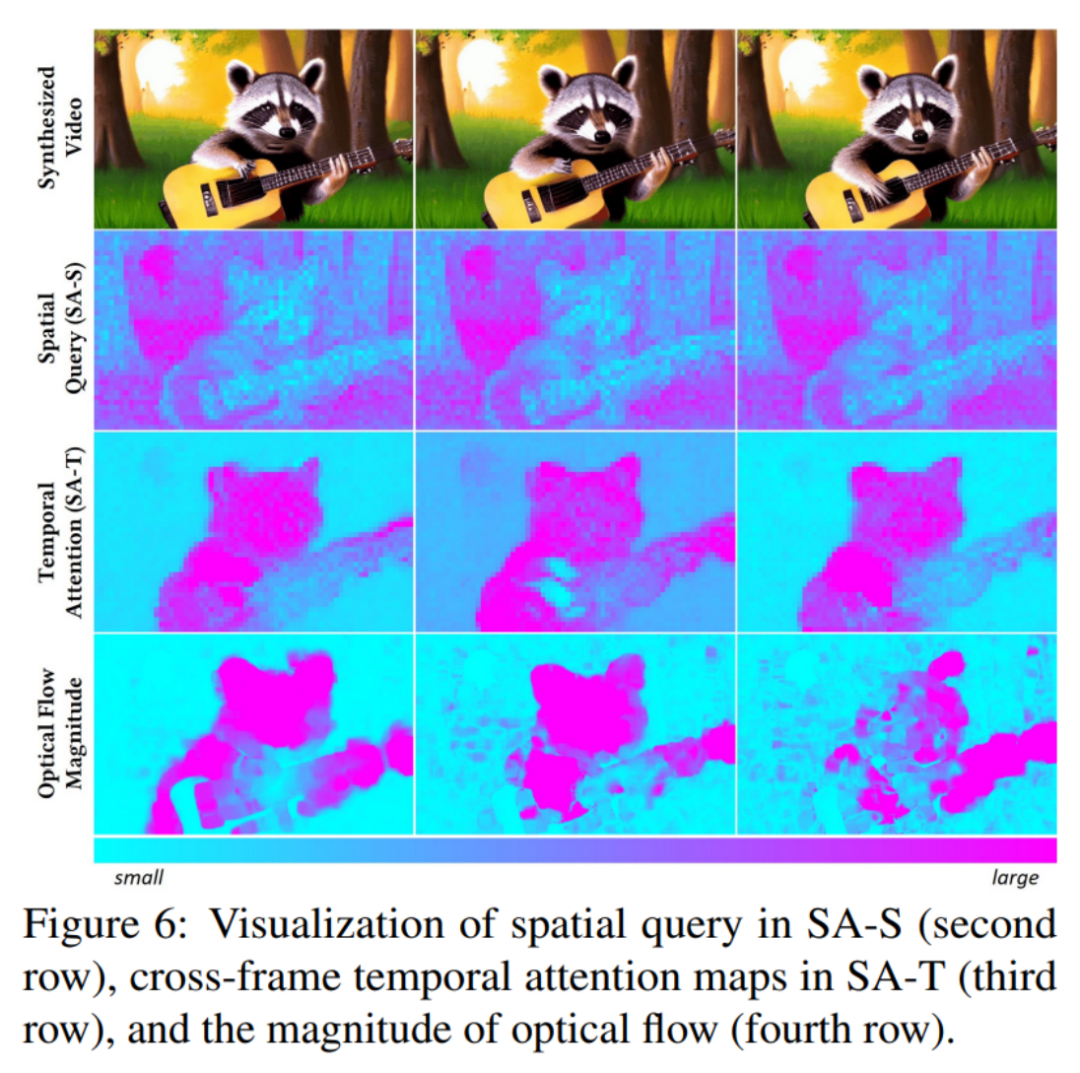
外观编辑 — 空间结构控制。总的来说,外观编辑和动作编辑之间有两个主要区别。首先,外观编辑不需要改变视频的帧间关系。因此,研究者从动作编辑流程中移除了动作参考分支和相应的动作注入机制。其次,外观编辑的主要挑战是保持源视频的结构一致性。为了解决这个问题,研究者在主编辑路径和重建分支之间引入了空间结构控制。
先前的视频外观编辑方法主要利用辅助网络(例如 ControlNet)实现空间结构控制。当辅助控制模型失败时,可能会导致在保持原始视频结构方面的性能下降。作为替代,研究者建议从重建分支中提取源视频的空间结构信息。直观地说,空间自注意层中的注意力图编码了合成视频的结构,如下图所示。因此,研究者用重建分支中的查询和键替换主编辑路径中 SA-S 模块的查询和键:
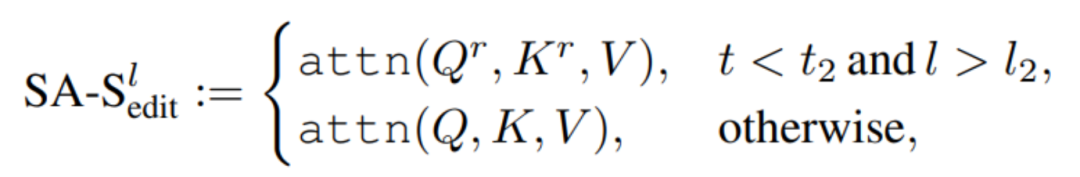
其中![]() 和
和![]() 指重建分支的查询和键,
指重建分支的查询和键,![]() 和
和![]() 用于控制编辑的程度。值得一提的是,空间结构控制的效果与内容保留机制不同。以风格化为例,上式中的结构控制机制只确保了每帧空间构图的一致性,同时使模型能够基于文本提示生成所需的纹理和风格。另一方面,内容呈现技术继承了源视频的纹理和风格。因此,研究者使用结构控制而不是内容保留来进行外观编辑。
用于控制编辑的程度。值得一提的是,空间结构控制的效果与内容保留机制不同。以风格化为例,上式中的结构控制机制只确保了每帧空间构图的一致性,同时使模型能够基于文本提示生成所需的纹理和风格。另一方面,内容呈现技术继承了源视频的纹理和风格。因此,研究者使用结构控制而不是内容保留来进行外观编辑。

允许图像输入。为了使 UniEdit 更加灵活,研究者进一步提出一种方法,允许将图像作为输入并合成高质量的视频。与图像动画技术不同,UniEdit 允许用户用文本提示指导动画过程。
具体来说,研究者提出首先通过以下方式实现文本到图像(I2V)的生成:1)通过模拟相机运动转换输入图像,形成伪视频片段;或者 2)利用现有的图像动画方法(例如SVD、AnimateDiff)合成一个具有随机动作的视频(这可能与文本提示不一致)。然后,研究者使用以上介绍的 UniEdit 算法对原始视频进行文本引导编辑,以获得最终输出视频。
UniEdit 不局限于特定的视频扩散模型。研究者将 UniEdit 建立在视频生成模型 LaVie 之上,以验证所提出方法的有效性。对于每个输入视频,研究者遵循 LaVie 的预处理步骤将分辨率调整为 320×512。然后,将预处理后的视频输入 UniEdit 进行视频编辑。每个视频在 NVIDIA A100 GPU 上编辑仅需 1-2 分钟。

基线方法。为了评估 UniEdit 的性能,研究者将 UniEdit 的编辑结果与最先进的动作和外观编辑方法进行比较。对于动作编辑,由于缺乏开源的无需训练的方法,研究者将最先进的非刚性图像编辑技术 MasaCtrl 适配到 T2V 模型,以及 one-shot 视频编辑方法 Tune-A-Video (TAV) 作为强基线。对于外观编辑,研究者使用最新的性能强大的方法,包括 FateZero、TokenFlow 和 Rerender-A-Video (Rerender) 作为基线。结果如下图所示:

定性结果。研究者在图中给出了 UniEdit 的编辑示例(更多示例见项目主页及论文原文)。观察到 UniEdit 可以:1)在不同场景中编辑,包括动作变化、物体替换、风格转换、背景修改等;2)与目标提示一致;3)展示出极佳的时序一致性。
此外,研究者在图 5 中与最先进的方法进行了比较。对于外观编辑,即将源视频转换为油画风格,UniEdit 在内容保留方面优于基线。例如草原仍保持其原始外观,没有任何额外的石头或小路。对于动作编辑,大多数基线方法未能输出与目标提示对齐的视频,或者未能保留源内容。
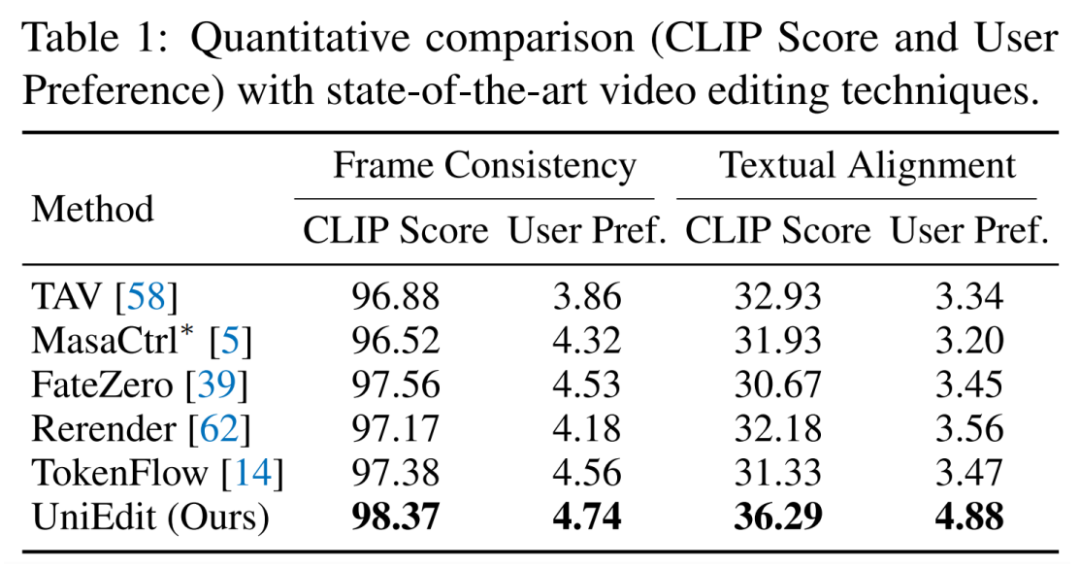
定量结果。研究者从两个方面定量验证了 UniEdit 的有效性:时间一致性和与目标提示的一致性。遵循之前的工作,研究者使用 CLIP 模型计算帧间一致性和文本对齐的分数。研究者还通过邀请 10 位参与者对 UniEdit 和基线方法编辑的视频进行五级评分(1-5)进行了用户研究。如下表所示,UniEdit 的表现大幅超过基线方法。
更多细节内容请参阅原论文。
文章来自于微信公众号 “机器之心”



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
