# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
人类创作者与 Agent 是平等的。

OpenClaw 火了之后,行业里出现了一个挺有意思的判断。
大家开始讨论一件事:AI 产品需要 Agent 化。要让 Agent 能理解你的产品,能调用你的能力,要给 Agent 留下足够多、足够好用的接口。
换句话说,产品未来的用户,可能有一半是 Agent。
这个判断放在一年前,大多数人会觉得有点超前。但 OpenClaw 之后,它变得非常具体了。当你看到一个 Agent 可以自己去调用工具、编排流程、跑完一整段任务的时候,你会很自然地想到下一个问题:那其他领域呢?视频创作呢?
就是在这个节点上,LiblibAI 推出了一款新的 AI 视频产品:LibTV。
这个产品最大的看点之一,就是从 Day 1 开始,同时给人和 Agent 用。人类创作者有自己的画布和工作流,Agent 有自己的 Skill 接口,两者是平等的。
接下来,分享我们的实测体验和观察。
如果你去跟真正在用 AI 做视频的创作者聊,会发现一个很普遍的感受:生成一个好看的镜头,已经不难了。难的是,怎么把十几个、几十个镜头,组织成一支完整的片子。
这个过程非常碎,市面上大致有两类方案。
【1】一类是 Agent 对话式的,你给它一句话,它帮你生成。这种方案上手很快,但能力上限很低,稍微复杂一点的创作意图,它就理解不了了。
【2】另一类是纯节点式工作流,像 ComfyUI 这种。能力确实很强,但搭建成本、门槛太高了,能劝退大部分创作者。而且过程中遇到的各种小修改、小调整,因为没有顺手的工具,只能不断导出到别的软件里处理,流程被切得更碎了。
所以,这个领域真正缺的,是一个能把模型能力和创作流程串在一起的东西。
LibTV 想做的,就是这件事。

不过,在做这件事的同时,他们同时将这块画布开放给了:人类和 Agent,人类方直接在 LibTV 画布上创建工作流,画布、节点、分镜、剪辑,所有需要精细控制的地方,你都可以自己上手调。
而 Agent 则是自动化地做这套任务,通过 Skill 接口,Agent 可以理解任务、调用模型、编排工作流、自动生成内容。
LibTV 直达:https://www.liblib.tv/
LibTV Skill 开源地址:https://github.com/libtv-labs/libtv-skills
这次我用 LibTV 从头搭了一个 AI 工作流,做了一条有点反转感的短片。顺带把 LibTV 现在有哪些独特功能、整体流程是什么体验,一起讲清楚。
我一开始构思的分镜是这样的:

先说基础。LibTV 的核心界面就是一块无限画布,双击任意位置,直接生成节点。
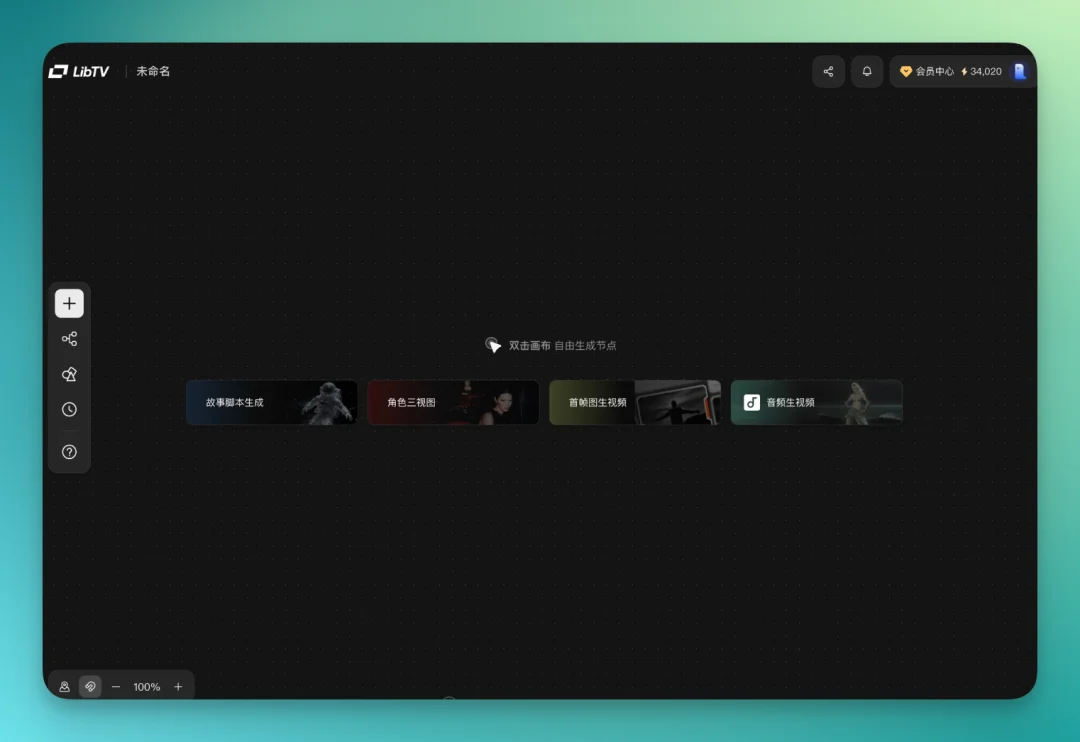
文本、图片、视频、音频、脚本,双击就能生成。也可以直接上传素材。LibTV 自己的资源库也是打通的,直接拖进画布就行。
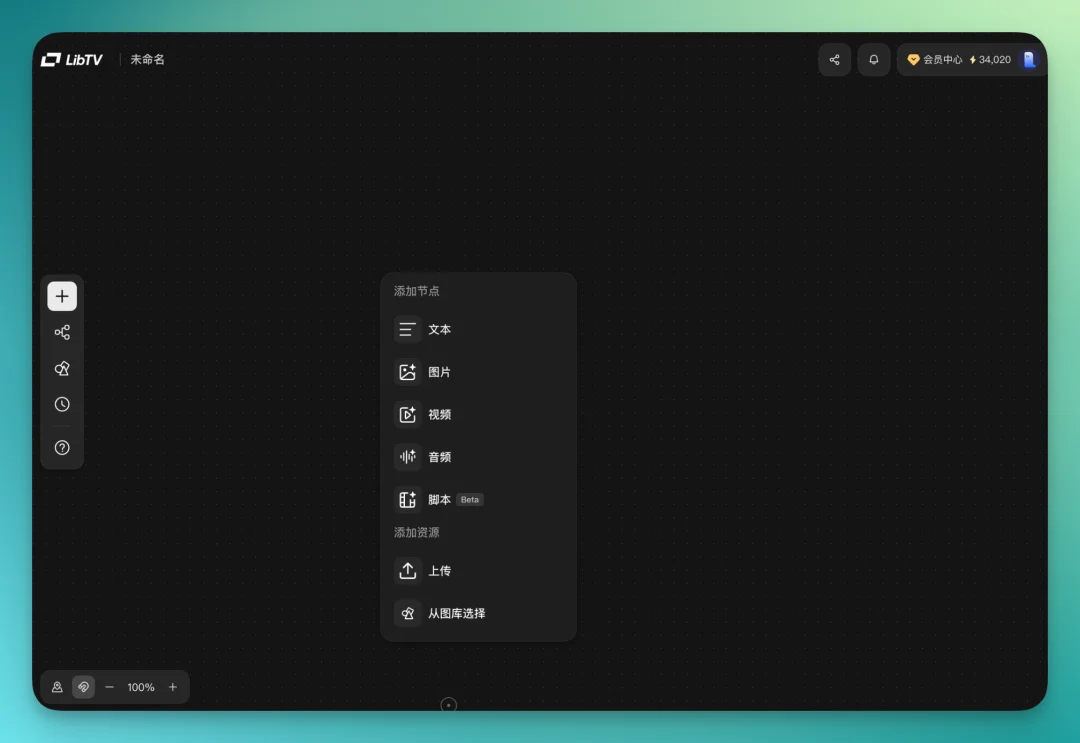
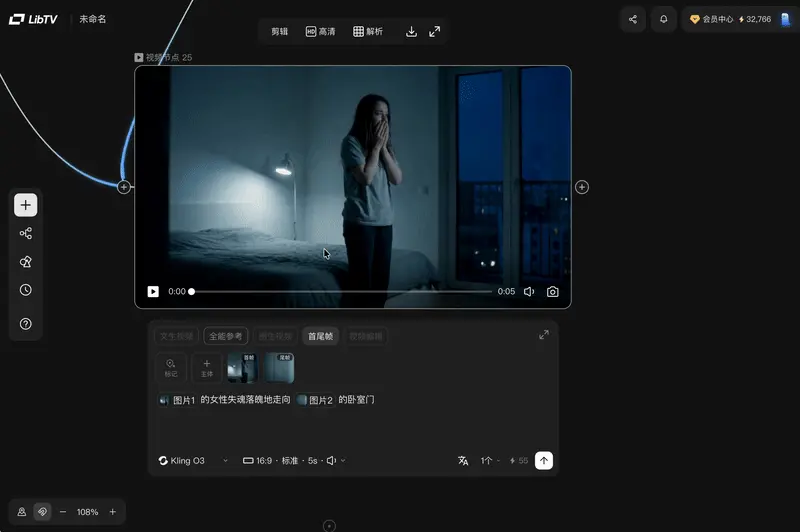
我这次做的短片,主场景是一个年轻女性在昏暗房间里哭泣。起点很简单,先建一个文本节点。
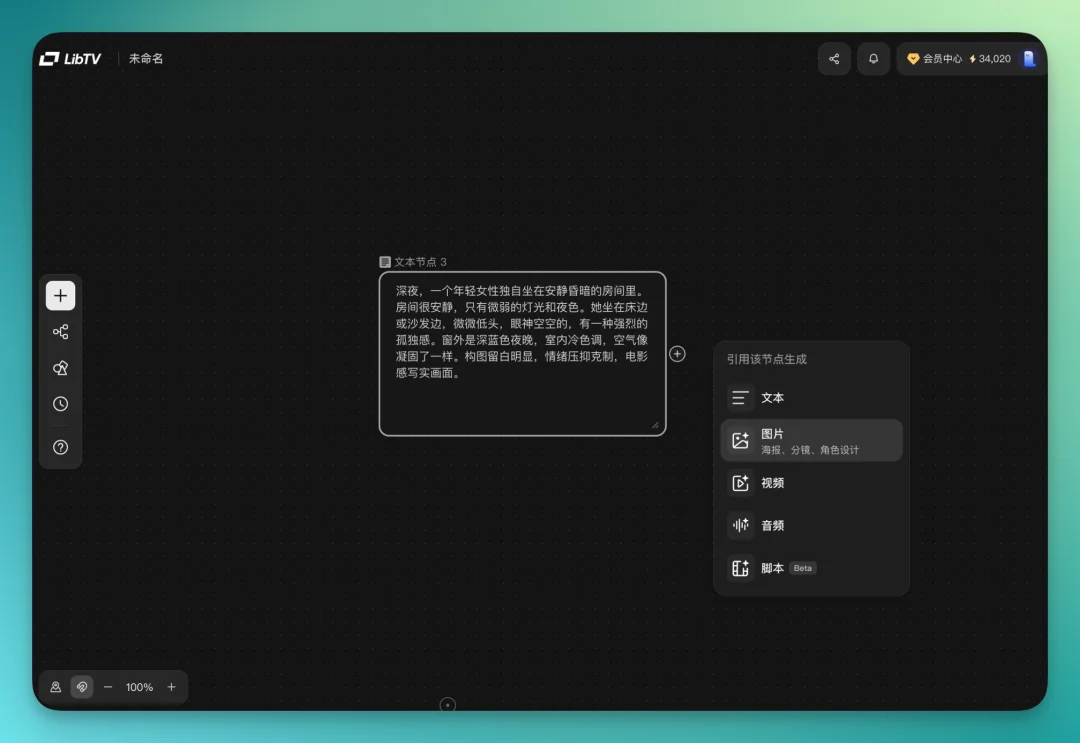
从文本节点直接拉一条线出来,接到下一个节点。比如接一个图片节点,思路走到哪,线就连到哪。连好之后直接生成图片。
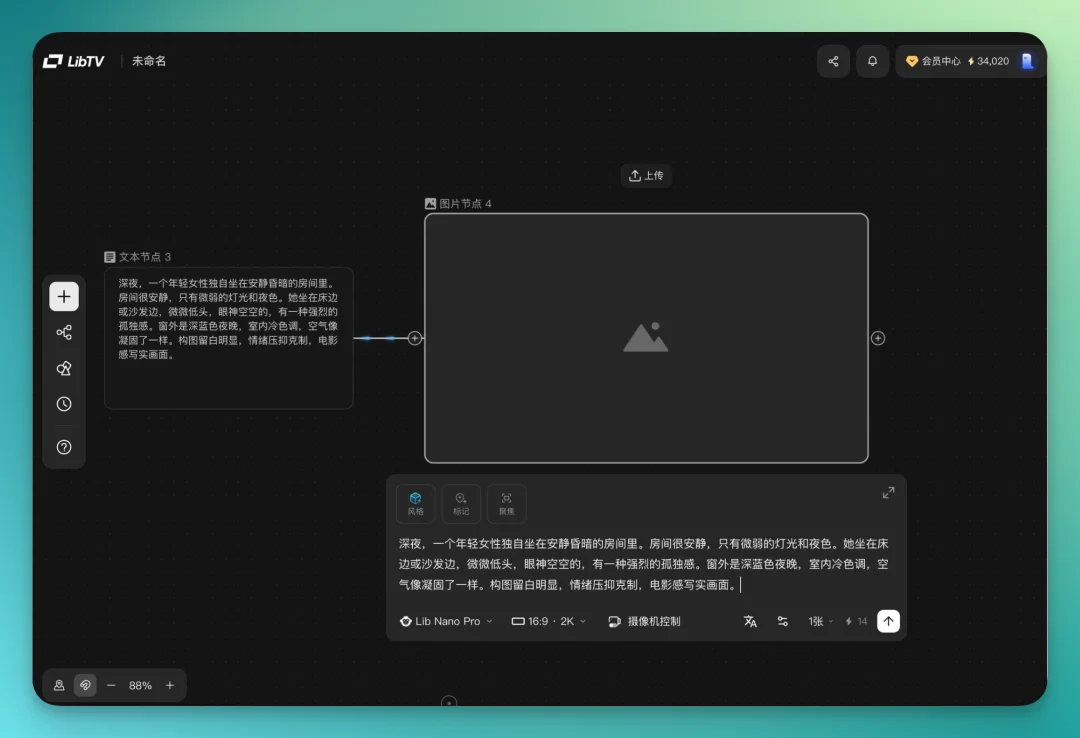
模型这块,LibTV 内置了一个挺全的模型库。图像有 Seedream 5.0、全能图片模型 V2 这些,视频有 Seedance 2.0、可灵 3.0 和 O3、Wan 2.6,语言模型接了 3 个主流 LLM,音频也有覆盖是 ElevenLab v3 和 Mureka v8。
我自己图片一般用 Lib Nano Pro,视频就用 Kling O3。
在画布里连线操作,整个流程会很顺。
有个细节功能挺有意思,图片节点上有个"聚焦"。就是说你可以框选之前某个节点里的某个主体或细节,作为参考去生成。
我就直接框了上一张图里人物的脸,让它聚焦脸庞,重点是眼神特写。
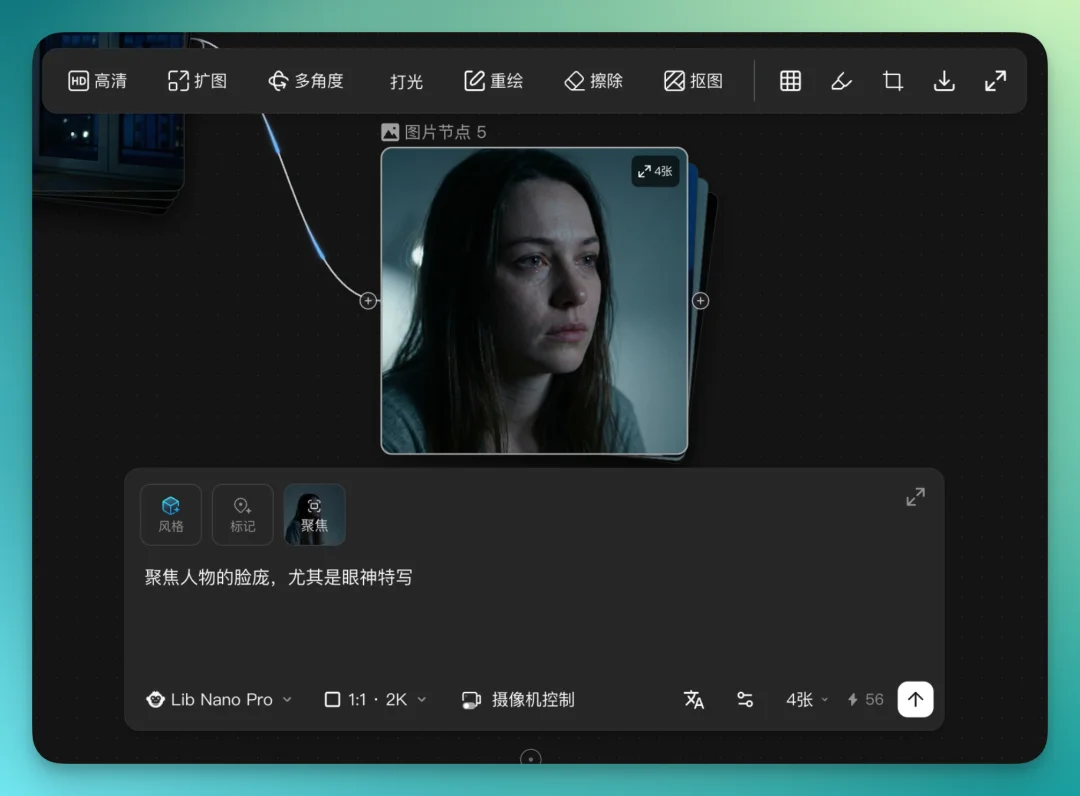
每个图片节点里子功能很多。打光效果可以直接选,亮度、颜色都是点一下就能调,基本是傻瓜式操作,透视角度也能直接拖。
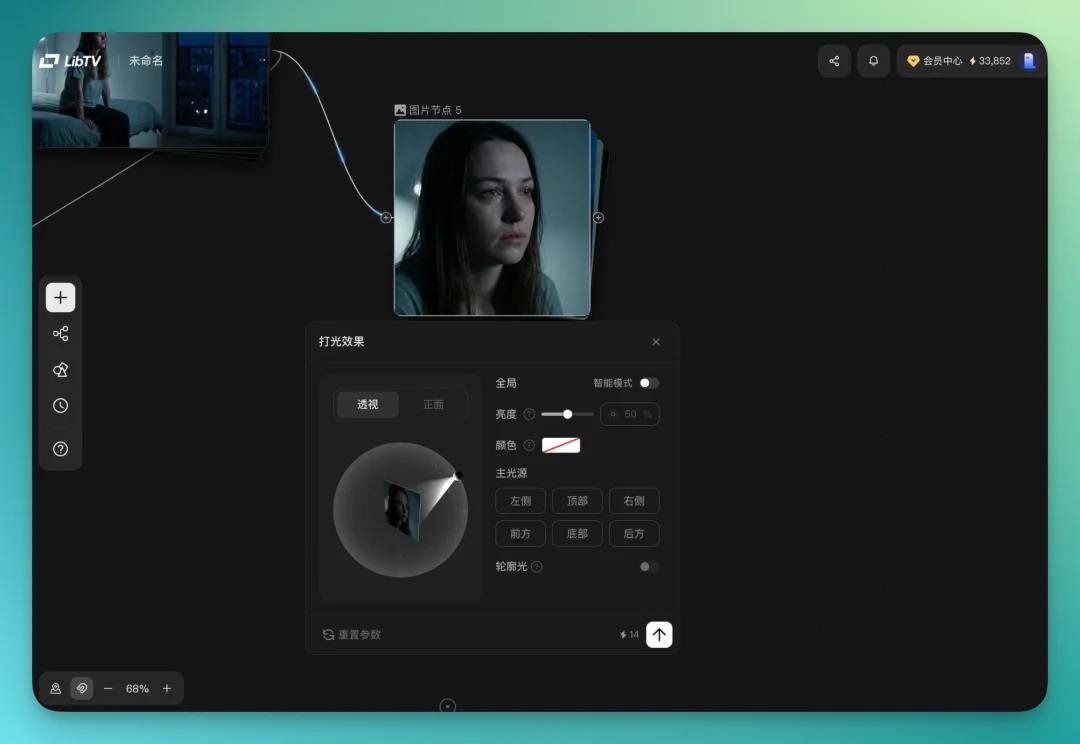
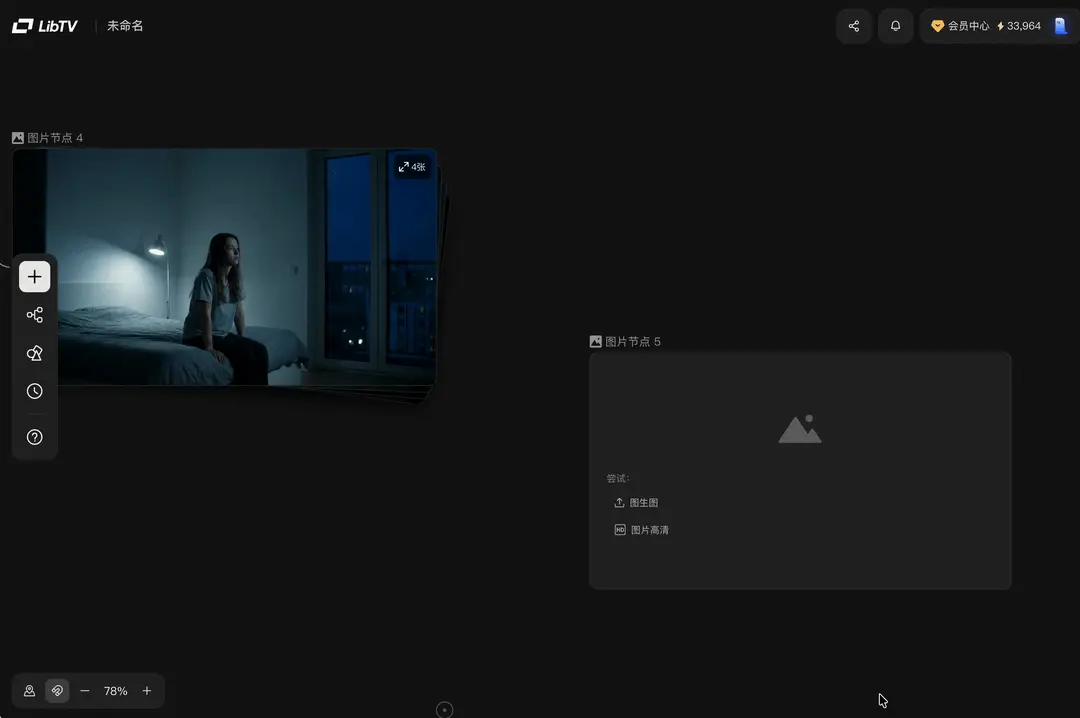
LibTV 里还有个实用的细节,视频节点里可以直接剪辑。AI 生成的视频经常这样:5 秒里可能只有 2 秒能用,现在直接在画布里就剪了。
下一个场景,我想做女性打开房门、神情疑惑的那种氛围。有时候思路跟着走,但灵感还是会卡一下。
这时候 LibTV 有个挺独特的功能,在图片节点里打一个斜杠,跟 Claude Code 里用命令一样。弹出来的选项里有九宫格、剧情推演这些,内置了不少辅助工具。
我直接拉了一个图片节点,让它生成多机位九宫格,甚至可以出25宫格的连贯分镜。有了这些分镜,灵感就可以扩展了。
实际用下来,对工作流的提效是比较明显的。

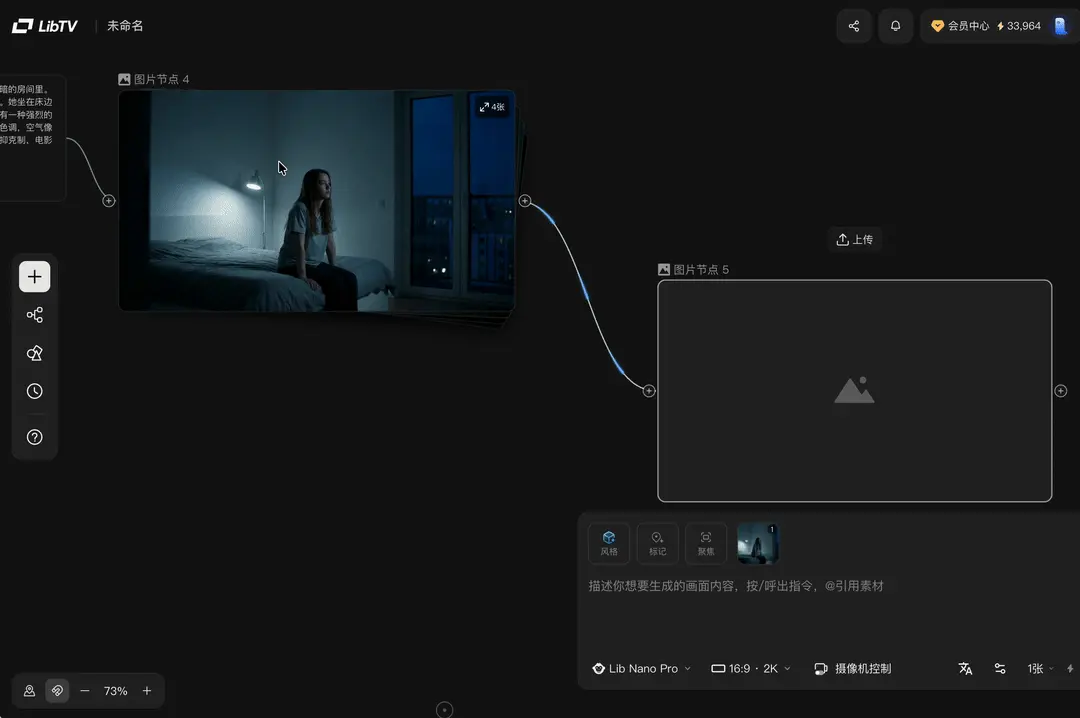
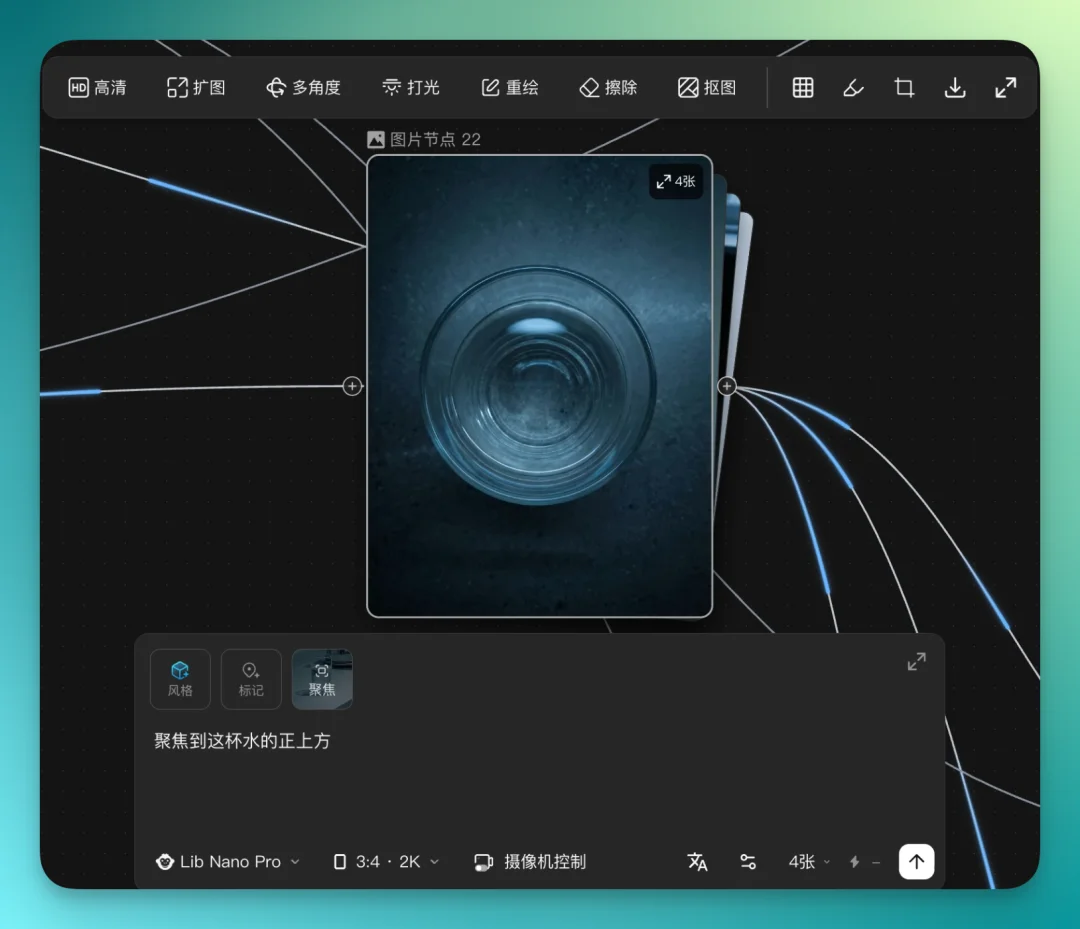
下一个场景切到厨房,她在厨房里喝水。

看着 LibTV 给的九宫格分镜,我有了个思路,用"聚焦"框选厨房里那杯水,让它生成这杯水正上方的视角。
出来的图,背景还是那张桌面,细节是连贯的。
前一个场景是镜头聚焦女性流泪的瞬间,下一个场景直接切到泪水滴落进杯子里。这个转场衔接出来效果挺好的。

泪水滴进杯子的瞬间,我想硬切到一个完全不同的场景:满屏花草绽放,铺满整个画面。
但问题来了。这种风格跳跃太大,直接用 Kling O3 接着生成,很难控制出来的结果。所以这里换个思路:在画布上单独拉出一条新的工作流,两条线分开跑。
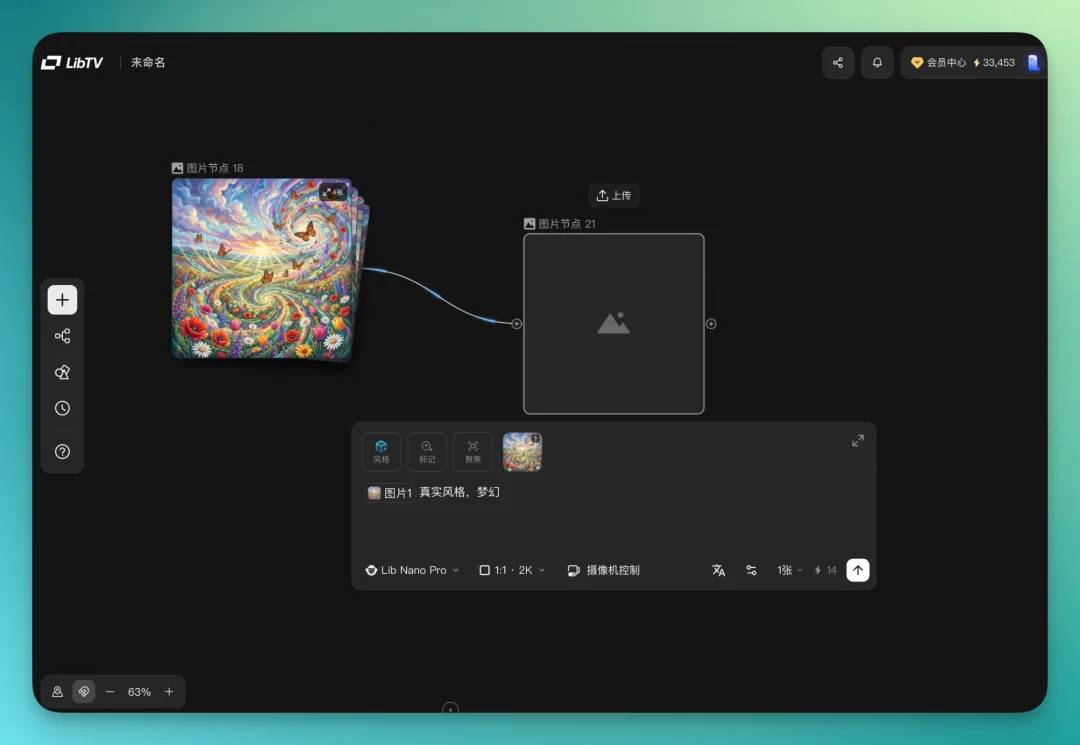
生成图片的时候,节点里有个风格模块。里面集成了社区里大量用户创作者上传的风格预设,直接选就行。
我这里挑了一个「中式美学国风颜彩鎏金」的风格套上去。
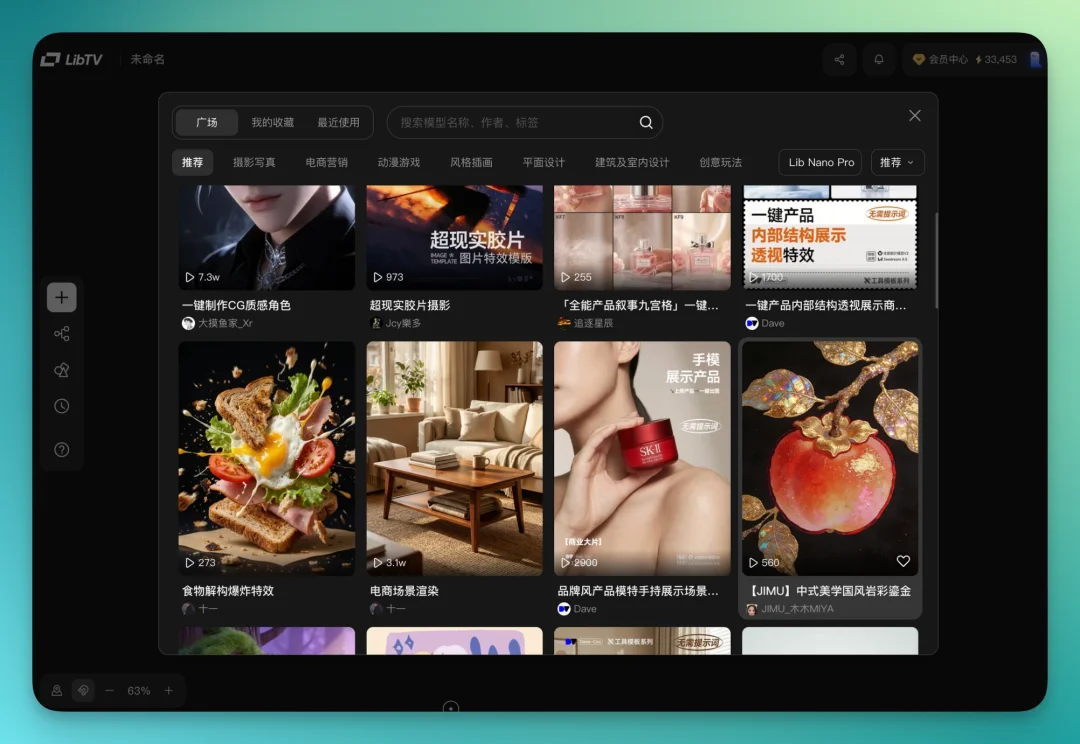
然后就可以批量生成了。每个图片节点都可以基于前一个节点微调,一张一张往下推。我这条线大概生成了四五十张,最后挑出一张满意的,再让它做出花片炸开的效果。

这个转场是整条片子里我最喜欢的一段。女性难受流泪,喝水时泪水滴进杯子,硬切花片炸开,再硬切回现实,她开始疑惑。节奏很跳,转折感很强。
接着往下做。LibTV 还有个画面推演功能,直接根据当前图片,推演 3 秒后的画面会是什么样,帮你把连贯分镜想出来,从里面找灵感,这个功能我挺喜欢用的。
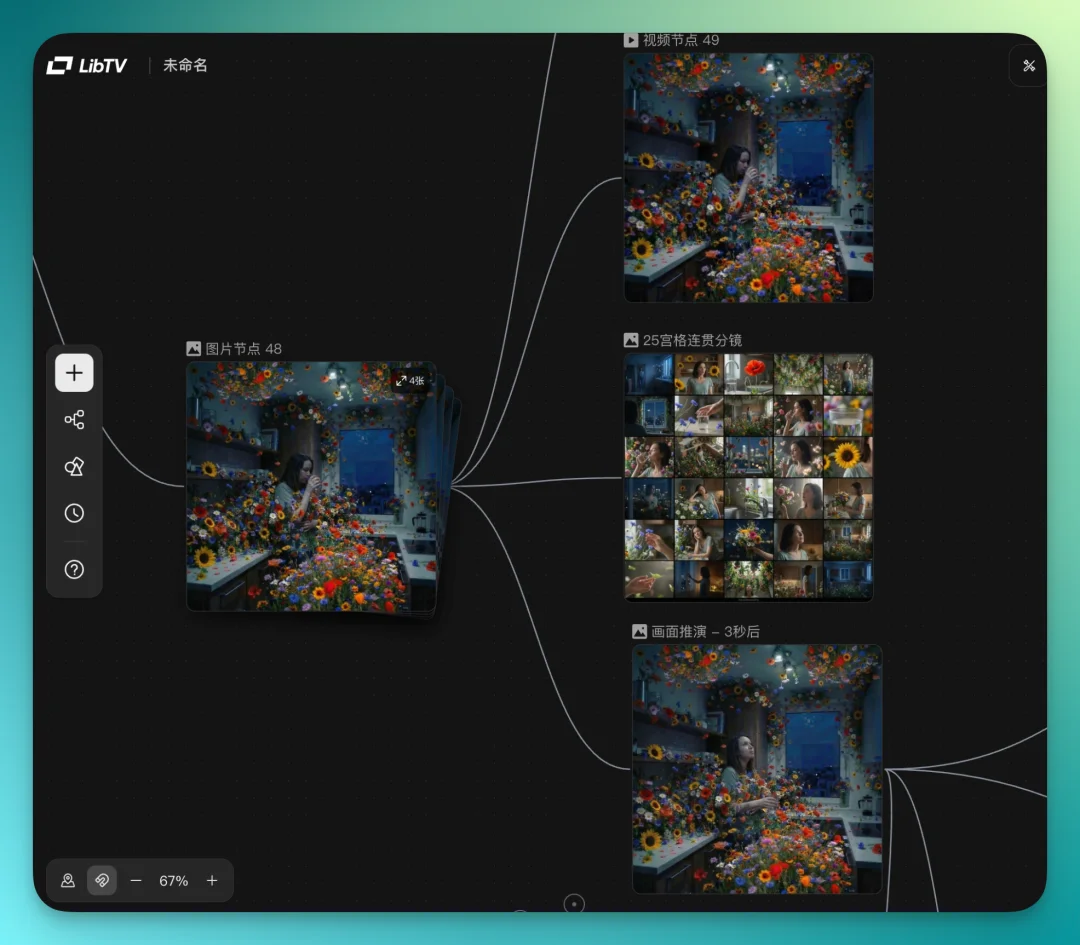
女主角心情开始变好,画面里全是花草。这时候我想到,可以用聚焦框到窗外,然后让窗外飞过一个热气球经过十字路口。

这时候上传 Koji 的图片,用 LibTV 内置的截图功能,直接截取生成图里左下角那束花,然后让 Koji 捧着这束花站在热气球上面。
它会批量出一组图,哪张顺眼就选哪张,一步步微调就行。
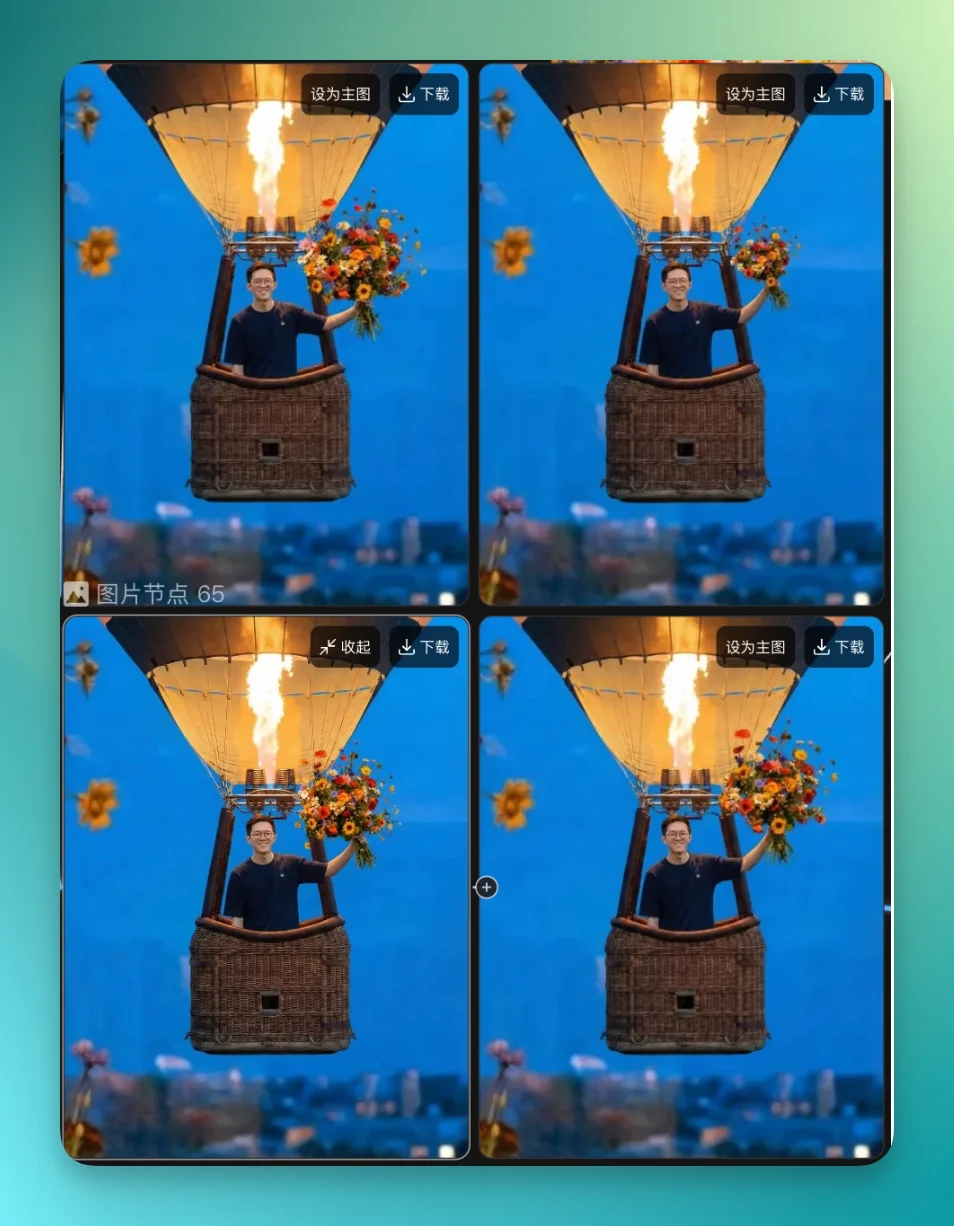
最终效果是这样的:
女性独自坐在阴暗的房间里哭泣。她起身去厨房喝水,镜头跟着她走。喝水时,一滴泪落进杯子,硬切,满屏花片炸开。她猛地回过神,一脸疑惑。疑惑的下一秒,又像做梦一样,厨房里花朵再次炸开。
她转头看向窗外,一个热气球飘过十字路口,上面站着个男生,捧着花,意思就是:be happy。

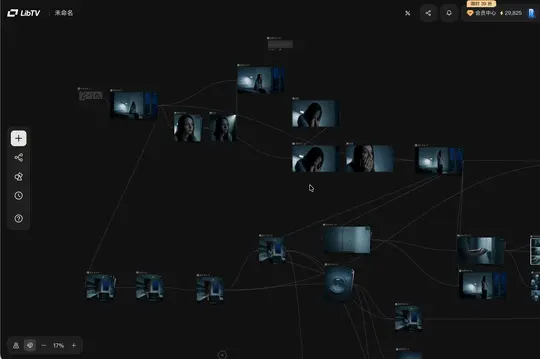
下面这张动图就是我这次完整的工作流。
看起来很像一张思维导图,但 LibTV 的无限画布承载的是真实的创作逻辑。灵感走到哪,画布就跟到哪。没思路的时候,用它的内置功能一键延展,选一个方向,直接生成下一个节点。
所有节点都是用 AI 能力串起来的,整体跑下来确实很顺,省了不少时间。
前面聊的是 LibTV 作为创作工具怎么用。但真正让我觉得值得多说的,是它的另一面。
LibTV 给 Agent 留了个入口。目前已经开放了几个 Skill,比如短漫剧生成 Skill,你在聊天窗口里给 Agent 一句话,它自己跑完剧本、角色设计、分镜、视频生成、剪辑,最后交出一个完整短剧。
如果你用过小龙虾这类 Personal Agent,这些 Skill 可以直接被调用。发一条消息,Agent 就在 LibTV 后台跑流程,你甚至不用打开 LibTV 的网页。
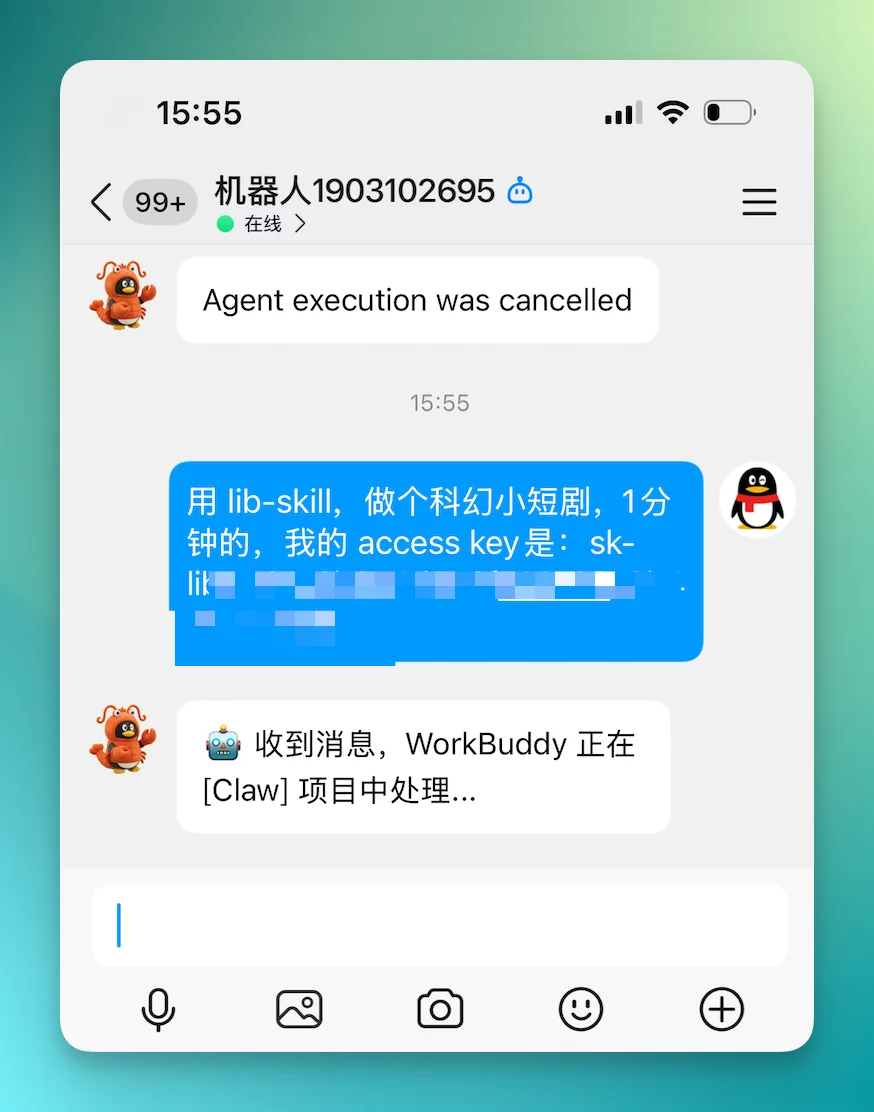
我这里用的是腾讯的 WorkBuddy Claw 配上 QQ。现在各家魔改版的 Claw 能力基本差不多,都能遥控本地操作。
我直接在 QQ 里发一条消息,让它帮我做一个科幻小短剧,把 key 给它就行了。
做个 25 秒科幻动漫短剧
WorkBuddy Claw 会不断去访问 LibTV 的接口,每 60 秒查一次进度,每次有新进展都会推给我。整个过程不用盯着,等通知就行。
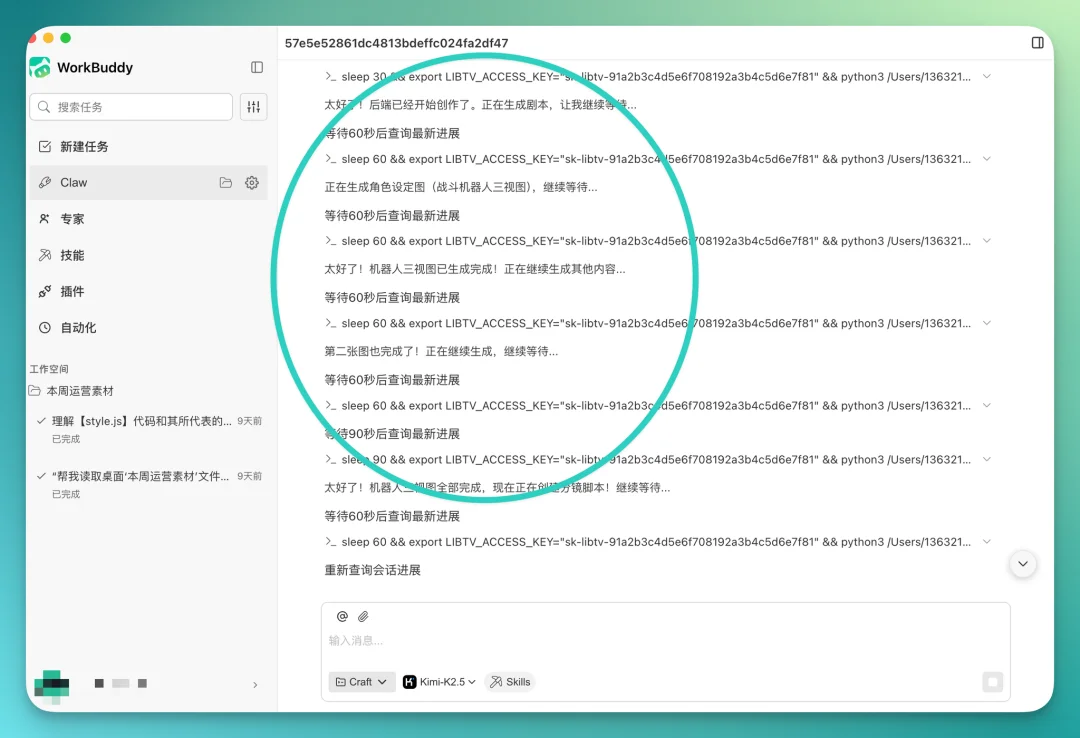
与此同时,LibTV 官网的最近项目里会多出一个 OpenAPI 默认项目。你可以直接在里面实时看着它一步步自己搭工作流,整个过程全透明。
它会先写剧本,然后给每个角色设计正面、侧面,自动生成脚本,再根据脚本逐帧做出分镜。

角色设计这块,它会自己生成正面和侧面两张设计图,还会出两种不同风格。

下面是它做出来的视频。
说实话,我就给了一句话,没有任何额外的提示词限定,这只是第一版试验品。仔细看的话瑕疵不少,剧本也还需要自己微调一下。
但考虑到全自动、0 提示词,第一版跑出来的流畅度和完整性,已经还可以了。

后来我自己在 LibTV 里做了一个脚本和视图,它给出了一批分镜。效果还行,但不完全是我想要的。
不过这本身也是 LibTV 的一个用法,就算结果不满意,脚本和分镜也能给你提供一些灵感方向。

实测下来,还是要给 LibTV 说得稍微详细一点,明确你想做什么内容,效果会好很多。
于是我根据脚本给的灵感,翻了最近大家在回温的胡金铨导演的侠女,让它参考这种风格,做一个25 秒的短片。
提示词如下:
用 LibTV-Skill 做一个 25 秒的视频,武侠电影风,参考胡金铨导演的侠女电影风格,图片在我本地「LibTV」文件夹里,请作为参考然后请你把这个任务的工作流完整创建到画布上
我在本地的 LibTV 文件夹里放了一张侠女的截图,作为参考图给它用。

LibTV 同样会在后台实时搭工作流。这回因为提示词稍微详细了一点,整体风格把握明显更准。分镜的人物一致性、镜头连贯性都比上一版好不少。
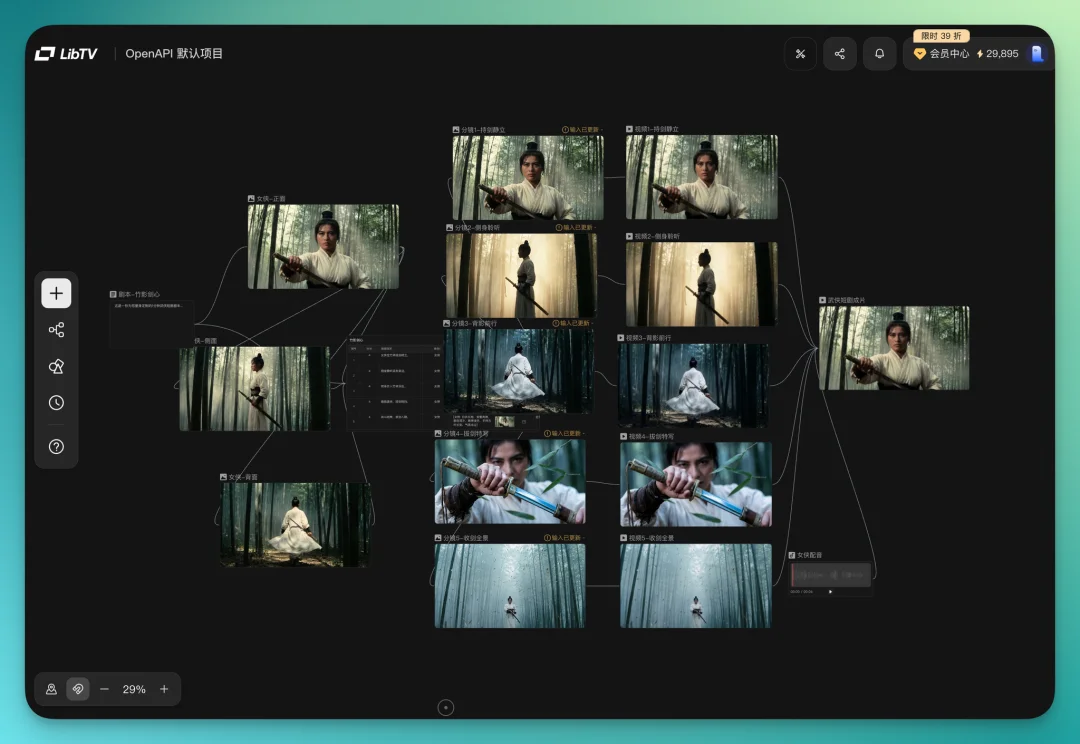
最终视频风格一致性很高,很多场景都有胡金铨那种上世纪的氛围感。细节也到位,拔剑的动作、镜头角度的切换,都挺有感觉的。
而这些,也只是一句话提示词做出来的。

最后再来说下价格,这个很实际。
视频创作里有个说法叫「抽卡」,因为 AI 生成的画面质量有波动,你经常需要跑很多次才能抽到满意的结果。
LibTV 在定价上做了一些优化,现在年卡最低到 39 折,部分模型还有额外的 6 折优惠叠加,会员价格比主流竞品低了差不多 70%,模型积分的定价也很低。
而且现在订阅用户还会获赠最高 300 条免费的顶级视频生成额度。
整体看下来,LibTV 给出了一种可能的回答:把模型能力、创作工具和工作流管理装进同一块画布,让创作者在一个地方完成所有事。
同时,给 Agent 留一扇同样宽的门,让 AI 也能调用同样的创作能力。
当创作者在画布上反复调整、最终选定一套自己满意的创作流程时,这套流程可以被打包成工作流模板,甚至在未来变成 Skill。
这意味着一个创作者的审美判断和创作经验,有可能流进其他 Agent 的工具箱里,被更多人调用。
当然,LibTV 目前还处在比较早期的阶段,很多能力还在开发中。它能不能真正跑通这套逻辑,还需要时间来验证。
LibTV 直达:https://www.liblib.tv/
LibTV Skill 开源地址:https://github.com/libtv-labs/libtv-skills

文章来自于“十字路口Crossing”,作者 “镜山”。



【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
