# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
这是一篇关于 LPU 的简单科普。
在如今的人工智能领域,「GPU is All You Need」已经逐渐成为共识。没有充足的 GPU,连 OpenAI 都不能轻易升级 ChatGPT。
不过最近,GPU 的地位也在经受挑战:一家名为 Groq 的初创公司开发出了一种新的 AI 处理器 ——LPU(Language Processing Unit),其推理速度相较于英伟达 GPU 提高了 10 倍,成本却降低到十分之一。
在一项展示中,LPU 以每秒超过 100 个词组的惊人速度执行了开源的大型语言模型 —— 拥有 700 亿个参数的 Llama-2。下图展示了它的速度,可以看到,人眼的阅读速度根本跟不上 LPU 上模型的生成速度:

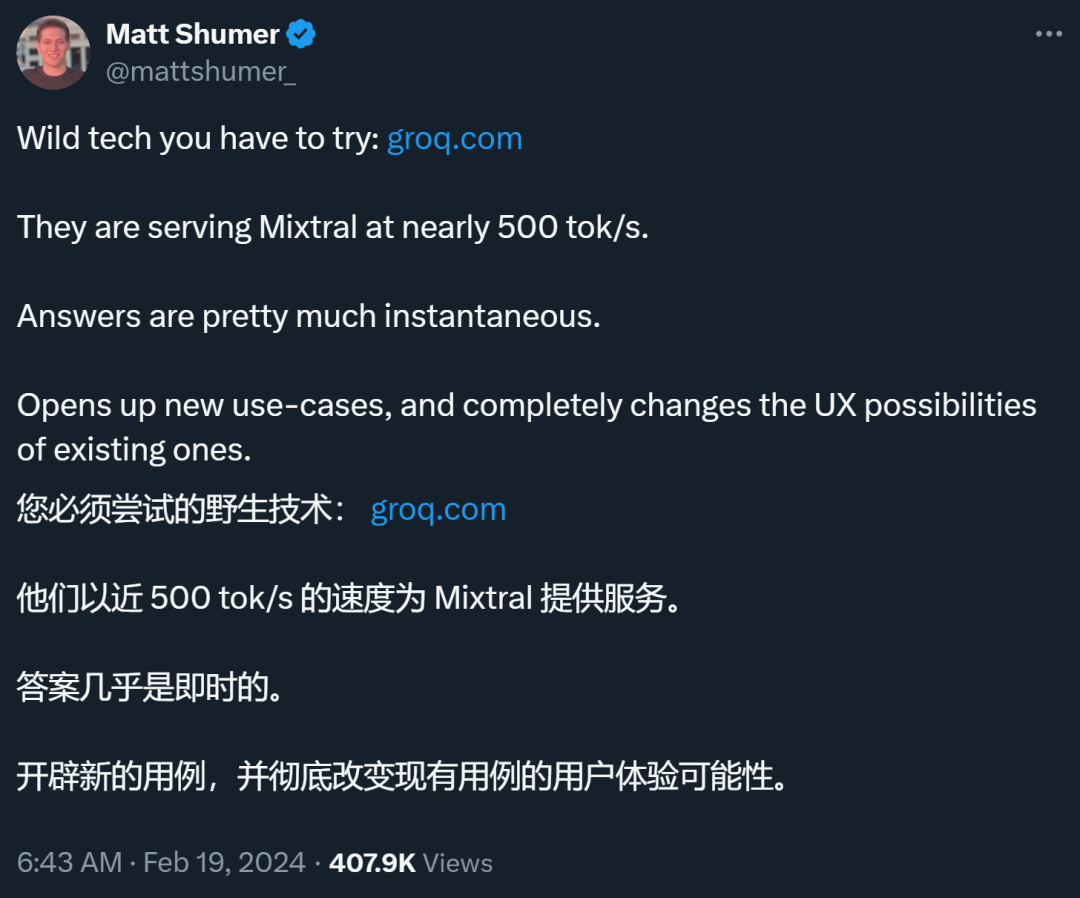
此外,它还在 Mixtral 中展示了自己的实力,实现了每个用户每秒近 500 个 token。
这一突破凸显了计算模式的潜在转变,即在处理基于语言的任务时,LPU 可以提供一种专业化、更高效的替代方案,挑战传统上占主导地位的 GPU。
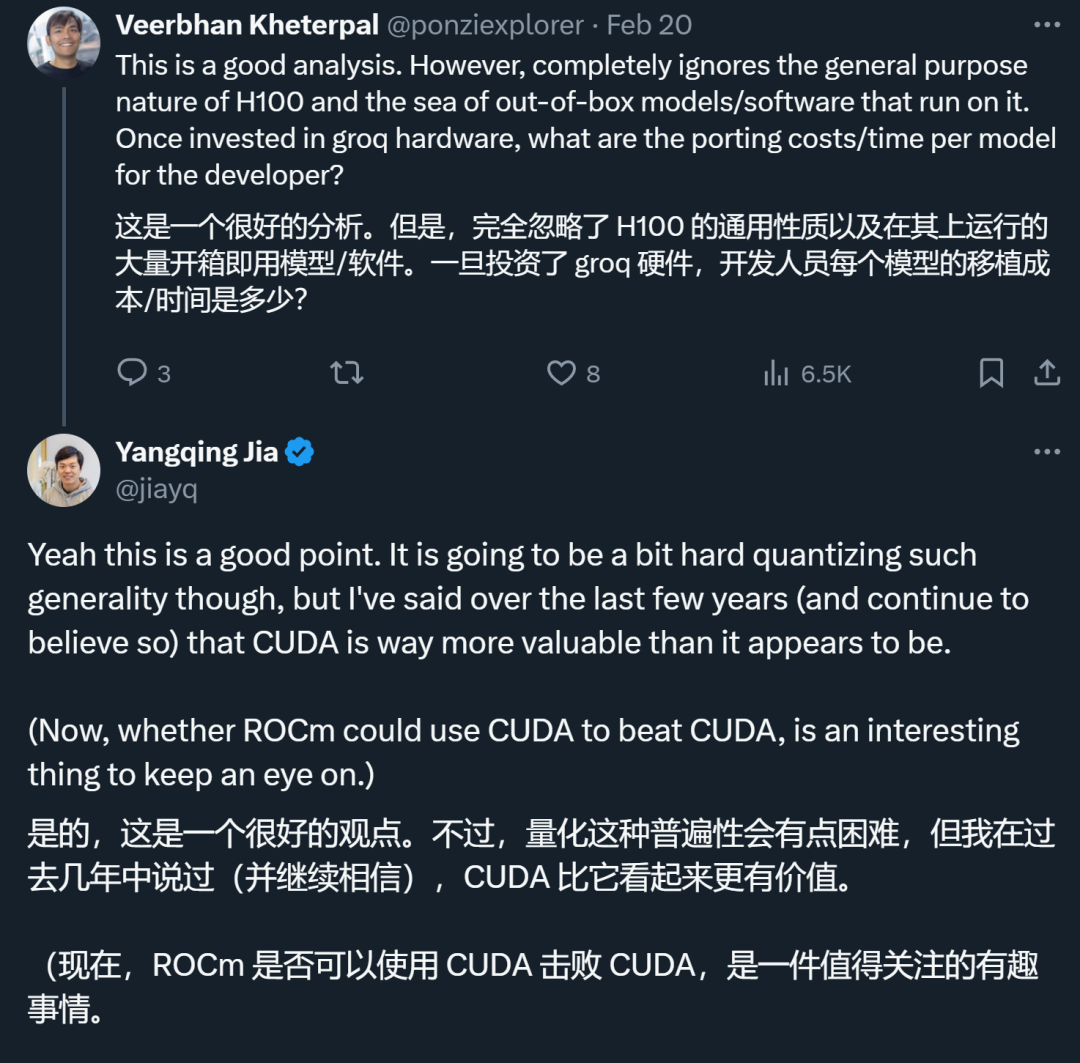
不过,原阿里技术副总裁、Lepton AI 创始人贾扬清发文分析称,Groq 的实际部署成本可能远高于预期。因为 Groq 的内存容量较小,运行同一模型(LLaMA 70B)最少需要 305 张 Groq 卡(实际需要 572 张),而使用英伟达的 H100 只需 8 张卡。从目前的价格来看,Groq 的硬件成本是 H100 的 40 倍,能耗成本是 10 倍。如果运行三年的话,Groq 的硬件采购成本是 1144 万美元,运营成本是 76.2 万美元或更高。8 卡 H100 的硬件采购成本是 30 万美元,运营成本是 7.2 万美元或略低。因此,虽然 Groq 的性能出色,但成本和能耗方面仍有待改进。

此外,Groq 的 LPU 不够通用也是一大弱点,这使得它短期内很难撼动英伟达 GPU 的地位。
下文将介绍与 LPU 有关的一系列知识。
究竟什么是 LPU?它的运作机制是怎样的?Groq 这家公司是什么来头?
根据 Groq 官网介绍,LPU 是「language processing units(语言处理单元)」的缩写。它是「一种新型端到端处理单元系统,可为人工智能语言应用等具有序列成分的计算密集型应用提供最快的推理」。

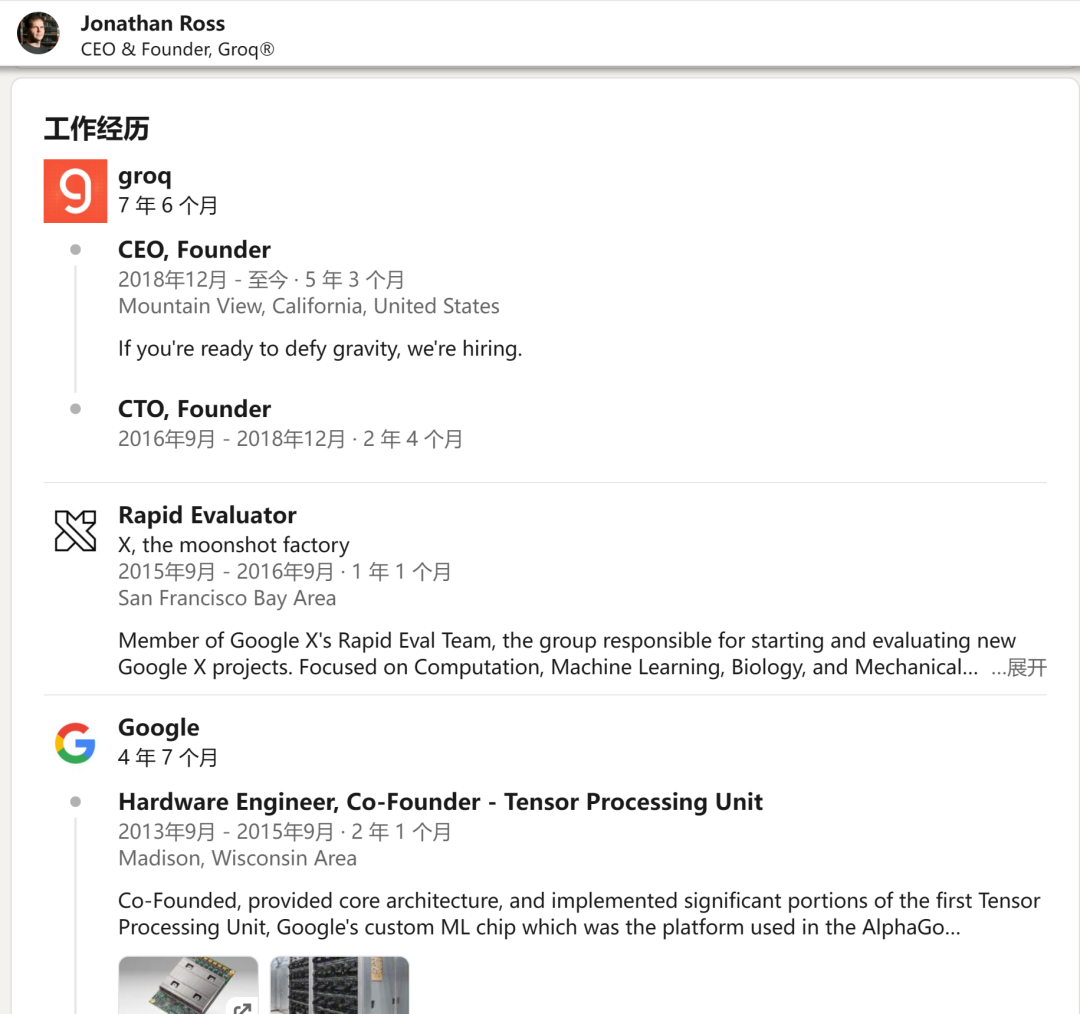
还记得 2016 年 AlphaGo 击败世界冠军李世石的那场历史性围棋比赛吗?有趣的是,在他们对决的一个月前,AlphaGo 输掉了一场练习赛。在此之后,DeepMind 团队将 AlphaGo 转移到 TPU 上,大大提高了它的性能,从而以较大优势取得了胜利。
这一刻显示了处理能力在充分释放复杂计算潜能方面的关键作用。这激励了最初在谷歌领导 TPU 项目的 Jonathan Ross,他于 2016 年成立了 Groq 公司,并由此开发出了 LPU。LPU 经过独特设计,可迅速处理基于语言的操作。与同时处理多项任务(并行处理)的传统芯片不同,LPU 是按顺序处理任务(序列处理),因此在语言理解和生成方面非常有效。
打个比方,在接力赛中,每个参赛者(芯片)都将接力棒(数据)交给下一个人,从而大大加快了比赛进程。LPU 的具体目标是解决大型语言模型 (LLM) 在计算密度和内存带宽方面的双重挑战。
Groq 从一开始就采取了创新战略,将软件和编译器的创新放在硬件开发之前。这种方法确保了编程能够引导芯片间的通信,促进它们协调高效地运行,就像生产线上运转良好的机器一样。
因此,LPU 在快速高效地管理语言任务方面表现出色,非常适合需要文本解释或生成的应用。这一突破使系统不仅在速度上超越了传统配置,而且在成本效益和降低能耗方面也更胜一筹。这种进步对金融、政府和技术等行业具有重要意义,因为在这些行业中,快速和精确的数据处理至关重要。
如果想要深入了解 LPU 的架构,可以去读 Groq 发表的两篇论文。
第一篇是 2020 年的《Think Fast: A Tensor Streaming Processor (TSP) for Accelerating Deep Learning Workloads》。在这篇论文中,Groq 介绍了一种名为 TSP 的架构,这是一种功能分片微架构,其内存单元与向量和矩阵深度学习功能单元交错排列,以利用深度学习运算的数据流局部性。

论文链接:https://wow.groq.com/wp-content/uploads/2020/06/ISCA-TSP.pdf
第二篇是 2022 年的《A Software-defined Tensor Streaming Multiprocessor for Large-scale Machine Learning》。在这篇论文中,Groq 介绍了用于 TSP 元件大规模互连网络的新型商用软件定义方法。系统架构包括 TSP 互连网络的打包、路由和流量控制。

论文链接:https://wow.groq.com/wp-content/uploads/2024/02/GroqISCAPaper2022_ASoftwareDefinedTensorStreamingMultiprocessorForLargeScaleMachineLearning.pdf
在 Groq 的词典中,「LPU」似乎是一个较新的术语,因为在这两篇论文中都没有出现。
不过,现在还不是抛弃 GPU 的时候。因为尽管 LPU 擅长推理任务,能毫不费力地将训练好的模型应用到新数据中,但 GPU 在模型训练阶段仍占据主导地位。LPU 和 GPU 之间的协同作用可在人工智能硬件领域形成强大的合作伙伴关系,二者都能在其特定领域发挥专长和领先地位。
让我们比较一下 LPU 和 GPU,以便更清楚地了解它们各自的优势和局限性。
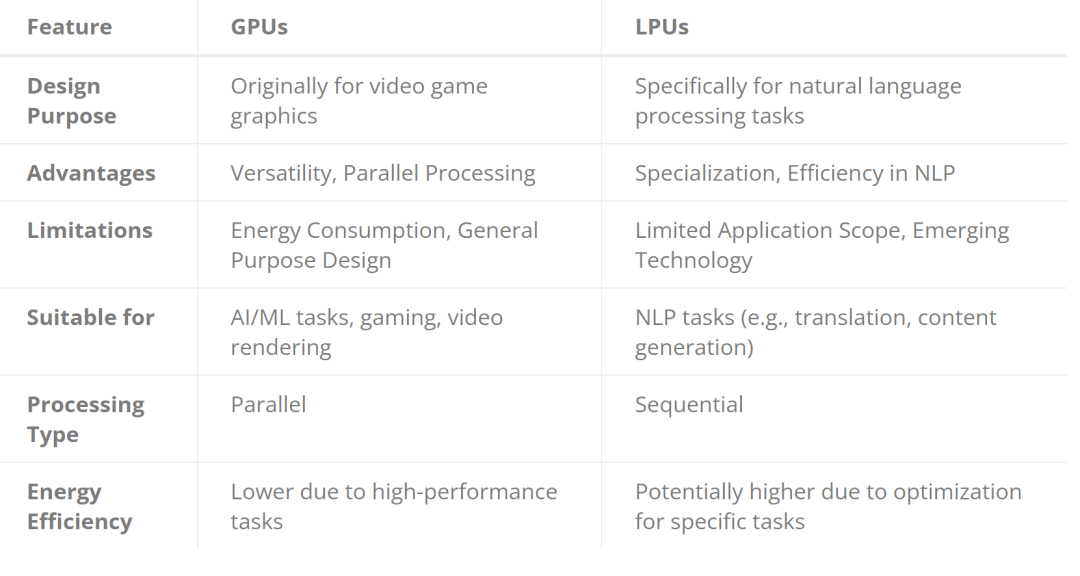
用途广泛的 GPU
图形处理单元(GPU)已经超越了其最初用于渲染视频游戏图形的设计目的,成为人工智能和机器学习工作的关键要素。它们的架构是并行处理能力的灯塔,可同时执行数千个任务。
这一特性对那些需要并行化的算法尤为有利,可有效加速从复杂模拟到深度学习模型训练的各种任务。
GPU 的多功能性是另一个值得称道的特点;它能熟练处理各种任务,不仅限于人工智能,还包括游戏和视频渲染。它的并行处理能力大大加快了 ML 模型的训练和推理阶段,显示出显著的速度优势。
然而,GPU 并非没有局限性。它的高性能是以大量能耗为代价的,这给能效带来了挑战。此外,GPU 的通用设计虽然灵活,但并不总能为特定的人工智能任务提供最高效率,这也暗示了其在专业应用中潜在的低效问题。
擅长语言处理的 LPU
语言处理单元(LPU)代表了 AI 处理器技术的最前沿,其设计理念深深植根于自然语言处理(NLP)任务。与 GPU 不同,LPU 针对序列处理进行了优化,这是准确理解和生成人类语言的必要条件。这种专业化赋予了 LPU 在 NLP 应用中的卓越性能,使其在翻译和内容生成等任务中超越了通用处理器。LPU 处理语言模型的效率非常突出,有可能减少 NLP 任务的时间和能源消耗。
然而,LPU 的专业化是一把双刃剑。虽然它们在语言处理方面表现出色,但其应用范围较窄。这限制了它们在更广泛的 AI 任务范围内的通用性。此外,作为新兴技术,LPU 还没有得到社区的广泛支持,可用性也面临挑战。不过,随着时间的推移和该技术逐步被采用,这些差距可能在未来得到弥补。
围绕 LPU 与 GPU 的争论越来越多。去年年底,Groq 公司的公关团队称其为人工智能发展的关键参与者,这引起了人们的兴趣。
今年,人们重新燃起了兴趣,希望了解这家公司是否代表了人工智能炒作周期中的又一个转瞬即逝的时刻 —— 宣传似乎推动了认知度的提高,但它的 LPU 是否真正标志着人工智能推理迈出了革命性的一步?人们还对该公司相对较小的团队的经验提出了疑问,尤其是在科技硬件领域获得巨大认可之后。
一个关键时刻到来了,社交媒体上的一篇帖子大大提高了人们对该公司的兴趣,在短短一天内就有数千人询问如何使用其技术。公司创始人在一次视频通话中分享了这些细节,强调了热烈的反响以及他们目前由于没有计费系统而免费提供技术的做法。
公司创始人对硅谷的创业生态系统并不陌生。自 2016 年公司成立以来,他一直是公司技术潜力的倡导者。此前,他曾在另一家大型科技公司参与开发一项关键的计算技术,这为他创办这家新企业奠定了基础。这段经历对公司形成独特的硬件开发方法至关重要,公司从一开始就注重用户体验,在进入芯片的物理设计之前,公司最初主要致力于软件工具的开发。
随着业界继续评估此类创新的影响,LPU 重新定义人工智能应用中的计算方法的潜力仍然是一个引人注目的讨论点,预示着人工智能技术将迎来变革性的未来。
原文链接:https://dataconomy.com/2024/02/26/groq-sparks-lpu-vs-gpu-face-off/?utm_content=283765034&utm_medium=social&utm_source=twitter&hss_channel=tw-842860575289819136
文章来自于微信公众号 “机器之心”



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
