# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
长上下文推理已经成了VLM/LLM的默认形态。
但真正的“隐形天花板”往往出现在推理端的KV缓存里。
上下文一拉长,KV缓存线性膨胀,显存占用与带宽开销一起飙升,吞吐自然被压下去。

于是,KV缓存压缩成了绕不开的工程选项。然而,压缩确实省显存,却常常带来“越压越不稳”的翻车风险。来自上海交通大学EPIC Lab的研究团队指出,这背后是压缩准则的根本问题:
很多方法几乎只优化“重要性(importance)”,却忽略了多模态KV中天生更强的“语义冗余(redundancy)”。当一批高度相似的KV反复被保留下来,它们不会线性叠加信息量,反而挤占预算、压缩语义覆盖面,让模型在冗余里越选越窄,稳定性自然难以保证。
为了解决这一问题,团队提出MixKV:把“重要性”和“多样性(diversity)”联合起来,并在注意力头(head)维度自适应混合两者权重,让上下文压缩在质量与效率之间不再二选一。论文已中稿ICLR 2026。
研究团队首先从KV的统计特性入手做可视化:他们在同一层、同一注意力头(head)内,取不同token的key/value表示,两两计算余弦相似度,一方面用相似度矩阵直观看“哪些token更像”,另一方面用分布曲线看“整体冗余水平”到底高不高。由此得到两条非常直觉、也非常关键的发现:
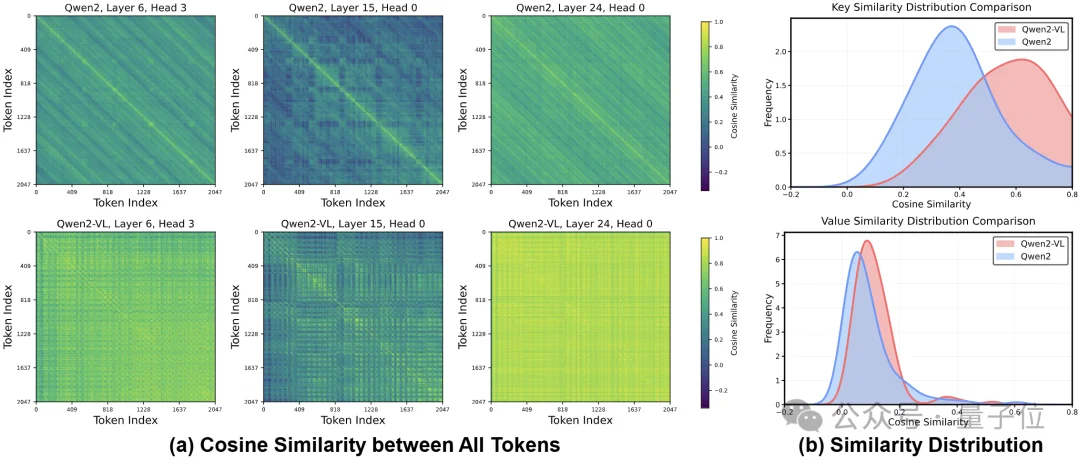
△ 视觉-语言输入下的KV相似度分布整体右移,语义冗余更强
发现1:如图1所示,视觉-语言输入下的相似度分布整体明显右移(更偏向高相似度区间)。这意味着在多模态输入中,KV缓存里语义相近/重复的内容更多—也就是冗余更强。换句话说,多模态KV缓存的“可压缩空间”更大,但同时也更容易出现“保留了一堆看似重要、实则重复”的情况。
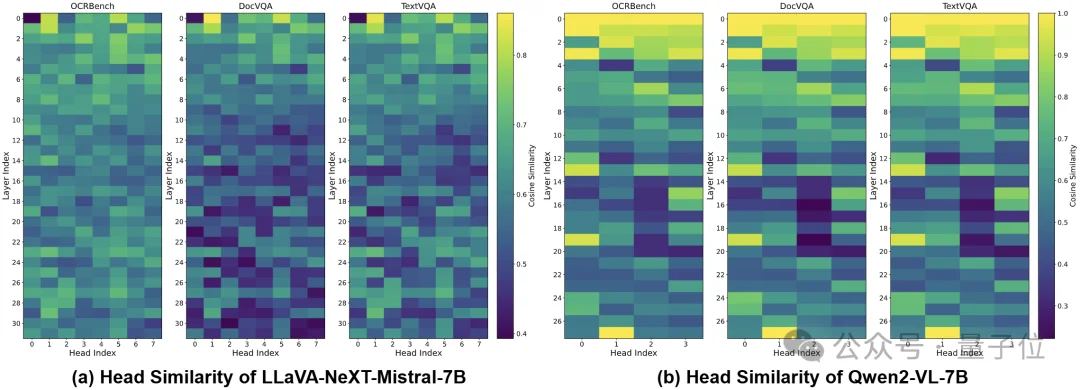
△ head级冗余热力图显示差异显著:有的head更偏“局部重复”,有的head更偏“全局信息”
发现2:如图2所示,同一模型内部不同head的冗余水平差异巨大:有的head长期处于高相似度(更冗余),有的head相似度显著更低(更分散)。这说明冗余并不是均匀分布在所有head上的,而是存在明显的“分工”—有些head更偏向捕捉局部、重复模式(因此冗余更高),而另一些head更像在承载更全局、更稀疏的信息(因此冗余更低)。
综上,团队进一步对比了纯文本与视觉-语言两类输入下的head冗余模式,发现它们的整体形态高度一致:在文本上相对更冗余的head,往往在视觉-语言输入中也依然更冗余。
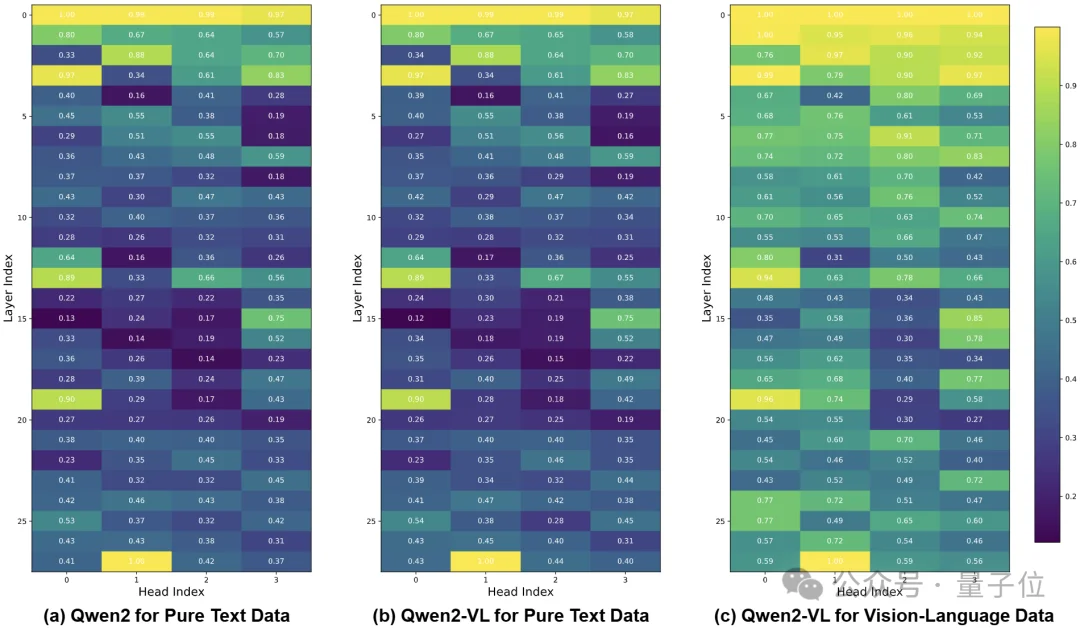
△ 纯文本与视觉-语言输入下的冗余模式高度一致:文本上更冗余的head,在视觉-语言输入中往往也更冗余(示意)
最终,论文将这一现象概括为KV Cache的“异构头部冗余性差异”(heterogeneous head-wise redundancy):冗余具有稳定的head级异构结构——这也直接解释了为什么“对所有head一刀切、再只按重要性筛选”的压缩策略更容易不稳:在高冗余head里重复保留近邻信息,会让预算被重复内容吃掉,语义覆盖面被削薄,从而触发质量波动甚至翻车。
基于上述发现,MixKV的目标很明确:在不改变原有Top-K选取主流程的前提下,升级“打分器”,让保留下来的KV同时具备“重要性”和“多样性”,从而减少“重要但重复”带来的覆盖面塌陷。
MixKV的核心由“三件事”组成,可以概括为“两步打分+一个自适应混合”:
重要性打分(Importance):融合窗口内注意力信号(外在重要性)与KV本身强度信号(内在重要性,默认用VNorm)。
多样性打分(Diversity):鼓励挑选更“互不相似”的KV,避免在高冗余head里重复选择语义近邻,扩大语义覆盖。
Head-wise Mixing:在线估计每个head的冗余度;冗余越高越强调多样性,冗余越低越强调重要性,实现细粒度联合优化。

△ MixKV:重要性+多样性联合打分,并按head冗余自适应混合
只按重要性压缩时,一个常见风险是:保留下来的KV会在表示空间里“扎堆”到少数相似区域——看似保关键点,实际上覆盖面变窄。MixKV加入多样性并进行head级混合后,保留KV更接近Full KV的整体分布,能够覆盖到更多原本会被遗漏的信息区域,从而让压缩在更紧的预算下也更稳。
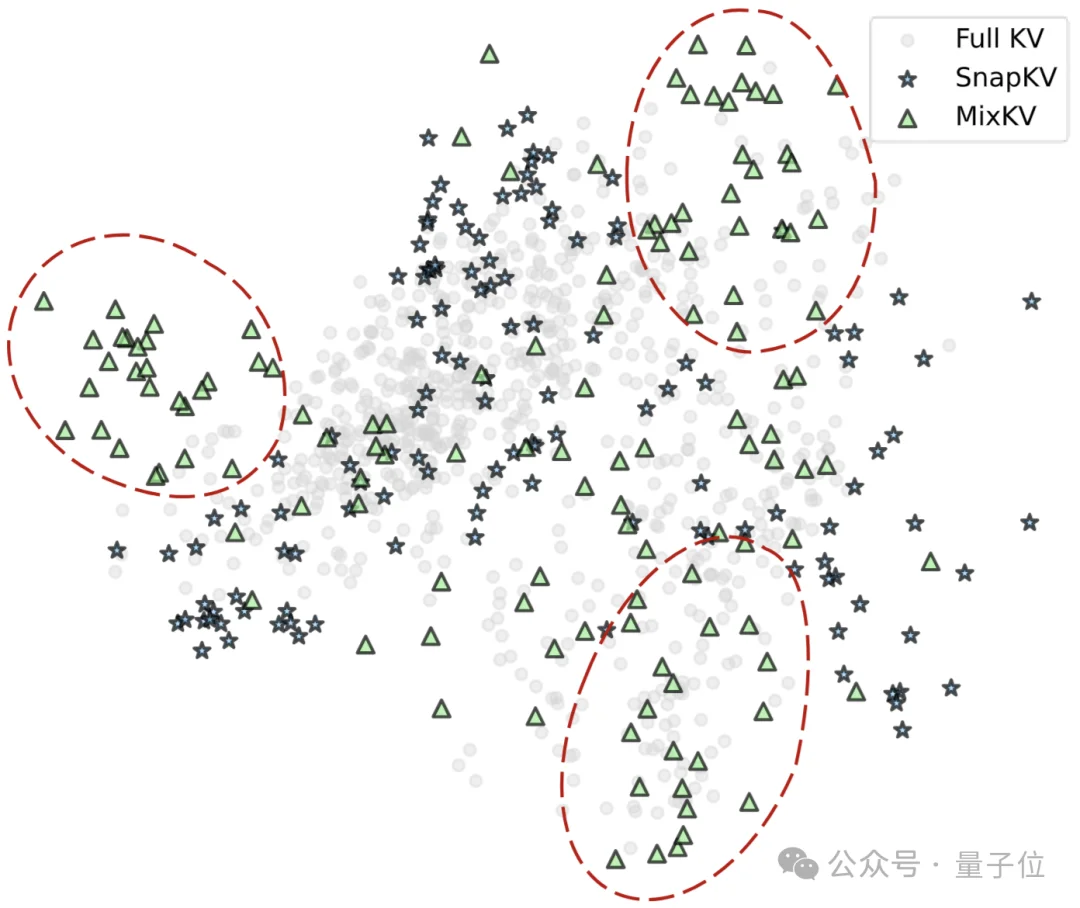
△ 表示空间可视化:加入MixKV后,保留KV分布更接近Full KV,覆盖更完整(示意)
如表1所示,MixKV在多个图像理解基准与多种设置下带来一致增益。
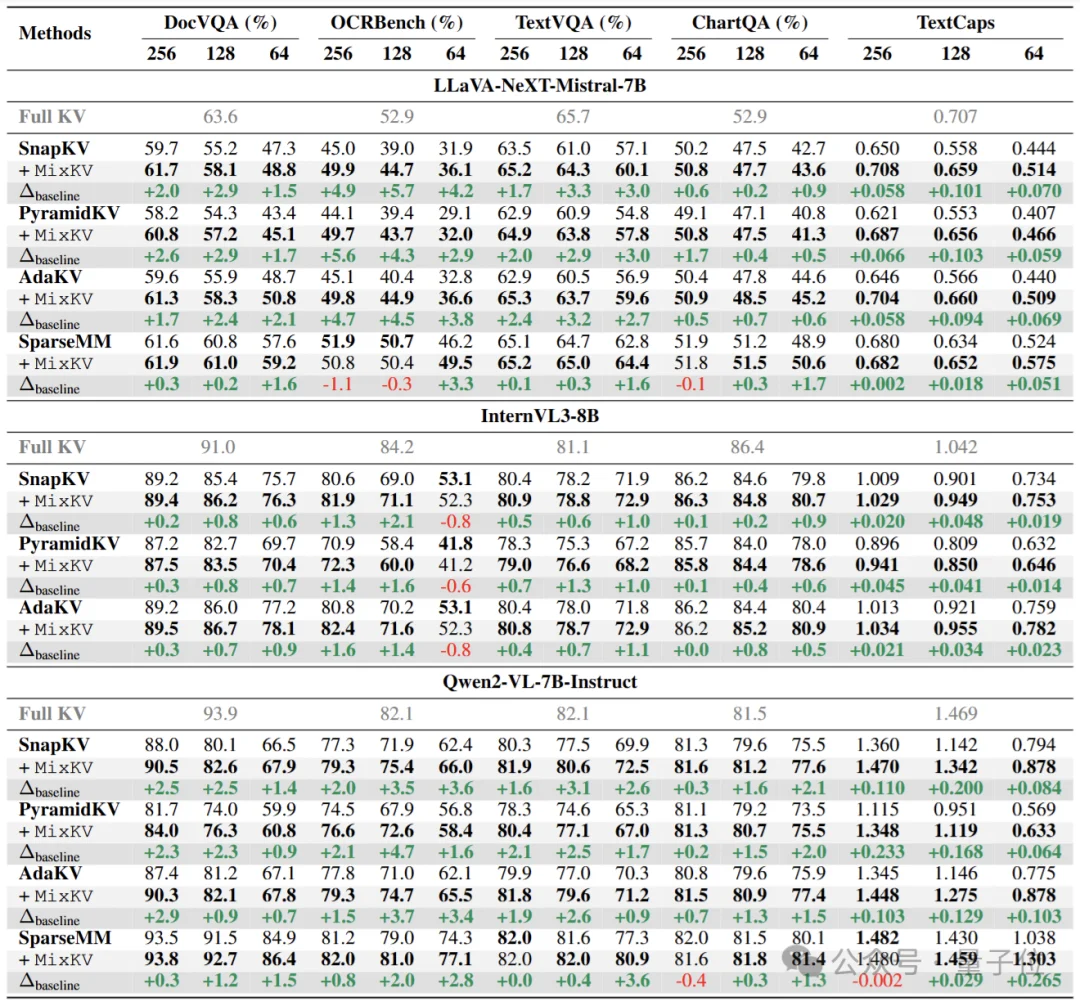
△ 表1. 多图像理解基准:多任务一致提升
如表2所示,在纯文本长上下文任务上,MixKV同样带来一致增益,说明该方法不仅对VLM有效,对LLM长文本推理也同样适用。
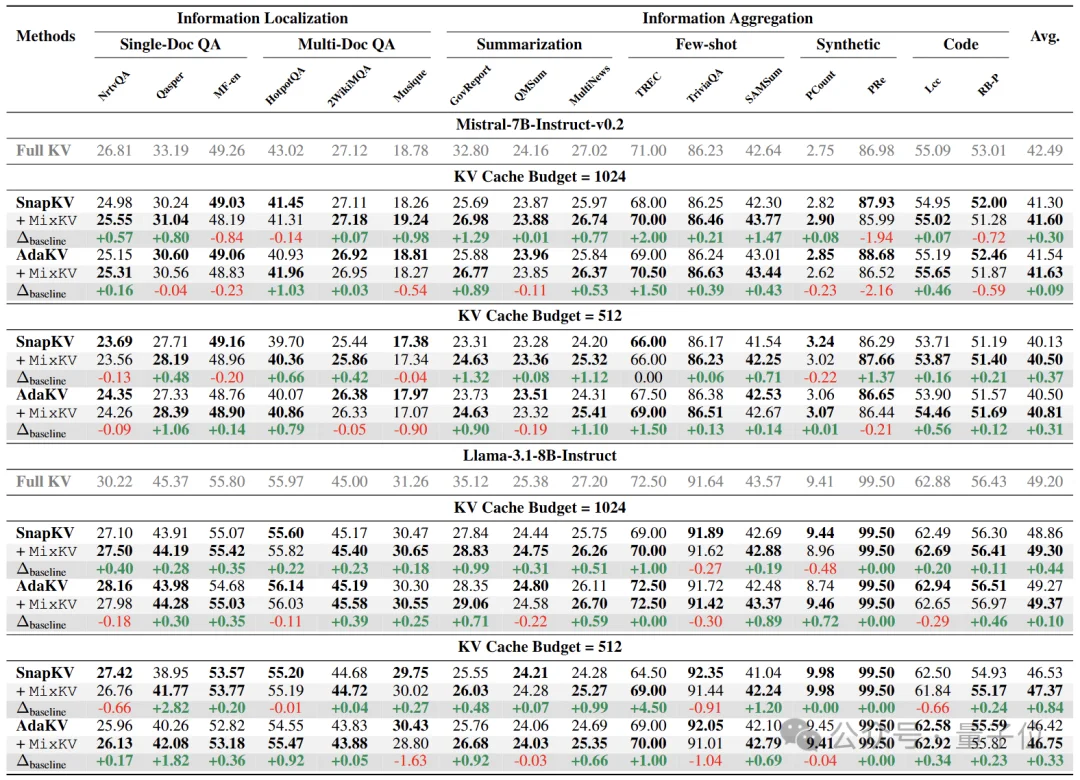
△ 表2. 更多对照:额外设置下的一致增益
如表3所示,在更大尺寸的InternVL3-38B模型上,MixKV同样能带来稳定提升,体现出良好的可扩展性。
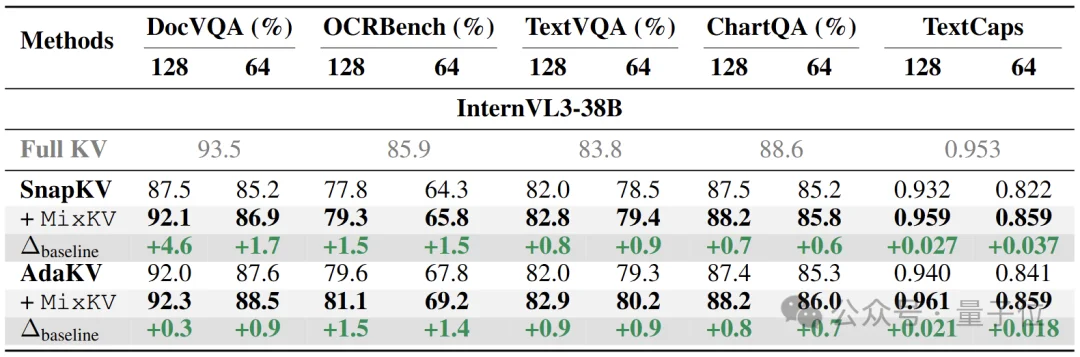
△ 表3. 更大规模VLM上的结果:稳定提升
如表4所示,在MoE架构的Qwen3-VL-30B-A3B-Instruct上,MixKV同样有效,进一步验证其通用性。
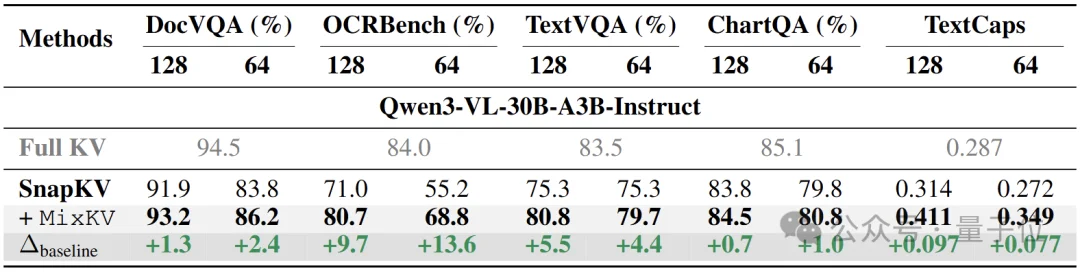
△ 表4. MoE架构VLM上的结果:保持一致增益
如表5所示,在GUI定位(ScreenSpot-v2)的多个子场景上均实现提升;其中整体增益直观:在两档预算下分别平均提升7.9和8.0。
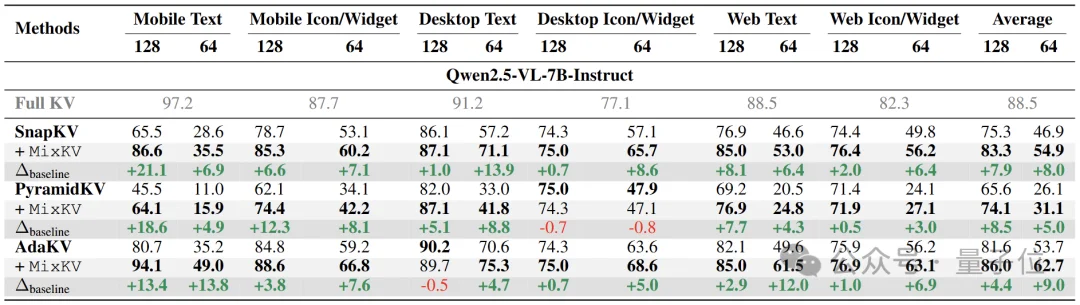
△ 表5. GUI grounding:多子场景提升与Average总体增益
如下图所示,在极致压缩条件下(上下文预算为64),MixKV能显著降低模型推理延迟与峰值显存。
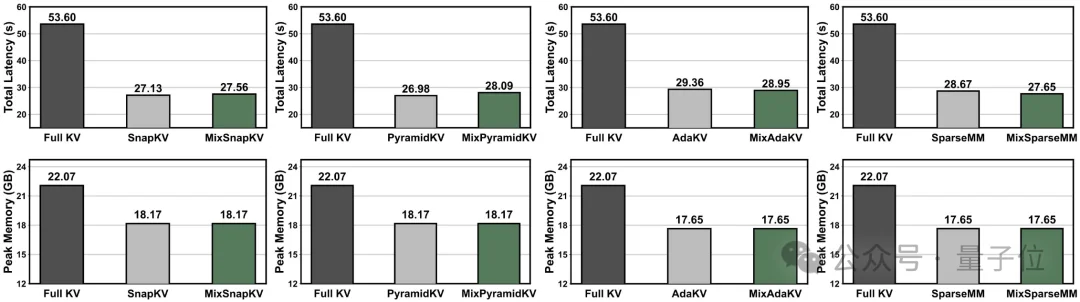
△ 效率对比:总延迟与峰值显存
MixKV为长上下文推理的KV缓存压缩带来了一次“又快又稳”的关键升级。它从现象出发,系统揭示了KV Cache存在稳定的head级异构语义冗余:不同head的冗余程度显著不同,且在纯文本与视觉-语言输入上呈现高度一致的结构性模式。
基于这一洞察,MixKV以“重要性+多样性联合”为核心准则,并通过head-wise自适应混合,在不改变原有压缩流程的前提下,让保留的KV既抓住关键信息、又避免重复堆叠,从而显著提升压缩后的信息覆盖与稳定性。
实验表明,MixKV不仅能在多模态理解、GUI定位、长文本理解等任务上带来一致收益,同时还能带来可观的效率改善(如推理提速与显存下降)。这项研究也进一步说明:面向长上下文部署,KV压缩不能只“挑重要”,更要“保覆盖”——把冗余结构纳入设计范式,是让VLM/LLM真正走向可用、可规模化落地的重要一步。
作者简介:
本文由上海交通大学EPIC Lab、四川大学和华中科技大学联合完成。共同一作为四川大学研究生刘旭洋,华中科技大学本科生桂熙严,通讯作者为上海交通大学人工智能学院助理教授张林峰。
论文链接:
https://arxiv.org/pdf/2510.20707
代码链接:
https://github.com/xuyang-liu16/MixKV
项目主页:
https://xuyang-liu16.github.io/MixKV/
文章来自于"量子位",作者 "MixKV团队"。



