# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
让人工智能变得无处不在。
北京时间 2 月 22 日,半导体巨头 Arm 更新了 Arm® Neoverse™ 产品路线图,宣布推出两款基于全新第三代 Neoverse IP 构建的全新计算子系统(CSS):Arm Neoverse CSS V3 和 Arm Neoverse CSS N3。
Arm Neoverse CSS V3 是首款高性能 V 系列 CSS 产品,与前代产品 CSS N2 相比,单芯片性能提升可达 50%。
Arm Neoverse CSS N3 是 N 系列 CSS 产品的最新拓展,相较于 CSS N2,其每瓦性能提升了 20%。
Arm 高级副总裁兼基础设施事业部总经理 Mohamed Awad 指出:“Arm 构建了全球应用最为普及的 CPU 架构,在多个领域的技术革新中发挥主导作用,尤其在智能手机产业中占据核心地位。随着 AI 渗透到教育、就业、制造、医疗和交通等领域,AI 正在改变经济发展和我们的日常生活,而 Arm 是这一切变革的基石。”
Arm® Neoverse™ 这条产品线是 Arm 专为基础设施应用市场设计,进入 AI 时代之后,其应用范围从最初的应用服务器和数据中心拓展到了网络、安全和存储等诸多领域,在整个基础设施领域发挥着关键作用。
在如今 OpenAI 强势领衔,NVIDIA 叱咤风云的这段 AI 加速增长期,我们可以通过解读此次产品路线图的更新,一览 Arm 这位“老大哥”对计算技术界的未来布局。
在过去,软件和硬件分别由不同的公司负责开发,但如今这种传统模式已无法满足客户对性能的高要求以及应对日趋复杂的软硬件环境。很多企业期望其部署的硬件,包括微架构层面,能针对软件负载进行深度优化。然而,实现这样的深度融合与联合优化需要多方协作,在软硬件研发上耗费大量的时间。
这不仅很花精力,而且能自研硬件的软件厂商在全球范围屈指可数,于是他们不会绕弯子,而是选择直接去找最可靠的合作伙伴:Arm。
所谓可靠,是指 Arm 会通过在 IP 开发阶段便展开深入且全面的支持来确保架构与微架构设计符合实际工作负载需求,并提供从 CPU 到整个平台层面的定制化优化服务:那么,为了深入优化 TCO,就必须着眼于整个平台,而世界上只有 Arm 能够在平台级别上调优内存和 I/O,并添加自定义工作负载加速器。
这是一种非常紧密的合作关系。尤其是在 Arm 推出了 Neoverse CSS 之后,定制芯片变得更迅速,且更易实现。微软的 Cobalt 100 CPU 就是一个经典的合作案例。从头部云服务提供商到初创公司,Neoverse CSS 被广泛应用来推动更高的创新发展。
不难想象,这构成了一个极其强大的生态系统。
去年十月,Arm 在Neoverse CSS 的基础上,进一步推出了 Arm 全面设计 (Arm Total Design) 生态项目,集结了半导体产业中的芯片设计伙伴、IP 供应商、EDA 工具提供商、代工厂和固件开发商等各方力量,围绕 Arm 计算子系统(CSS)开展协同创新和系统开发工作。
通过路线图的协同和技术整合,Arm 还设立了专业技术中心来缩短上市时间并降低成本,助力合作伙伴更高效地开发基于 Neoverse CSS 的定制芯片。
在计算机发展的早期,IBM 垄断了大型机市场,拥有自己独特的硬件和软件体系结构。然而,一些公司(Amdahl、Fujitsu 和 Hitachi)决定挑战 IBM,试图制造与其大型机兼容的计算机。最终 IBM 通过保持技术领先和市场份额,还是成功抵御了这些竞争者的挑战。这就是所谓的“大型机克隆战争”。
在这个 AI 时代,比起掀起新一轮的硬件战争,Arm 选择带头团结这些力量,立志使人工智能变得无处不在,并在网络安全领域为从芯片到云端的数字世界奠定信任的根基。
其中也包括我们熟知的头部企业,如台积电、Intel 和三星。还有开发者们耳熟能详的云原生计算基金会(CNCF)毕业项目,也原生支持 Arm 架构。
目前,在短短四个月内已有超过 20 家企业加入 Arm 全面设计项目,涵盖新的 EDA 和配套 IP 提供商,以及来自韩国、中国台湾、中国大陆和印度等具有巨大发展潜力的战略市场的芯片设计公司。他们均致力于确保高性能、高效率解决方案的广泛可触及性,助力满足 AI 加速未来的计算需求。
此外,基于 Arm 全面设计生态伙伴的反馈意见,Arm 近期还发布了芯粒系统架构 (Chiplet System Architecture, CSA)。其旨在定义一个功能强大、支持通用的芯粒生态系统。
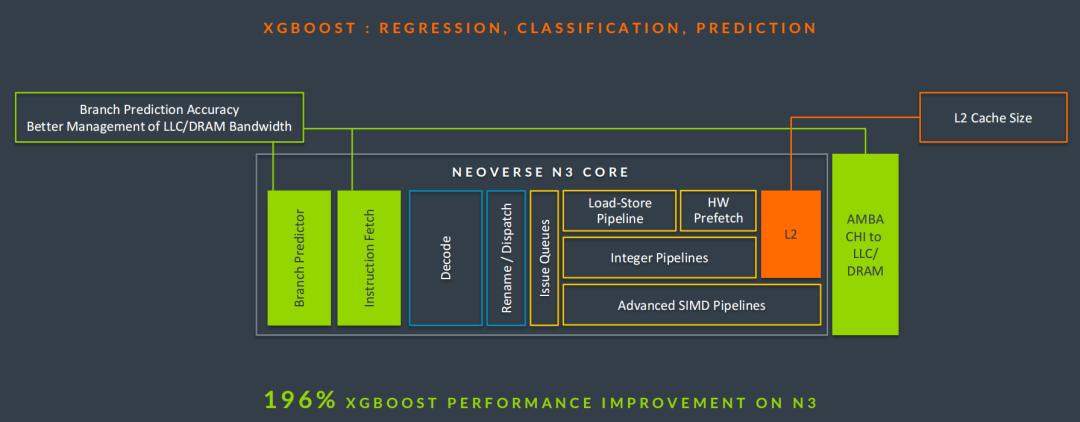
在过去的一年里,Arm 发现了不少市场空缺,于是为了提供满足基础设施性能要求的高效计算,他们推出了 N 系列的最新 CSS 产品——Neoverse CSS N3。CSS N3 的首个实例可提供 32 核心,拥有卓越的能效表现,其热设计功耗(TDP)低至 40 瓦特。
基于最新的 Neoverse N3 IP 平台构建的 CSS N3,不仅引入了 Armv9.2 架构特性,还在每个核心上配备了高达 2 MB的专用二级缓存(L2),同时兼容并支持当前最前沿的 PCIe 和 CXL I/O 接口标准,以及统一芯片互连(UCIe)的芯粒互联规范。
也有些厂商希望在保有 CSS 所有优势的同时,实现更高的性能。因此,Arm 便将 CSS 引入到了高性能的 V 系列,推出了 Neoverse CSS V3。
CSS V3 在单芯片上最多可扩展至 128 核,并支持最新的高速内存和 I/O 标准。CSS V3 基于最新的 Neoverse V3 核心打造,是 Arm 目前单线程性能最高的 Neoverse 核心。V3 为 Arm 机密计算架构 (CCA) 提供硬件支持。V3 和 N3 核心均可提供业界领先的专用 L2 缓存大小,显著改善性能表现。
既然 CSS V3 主打性能,那它在关键工作负载下又能达到什么水平?Arm 提供了如下两张数据图,并强调了一个有意思的点:代际产品之间的性能提升。Arm 的一大优势就是使合作伙伴可以不受制于技术供应商,而是自己掌握创新的步伐,所以更新迭代的速度特别快。
此外,常有人忽视一枚芯片有多少计算周期最终被用于压缩和协议转换等后台任务。N 系列在压缩方面取得了性能优势,可降低云服务运营商的成本,并最终降低云服务客户的成本。同样地,V 系列显著提高了协议缓冲区的性能,这是在数据中心内传输数据的一项关键功能。
光说数据会没什么实感,所以 Arm 也提供了实例。
如今,XGBoost 机器学习算法基本上渗透到所有依赖预测和个性化服务的领域,如内容推荐、出行费用预估及旅行优惠推送等日常应用场景。可以说,我们现在随便打开一个网页所看到的个性化内容,均使用 XGBoost 作为主要数据库来驱动相关核心算法。
所以,这种以工作负载为重点的协作就能最好地体现生活中的实际应用场景。Arm 针对特定关键工作负载的优化,让 N3 平台的 XGBoost 性能飙升至原来的 196%,而且这还是在已经超越同类厂商的工作负载上进行的结果。
去年,有关 AI 的讨论焦点主要集中在生成式 AI 和大语言模型 (LLM) 上,行业重点都是如何训练更厉害的大模型。但根据 Arm 的分析,随着生成式 AI 广泛应用于实际业务场景,其工作重点将转向推理。
分析师估计,已部署的 AI 服务器中有高达 80% 专用于推理,且这一数字还将持续攀升。这一转变意味着要找到合适的模型和模型配置,并加以训练,然后将其部署到更具成本效益的计算基础设施上。
CPU 广泛可用,并可灵活用于机器学习或其他工作负载,此外, CPU 还易于部署,并可支持各种软件框架,具备低成本和高能效等优势。因此,CPU 推理将是生成式 AI 计算应用的关键组成。
但是,并非所有 AI 处理都将在 CPU 上进行,现在风头正盛的 AI 硬件商不是 NVIDIA 吗?事实上,NVIDIA 不仅利用其领先的 Hopper GPU,同时也使用了基于 Neoverse V2 平台的紧耦合计算芯粒 Grace。这种紧耦合的 CPU 加上加速器配置,对大参数 LLM 非常有益,对检索-增强-生成 (RAG) 等新兴方法也很有帮助。
可以见得,Arm 已经通过这次发布解释了自己为什么是未来计算及 AI 的基石。
建设 AI 时代也离不开广大开发者的努力,Arm 在生成式 AI 时代又该如何赋能开发者?Arm 基础设施事业部营销副总裁 Eddie Ramirez 向 CSDN 回答了这点:
我们致力于实现让 AI 应用开发者可以轻松部署的 AI 软件栈。针对中国开发者,我们与龙蜥社区紧密合作。通过提供 Arm Compute Library (ACL, Arm 计算库),为 AI 应用中所使用的许多算法的实现提供出色的支持。Arm 对 TensorFlow、PyTorch 等 AI 框架的支持,加之我们的加速计算库,两者将紧密集成,并纳入未来的龙蜥社区版。
文章来自于微信公众号“CSDN”(ID:CSDNnews),作者 “王启隆”



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI