# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
近日,哈尔滨工业大学(深圳)联合深圳河套学院、Independent Researcher提出了隐式思考模型 LRT(Latent Reasoning Tuning),通过一个轻量级的推理网络,将大模型冗长的「思维链」压缩为紧凑的隐式向量表征,一次前向计算即可完成推理,无需逐 token 生成数千字的中间推理过程。
LRT 不仅实现了高效思考,还能作为一种全新的混合思考范式,在 Qwen3 系列模型上超越了其原生的非思考模式。

以 OpenAI o1、DeepSeek-R1、Qwen QwQ 为代表的慢思考推理模型,通过生成详尽的逐步推理链来解决复杂问题,展现了强大的推理能力。然而,这些模型存在一个显著痛点 —— 过度思考(Overthinking):
Question:这些冗长的推理链真的全部必要吗?
为了回答上述问题,团队设计了一组实验:在 DeepSeek-R1-Distill-Qwen-7B 模型上,将推理轨迹进行不同粒度的删减 —— 随机跳过一定比例的 token 或推理步骤,然后观察模型能否仅凭残缺的推理链给出正确答案。
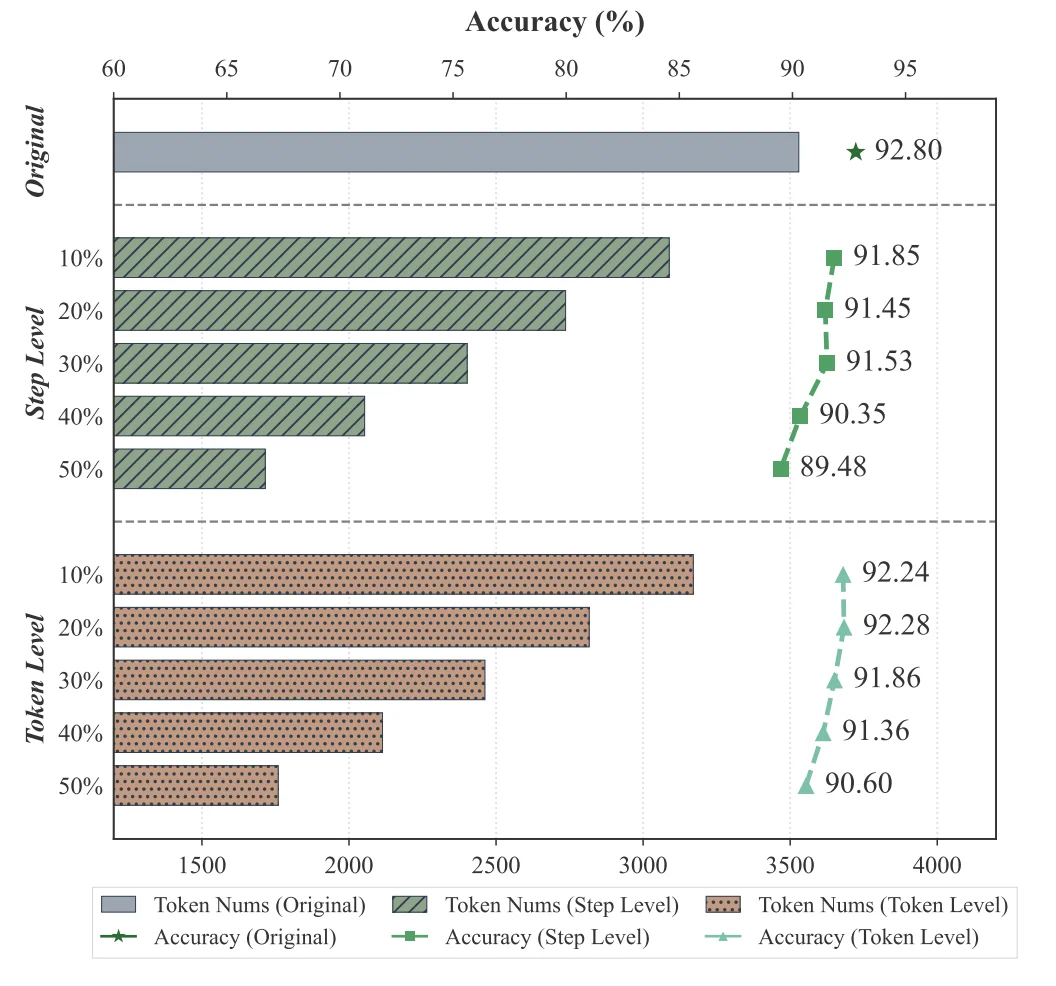
核心洞察: 即使随机丢弃 50% 的推理轨迹,模型准确率仅下降约 2 个百分点。这可以得出两个结论:
这一发现直接启发了团队的核心思路:既然完整的逐步推理链并非必要,能否用一种更紧凑的隐式表征来替代它?
基于上述洞察,团队提出了 Latent Reasoning Tuning(LRT) 框架。其核心思想可以概括为:用一个轻量级推理网络,将显式的推理链「编码」为固定长度的隐式向量,直接注入大模型即可生成最终答案。
技术架构
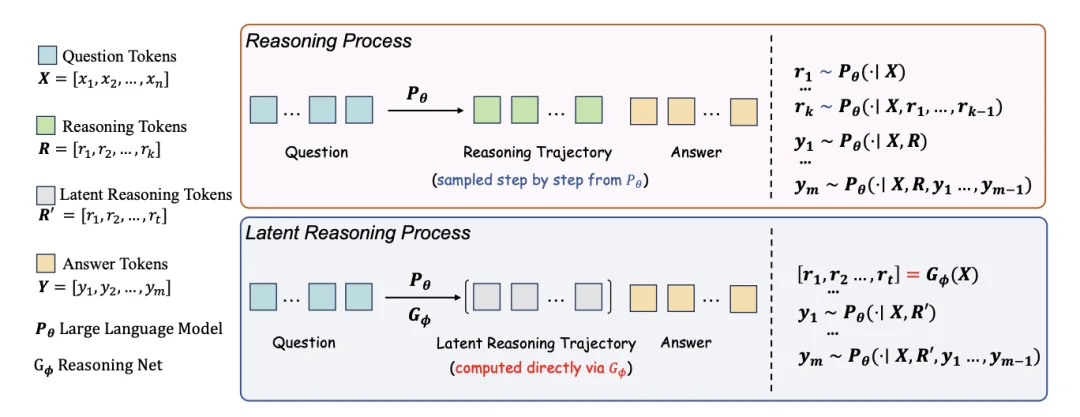
如上图所示,传统推理模型需要逐 token 自回归生成整条推理链(Decode → Decode → ... → Decode),而 LRT 的流程为:

模型的推理生成过程可分为两个阶段:
在 Decode 阶段,思维链的生成过程可以形式化为:
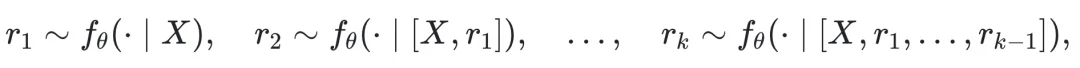


1. 高效思考 —— 在不同 Token Budget 下表现最优
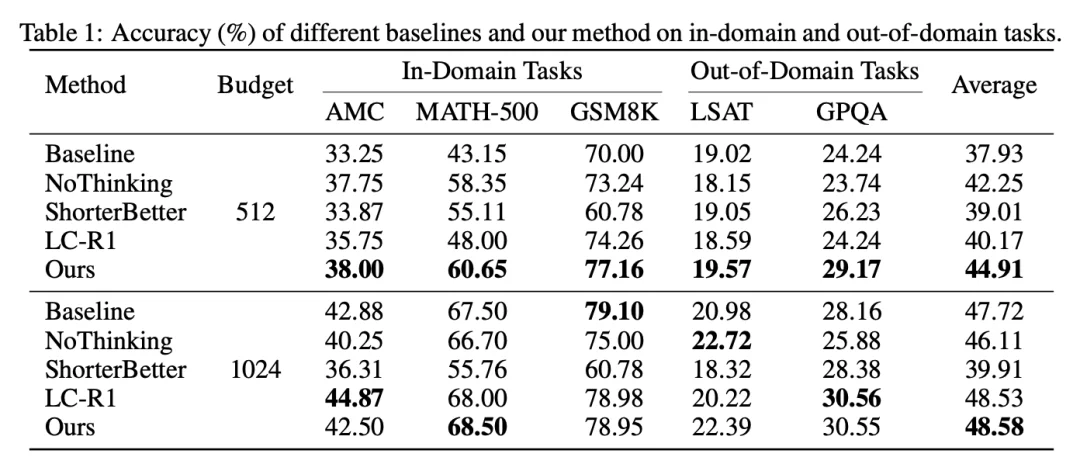
在 DeepSeek-R1-Distill-Qwen-1.5B 上,与多种高效推理方法进行对比:
2. 混合思考 —— 超越 Qwen3 原生混合思考模式
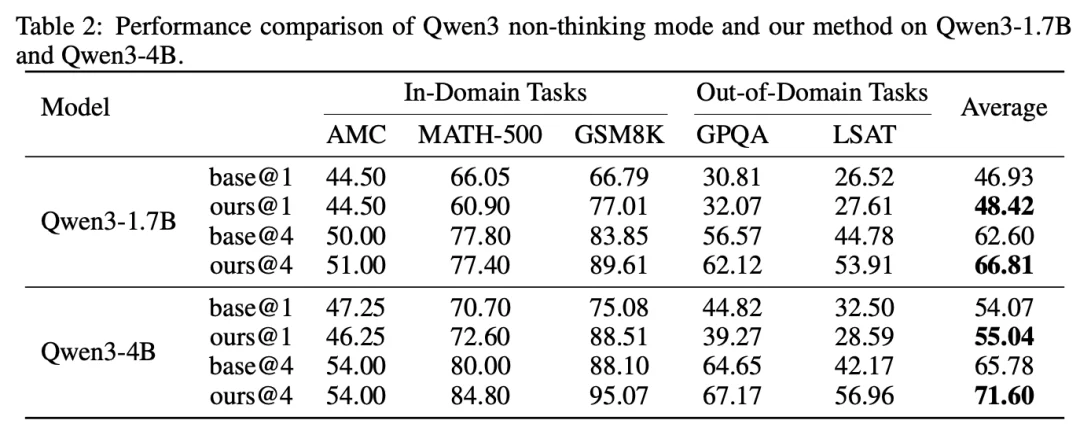
LRT 的模块化设计天然适合作为混合推理的新范式:面对简单问题使用隐式思考快速作答,面对困难问题切换回显式慢思考深入推理。在 Qwen3 系列模型上验证了这一能力:
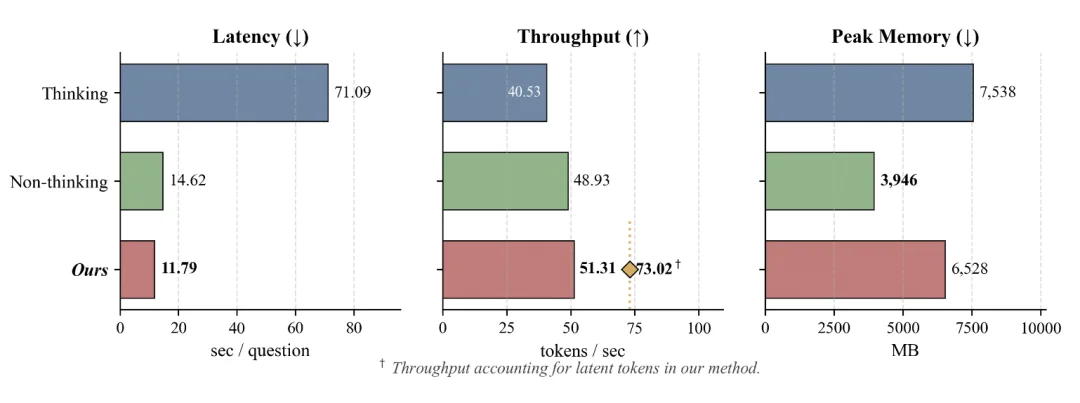
3. 推理效率对比
4. 消融实验分析
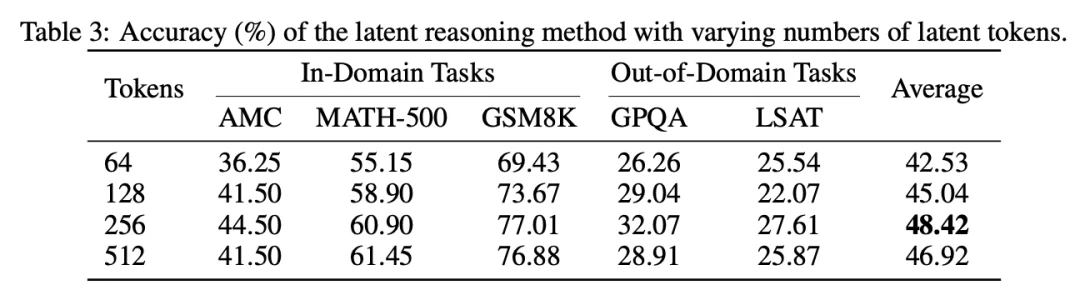
隐式推理 token 数量的影响: 随着隐式 token 数从 64 增加到 256,性能稳步提升(42.53% → 48.42%)。
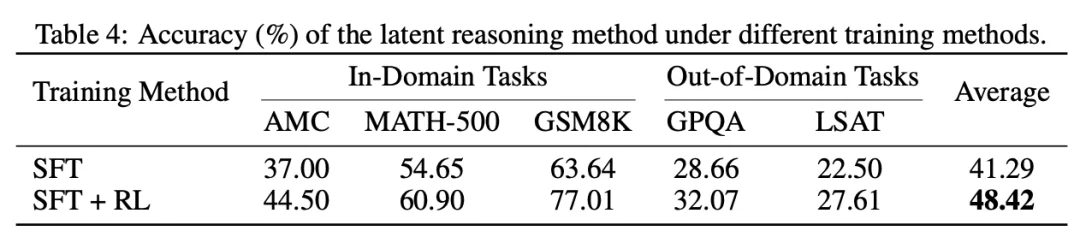
两阶段训练: 加入 RL 阶段后,域内任务平均提升约 9%,域外任务平均提升约 4.3%,验证了强化学习对隐式推理优化的关键作用。
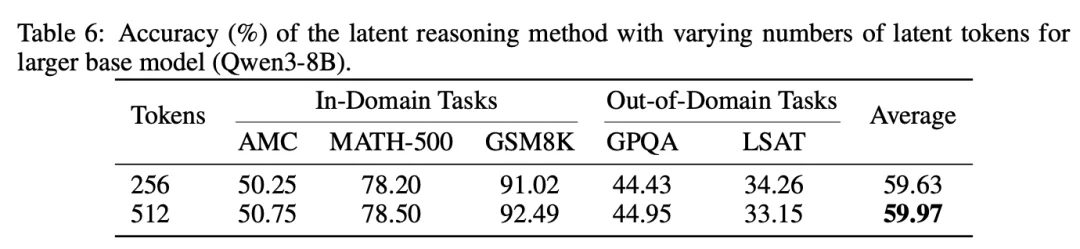
更大的基础模型(如 Qwen3-8B)则能充分利用更多的隐式 token(使用 512 个隐式 token 时结果仍能提高),说明隐式推理的「容量」与基础模型能力正相关。
隐式思考模型 LRT 开辟了一条全新的高效推理路径:
本文第一作者姜聪,哈尔滨工业大学(深圳)博士生,研究方向为高效思考与推理模型。通讯作者张正,哈尔滨工业大学(深圳)教授、博士生导师,教育部青年长江学者,主要从事高效能多模态人工智能的研究,近年专注于高效与可信多模态大模型。
主要完成单位为哈尔滨工业大学(深圳)& 深圳河套学院。
文章来自于"机器之心",作者 "机器之心"。



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
