# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

Anthropic 没有公开 Claude Mythos 的架构。但研究社区没有等。
Kye Gomez,Swarms 框架的作者,发布了 OpenMythos——一个用 PyTorch 从头实现的 Claude Mythos 疑似架构重建项目。发布不到 24 小时,GitHub 已经有 175 个 Star,39 个 Fork。
这不是微调,不是 prompt 工程。是在说:我们根据公开研究推断出了 Mythos 的架构,然后把它完整实现了一遍。
Kye Gomez (@KyeGomezB) 在 X 上宣布发布 OpenMythos,173K 浏览量
这个项目的核心主张是:Claude Mythos 很可能是一个「循环深度变换器」(Recurrent-Depth Transformer,RDT)。
不是更多层,不是更多参数。是同一批层,反复运行多次。
标准的 Transformer 会把 32 层、48 层、96 层叠在一起,每一层参数不同,依次往下走一遍。RDT 不这样——它把中间的一块「循环块」重复运行 T 次,每次用的是完全一样的权重。
推理深度不靠参数堆出来,靠循环次数撑出来。
这意味着什么?Parcae 研究的测试结果:一个 770M 参数的循环模型,达到了 1.3B 参数固定深度模型的同等质量。同样的任务,参数量少了 40%。
在理解 OpenMythos 之前,先说一下背景。
Claude Mythos 是 Anthropic 的新模型。它在很多任务上的表现让研究者感到困惑:它对从未见过的新问题的处理方式,和以前的 Claude 有质的不同。不是更快地记起训练数据,而是更像是「在想」。
Sigrid Jin、rosinality 等研究者陆续发帖:Mythos 的行为模式高度符合循环深度变换器的理论预测。尤其是两个特征让人印象深刻:
第一,系统性泛化。把 Mythos 放到训练分布之外的新组合问题上,它不会像传统 Transformer 那样逐渐退化,而是在某个节点「突然」就会了。研究者把这个现象叫做三阶段 grokking:记忆 → 分布内泛化 → 分布外泛化。这第三个阶段,标准 Transformer 做不到,循环 Transformer 有理论证明可以做到。
第二,深度外推。在 5 跳推理链上训练,在 10 跳推理链上测试——标准 Transformer 失败,循环 Transformer 成功(只要在推理时多跑几个循环)。这直接对应了 Mythos 处理多步数学和长链规划时不需要显式 chain-of-thought 的观察。
OpenMythos GitHub 主页:175 Stars,39 Forks,MIT 许可证
OpenMythos 实现的架构分三段:
输入
↓
[Prelude] — 标准 Transformer 层,只跑一次
↓
[Recurrent Block] — 循环 T 次(推理时可变)
↑__________↓ 每次循环都会重新注入原始输入信号 e
↓
[Coda] — 标准 Transformer 层,只跑一次
↓
输出
循环块的更新公式:
h_{t+1} = A·h_t + B·e + Transformer(h_t, e)
其中 h_t 是第 t 次循环后的隐藏状态,e 是 Prelude 编码的原始输入,A 和 B 是可学习的注入参数。
关键细节:每次循环都会重新注入原始输入 e。这是防止模型在循环中「漂移」的机制——即使循环了七次,模型始终记得它最初在处理什么问题。没有这个 e 的重注入,多次循环会把隐藏状态推向与原始输入无关的方向。
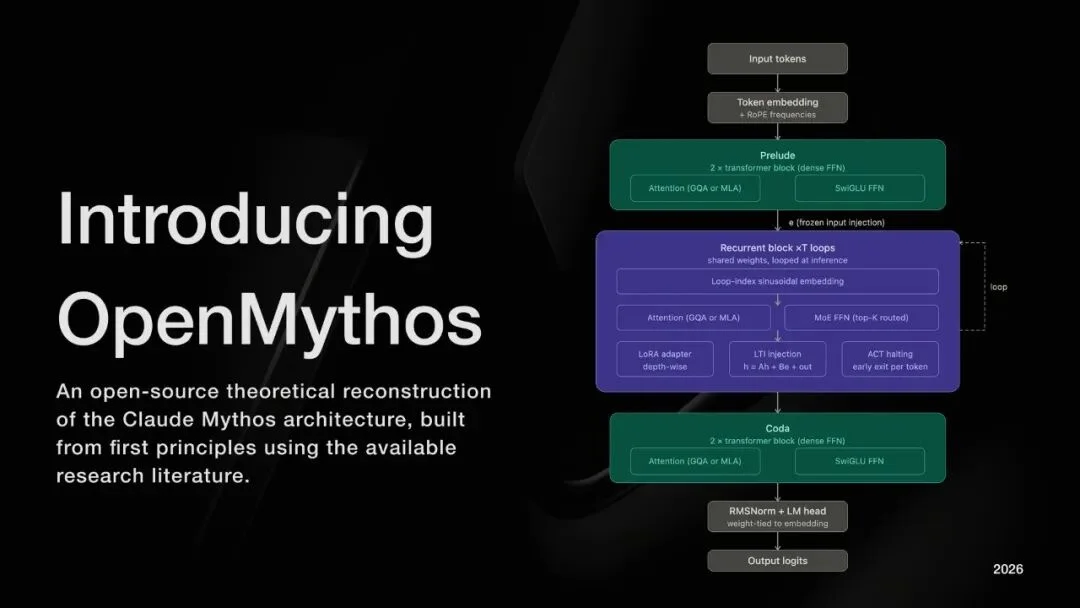
OpenMythos 发布时附带的架构图:Prelude → Recurrent Block(×7 loops)→ Coda
这是整个架构里最反直觉的一点。
标准的 chain-of-thought 是「输出中间步骤」:模型把 step 1 的结果写成 token,再把 step 2 的结果写成 token,一步步把推理过程可视化出来。
循环 Transformer 不这样。它的每次循环,等价于 chain-of-thought 的一步,但这一步是在连续的潜在空间里发生的,不输出任何 token。
Saunshi 等人在 2025 年已经形式化证明了这一点:一个运行 T 次循环的循环模型,等价地模拟了 T 步的 chain-of-thought 推理,但全部发生在单次前向传播内部。
更有意思的是:连续潜在空间里的「思维步骤」,可以同时编码多条可能的推理路径。它不需要在 step 1 就提交一个具体的方向,而是可以在多条路径上并行探索,在循环过程中逐渐收敛。这接近于对推理空间做某种形式的宽度优先搜索,而不是一条走到底的贪心路径。
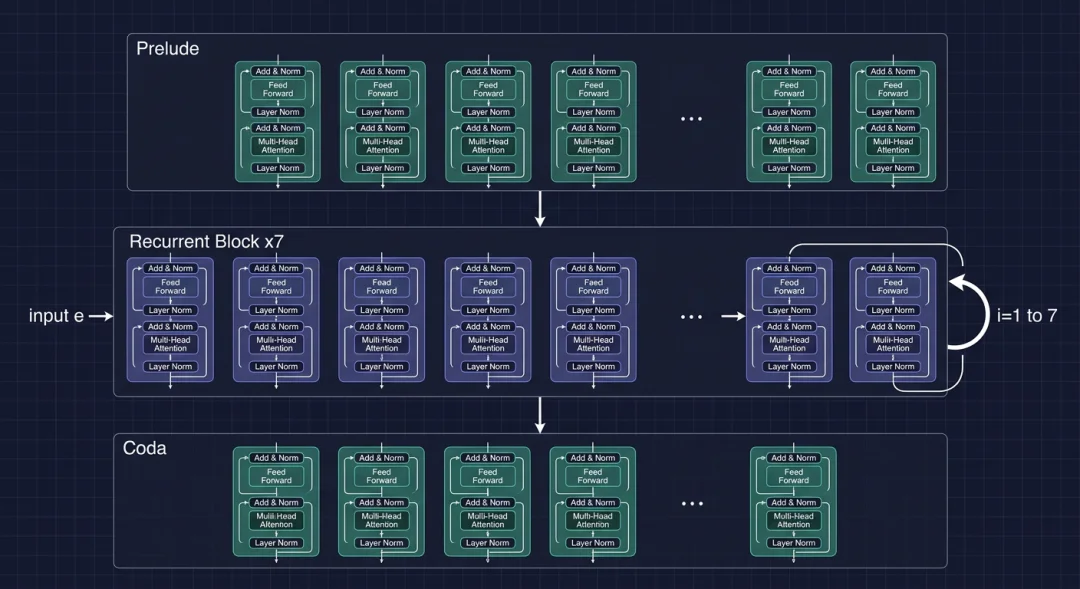
循环深度变换器(RDT)三段架构示意:Prelude 编码输入,Recurrent Block 反复循环推理,Coda 解码输出
循环深度变换器有一个工程上的大麻烦:训练极不稳定。
有两个主要失败模式:残差爆炸(h_t 跨循环无限增长)和 loss spike(训练中途突然发散)。
OpenMythos 采用了来自 Parcae 架构(Prairie 等,2026)的解决方案,用动力系统的角度来理解这个问题。把循环简化成一个线性时不变系统,这个系统是否稳定,完全取决于矩阵 A 的谱半径 ρ(A):
Parcae 的解决方案是:把谱半径 < 1 的约束直接烧进参数化设计里。用 A := Diag(-exp(log_A)) 强制负值,配合 ZOH 离散化方案,无论学习率多高,ρ(A) < 1 总是成立。
OpenMythos 在代码里把这个检查暴露了出来:
A = model.recurrent.injection.get_A()
print(f"Spectral radius ρ(A) max: {A.max().item():.4f} (must be < 1)")

Parcae(Prairie 等,2026):为循环语言模型建立稳定训练方法和规模律,同等质量参数量减半
循环机制解决了推理深度的问题,但没有解决知识广度的问题。用同一批权重处理代码、数学、文学、法律……这批权重要覆盖的东西太多了。
OpenMythos 的猜测是:Mythos 的循环块里每个 FFN 层都是稀疏的 MoE(混合专家)。
具体设计:每个 FFN 被切分成很多小专家(每个只有正常 FFN 的 1/m 大小);一个路由器每次只激活 top-K 个专家处理当前 token;少数几个共享专家(shared experts)始终激活,吸收跨领域通用知识——语法、基础推理、通用上下文。
估计激活比例大约是 5%。这意味着 Mythos 可以持有数千亿的总参数量,而每次推理只激活其中一小部分。
关键的组合效应:随着隐藏状态在循环中演进,路由器在每次循环时可能选择不同的专家子集。每次循环不只是在用同样的权重重复计算——路由决策不同,激活的专家不同,实际上是在用不同的「专家组合」处理同一个问题的不同推理阶段。MoE 提供宽度,循环提供深度。
更多循环不是总是更好。
超过某个深度之后,过度的循环会让隐藏状态漂离正确答案,预测质量开始下降。这叫「过度思考」(overthinking)问题。
解决方案来自 Universal Transformer(2018)的 ACT(自适应计算时间)停机机制:每个位置学一个标量停机信号,动态决定什么时候停止循环。处理难的 token 多循环几次,处理简单的 token 早点停。
OpenMythos 的猜测是:Mythos 几乎肯定有某种版本的停机机制。不可能对所有输入都跑最大循环次数——这需要一个学到的「答案已收敛」信号。ACT 机制还让循环 Transformer 在某些假设下变成图灵完备的,这对它能处理的问题类型有深远含义。
Parcae 为循环模型建立了第一套可预测的规模律:
对于固定的 FLOP 预算和固定的参数量,增加平均循环次数、减少 token 数量,比最少循环 + 更多数据的效果更好。最优循环次数和最优 token 数都遵循幂律,指数在不同规模下保持一致。
推理时的规律:更多循环带来更好质量,但服从预测性的饱和指数衰减——收益真实存在但递减。这和 chain-of-thought 的推理时规模律几乎一模一样。
实验数字:770M 参数的循环模型,在相同训练数据上,达到了 1.3B 参数固定深度 Transformer 的下游质量。
如果 Mythos 在这套规模律下训练,它的「能力」有相当大的比例来自循环深度而非参数量。Anthropic 从未公布 Mythos 的参数数量,这或许是原因之一——公布参数量不能反映实际的计算深度。
OpenMythos 是一个 disclaimer 写得很清楚的项目:「这是独立的社区重建,基于公开研究和推测,与 Anthropic 无关。」
但这件事本身值得认真对待,原因有几个。
第一,研究社区围绕 Mythos 架构形成了相当强的共识。循环深度变换器不是一个新想法,Universal Transformer(2018)就提出了原型,但直到最近的一系列论文(Saunshi 2025、Prairie 2026),理论和工程上的难题才陆续被解决。公开证据从多个方向指向同一个架构类。
第二,循环推理有一个深刻的工程含义:推理时的计算量可以根据问题难度动态调整。简单的问题少循环几次,复杂的问题多循环几次,在同一个批次里混合处理,吞吐量理论上可以提高 2-3 倍。对于部署规模的模型,这不是学术上的细节。
第三,这条路线和「更大的模型 = 更强」的直觉不同。它说的是:同样的参数可以循环利用,推理深度可以在推理时动态控制。这对 AI 能力提升的路径有重要含义——不一定需要无限堆参数,但需要更聪明地利用有限的参数。
我在看完这个项目之后想了一个比喻:标准 Transformer 像一条流水线,每个工人做完自己的工序把零件传给下一个;循环 Transformer 像一个人反复审读同一份文稿,每次阅读都加深理解。七次循环,越来越接近答案。
参数数量不是这里最重要的东西。思考的次数,才是。
相关链接
• OpenMythos 源码: github.com/kyegomez/OpenMythos
• Parcae 论文博客: sandyresearch.github.io/parcae
• 原始帖子: x.com/KyeGomezB/status/2045659150340723107
文章来自于"深思SenseAI",作者 "深思SenseAI"。


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
