# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

看到标题《这个模型让机器人长出了嘴》,你可能会心生疑惑:
AI不是早就懂语音播报了吗?
Siri、各种智能音箱,甚至导航里的志玲姐姐,哪个没有嘴?
不,在真正的 Voice Agent(语音智能体)语境下,那不叫嘴,那顶多叫一个没有感情的外接扬声器。
玩过《底特律:变人》或者看过美剧《西部世界》的朋友,一定对里面那些仿生人印象深刻。
他们之所以让人产生非常真实体验感,不仅仅是因为无限趋近人类的硅胶外表,更是因为他们极其自然的交流方式。

他们不需要你按着按钮才能说话,他们懂得察言观色,能在你发火时瞬间停止陈述,也能在背景嘈杂的酒馆里,准确剥离出你的声音,和你自然地你来我往。
反观现实,我们过去两年用的 Voice Agent,哪怕参数卷上天、延迟做到几十毫秒,交互时依然有极浓的机器味。
本质上,你还是得像用对讲机一样单向输出。
你要是中间结巴一下,它立刻抢话;
旁边要是有人咳嗽一声,它就开始胡言乱语。
直到最近,实测了豆包刚上线的全双工语音模型Seeduplex后,我第一次产生了一种奇妙的错觉:
这不再是机械的指令对答,而是一次真正意义上与机器人的自然聊天。
抛开极低延迟这些噱头不谈,今天我想以一个行业观察者的视角和大家聊聊:
为什么让AI长出嘴并不难,难的是教会它什么时候该闭嘴?
开头提到的对讲机模式,在通信工程的底层架构里,被称为半双工(Half-Duplex)。
为什么过去两年我们跟AI聊天,哪怕它回答得再好,依然会觉得那么累、那么有机器味?
因为以前的Voice Agent,本质上是在做一场各管一摊的接力赛。
你的语音先交给ASR(语音识别)转成文字,文字跑去给LLM(大模型)生成回复,最后再交给TTS(文本转语音)把它念出来。
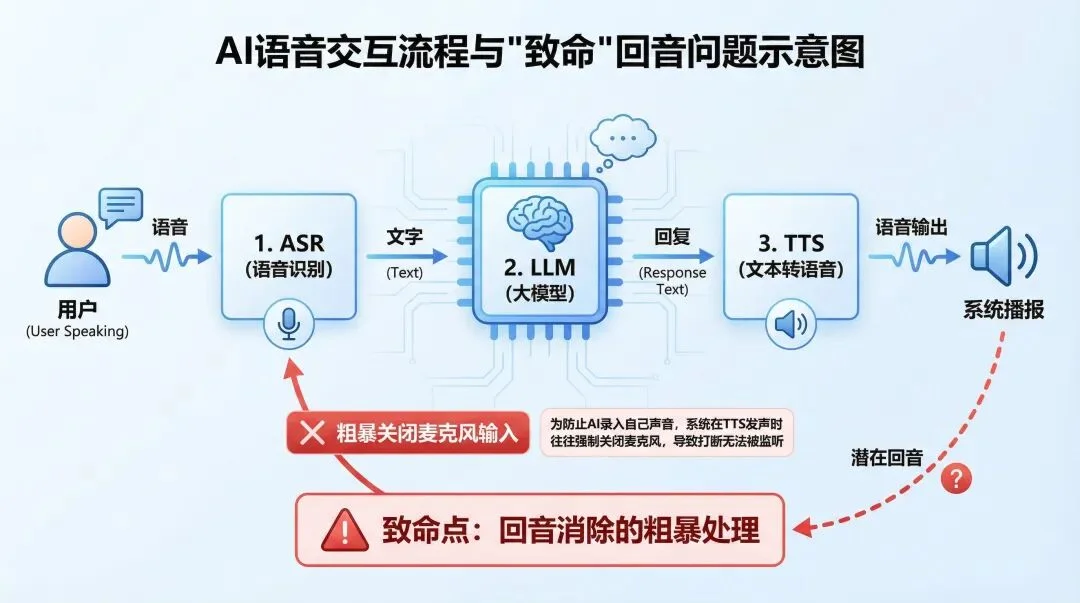
更致命的是,在模型的TTS模块开口说话时,为了防止AI把自己的声音也录进去造成回音,系统往往会粗暴地把麦克风输入关掉(或者不作处理)。
这就是为什么你对着滔滔不绝的AI大喊闭嘴毫无作用:
因为它说话的时候,物理上是聋的。
这种听和说是单行道的粗暴轮流制,直接导致了我们过去和AI语音交互时遇到的三大至暗时刻:
第一,绝不能犹豫。
你要是中间因为想词儿结巴了一下,哪怕只停顿了1.5秒,VAD这个机械定时器就会切断你的麦克风,像一个急躁的抢答器一样,拿着你半路夭折的话开始滔滔不绝。
第二,必须强行手动打断。
当AI开始疯狂输出一段你根本不需要的长篇大论时,语音打断是无效的。你必须极其反直觉地去点亮屏幕,寻找那个小小的停止按钮。
第三,极其脆弱的环境适应力。
只要出了安静的房间,旁边要是有人咳嗽一声,或者经过一辆按喇叭的汽车,VAD就会瞬间迷失自我,把这些噪音当成你的指令,然后大模型就开始胡言乱语。
刚刚提到的那些痛点,就是旧时代的至暗时刻。
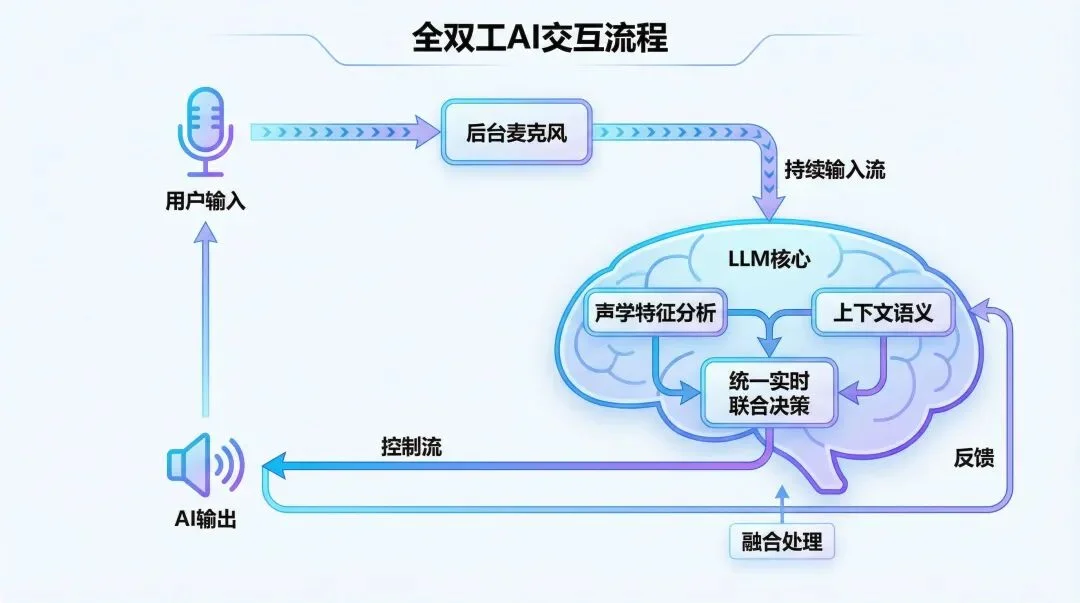
而这次我实测豆包搭载的 Seeduplex 模型后,之所以产生了像和真人通电话的错觉,核心就在于它打通了全双工(Full-Duplex)的任督二脉,从底层架构上重构了交互。
模型在开口说话的同时,后台麦克风依然保持常开,持续接收并处理输入流。
判断你是否要打断它的,不再是无脑的声控开关,而是统管全局的大语言模型(LLM)本身。
它将声学特征与上下文语义彻底融合,进行统一的实时联合决策。
这种底层重构带来的并不是虚无缥缈的概念,而是极其硬核的参数跃升。
从官方公布的测试数据来看,Seeduplex的新架构将判停延迟降低了约 250ms,复杂场景下的 AI 抢话比例大幅减少了 40%。
而当你主动发起打断时,它的响应延迟进一步缩短了约 300ms,复杂声学干扰场景下的误回复率和误打断率更是直接降低了一半。
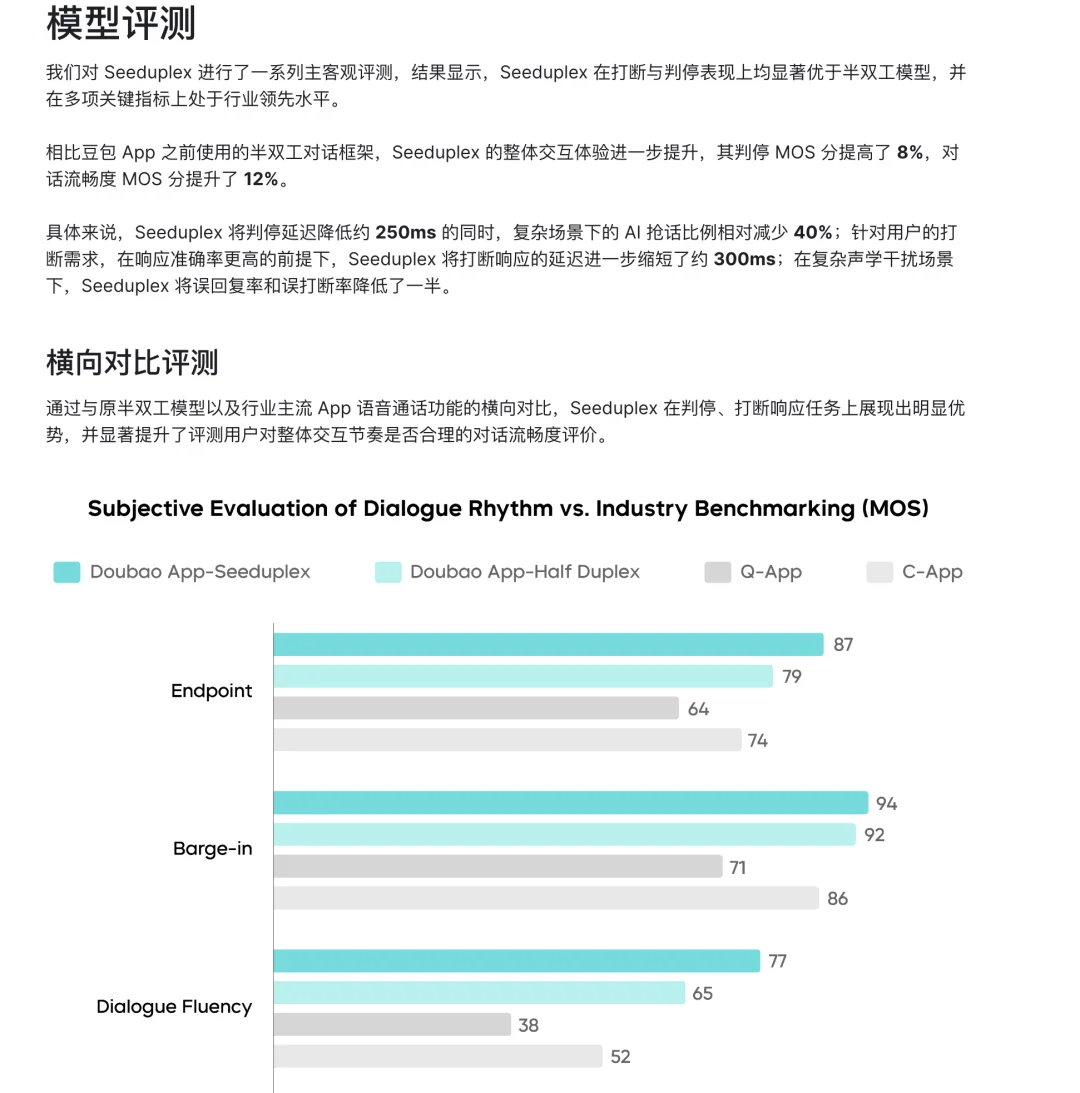
最有意思的是,官方甚至做了一组极其极客的摸底测试——把全双工AI拿去和普通的真人对话做基准对标。
结果出现了一个极其反直觉的数据:
在响应打断(Barge-in)这项指标上,由于人类在聊天时偶尔也会走神或反应滞后,Seeduplex 的打断响应表现,甚至略微超越了真实人类的平均水平(MOS分 94 vs 91)!
冰冷的架构重组和参数跃升,最终都需要兑现为真实的对话体验。
基于这种耳朵和嘴巴终于能并行工作的底层技术升,你会发现,豆包并没有把精力浪费在延迟又降低了零点几秒这种枯燥的内卷指标上,而是试图解决一个更本质的痛点:
让人机交互真正对齐人类的生理直觉。
落实到具体的日常交流中,这种跨越机器味的对齐感,集中爆发在两大核心体验的跃升上:
在真实世界里,绝对安静的实验室环境是不存在的。
我们的日常充满了背景音:地铁的轰鸣、咖啡馆邻桌的八卦、电视机里的新闻。
人类的大脑拥有一种非常神奇的机制,叫鸡尾酒会效应(Cocktail Party Effect)。
哪怕在极其喧闹的酒会上,只要有人叫你的名字,或者你正在专注和眼前的人聊天,你的大脑会自动过滤掉周围的杂音。
但过去的AI没有这种脑子,它的判断逻辑是死板的:
只要麦克风收到了大于某个分贝的声音,它就判定输入的指令来了。
所以,过去的AI只要一出门就变傻。
官方给出了一个极其生动的Case:
你正在家里开着免提和豆包聊天:帮我构思一个明天开会的发言稿……
就在这时,外卖小哥敲门大喊:你的外卖放门口了啊!
你转过头,顺口回了一句:好嘞,谢谢,你就放那儿吧!
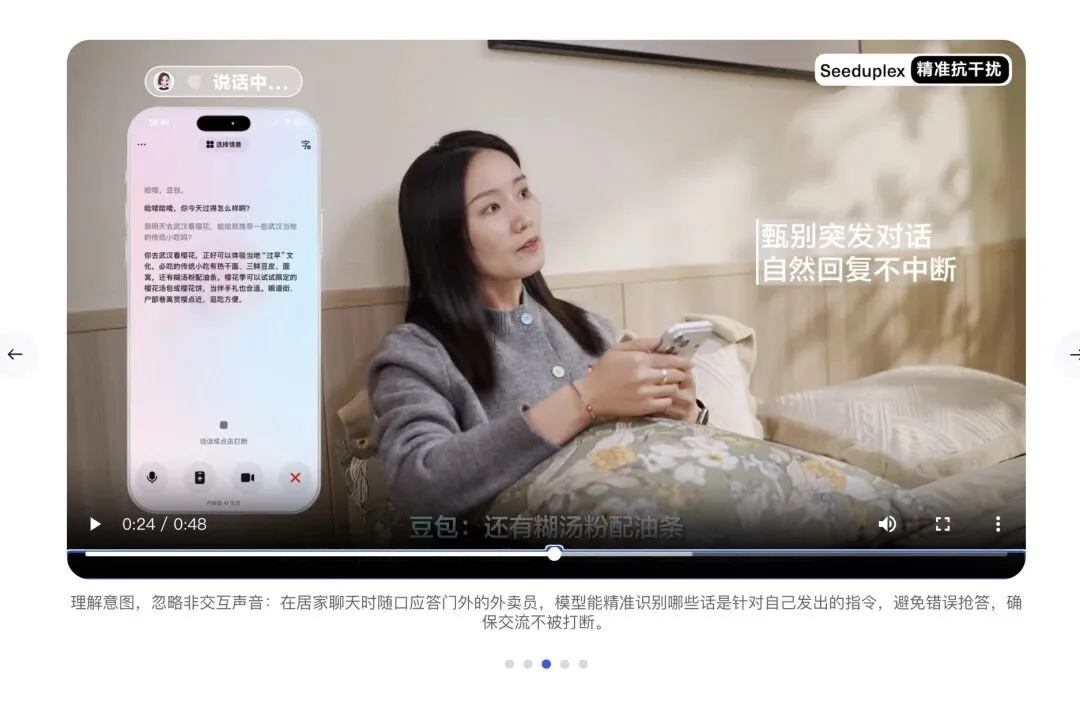
如果换做以前的半双工AI,它一定会把外卖放那儿吧当成你的最新指令,然后智障地回复你:
好的,已经为您记录,关于外卖的安排……
但全双工的豆包,在这里展现出了惊人的语境判断力。
它不仅在持续监听,而且同一个底层模型在实时判断:
这句话的声学特征、语义上下文,是不是对我说的?
它瞬间意识到,主人是在回应第三方的打断,于是它选择了最像人类的反应:
保持安静,继续倾听,等你回过头来接着聊。
这种识别不是对我说话,并保持沉默的能力,在嘈杂的真实环境中太重要了。
它意味着你以后和AI语音,不再需要刻意清场。
另一个极其打动我的点,是动态判停机制。
这解决了过去AI交互中最让人窒息的压迫感。
真实的、非剧本的人类聊天是什么样的?
是充满了废话、停顿、迟疑、甚至是倒装句的。
我们会说:呃……那个叫什么来着……就昨天你看的那个电影……啊对,《沙丘2》!
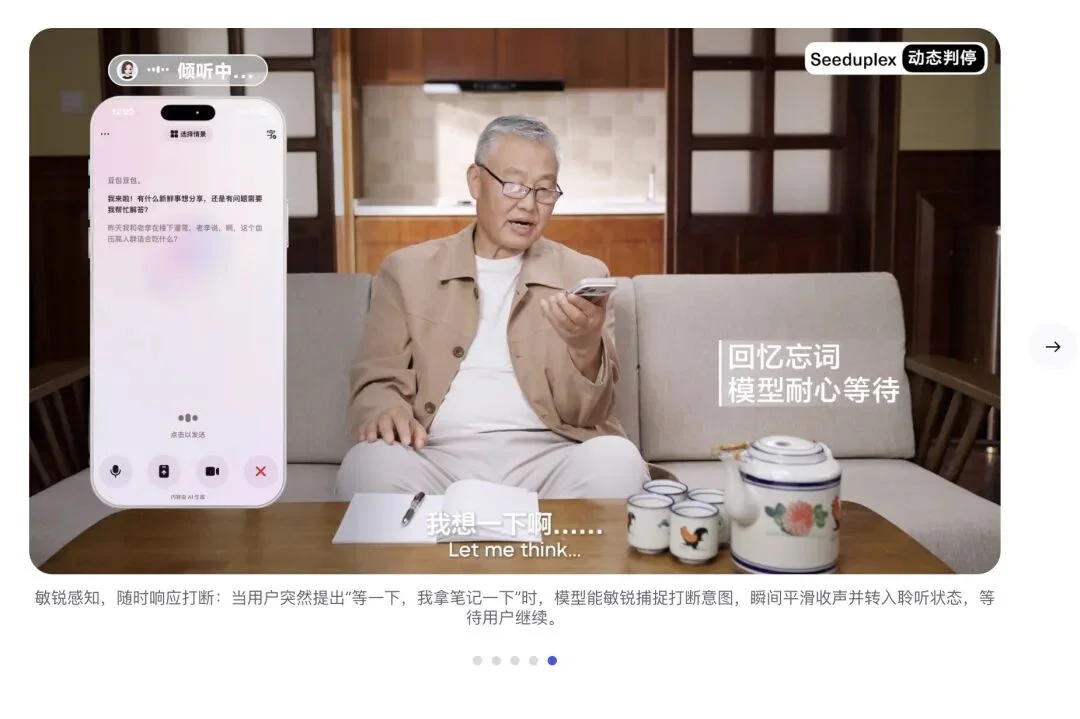
传统的AI语音系统里,判断你有没有说完的,是一个叫 VAD(Voice Activity Detection,语音活动检测)的独立小组件。
传统的VAD很多时候非常智障。
这个小组件是个没有感情的定时器,它只看声波,根本不懂你在说什么。
只要它检测到你停顿超过了设定好的阈值(比如1.5秒或2秒),它就无情地切断录音,强行把前半句半路夭折的话发给大模型去处理。
这就导致我们在和AI语音交流的时候,只要稍微一卡壳,AI就会立刻抢话。
这种糟糕的体验,逼得我们每次和AI说话前,都得在脑子里先打好完整的草稿。
但豆包这次的更新,从根本上摧毁了这个机械的定时器。
它将判停的权力,交给了拥有理解能力的大模型本身。
声学特征和语义上下文开始同时参与决策。
当你停下来呃……的时候,模型通过你上一句话的语义结构(比如主谓宾还不完整),判断出你只是在思考,而不是结束。
它会像一个极具耐心的倾听者一样,在电话那头静静等你把缺失的那个词找出来,不再像个没有边界感的抢答器一样强行接话。
懂得在人类思考时保持沉默,这是机器拥有情商的开始。
当然,官方的测试Case看起来总是那么美好。
但作为长期折腾各种 Voice Agent、被无数早期模型折磨过的骨灰级玩家,我肯定不会轻易买账。
是骡子是马,得拉到最极端的真实场景里溜溜。
为了验证这个“全双工”到底是不是噱头,我没有在安静的房间里测,而是直接把它带到了一个极其典型的复杂环境——车厢里。
并且,我刻意让车机屏幕大声播放着带有密集台词的影视剧,然后打开了豆包的“桃子”音色,进行了一场没有彩排的极限测试。
我不测它上知天文下知地理的知识库,我只测它的社交边界感和耳朵的定力。
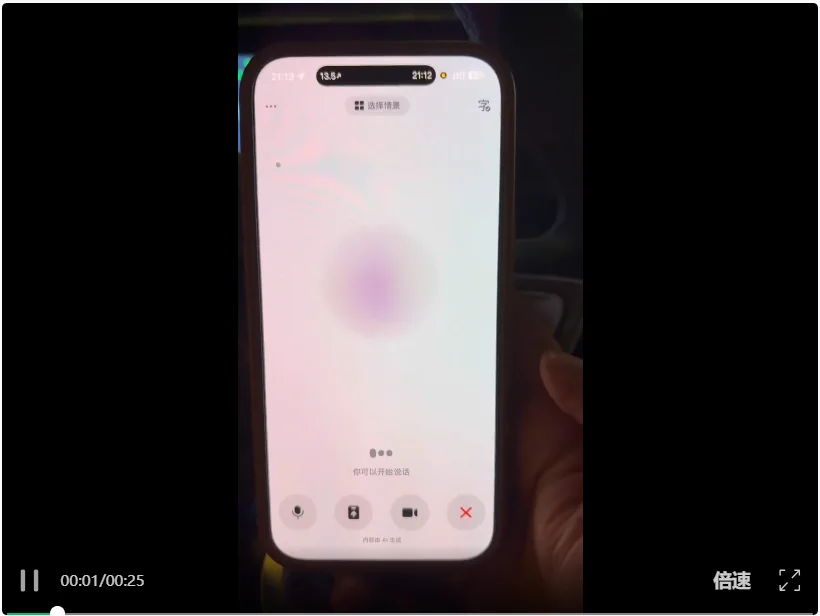
【极限场景一:精神分裂式的迟疑与修正】
我开始用非常散漫、甚至有些结巴的语气跟她下指令。
我问:“我想知道最近北京有什么演出?啊……呃……别了,还是告诉我最近有什么好的电影吧。”
如果是以前的半双工AI,在我说出“啊……呃”的那一两秒停顿里,VAD定时器早就强制掐断录音,然后给我强推北京的演唱会了。
但在这场测试中,豆包展现出了惊人的“耐心”。
它完美地识别出我正在思考卡壳,并在我完成逻辑跳跃后,极其平滑地接住了我的真实意图,开始给我介绍北京国际电影节的片单。
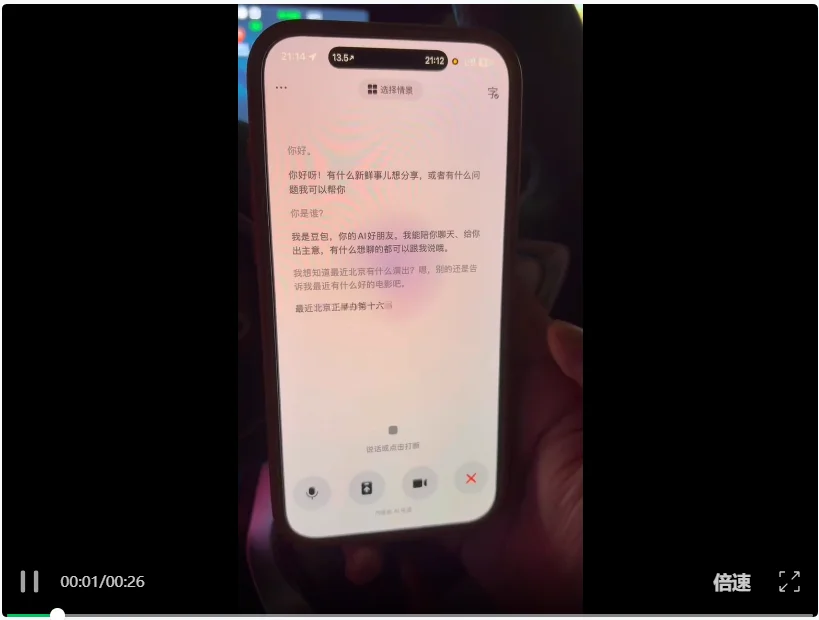
【极限场景二:无缝的语音级打断】
当她刚开始滔滔不绝地给我报片单时,我毫不客气地在半路直接插话:
“你能跟我说下有什么国外片子吗?就是进口的。”
它的声音瞬间掐断,没有任何延迟的拖泥带水,就好像电话那头的人真的把刚到嘴边的话咽了回去,立刻调转车头,给我筛选出了《穿普拉达的女王》。
【极限场景三:地狱级的“背景台词”抗干扰】
这是整个实测中最让我头皮发麻的一段。
当我正准备让她帮我查查《穿普拉达的女王》的介绍时,我故意打开了旁边的车机屏幕里的电视剧,传出了极其大声的影视剧台词——里面的人正在大喊:“洗手吧!”、“先生,您也要许愿吗?”
注意,这可是极其清晰、响亮的人类对话声。
换作以前的模型,肯定会把“洗手”、“许愿”这些词全部当作我的最新指令,然后给我一个极其离谱的回答。
但豆包在这漫天的背景台词中,像一个拥有极强专注力的特工一样,精准地剥离出了“哪些是我说的,哪些是背景音”。
它完全无视了车机里演员的对话,只针对我关于《穿普拉达的女王》的问题,娓娓道来地给出了介绍。
实测下来,我必须承认,这次的升级并不是停留在PPT上的概念。
当一个机器可以被你无情打断、可以包容你的结巴反悔、甚至可以在嘈杂的电视剧背景音中唯独锁定你的声音时…
那种长久以来横亘在人机交互之间的恐怖谷效应,终于开始消散了。
跳出豆包这款新模型,作为行业观察者,回看这两年 Voice Agent 的发展,其实经历了一个巨大的预期落差。
2024年,是语音模型画大饼的一年。
各种能模拟呼吸、会冷笑的实验室 Demo 满天飞,所有人都觉得《钢铁侠》里的贾维斯要来了。
但到了2025年,行业却放缓了。
因为大家痛苦地发现:实验室跑分容易,但在高并发、在满是闲聊声的真实世界里不卡顿、不抢话,极难。
无数炫酷的模型,最终还是只能困在实验室/论文的代码里。
而时间来到今年(2026年),豆包的全双工模型,算是在行业落地的瓶颈中,交出了一份极其务实且硬核的答卷。
它不再去卷那些花哨的噱头,而是回归了人机交互的第一性原理:
交流,必须建立在平等的节奏上。
从对讲机到真正的双向电话,人类在通信史上走过了很多年;
而AI从半双工走到稳定可落地的全双工,也同样经历了无数工程师的暗夜摸索。
科技进化的终极归宿,应当是隐藏科技本身。
不再是人类小心翼翼地去迁就机器的缺陷,而是你可以结巴、可以反悔、可以在任何喧闹的街头自然地开口;
而赛博世界里的那个人,能在你需要倾听时闭嘴,在需要回应时发声。
今天,在这个长了嘴也学会了闭嘴的豆包身上,我隐约看到了那个未来的雏形。
也期待在接下来,行业能迎来更多全双工底层的突破,让真正自然的AI对话,成为我们日常生活中最微不足道、却又不可或缺的一部分。
文章来自于"01Founder",作者 "Max"。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
