# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
通义千问是阿里巴巴推出的一个大语言模型,此前开源的Qwen-7B引起了广泛的关注,因为他的理解能力很强但是参数规模很小,因此受到了很多人的欢迎。而目前再次开源全新的Qwen-14B的模型,参数规模142亿,但是它的理解能力接近700亿参数规模的LLaMA2-70B,数学推理能力超过GPT-3.5。
除了Qwen-14B外,本次阿里还开源了一个基于Qwen-14B模型打造的Agent开源软件。
Qwen-14B是基于Transformer的大型语言模型,按照官方的介绍,Qwen-14B在超过3万亿tokens上训练,数据集包含高质量中、英、多语言、代码、数学等数据,涵盖通用及专业领域的训练语料。而此前的Qwen-7B模型实在2.4万亿tokens上训练。因此,不仅参数规模翻了一倍,其训练数据也增长了25%。
训练数据不同语言占比如下:
参数规模和训练数据的增长也让Qwen-14B的效果大幅增加,在MMLU的评测结果上得分66.3,接近700亿参数规模的LLaMA2-70B,引起了非常多的关注。
Qwen-14B使用了超过3万亿tokens的数据进行预训练,这些数据包括高质量的中文、英文、多语言、代码、数学等信息,覆盖了广泛的领域。通过大量对比实验,预训练数据的分布得到了优化,确保了模型的高质量训练。
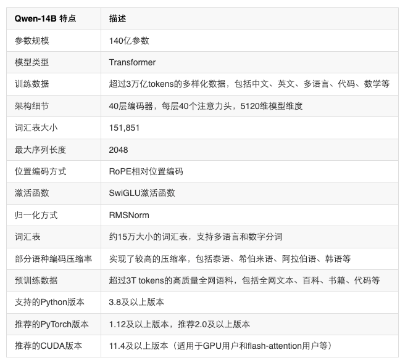
模型的架构也非常出色,包括了40层的Transformer编码器,每层有40个注意力头,以及一个5120维的模型维度。
模型的词汇表大小达到了151,851,而序列长度可达2048。这个词汇表可以说是超过了很多模型。大模型的词汇表是指在自然语言处理(NLP)中使用的模型所能理解和处理的所有单词、子词或标记的集合。词汇表的大小通常是衡量一个NLP模型规模的重要指标之一。
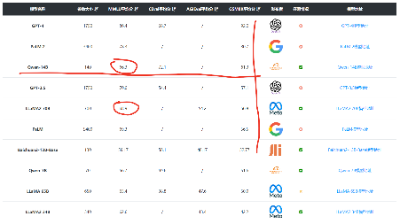
目前常见的模型词汇表大小如下:
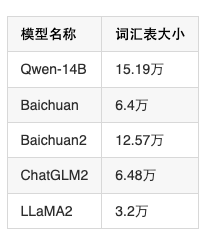
可以看到,但从词汇表看,Qwen-14B也是目前最多的模型之一。
在实现方式方面,Qwen-14B采用了流行的技术,如RoPE相对位置编码、SwiGLU激活函数和RMSNorm,这些技术的应用使得模型在各种任务上表现出色。
以下是通义千问-14B(Qwen-14B)模型的详细信息:
Qwen-14B的强大之处不仅在于其参数规模和训练数据的广泛性,还在于其对长上下文的支持。引入NTK插值,LogN注意力缩放,窗口注意力等技巧,将Qwen-14B模型的上下文长度从2K扩展到8K以上。
这意味着模型能够理解和处理更长的文本片段,这对于复杂的自然语言处理任务非常重要。
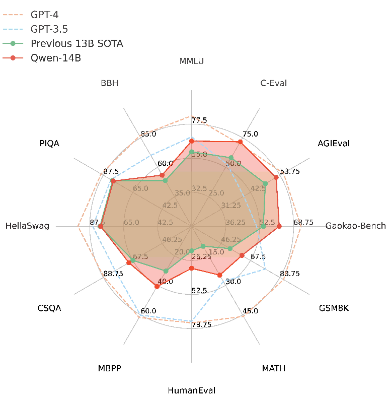
最终,我们来看一下Qwen-14B在各种评测任务上的表现。这个模型在多个中英文下游评测任务上都表现出色,包括常识推理、代码理解、数学问题求解、翻译等。事实上,它的性能不仅超越了相近规模的开源模型,甚至在某些指标上也与更大尺寸的模型竞争激烈。在MMLU的评测上,Qwen-14B的得分66.3,远超Baichuan2-13B-Base的59.17分,接近700亿参数规模的LLaMA2-70B的68.9分,而在GSM8K的数学推理上,Qwen-14B的得分61.3分,超过了GPT-3.5的57.1分。
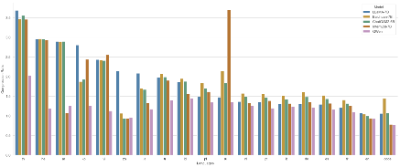
下图是DataLeaner大模型评测中Qwen-14B和其它模型的评测对比结果:
在代码评估上,HumanEval的得分32.3,比CodeLLaMA-7B的33.5略低,但是超过了LLaMA2-70B的30.5分,也就是说,作为语言模型,Qwen-14B代码表现尚可,但是与专门的代码模型相比则不太行。
Qwen-14B模型开源了2个版本,一个是Qwen-14B的基础大模型,一个是Qwen-14B-Chat版本的对话调优版本。后者可以更好适应对话任务。
需要注意的是,Qwen-14B模型开源协议是自定义开源协议,对学术研究完全开放,而商用需要申请授权,不过也是免费授权商用~
Qwen-Agent是一个基于开源模型通义千问(Qwen)的代码库,用于将工具使用、规划生成、记忆等组件集合在一起。目前,我们已经开发了一个名为BrowserQwen的浏览器扩展程序,它能够方便地辅助您进行网页和PDF文档的理解、知识整合和富文本内容编辑工作。以下是BrowserQwen的特点:
将Qwen集成到浏览器扩展程序中,支持在浏览器中与Qwen进行讨论,聊一聊当前Web页面、PDF文档的内容。
在您允许的前提下,BrowserQwen将记录您浏览过的网页和PDF素材,以帮助您根据浏览内容完成编辑工作。通过BrowserQwen,您可以快速完成多网页内容的理解、浏览内容的整理和新文章的撰写等繁琐工作。
支持插件调用,目前已经集成了代码解释器(Code Interpreter)等插件,代码解释器能够支持上传文件进行数据分析等功能。
目前,我们支持两种模型:Qwen-14B-Chat(推荐)和Qwen-7B-Chat。对于Qwen-7B-Chat模型,请使用2023年9月25日之后从官方HuggingFace重新拉取的版本,因为代码和模型权重都发生了变化。
文章转载自“数据学习”


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md