# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
月之暗面昨天发布了 Kimi K2.6,代码能力和 Agent 能力都有明显增强。官方数据很亮眼:13 小时不间断编码、4000 行代码重构、LMArena 全球开源第一。
作为 Kimi 的重度用户,其实挺早就拿到了内测资格,用了有段时间了。这期间摸索出一套自己觉得挺顺手的用法,现在 K2.6 正式发布了,正好把这个案例完整分享出来。

技术栈很简单:Kimi K2.6 + Hermes + Obsidian。整个流程跑下来,在多模态理解、长程推理、结构化输出这三块,K2.6 的表现都让我挺惊喜。
K2.6 + Hermes 这套组合已经可以实际用了。不只是知识库,看 B 站技术视频做笔记,读行业报告提取关键信息,听播客整理要点,开会做记录。个人知识库、团队协作、垂直领域 Wiki,都可以用同一套方法。
我们写了完整的保姆级教程,部署 Hermes 大概 15 分钟,初始化知识库 5 分钟,处理第一个视频 10 分钟。下面这张图就是教程概览,可以存下来对照着走。
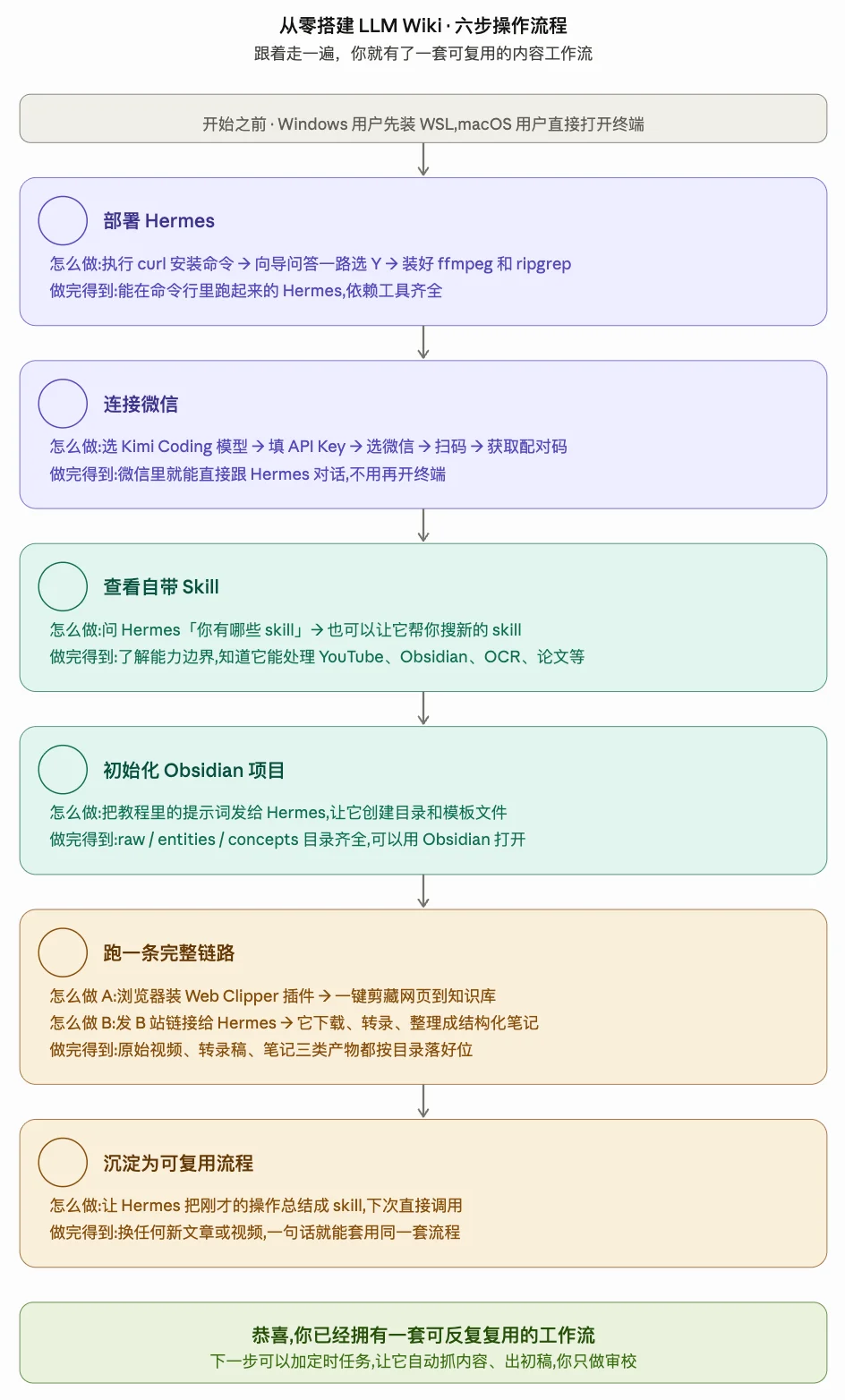
为了方便持续更新,教程放在了飞书文档里,点进去就是最新版。每一步的具体命令、截图和踩坑记录都在里面,新手照着做也能半小时跑通。
完整保姆教程:https://datawhale.psce.pw/8ymxer
最常用的场景就是看 B 站技术视频做笔记。
扔一个 B 站视频链接给 Hermes,一段时间后,一篇结构化笔记就躺在 Obsidian 里了。

打开笔记的时候,我注意到一个细节:K2.6 不只是把音频转成文字,而是结合视频画面和语音一起理解,生成的笔记里既有讲解内容,也有对画面元素的补充说明。
这就是 1T 参数原生多模态的优势——它真的在"看"视频,而不是简单地把音频转成文字。K2.6 作为原生多模态模型,能同时处理视觉和语音信息,100 tokens/s 的推理速度让整个流程很流畅。
整个流程 Hermes 会自动拆成几步:用 yt-dlp 下载视频、转录成 markdown 文稿、再基于视频和文稿生成结构化笔记。最后按目录落位好,视频放 raw/assets,转录稿放 raw/transcripts,笔记放对应的 concepts 或 entities 目录。生成的笔记不是流水账,而是按"核心观点、关键要点、行动建议"这种结构化方式组织的,直接就能用。
第一个视频跑通后,Hermes 自动把整个流程沉淀成了一个 Skill。下次处理新视频只需要一句话:"用那个 Skill 处理这个视频。"
这就是很多人第一次看 Hermes 会觉得惊讶的地方。它能自己总结经验封装成 Skill,相当于可以自进化的小龙虾。跑一次完整流程,下次就多一个能力,越用越顺手。
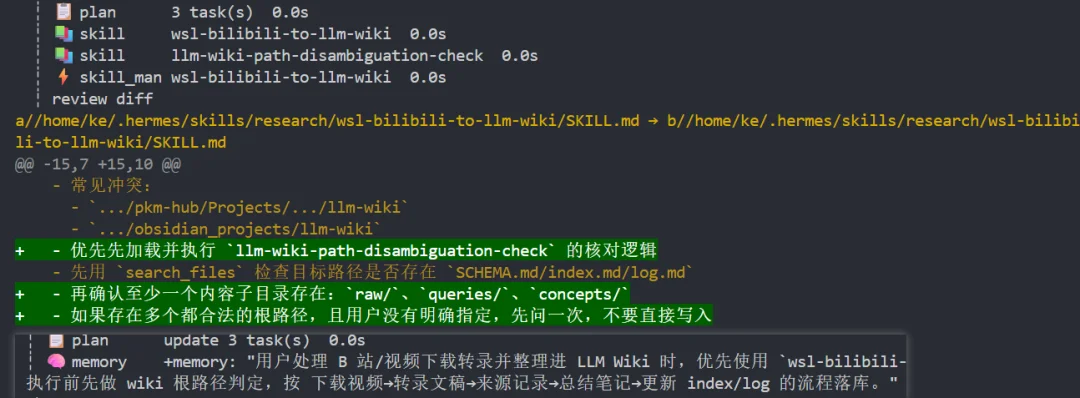
但 Skill 沉淀这件事对底层模型的要求其实不低。它需要模型准确理解每一步在做什么、哪些是通用步骤、哪些是当次特有的提示词,然后抽象成可复用的流程。如果模型长程推理能力不够,要么抽象得太浅,下次还是得重新写提示词;要么抽象得太死板,换个视频就跑不通。
官方说 K2.6 能不间断编码 13 小时、修改超过 4000 行代码,完成复杂系统的开发和优化,这种长程推理能力在知识管理场景里同样扛得住。处理一条完整链路「下载、转录、理解、提取、生成」,需要 K2.6 保持上下文连贯,理解视频内容的逻辑关系,还要按照 SCHEMA.md 里定义的规则输出结构化内容。每多跑一条素材,Skill 就更精准一点,整个工作流就越跑越顺。
处理完几个素材之后,知识库有了一定规模。这时候一般人整理笔记最头疼的问题就该出现了:越整越乱:新内容进来不知道放哪,旧笔记和新笔记讲的是同一件事却互相打架,最后堆成一个大杂烩。
但在 LLM Wiki 里,我看到的是相反的现象:知识库开始自己进化了。
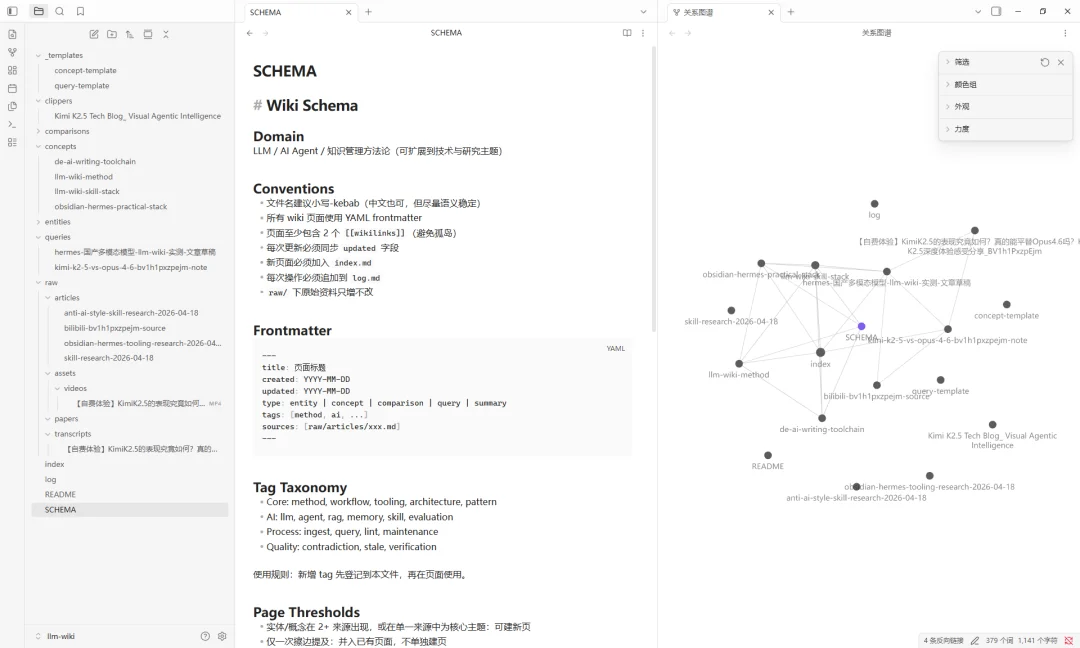
相关概念自动关联,重复信息自动合并,冲突观点并列记录。这套机制依赖 SCHEMA.md 里定义的规则:什么时候新建页面、什么时候并入已有页面、遇到不同视频对同一个概念有不同解释时怎么办。
规则定好之后,K2.6 每次处理新素材时都会照着执行。所以知识库不是死的,你塞进去的视频、文章越多,它自己就会长出关联。半年前看过的一篇文章,今天看到另一个视频讲同一件事,它能自己把两者关联起来。
这也是为什么底层模型很关键。SCHEMA.md 把规则写死了只是第一步,真正难的是每次处理新素材时,模型得一边读内容一边做判断:这块该归到 entities 还是 concepts?该新建页面还是并入已有的?元数据字段有没有填全?内部链接语法对不对?判断错一次,整个知识库就开始走样。K2.6 的长程推理能力在这种场景下就很有用:规则能稳定执行,结构化输出能严格按 SCHEMA 来,不会跑着跑着就格式乱了。
除了 B 站视频,我还使用了 Obsidian Web Clipper 把网页文章剪藏进来,流程和处理视频类似。K2.6 能准确识别文章里的专业术语、理解上下文的指代关系、生成符合中文习惯的摘要。
整个知识库的搭建也很简单。让 Hermes 初始化一个 LLM Wiki 项目,10 分钟后它建好了所有文件夹,还自动生成了 SCHEMA.md、index.md、log.md 这些核心文件。SCHEMA.md 里已经定义好了 tag taxonomy(标签分类体系)、页面阈值规则、更新策略,直接就能用。
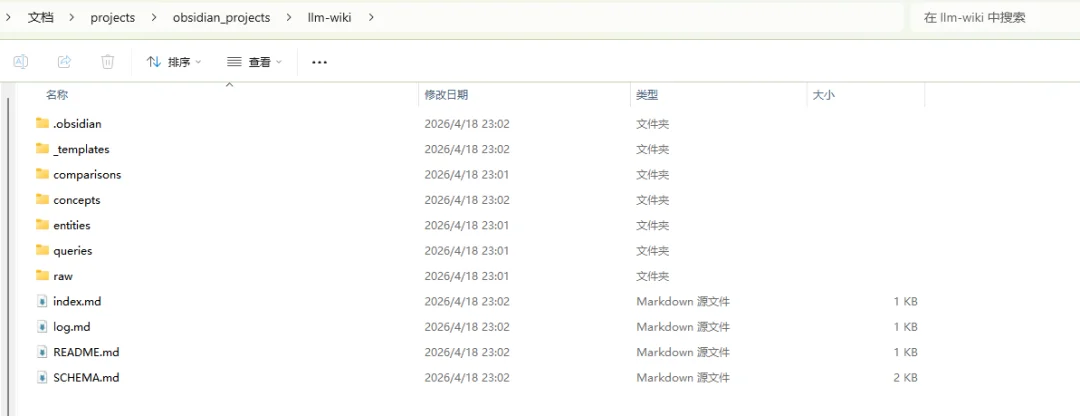

塞一篇文章进去是几分钟的事,但跑上几个月你会发现,这不是一堆散落的笔记,而是一个真正属于自己的、可追溯、可扩展的知识资产。
知识库只是 K2.6 能力的一部分。今天,我又看了看官方发布的其他案例,有个场景让我印象很深。
官方给了一个 Agent 集群的案例:针对全球 100 个半导体标的设计并执行 5 套量化策略,最终交付详尽的建模表格和一整套汇报演示文档。K2.6 的 Agent 集群从 K2.5 的 100 个子 Agent、1500 步,直接拉到了 300 个子 Agent、4000 步。

另一个案例更硬核:把一篇包含海量视觉数据的天体物理论文转化为可复用的学术技能,产出 40 页、7000 字的研究论文,以及包含 2 万多条数据的结构化数据集和 14 张天文级图表。
这种规模的任务,单个 Agent 根本搞不定。K2.6 会自动拆解任务、创建不同角色的子 Agent、让它们并行工作,最后把所有结果整合起来交付。从知识库到量化策略,从论文分析到数据可视化,K2.6 的能力边界比我用到的要宽得多。
当然 K2.6 也不是没有短板。一个是文笔相比 K2.5 退步了一些,输出经常中英文混着来,做中文知识库的时候得人工再顺一遍。另一个是上下文长度只有 256k,对比 GPT-5.4 的 1M 差了不少,Hermes 跑长链路任务时需要频繁压缩 memory,偶尔会因为压缩丢掉一些早期的上下文细节。

Kimi K2.6 现在可以通过 Kimi Code 免费试用:https://www.kimi.com/code
完整的保姆级教程我放在文章开头了,包括:
选个主题,建好文件夹,把现有内容扔进去,剩下的交给 Kimi K2.6吧!
文章来自于"Datawhale",作者 "筱可,Datawhale成员"。



【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
