# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

“这是我过去四个月一直在研究的东西!”
几个小时前,OpenAI 的 Image 2 成功反超 Google !
而这款上线即 SOTA 的文生图模型,直接在榜单上以碾压性的 242 分的优势超过了第二名 Nano Banana 2!
如此强悍的模型悄然而至,似乎一下让开年以来不断被 Anthropic 盖过风头的OpenAI,再次回到了舞台 C 位!
这这款模型背后,究竟是如何做到?本篇就带大家一探背后的技术实现路径。
随着 OpenAI CEO Sam Altman 的一场直播,大家开始注意到 Image 2 核心研发者:Boyuan Chen!
Chen 在帖子中爆料到:
这款模型研发周期持续了四个月。
直播一开场,Sam 就为这款模型给出了一个相当高的评价:就好像直接从GPT3跳到了GPT5一样!

Text-to-Image 项目中实现了完美统治,以创纪录的+242 分领先优势 - 这是迄今为止我们见过的最大差距。

这是 Image 2.0 最为让人惊艳的地方。
这是一个范式变化。用 Sam 的话来说:如果 DALL·E 是洞穴壁画,Image Gen 1 是古代艺术,那么 Image 2.0 就是文艺复兴。
简单理解,就是学前班画画水平跟专业设计师之间的区别!
这里之所以用了“文艺复兴”,其实一点也不夸张。大家只要简单回顾一下前两代模型的使用经历,再试一把
Image 2.0 就能明显感觉到代际差异。
先看下这个例子就知道了。小编考了一道中学生未必都能半分钟回答出来的问题:帮我在一张A4纸上用红色中性笔证明一下勾股定理。
Image 2 似乎理解了我所提的每一个概念要素:A4 纸、红色中性笔、勾股定理、证明。
结果就这么水灵灵的给出了一个几何证明题的作业纸。“白纸红字”,不服不行!

这就如同文艺复兴时期,人们开始走出原始表达和理想化审美的束缚,
开始系统地理解世界,并学会用科学方法去重建现实。
具体怎么触发这一功能?
只需要在 ChatGPT 里选 thinking 或 Plus、Pro 模型即可。然后你吩咐模型做图,模型就会做三件事:联网搜索实时信息、基于用户上传的文件生成可视化解释内容(一次产出最多 8 张连贯图)、图像生成前自我检查输出质量。

升级后的模型,作图过程也变得更加专业范儿:
先打个草稿,生成初稿中,搭好场景,打磨细节,收尾中,最后润色中,最后微调一下,创建完成。
下面这个例子,很好的体现了这一过程,在不同画面中保持人物、物体和风格的一致性。
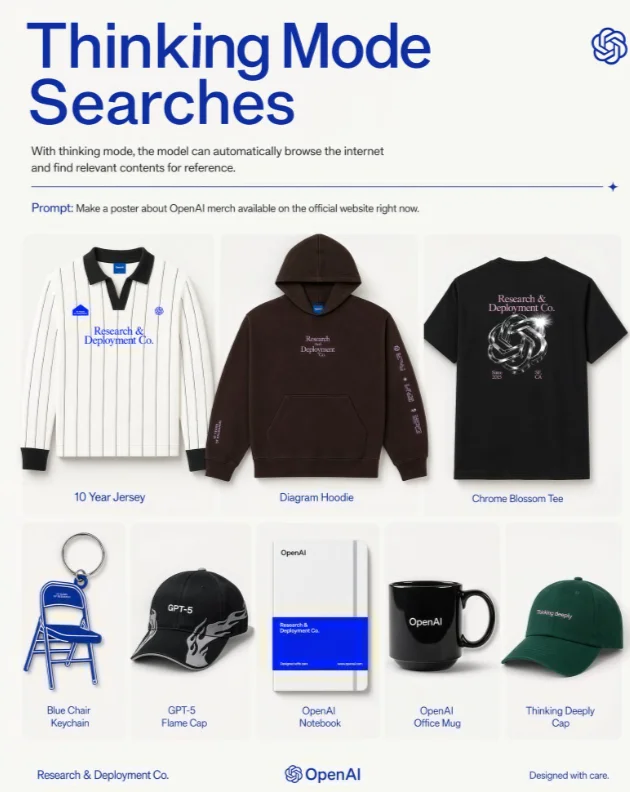
总结一下,OpenAI 这波释放了一个图像模型的演进方向:
模型不只是生成图像,它在“思考”。它可以进行研究,甚至能搜索网络,以最准确的信息生成图像。
基于这些能力,它可以生成解释复杂系统的信息图,甚至用带证明的方式解决数学问题。
OpenAI 表示,这将使生成漫画页面、社交媒体视觉内容系列,或整套家居设计方案变得更加容易。
比如,我们已经可以在毫无上下文背景的情况下,让 Image 2 生成一张流川枫三步篮的动作拆解图。
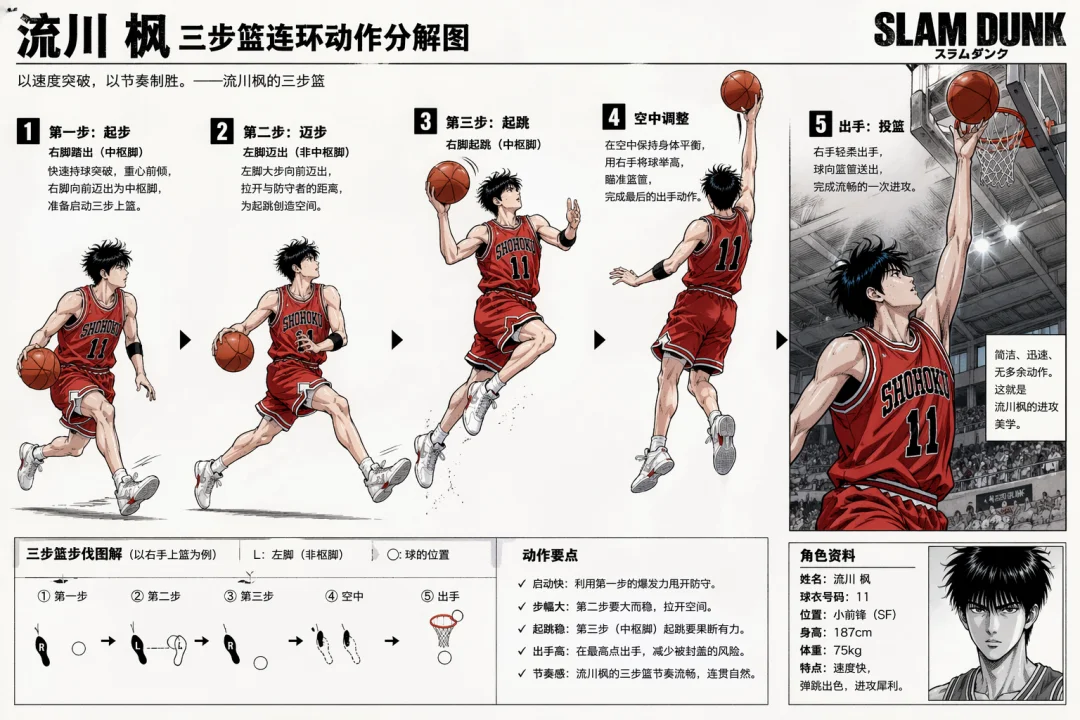
可以看出,原本需要专业体育+绘画知识的一张分解图,就这样被 OpenAI 分分钟秒出了。文本内容非常专业准确,而结构化的构图设计也非常合理,视觉布局能力也没的说。
毫无疑问,OpenAI 这次是真的瞅准了生产级环境的视觉内容。
目前,OpenAI Imagegen 团队研究员 Ayaan Haque (多说一嘴,前 Luma 团队成员),透露了一些工程信号:模型先做研究,再去做。
以前,如果你让图像模型去研究一个主题,它其实并不具备足够的世界知识,也缺乏各个领域的专业能力。
现在,它已经可以执行完整任务:先做研究,查看图片,找出它们之间的共性,还能生成多个相互一致的输出,把它们组织成一个完整的故事。

Sam 也在直播中表示:Image 2 在生成图像之前,会先进行一轮思考,甚至主动检索信息,再将结果组织成视觉画面。
图像不再是死板地依赖一句提示词直接生成,中间多了一层内容梳理的过程。
生成前进行推理、结构规划,并结合网络信息完成复杂图像任务
它会主动思考这些内容:哪些信息需要放进去、以什么顺序呈现、最终输出什么结构图片。
在团队成员演示过程中,曾提到了两处模型的自主思考点:
第一处,模型会自主决定文字的位置,保证整个图片设计布局的高完成度;
第二处,则是模型会在最终输出前检查自身生成的结果,以确保多张图片之间的一致性。
小编认为,虽然 OpenAI 短期不会公开背后的技术细节,但对于人才辈出的今天,很快就会有人“逆向”出来。
对此,不少业界分析也有质疑的声音,所谓的图像“thinking mode”,仍属于工程层面的推理增强,而非真正意义上的“思考”。
另一个值得关注的点是,Image 2 成功攻克了“多语言”文字显示的问题。
这可以说是无数创作者以前“心中最大的伤疤”之一了。
过去的图像模型常将文字视为“贴入画面的元素”,导致中文、日语等语言笔画变形或乱码,而新模型实现了“语言融入设计”——不仅保证字形准确,还能匹配字体选择、排版节奏与书写习惯,例如中文海报的留白和日文漫画的分镜逻辑。
官方测试案例显示,该模型能稳定处理密集文本场景:
在中文连环漫画中,连底部超小字号的注释“(此处为极小字号测试)无锡是作者的故乡”都清晰可辨;
在印度书店场景中,同时渲染印地语、孟加拉语等九种印度语言的书封文字,且语句通顺连贯。
Boyuan 还演示了自己让 Image 2 渲染成一篇论文的过程,这种高度密集的中英文混合小字排版,也被 OpenAI 成功接住了!
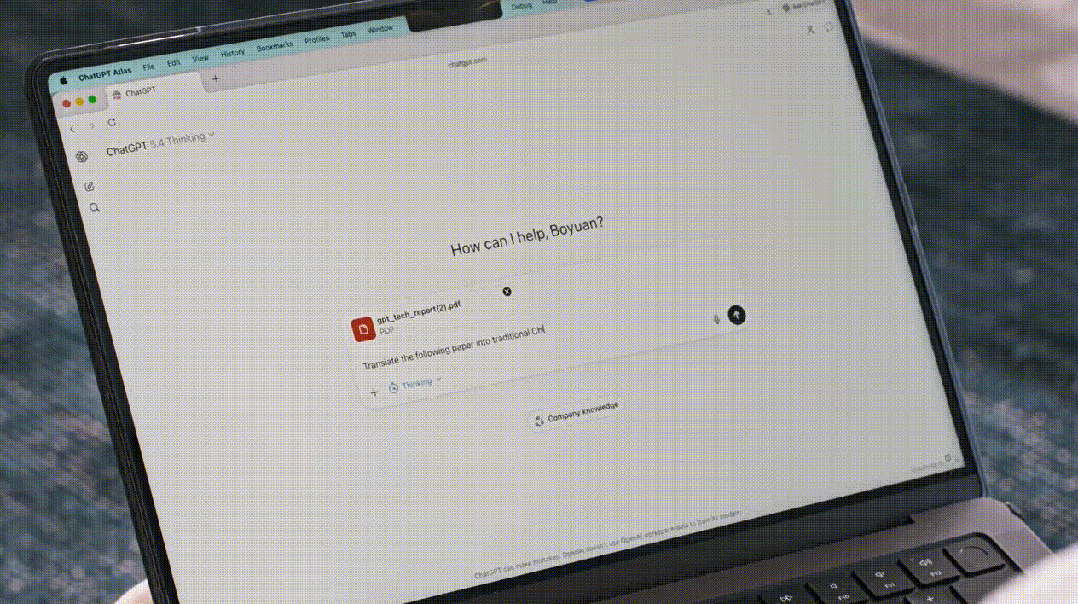
据悉,Image 2 之所以能够突破这个痛点,是源于模型对非拉丁语系语言的底层训练优化,而非简单的字符映射——它能理解文字的语义和排版规则,例如中文从左到右的阅读顺序、日语竖排文字的行距要求。
更关键的是,Image 2 将多语言能力与“思考模式”结合:生成前会分析语言特性、搜索字体参考(如中文宋体的笔画细节),再输出符合文化习惯的设计。
这意味着用户无需额外标注“使用黑体”或“竖排文字”,模型会自动适配——例如生成韩语广告时,标题会采用符合韩屋风格的手写字体,而非通用印刷体。
不要小看,这一层面的变化。
这种能力直接改变了内容创作流程:过去生成中文海报需在Photoshop中手动补字,现在模型可直接输出可用的文字图层。
更重要的是,对非英语市场的用户而言,更是大大的福音!之前事后再P“中文”的时代一去不复返了,跟英文一样成为了图像生成领域的“一等公民”。
指令遵循一直是创作者和设计者非常关注的细节能力,OpenAI 团队这次也在这方面下足了功夫。
实测显示,Image 2 对于构图、方位、时钟渲染问题都得了质的飞跃。
以时钟渲染为例,众所周知,以前很多模型对于生成时钟图片,都普遍存在一个问题:
即使你输入其他时间,它也很容易画成 10:10。

因为在现实中,钟表广告大多都会用 10:10 这个时间点,所以互联网上大量图片都是这个样子。
而这次 Image 2 解决了这个问题,结果对比非常明显。
小编实测问题如下:
生成一张Apple Watch S11 (钟表刻度盘)显示不同时刻的图片, 它画不同时间:5:15、9:10、10:59,最后一个是 12:45。
结果四个图中的指针位置全都精确地显示正确了。

目前公开的信息里,Image 2 支持非常灵活的输出尺寸调整,几乎覆盖了所有主流平台的图片尺寸。此外 API 端甚至支持高达 2K 分辨率输出,最大边长像素为 3840 px,总像素达 829 万。
要知道过去版本的模型,也只够支持固定的竖版、横版或者正方形。API 端最高仅支持 1K 分辨率。
小编整理了一张核心能力特点,如下:

包括超广角的“专业摄影”设置也能心领神会,那种轻微的扭曲感也达到了以假乱真的地步。

prompt:用超广角手法拍摄春天里的上海外滩

稻米上的小黑字清晰可见
不过,根据官方披露的信息,当前 Images 2.0 的高分辨率输出仍处于beta阶段,2K以上分辨率结果可能不稳定;同时对于折纸步骤图、倾斜面细节等需要完整物理世界模型的复杂场景,细节处理仍存在局限。
那么,如此灵活多变的尺寸,技术上如何实现的呢?
很明显,OpenAI 不会这么快就公开出来。 不过,结合当前图像生成领域的通用技术路径,Images 2.0 的可变像素输出大概率通过以下三种方式实现:
如果OpenAI后续公布更多技术细节,小编也会及时为大家跟踪解读。
这次 OpenAI 新版本的生图模型发布,可以看出几乎出动了整个OpenAI图像生成团队的核心成员。

作为 OpenAI 早期图像生成领域的研究者,Gabriel Goh 是这个部门的负责人。他在 X 上列出的参与名单就多达 20 位之多。
除了上文提到的 Ayaan Haque,这里为大家稍微介绍一下排名第二的 Boyuan Chen。
Boyuan Chen 可以说,属于新一代“多模态基础研究者”的典型代表。他现任 OpenAI 研究科学家,参与了 GPT 图像生成等核心项目。

Boyuan Chen 博士毕业于 MIT(EECS,辅修哲学),本科就读于 UC Berkeley。
他的研究聚焦于“世界模型”、具身智能与强化学习,核心目标是让 AI 不只生成内容,而是理解环境、预测变化并与现实世界交互。
而另一位演示的东方面孔:Yuguang Yang。 同样也是 OpenAI 图像生成团队的研究员,参与了 ChatGPT Images 2.0 等核心项目的研发。

他这次的工作和演示重点集中在将复杂信息转化为高质量视觉内容,例如生成信息图、将 PDF 转换为幻灯片或海报等,推动图像模型从“生成图片”向“表达结构化信息”演进。

可以看出,Yuguang 更接近“应用与研究的交叉层”,既理解模型能力边界,又负责将其转化为可用工具。这个方向正成为 AI 产品化落地的重要推动力量。
整体看下来,如果我们对比 Midjourney、Image1.5、NanoBanana,不难看出 OpenAI 这帮硬核且且灵动研发团队,又一次把生图智能向前推进了一步!
Image 2 给出了2026版本的新定义:
首先,让“AI生图”变成一场结构化推理的设计过程,充分利用大模型所掌握的领域能力,
其次,给用户更多的控制权,像素尺寸可以自由选择、不同创作场景都能实现专业的图文排版设计。
其三,非常擅长理解用户意图,即便很短的提示,也能抓到重点完美呈现。
就好比小编,随手丢的一句海报设计提示词,我连具体文案都没有给到它:
为明星沈腾设计一张时代周刊封面。
Image 2 给出的结果相当“暖心”:
用笑声链接时代,用作品温暖人心
The Power of Joy:沈腾如何重新定义喜剧,并成为文化符号

大家看下,这种地步的封面设计,你会打几分呢?
有了它,谁还会再去找图片模版去一点点复制粘贴素材呢?
参考链接:
https://www.youtube.com/watch?v=B4r4t9eIwNI
https://x.com/OpenAI/status/2046670977145372771
https://x.com/BoyuanChen0/status/2046678444042596581
文章来自于"51CTO技术栈",作者 "云昭"。


【开源免费】ai-comic-factory是一个利用AI生成漫画的创作工具。该项目通过大语言模型和扩散模型的组合使用,可以让没有任何绘画基础的用户完成属于自己的漫画创作。
项目地址:https://github.com/jbilcke-hf/ai-comic-factory?tab=readme-ov-file
在线使用:https://aicomicfactory.app/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
