# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
过去24小时,大家过得好吗?
反正我的开发朋友们过得不太好:DeepSeek V4、GPT-5.5、小米MiMo V2.5、腾讯Hy3,接连四款模型发布,大家测完你的测你的,测完这个测那个……
忙就不说了,主要是现在的新模型,上下文长度起步就是1M,基本上几轮测试结束,账单就已经要爆了。
那么,有什么办法在不降低大模型输出质量的情况下,减少模型的 Token 消耗?
欢迎大家尝试前不久GitHub的日榜榜首项目——Claude Context。
https://github.com/zilliztech/claude-context
通过在AI coding场景引入混合检索,Claude Context相比使用grep的原生 Claude Code 能大幅提升检索精度和效率,减少约 40% 的 不必要Token 消耗。
那么它是如何工作的,我们要怎么使用它,本文将一一解读。
理解Claude Context的价值之前,我们需要先理解多数AI coding软件,他们是怎么工作的。
AI coding软件能够精准构建生产级代码的前提,除了强大的推理能力之外,还依赖于它对我们代码库中历史代码的精准理解,知道其中的函数调用逻辑,了解我们想要的内容会和历史代码中的哪一部分相关。
而关于如何做好代码检索,行业大致可以分为RAG类与grep类这两类,其中前者的代表是Cursor,后者的代表则是Claude Code。
两者的区别则在于,RAG主要借助于语义+关键词的混合检索做内容理解,而grep主要依靠单纯的字面匹配。
这就导致,在Claude Code类方案中,检索不仅召回率低,还会检索出大量不相关的内容,整个过程不仅效率低下,还极其耗时费力。
比如,我让 Claude Code帮找 bug ...结果,它反复使用 grep + read file tools,猜测可能的关键字,不断查找读取大量文件。1 分钟后,收获依然为0。
然后,通过一些提示和补充来指导帮助,Claude Code经过了整整 5 分钟,才终于定位到了问题文件。
但是问题是,它读取的文件中,只有 10 行代码是和这个 issue 相关的,其他 99% 的代码都是无关的。在这个反复对话和读取大量无关代码的过程中,Token 浪费不说,还浪费了大量宝贵的时间。
当然,遇到类似问题的,不止我一个,可以看到,有不少人都给 Claude Code 也提出过类似的 issue
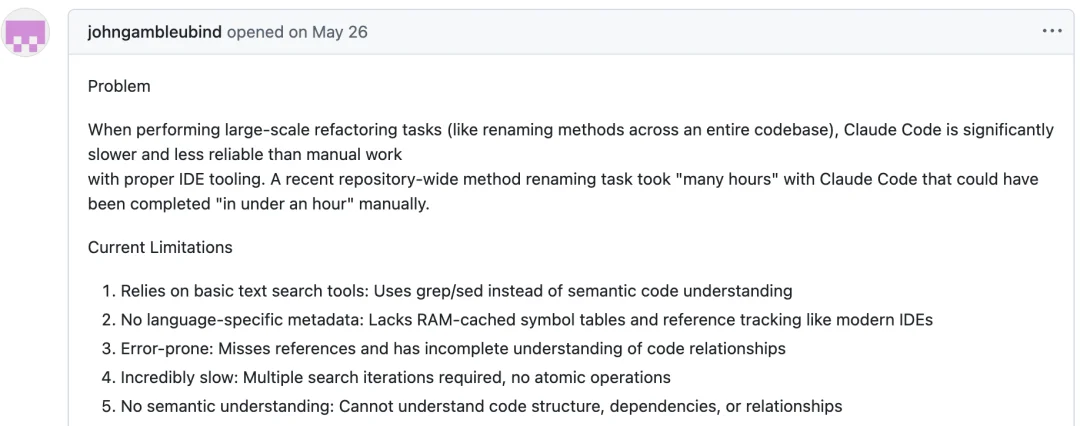
总结来说,纯grep方案主要有三大问题:
而之所以知道问题所在,但还是坚持使用grep,对Claude Code来说,一方面是技术路线的选择问题,另一方面,要搞好代码检索,里面有大量工程细节需要处理。如,代码如何切分?代码变动了怎么办?索引和检索速度怎么保证?怎么为海量的代码的 embedding 建立索引?
显然,这些都与 Claude Code 【简单】【无界面的 CLI】的定位相违背。更关键的是,embedding 模型和向量数据库也不是 Anthropic 的强项。
这也是我们为什么要做Claude Context,并且把它开源的原因:
https://github.com/zilliztech/claude-context
这是一个集成了向量数据库和 embedding 模型的开源代码检索 MCP 工具,可以无缝集成到 Claude Code 中,同时也兼容其他 AI Coding IDE,让 LLM 获得更优质、更准确、更低成本的上下文信息。
此外,针对纯grep方案的三大致命缺陷,Claude Context 分别做了专项突破
以下是个Claude Context方案实现全过程
🔌 接口层面:MCP
MCP 就像是 LLM 与外界交互的USB,可以把产品能力以 MCP server 的方式提供出来,这样不仅是 Claude Code,甚至其他 AI IDE 比如 Gemini CLI、Qwen Code 等都能用。
Zilliz Cloud 是全托管的 Milvus 向量数据库服务,具备高性能向量搜索、高 QPS 与低延时、云原生架构带来的弹性扩展和无限存储等特性,还有多副本增强可用性,简直是为 Codebase Indexing 量身定制的。
其他 embedding 模型,持续支持
在 Python 和 TypeScript 之间纠结了一下,最终选择 TypeScript。原因很简单:它更兼容应用层,开发的模块可以无缝集成到高层的 TypeScript 应用中,比如 VSCode 插件等。而且 Claude Code、Gemini CLI 等也都是用 TypeScript 写的,生态更友好。
从解耦、分层的设计原则角度来看,它的架构被设计成了两层:
核心模块:包含所有核心逻辑,里面每块的逻辑也是分开设计的,比如代码解析、向量化索引、语义检索、同步更新等。
上层模块:包含 MCP、vscode 插件等集成。它基于核心模块,更多是包含一些应用层的逻辑,尤其是 MCP,它是与 Claude Code 等 AI IDE 交互的最佳方式。
这样设计的好处是,核心模块可以被上层模块复用,后续不管是横向还是纵向,都很容易扩展其他模块。
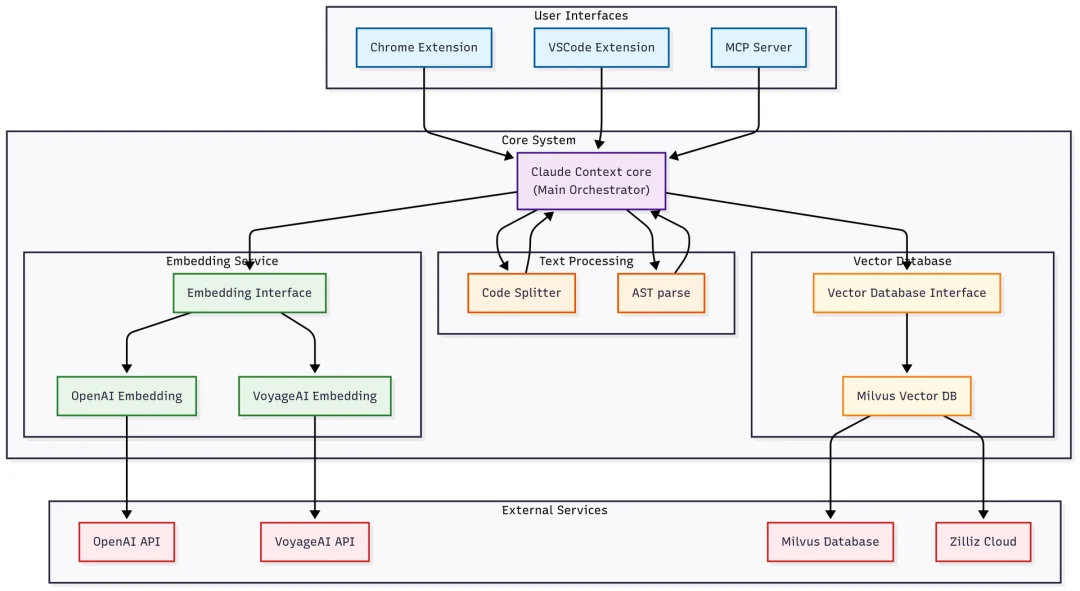
核心模块是地基,地基打好了才能盖好房子。核心模块其实就是要把向量数据库、embedding model 等抽象成一些模块,它可以组成一个 Context 对象,这样我就可以在不同的场景下使用不同的向量数据库和 embedding model。
import { Context, MilvusVectorDatabase, OpenAIEmbedding } from'@zilliz/claude-context-core';
// Initialize embedding provider
const embedding = newOpenAIEmbedding(...);
// Initialize vector database
const vectorDatabase = newMilvusVectorDatabase(...);
// Create context instance
const context = newContext({embedding, vectorDatabase});
// Index your codebase with progress tracking
const stats = await context.indexCodebase('./your-project');
// Perform semantic search
const results = await context.semanticSearch('./your-project', 'vector database operations');
上文说完了Claude Context的基本架构,接下来,我们还需要针对AI coding场景中的一些常见问题做一些优化,比如怎么针对代码做chunk,以及代码实时更新,我们怎么为其构建合适的索引?
以下是解决方案
代码切分这个问题,不能简单粗暴地按行切分或者按字符切分。那样切出来的代码块,要么逻辑不完整,要么上下文丢失。为此,我设计了两套互补的切分策略:
这是默认和推荐策略。通过解析器,理解代码的语法结构,按照语义单元进行切分。
AST 切分的好处显而易见:
语法完整性:每个 chunk 都是完整的语法单元,不会出现函数被切成两半的尴尬情况
逻辑连贯性:相关的代码逻辑会保持在同一个 chunk 中,AI 搜索时能找到更准确的上下文
多语言支持:针对不同编程语言使用不同的 tree-sitter parser,无论是 JavaScript 的函数声明、Python 的类定义、Java 的方法,还是 Go 的函数定义,都能被准确识别和切分
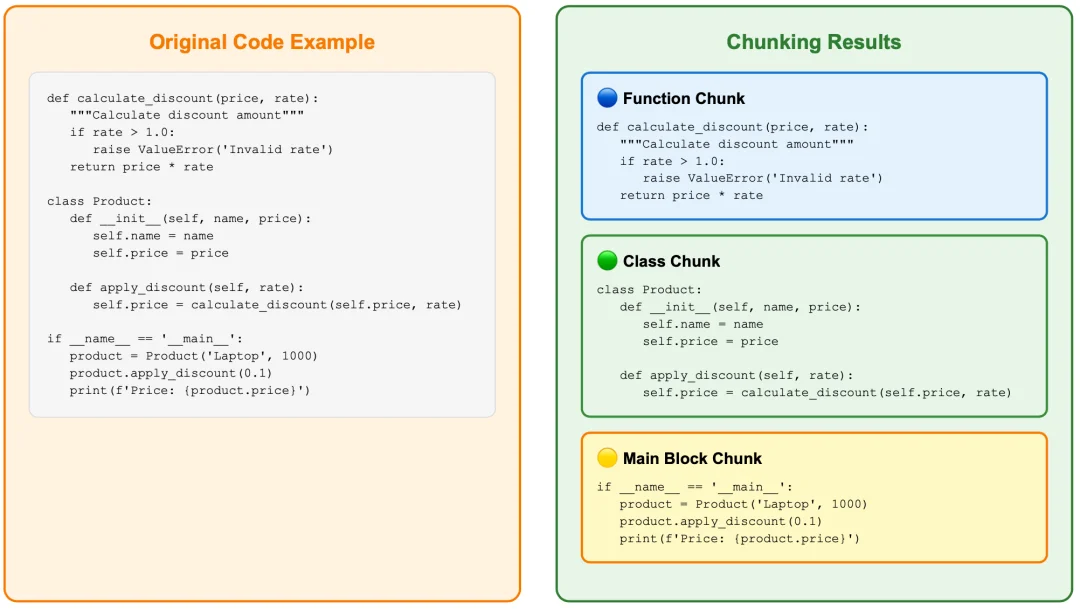
对于 AST 无法处理的语言或者解析失败的情况,可以用 LangChain 的 RecursiveCharacterTextSplitter 作为备用方案。
// 使用递归字符切分,保持代码结构
constsplitter = RecursiveCharacterTextSplitter.fromLanguage(language, {
chunkSize: 1000,
chunkOverlap: 200,
});
这种策略虽然没有 AST 那么智能,基本就是按照字符数量进行切分,但胜在稳定可靠。任何代码都能被正确切分,不会让你抓瞎。
这样的双重保险设计,既保证了代码的语义完整性,又兼顾了不同场景的需求。
代码变动处理一直是代码索引系统的核心挑战。想象一下,如果每次文件有微小改动就要重新索引整个项目,那简直是灾难。针对这个问题,我设计了一套基于 Merkle Tree 的同步机制来解决这个问题。
Merkle Tree 就像一个层层递进的"指纹"系统:
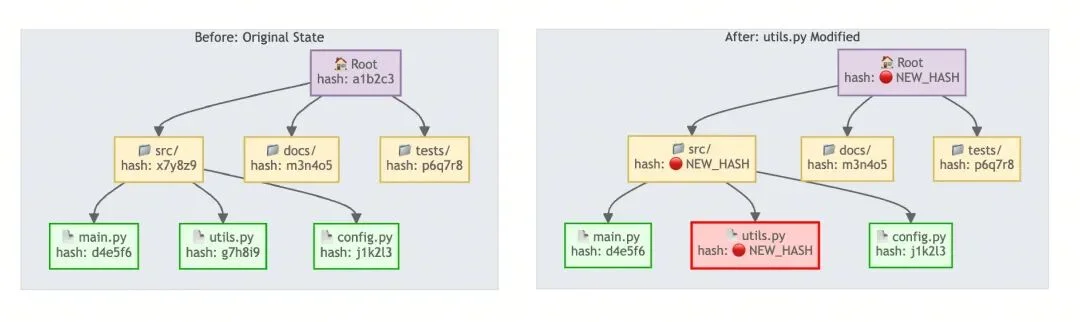
只要文件内容有变动,其上层的哈希指纹就会层层变化,直到根节点。
这样,不用重新索引整个项目,就可以从根节点往下,逐层对比哈希指纹的变化,快速感知和定位文件的变动。
默认 5 分钟进行握手同步检测一次,同步机制分为三个阶段:
计算整个代码库的 Merkle 根哈希,和上次保存的快照对比。如果根哈希一样?恭喜,什么都没变,直接跳过!几毫秒搞定。
如果根哈希不一样,那就进入精确对比模式。做文件级别的详细对比,找出到底哪些文件发生了变化,比如新增的文件、删除的文件、修改的文件。
只对变化的文件重新计算向量,然后更新到向量数据库中。
所有的同步状态都保存在用户本地的 ~/.context/merkle/ 目录中。每个代码库都有自己独立的快照文件,里面包含了文件哈希表和 Merkle 树的序列化数据。这样即使程序重启了,也能准确恢复之前的同步状态。
整套设计带来的好处真的很明显。大部分情况下几毫秒就能确定没有变化,只有真正变化的文件才会被重新处理,避免了大量无效计算。而且即使你关掉程序重新打开,状态也能完美恢复。
用户体验上,这意味着当你修改了一个函数后,系统只会重新索引这个文件,而不是整个项目,大大提升了开发效率。
套方案在实际使用中表现如何呢?实测看看就知道了:
安装使用超级简单,只需要在 Claude Code 运行前,执行一行命令:
claude mcp add claude-context -e OPENAI_API_KEY=your-openai-api-key -e MILVUS_TOKEN=your-zilliz-cloud-api-key -- npx @zilliz/claude-context-mcp@latest
这里的测试场景,还是选择让它找之前的那个代码中的 bug。先 index 当前的 codebase,然后要求它定位这个指定描述的 bug。
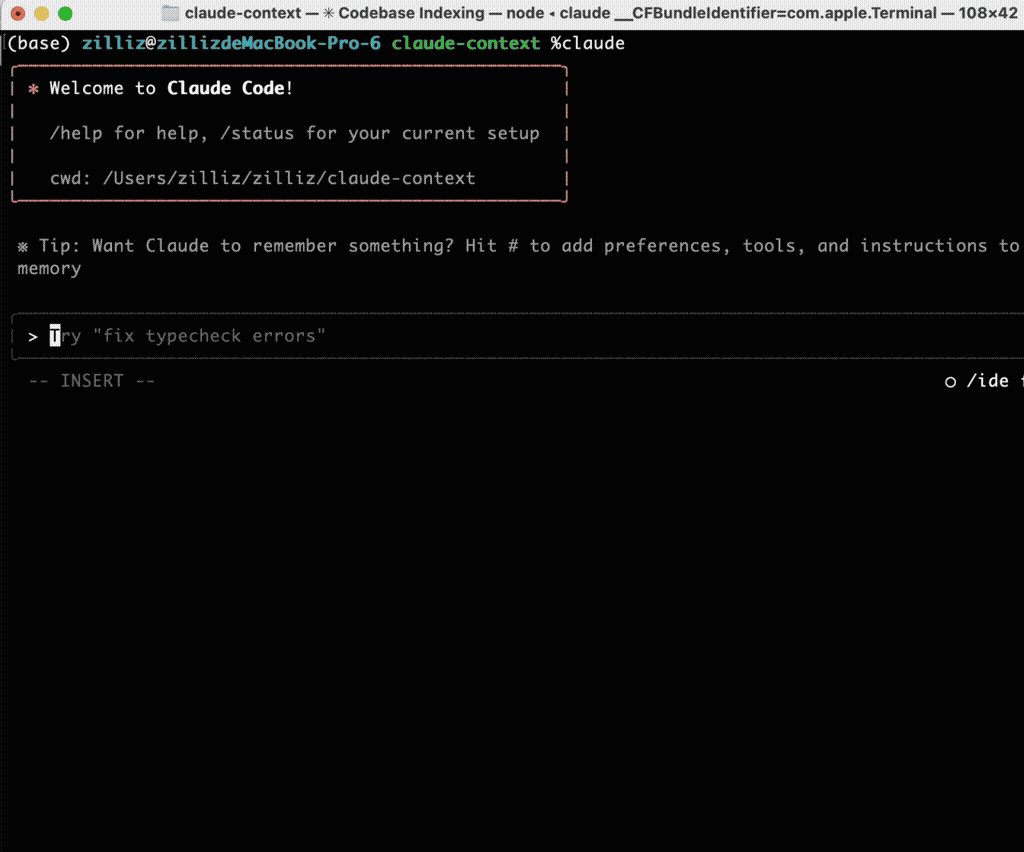
可以看到,通过 claude-context MCP tool 的调用,它成功找到了代码中指定 bug 的文件和行号,并且给出了详细的解释。
当然,不只是能做bug检索,只要配上了这个 claude-context MCP,Claude Code 在很多场景下都能触发调用它,获得更优质、更准确的上下文信息,比如 Issue 修复、代码重构 、重复代码检测、代码测试,等等。
另外,很多朋友想要看看 benchmark 定量测评,测一下 claude-context 能给AI IDE带来多少定量提升。
目前我已经做了一些相关的测试和实验,可以看到,在同等召回率的情况下,使用 claude-context,与不使用它的效果相比,可以大幅减少 40% 以上的 Token 消耗。
这同时也意味着 40% 以上的时间,和金钱的节省。
换句话说,在同等有限的 Token 消耗的条件下,使用 claude-context MCP 后,可以获得更好的检索效果。
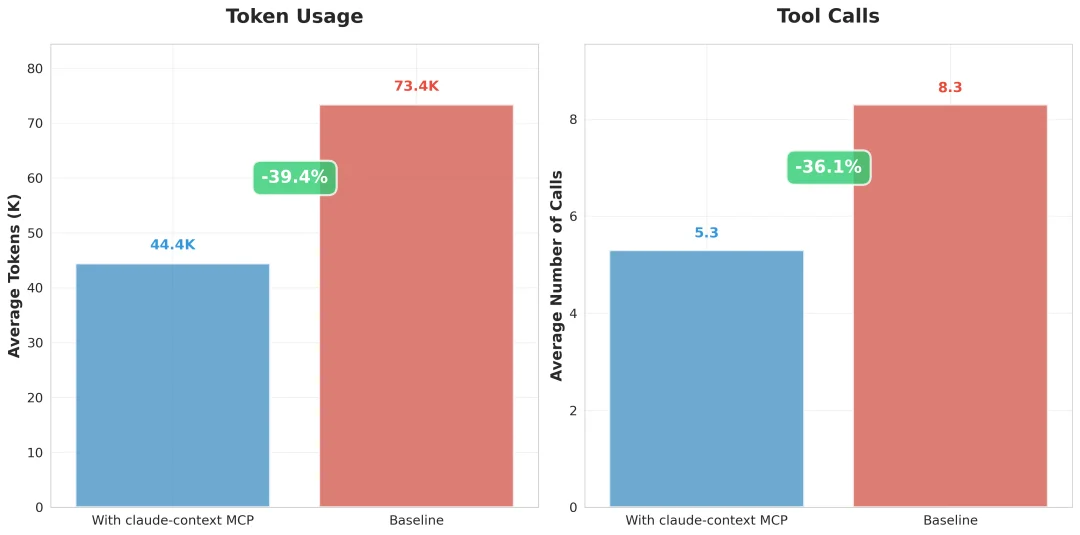
更多测试细节已经在 github 仓库中更新。
claude-context 也已经开源,并在GitHub上获得了九千 star,如果对你有帮助,欢迎使用和推荐。
https://github.com/zilliztech/claude-context
https://www.npmjs.com/package/@zilliz/claude-context-mcp
这里选择了两个案例,来展示下纯grep 方法与基于混合检索的RAG方案的能力差。
Issue 地址为
问题描述:Django 框架中,YearLookup查询优化破坏了__iso_year过滤功能。当使用__iso_year过滤器时,YearLookup类错误地应用了标准的 BETWEEN 优化,这对日历年有效,但对 ISO 周编号年无效。
#这应该使用 EXTRACT('isoyear' FROM ...) 但错误地使用了 BETWEENDTModel.objects.filter(start_date__iso_year=2020)
# 生成: WHERE "start_date" BETWEEN 2020-01-01 AND 2020-12-31
# 应该是: WHERE EXTRACT('isoyear' FROM "start_date") = 2020
Baseline grep 方法的过程日志分析:
🔧 directory_tree()
⚙️ 结果: 检索了 3000+ 行目录结构 (~50k tokens)
问题: 大量信息过载,没有直接相关性
🔧 search_text('ExtractIsoYear')
⚙️ 结果: 在多个文件中找到 21 个匹配项:
- django/db/models/functions/__init__.py:5 (导入语句)
- django/db/models/functions/__init__.py:31 (导出列表)
- django/db/models/functions/datetime.py:93 (ExtractIsoYear 类)
问题: 大多数都是无关的导入和注册
🔧 edit_file('django/db/models/functions/datetime.py')
⚙️ 修改了多个注册语句,但这是错误的解决方向
关键问题:文本搜索专注于错误的组件(ExtractIsoYear 注册),而不是实际的优化逻辑(YearLookup 类)。
Claude Context 方法的过程日志分析:
🔧 search_code('YearLookup')
⚙️ 为查询找到 10 个结果: "YearLookup" 在代码库中
1. 代码片段 (python) [repo__django__django]
位置: django/db/models/lookups.py:568-577
上下文: YearExact 类与 get_bound_params 方法
2. 代码片段 (python) [repo__django__django]
位置: django/db/models/lookups.py:538-569
上下文: YearLookup 基类与 year_lookup_bounds 方法
🔧 edit_file(django/db/models/lookups.py)
⚙️ 成功修改了核心优化逻辑,添加 ISO 年处理
关键成功逻辑:语义搜索立即理解了"YearLookup"作为核心概念,找到了需要修改的确切类。
效率对比:
Baseline 方法:8 次工具调用,消耗 130,819 tokens,0% 命中率
Claude Context:3 次工具调用,消耗 9,036 tokens,50% 命中率,节省了 93% 的 Token!
Issue 地址为
问题描述:Xarray 库的 .swap_dims() 方法意外修改了原始对象,违反了不可变性期望。在某些情况下,.swap_dims() 修改原始对象而不是返回新对象。
import numpy as npimport xarray as xrnz = 11ds = xr.Dataset({ "y": ("z", np.random.rand(nz)), "lev": ("z", np.arange(nz) * 10),})
这不应该修改 ds,但实际上修改了ds2 = ds.swap_dims(z="lev").rename_dims(lev="z").reset_index("lev").reset_coords()ds2.swap_dims(z='lev') # 这意外地修改了 ds2['lev']# ds2['lev'] 现在有维度 'lev' 而不是 'z'
Baseline grep 方法的过程日志分析:
🔧 list_directory('repo__pydata__xarray')
⚙️ 结果: 检索了多个子目录的目录结构
问题: 基本的目录导航,没有目标搜索
🔧 search_text('swap_dims')
⚙️ 结果: 在核心文件中找到 21 个匹配项:
- xarray/core/common.py:600 (Dataset.swap_dims 引用)
- xarray/core/dataarray.py:753 (".rename() or .swap_dims() instead.")
- xarray/core/dataarray.py:2026 (DataArray.swap_dims 引用)
- xarray/core/dataarray.py:2044 (def swap_dims 方法)
问题: 在不同上下文中有许多匹配项
🔧 read_file('xarray/core/dataarray.py', offset=2000, limit=40)
⚙️ 结果: 读取了显示 rename 方法文档的第 2001-2040 行
🔧 read_file('xarray/core/dataset.py', offset=3600, limit=40)
⚙️ 结果: 读取了显示 rename_dims 方法的第 3601-3640 行
低效原因:使用了大量的 list_directory 和 read_file 操作,而不是专注于相关方法。
Claude Context 方法的过程日志分析:
🔧 search_code('.swap_dims()')
⚙️ 为查询找到 10 个结果: ".swap_dims()" 在代码库中
1. 代码片段 (python) [repo__pydata__xarray]
位置: xarray/tests/test_formatting_html.py:67-76
2. 代码片段 (python) [repo__pydata__xarray]
位置: xarray/tests/test_dataset.py:2926-2979
🔧 edit_file('xarray/core/dataset.py')
⚙️ 成功修改文件,添加了维度处理逻辑
🔧 edit_file('xarray/core/dataarray.py')
⚙️ 成功修改文件,确保不修改原始 DataArray
关键成功逻辑:语义搜索立即定位了实际的swap_dims()实现并理解了功能上下文。
效率对比:
Claude Context不仅适用于Claude Code,同样适用于 Codex、 Gemini CLI、Cline在内几乎所有AI coding产品,欢迎大家多多体验与反馈。
https://github.com/zilliztech/claude-context
完整的实验数据、代码和复现方法都在项目的 evaluation/ 目录中开放。

文章来自于微信公众号 "Zilliz",作者 "Zilliz"


【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
