# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

阿里旗下HappyHorse(快乐马)、HappyOyster两款模型爆红出圈,发布未满一月,字节就悄然出手正面应战。
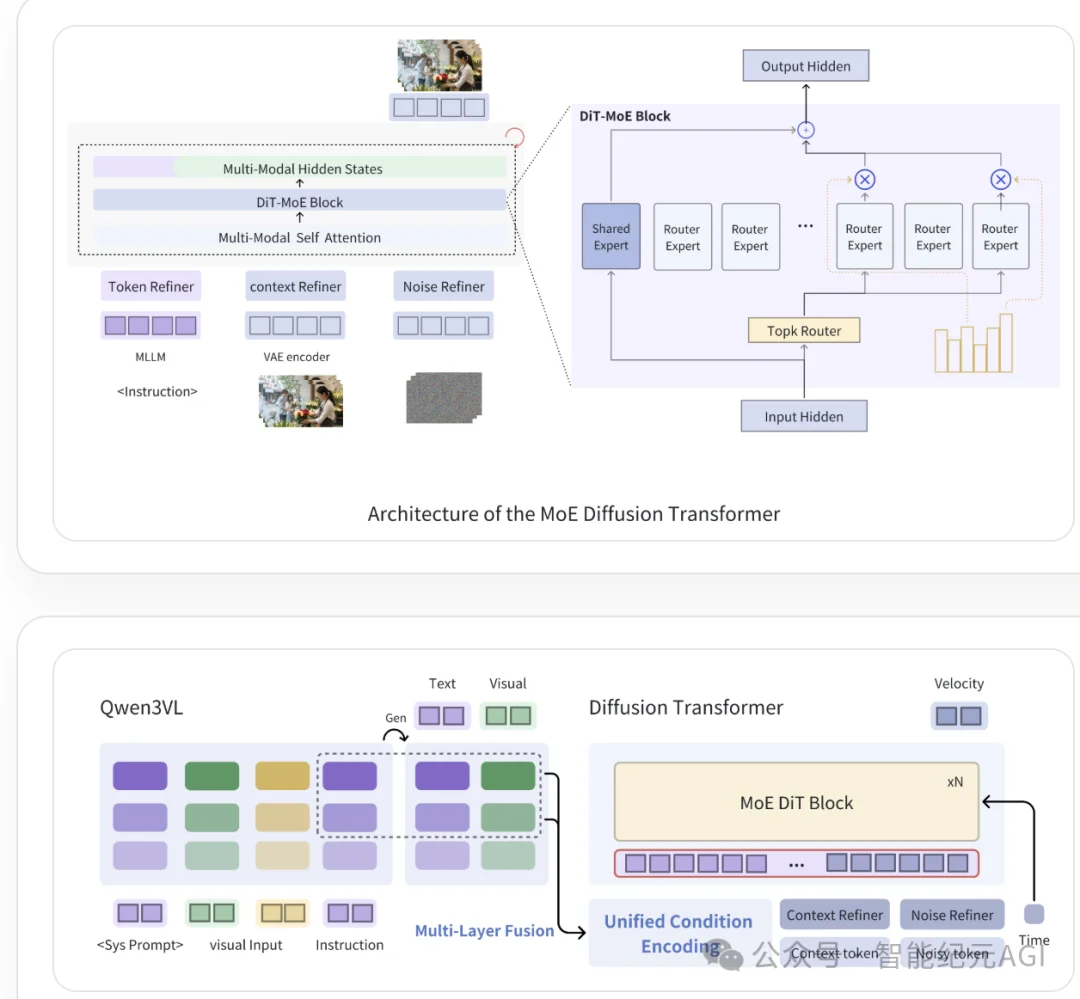
5月6日消息,智能纪元AGI独家获悉,字节跳动日前低调公布全球首个25B级、基于混合专家 (MoE) -扩散自注意力机制(DiT) 的开源增强统一多模态模型Mamoda2.5。
Mamoda2.5依托Qwen3-VL-8B、128 个专家,Top-8 路由的MoE+DiT架构搭建,最终模型参数高达250亿,而每次仅激活约30亿参数(约12%)。
基于稀疏激活优势,单设备下,Mamoda2.5模型推理速度比阿里Wan2.2 A14B快12倍以上,比美团LongCat Video快18倍。
视频编辑层面,新的Mamoda2.5模型采用4步方案,将编辑延迟降至仅9.2秒,比VInO快95.9倍,比OmniVideo2快41.7倍。
同时,统一视觉生成与编辑层面,Mamoda2.5将多模态理解、生成和编辑结合在一起,形成统一多模态模型架构。
所以,该模型仅激活3B参数,就实现文生图、文生视频、文生图像、视频编辑全任务SOTA,模型性能接近闭源的Sora和快手Kling。

谷歌Omni全模态还没登场,阿里快乐马刚刷屏完圈,字节直接甩出Mamoda2.5开源王炸。
这波操作太明显了:
不管是谷歌、阿里还是字节,最终路线全都指向同一个终点:
开源+统一全模态。
谁能想到,曾经各走各路的AI巨头,如今竟在同一条赛道上彻底会师。
追成本和速度优势,新模型实现95.9倍提速
事实上,统一的视觉模型正在经历从“单任务专家”到具备理解与生成能力的集成系统的范式转变。
然而,目前大多数统一的模型聚焦于图像领域,主要将视觉理解与图像生成和编辑相结合。
虽然这些模型在静态视觉生成方面取得了显著进展,但针对视频生成和编辑的统一框架仍处于早期阶段,主要受限于数据复杂性和计算瓶颈。
从专业视频生成模型的角度看,HunyuanVideo和WanVideo表明,在DiT范式内扩展参数能显著提升视频质量和对现实世界物理规律的建模能力。
而工业级系统如Aquarius进一步验证了在生产环境中部署大规模视频生成的可行性。
领先的闭源模型如Sora被认为参数规模可达数十亿甚至更高。
然而,视频任务本质上是计算密集型:视觉Tokens数量随空间分辨率和时间长度同步增长,而DiT对这些tokens的全注意力计算带来二次方成本。
因此,训练和推理成本随着模型规模和视频长度的增加急剧上升,使得高质量、长时视频生成在稠密架构下的实际部署变得极其昂贵。
为了解决规模扩展带来的质量提升与时空建模爆炸式计算成本之间的矛盾,专家混合(MoE)提供了一种可扩展的解决方案。
实际上,大型语言模型已成功采用路由机制实现稀疏激活,在不成比例增加计算成本的情况下扩展能力。
DeepSeekMoE的细粒度专家分割进一步增强了专业化与可扩展性。MoE在图像生成中也展现出巨大潜力。
例如,DiT‑MoE成功将扩散Transformer扩展至数十亿参数,而Race‑DiT和DiffMoE优化了路由策略,进一步提升了生成质量和训练效率。
在视频领域,WanVideo 2.2探索了一种粗粒度的双专家MoE,通过去噪时间步进行路由。

然而,细粒度MoE在视频生成中尚未得到系统性研究。
与此同时,以现有生成模型为基础进行高质量视觉编辑已成为一个关键的研究焦点。
在图像编辑领域,获取配对数据的相对简易性推动了快速进展,近期的闭源和开源模型已取得了强劲成果。
相比之下,视频编辑仍处于早期阶段,这主要源于构建高质量配对训练数据的复杂性,以及生成效率的挑战,显著增加内存占用和推理延迟。
基于这些观察,团队推出统一的自回归‑扩散(AR–Diffusion)框架模型Mamoda2.5,核心就是:显著降低了训练成本,同时扩展了模型容量。
该 AR-Diffusion 框架以 Qwen3-VL-8B 多模态理解模型为底座、MoE DiT 为生成骨干网络,既引入高效细粒度 MoE 架构,又实现了视觉生成与编辑任务的统一。
尽管总参数量规模达25B,但模型每次前向传播仅激活约3B参数。这种极致的稀疏性带来了卓越的训练和推理效率,直接应对了视频生成模型中固有的高昂时间复杂性挑战。
新的Mamoda2.5模型,30步编辑模型比VInO的推理速度快12.8倍;而精简后的4步模型则将编辑延迟降至仅9.2秒,比VInO快95.9倍,比OmniVideo2快41.7倍。
下面是基准测试。
字节Mamoda团队昨日公布的技术报告显示,在VBench 2.0测试中,Mamoda2.5视频生成方面达到61.64分,与腾讯HunyuanVideo 1.5和美团LongCat-Video水平相当,延迟仅为110秒,快于Wan2.2,称是“顶级开源模型水平”。
而视频编辑方面,Mamoda2.5模型达到了SOTA水平:在OpenVE-Bench测试中排名第一,超越快手可灵Kling O1;在FiVE-Bench测试中排名第一,达87.41分,并在Reco-Bench测试中整体表现最佳——所有这些测试的推理速度都比同类编辑基线快约10倍。
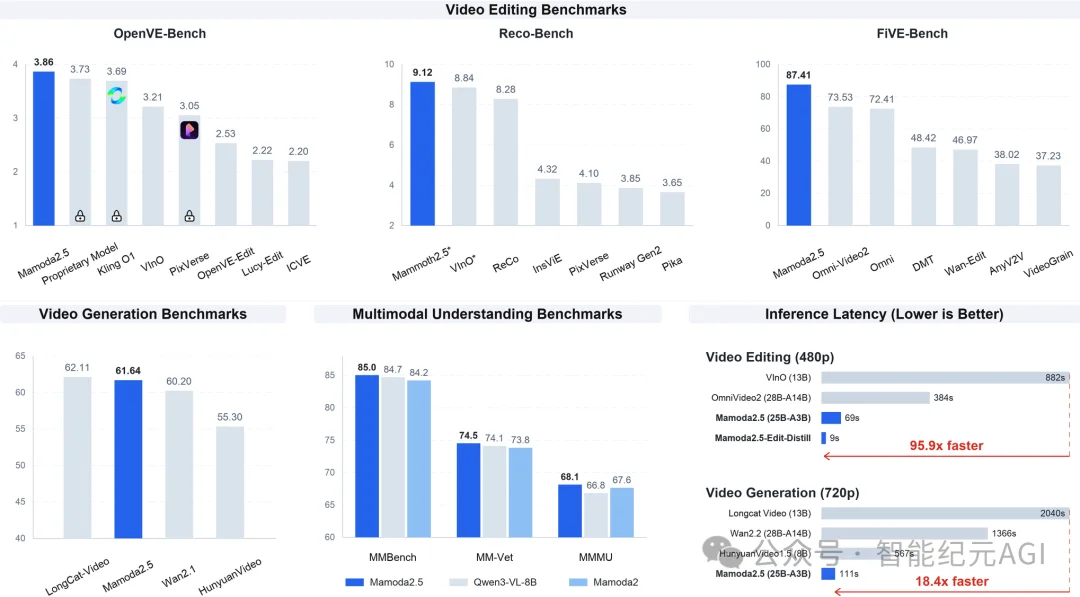
值得一提的是,此次Mamoda2.5引入了一个联合的少步蒸馏和强化学习框架,将30步编辑模型压缩为4步模型,极大地加速了模型推理。
因此,视频编辑速度层面,Mamoda2.5模型相比上交&快手&南洋理工VinO模型最高提升95.9倍,同时保持顶尖多模态理解能力。
真实世界被颠覆了
下面欣赏几个案例:
把人变成树人。

将马换成冰马。

将手变成机械手

编辑天气环境,从夏天到冬雪天。

编辑性别,从男生视频生成为穿同样衣服的女生。

当然还支持文字转视频能力。
Mamoda 团队表示,该模型具备一流的文生视频生成效果,推理速度比同规格稠密模型快 12 倍以上。

更多案例推荐你们到官方GitHub上看。
团队透露,在实际应用中,Mamoda2.5已成功部署于广告场景的内容审核和创意修复任务中,在内部广告视频编辑场景中取得了98%的成功率。
总结
今年4月,阿里ATH创新事业部团队连续发布了两个爆火的多模态开源模型:
HappyHorse(快乐马)和可实时构建和交互的世界模型产品 HappyOyster(快乐生蚝)。
这直接对标字节刚发布不到3个月的Seedance 2.0。
但这轮竞争远远未结束,Mamoda2.5就是最好的证明之一。目前字节并未公布Mamoda2.5更详细的情况。
但早在2025年10月1日,该团队就利用Qwen3VL-8B发布了MammothModa2-Dev版本。
去年底,开源的MammothModa2发布,采用MoE DiT架构,支持视频生成,今年2月发布了视频生成和视频编辑推理代码。
如今,Mamoda2.5更是一个新的开源模型——不过依然基于Qwen3VL进行训练,模型能力远超快手可灵等多个闭源模型。
然而,尽管Mamoda2.5在生成和编辑任务上表现出强大性能,但仍存在一些值得未来探索的可行方向:
1. 全模态音频‑视频生成与编辑。
Mamoda2.5 目前支持统一的图像和视频生成与编辑。一个自然的下一步是将音频处理整合到框架中,实现在单一模型中同步进行音频‑视频生成和编辑。这将使模型能够生成具有连贯配乐、对话和音效的视频,极大地扩展其在现实世界内容创作场景中的应用范围。
2. 更深度的理解与生成统一。
最近的系统如GPT‑Image‑2和Vision Banana已表明,深度整合理解与生成能够解锁涌现能力——将生成作为多样化视觉任务的通用接口,并利用推理来提高生成质量,因此,Mamoda2.5的统一架构内进一步探索理解与生成之间的协同作用,使这两种能力能够相互强化。
从谷歌Omni的全模态野心,到阿里快乐马的落地突袭,再到字节 Mamoda2.5 的开源重拳。
现在已经看得很明白:
AI 的终局,就是统一全模态,而且必须开源。
巨头们嘴上各说各的,身体却无比诚实。
未来世界的AI模型,统一、开源、全能,才是唯一答案。
文章来自于微信公众号 "智能纪元AGI",作者 "智能纪元AGI"



