# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
刚刚,芯片创业公司 Cerebras 宣布了该公司历史上最重要的消息,「我们发布了世界上最快的芯片,该芯片拥有高达 4 万亿个晶体管。」

一直以来,Cerebras 一直在往「大」的芯片方面发展,此前他们发布的晶圆级引擎(Wafer Scale Engine,WSE-1)面积比 iPad 还大。第二代 WSE-2 虽然在面积上没有变化,但却拥有惊人的 2.6 万亿个晶体管以及 85 万个 AI 优化的内核。
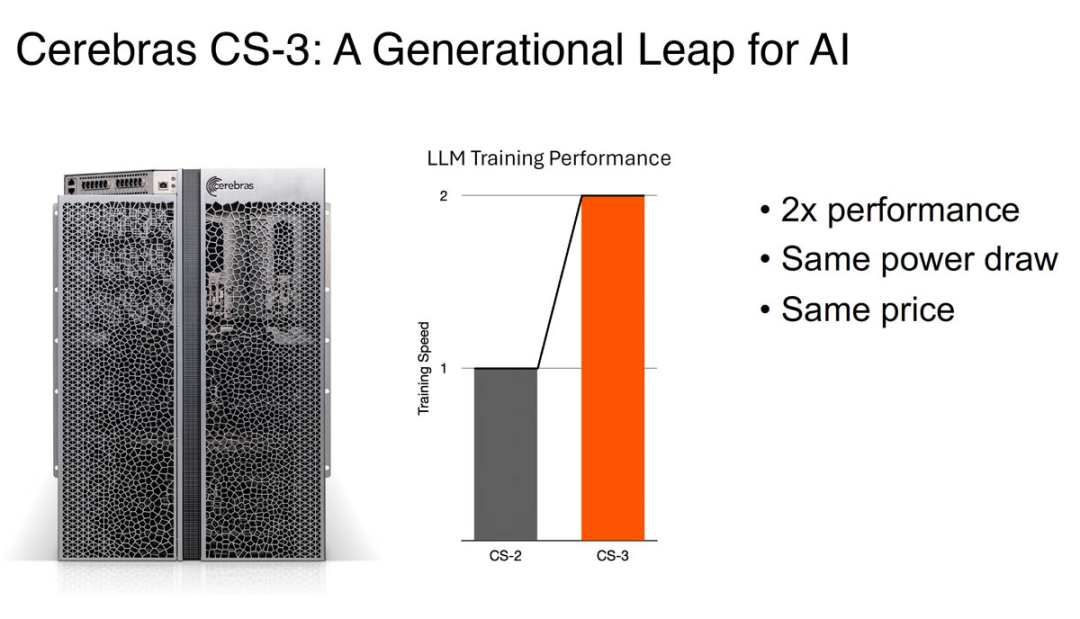
而现在推出的 WSE-3 包含 4 万亿个晶体管,在相同的功耗和价格下,WSE-3 的性能是之前记录保持者 WSE-2 的两倍。
此次发布的 WSE-3 是专为训练业界最大的 AI 模型而打造的,基于 5 纳米、4 万亿晶体管的 WSE-3 将为 Cerebras CS-3 人工智能超级计算机提供动力,通过 90 万个人工智能优化的计算核心,提供每秒 125 petaflops 峰值 AI 性能(1 petaflops 是指每秒 1,000,000,000,000,000(1 万亿)次浮点运算)。

WSE-3 呈正方形,边长为 21.5 厘米(面积为 46225mm^2),几乎是使用了整个 300 毫米硅片来制造一个芯片。这么看来,凭借 WSE-3,Cerebras 可以继续生产世界上最大的单芯片了。
WSE-3 大尺寸到底是个什么概念,在将其与 Nvidia H100 GPU 进行比较后发现,前者大了 57 倍,内核数量增加了 52 倍,芯片内存增加了 800 倍,内存带宽增加了 7000 倍,结构带宽增加了 3700 倍以上。而这些都是芯片实现高性能的基础。
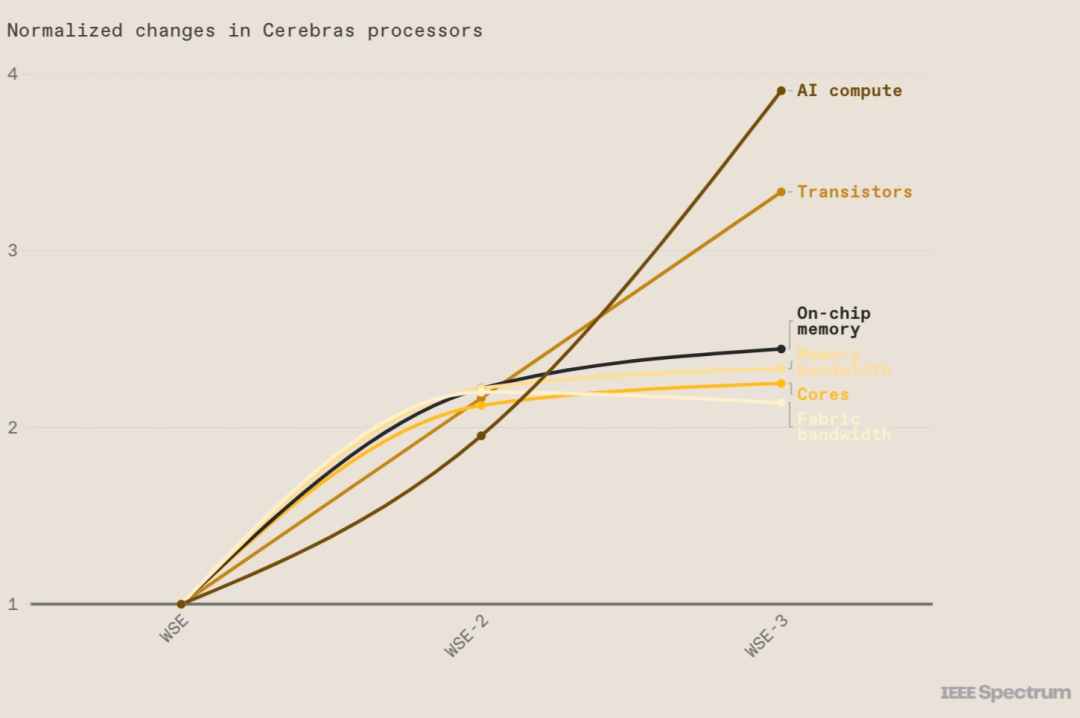
图源:https://spectrum.ieee.org/cerebras-chip-cs3
下图展示了 WSE-3 的特点:

WSE-3

前两代晶圆级引擎的一些参数。图源:https://twitter.com/intelligenz_b/status/1768085044898275534
配备 WSE-3 的 CS-3 计算机理论上可以处理 24 万亿个参数的大型语言模型,这比 OpenAI 的 GPT-4 等顶级生成式 AI 模型的参数高出一个数量级(据传有 1 万亿个参数)。这么看来, 具有 24 万亿个参数的模型在一台机器上运行成为可能。
图源:https://www.servethehome.com/cerebras-wse-3-ai-chip-launched-56x-larger-than-nvidia-h100-vertiv-supermicro-hpe-qualcomm/
CS-3 拥有高达 1.2 PB 的巨大内存系统,旨在训练比 GPT-4 和 Gemini 还大 10 倍的下一代前沿模型。24 万亿个参数的模型可以存储在单个逻辑内存空间中,无需分区或重构,从而极大地简化了训练工作流程并提高了开发人员的工作效率。在 CS-3 上训练 1 万亿个参数模型就像在 GPU 上训练 10 亿个参数模型一样简单。

CS-3 专为满足企业和超大规模需求而构建。紧凑的四系统配置可以在一天内微调 70B 模型,同时使用 2048 个系统进行全面扩展,Llama 70B 可以在一天内从头开始训练,这对于生成式 AI 来说是前所未有的壮举。

最新的 Cerebras 软件框架为 PyTorch 2.0 和最新的 AI 模型和技术(如多模态模型、视觉 transformer、MoE 和扩散模型)提供原生支持。Cerebras 仍是唯一能为动态和非结构化稀疏性提供本机硬件加速的平台,可以将训练速度提高 8 倍。
「八年前,当我们开始这一旅程时,每个人都说晶圆级处理器是一个白日梦。我们非常自豪能够推出第三代突破性人工智能芯片,并且很高兴将 WSE-3 和 CS-3 推向市场,以帮助解决当今最大的人工智能挑战」,Cerebras 首席执行官兼联合创始人 Andrew Feldman 如是说道。

Cerebras 联合创始人兼首席执行官 Andrew Feldman
由于每个组件都针对 AI 工作进行了优化,CS-3 比任何其他系统都能以更小的空间和更低的功耗提供更高的计算性能。CS-3 性能翻倍,功耗却保持不变。
CS-3 具有卓越的易用性。相比于大模型常用的 GPU,CS-3 需要的代码减少 97%,并且能够在纯数据并行模式下训练从 1B 到 24T 参数的模型。GPT-3 大小的模型在 Cerebras 上实现只需要 565 行代码(而 GPU 需要 20,507 行 )—— 这是行业纪录。
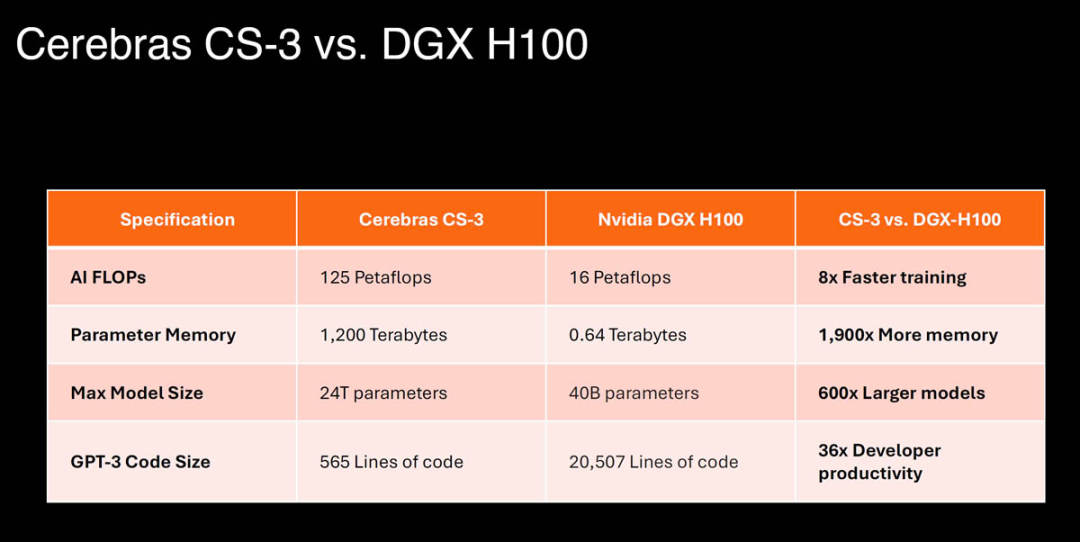
图源:https://www.servethehome.com/cerebras-wse-3-ai-chip-launched-56x-larger-than-nvidia-h100-vertiv-supermicro-hpe-qualcomm/
目前,Cerebras 已经积压了大量来自科技企业、科研机构的订单。美国阿贡国家实验室负责计算、环境和生命科学的实验室副主任 Rick Stevens 称赞道:「Cerebras 的大胆精神将为人工智能的未来铺平道路。」
参考链接:
https://www.zdnet.com/article/ai-startup-cerebras-unveils-the-largest-chip-yet-for-generative-ai/
https://www.servethehome.com/cerebras-wse-3-ai-chip-launched-56x-larger-than-nvidia-h100-vertiv-supermicro-hpe-qualcomm/
文章来自于微信公众号 “机器之心”



【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
