
通义实验室大火的 WebAgent 续作:全开源模型方案超过GPT4.1 , 收获开源SOTA
通义实验室大火的 WebAgent 续作:全开源模型方案超过GPT4.1 , 收获开源SOTAWebAgent 续作《WebShaper: Agentically Data Synthesizing via Information-Seeking Formalization》中
来自主题: AI资讯
8420 点击 2025-07-30 11:26
 搜索
搜索
WebAgent 续作《WebShaper: Agentically Data Synthesizing via Information-Seeking Formalization》中
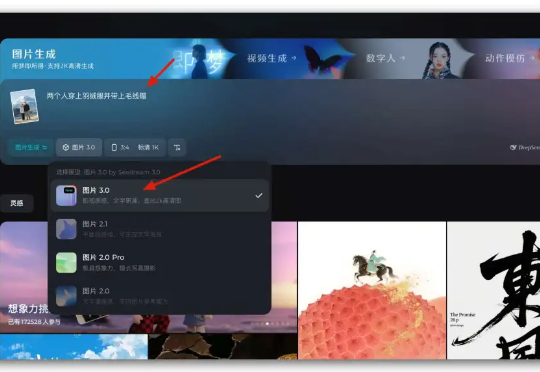
前段时间,我们横向对比了即梦3.0、2.1、GPT4o的海报生成能力, 当时即梦3.0的文生图中文能力就已经超过了 GPT4o,我们通过提示语就可以控制字体的样式、位置、大小、排版等等。

我是没想到,GPT4o用一段小小的Prompt生成的一些图片,引发的热度浪潮。
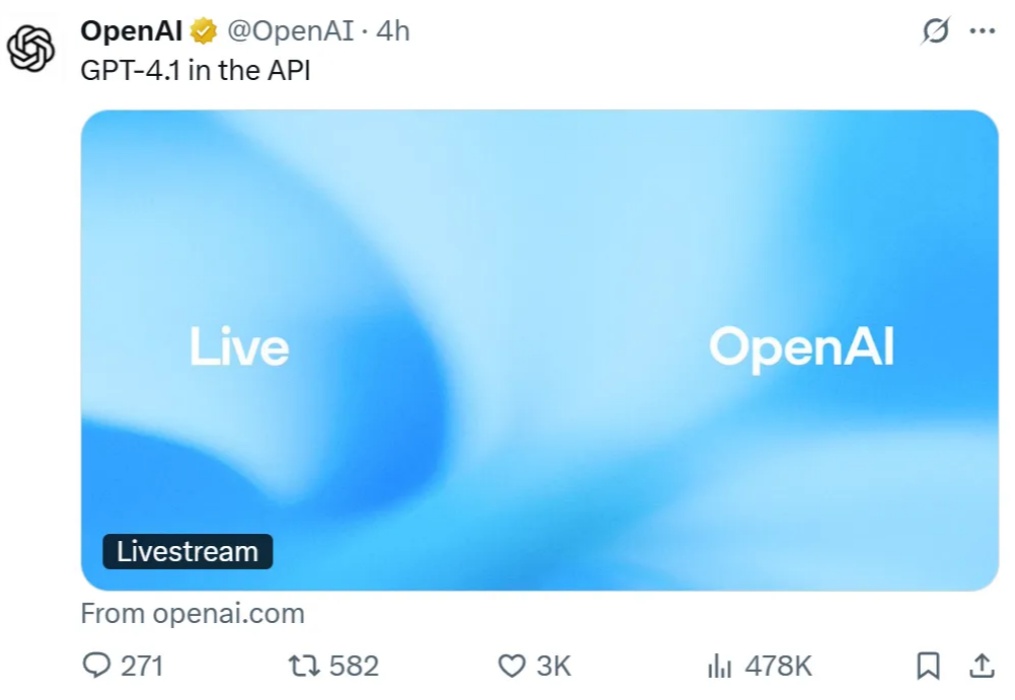
今天凌晨,OpenAI 的新系列模型 GPT-4.1 如约而至。
GPT4o的多模态生图前天上线之后。经过两天的发酵,含金量还在不断提升。
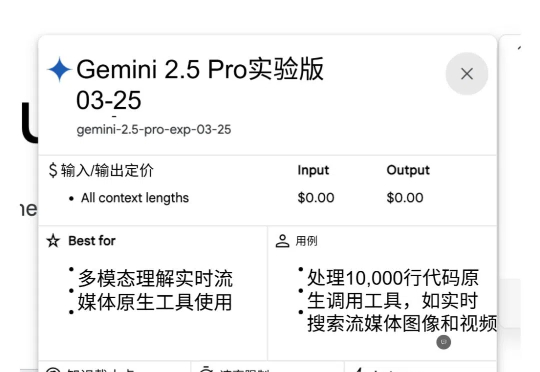
又双叒,抢在OpenAI直播之前,谷歌Gemini 2.5系列来了。首个版本Pro Experimental一登场就抢下大模型竞技场第一名,并且整整比GPT-4.5高出40分Gemini 2.5同样是推理模型,用Jeff Dean的说法是:

下周即将发布的AI汇总,太热闹了!Sam亲口宣布要下周发布,一些媒体也报道微软已经开始给GPT4.5和GPT5准备服务器昨天Claude网站更新了,有网友发现有一行提示“Try Anthropic‘s new thinking model”,这意味着Claude有新模型要发了!

上线一周, gemini-2.0-flash-exp、gemini-2.0-flash-thinking-exp 已经成为了我日常对话频率最高的模型之一。
你是不是以为发了GPT4.5?但很抱歉,今天只是发布了o1的API以及实时语音的新玩意。 还记得前段时间的OpenAI的DevDay吗?那上面曾经说过会更新OpenAI的API,现在期货交割了!这次OpenAI表现很好,才用了短短的一个多月就完成了交割,值得鼓励!(我是在吹不下去了。。。)

今天是美国的周一,本来以为会跟上周一样,挑选周一发个大货,毕竟上周就有爱好探索的网友发现 GPT4o 好像有了更新,已经开始说自己是 GPT4.5 了。