# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

“LLM 就是一条死路。”
说出这句话的,不是某个匿名论坛上的键盘侠,而是AI教父、图灵奖得主、前 Meta 首席科学家——杨立昆(Yann LeCun),并且他曾在多次采访中说过这句话。
在近日的公开访谈中,杨立昆又爆出了一个反人类直觉的判断:“一个没有预测自身行为后果能力的系统,不配成为真正的智能体。”
同时,他也进一步表明,今天所有 LLM 都还不具备这种能力,它们只是复读人类写下的句子,却从未真正理解物理世界。
此外,他还给出了一个更炸裂的判断:“像素重建是个坏主意,并不是自监督学习的正确方向。”
他指的不是某个小修小补的改进,而是整个生成式 AI 的根基:逐像素重建、逐 Token 预测,在物理世界面前根本走不通。
取而代之,他押注了一条截然不同的路径:“联合嵌入比传统方法更适合表示学习。”
这套路线的核心叫做 JEPA(Joint Embedding Predictive Architecture:联合嵌入预测架构)——一个从设计上就不输出任何像素或文字的架构。
为了证明自己是对的,他离开 Meta,投入10亿美元,成立新公司 AMI Labs,正式向整个 AI 行业宣战。
这一次,杨立昆不是在赌。他是想用真金白银告诉全世界:你们走错了。
“杨立昆是因为在 Meta‘失宠’才出来另立山头”——其实大错特错。
“我不像那些年轻人,看到什么火热就一头扎进去。”——这是杨立昆接受采访时说的话,如此精准地概括了他一贯的学术风格与立场:独立、审慎,且始终基于其长期的技术愿景进行判断,而非盲目追随行业热潮。
早在2015年,他就画了一张著名的“蛋糕图”:如果智能是一个蛋糕,那么蛋糕的主体是自监督学习,糖霜是监督学习,樱桃是强化学习。当时业界对强化学习非常狂热且痴迷,没人信他,但10年后 GPT 为他平反了。
如今,所有人为 LLM 摇旗呐喊时,杨立昆又提出了一个比 LLM 更终极的智慧蓝图:世界模型(World Model)。

在杨立昆看来,今天的 AI 与人类最大的差距在于:一个17岁的少年花20个小时就能学会开车,而 AI 系统被喂了数百万小时的视觉数据,却依然无法实现真正的L3/L4级自动驾驶。
核心关键在于:人天生理解物理世界,能够预判自己行为的后果,而 LLM 只会复述人类语言中的统计规律。用杨立昆的话说:“我实在无法理解,一个没有预测自身行为后果能力的系统,凭什么被称为真正的智能体?”
然而 AI 圈的主流声音是:“Scaling Law 还没碰到天花板。”关于“世界模型”的说法,在很多同行眼中类似于自嗨。杨立昆似乎并不在乎外界的冷嘲热讽。因为从杨立昆的经历来看,他从来不靠别人认同做研究。
杨立昆与主流的第一个根本分歧,源于一段“不堪回首”的经历。
在 Transformer 还没有问世的年代,他和许多研究者尝试过一个看似自然的路径:让 AI 看一段视频,然后像预测文字一样,逐像素预测下一帧。但很快他们发现了一个诡异的问题:无论怎么调参,模型生成的画面都永远是模糊的。
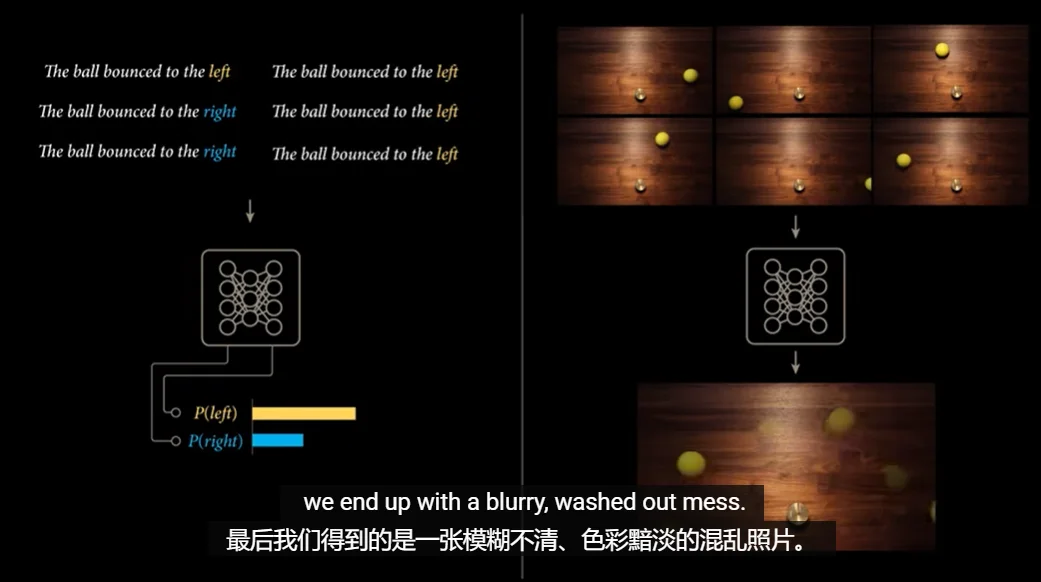
他举了一个很经典的例子:在训练数据里,球有时候往左弹,有时候往右弹。场景是相同的,但未来有多种可能性。如果模型被要求必须输出“唯一确定”的下一帧像素,那它最安全的办法就是取平均,把向左弹的那一帧和向右弹的那一帧叠在一起,每个像素取个平均值。但结果注定是:模糊、发灰、被冲淡。
这还不是最要命的。语言模型预测下一个词时,只需要从5万多个候选词里挑一个,例如 GPT-2 拥有50257个离散输出,每一个输出对应模型可能生成的下一个 Token。
但一张高清视频画面,由1920×1080×3个彩色像素构成,每个像素有256种取值——下一帧的可能性数量接近10的1500万次方,比宇宙中的原子总数还大无数倍。你不可能像给每个词设一个“出口”那样,给每种可能的画面也设一个出口。
杨立昆对此有一个非常直接的判断:“像素重建是个坏主意,并不是自监督学习的正确方向。”
那么问题来了:模型必须是生成式的吗?
答案:不是。
他提出了一条截然不同的路径:别让模型猜每个像素了,先学会“抽象”,再在抽象世界里做预测。
于是他彻底“推翻”了自己。他的主力思想是:让AI 先学会“表示世界”,忽略无关紧要的冗余细节,将视频帧压缩成数学向量,然后在抽象的表示空间里捕捉那些真正可预测的信息,比如物体的位置、速度和运动方向。
他将其命名为 JEPA ,与传统生成模型会尝试预测下一帧视频中的每一个像素不同,JEPA 的思路是:模型不再需要解决“预测所有像素”的问题,而是专注于场景中真正重要的结构信息。
工作流程大致是这样的:
-把当前视频帧(比如第t帧)送进一个编码器,压缩成一个数学向量(embedding)。
-把下一帧(第t+1帧)送进另一个编码器,也压缩成一个向量。
-中间加一个“预测器”,在向量空间里从当前帧的表示去预测下一帧的表示。
杨立昆打过一个比方:如果训练一个模型去预测行车记录仪视频,它会把大量算力浪费在预测道路两边树叶的随机摆动上,这些其实是不可预测的,但它们却占据了大量像素。JEPA 的思路是:只关注场景中真正重要的结构信息,比如物体的位置、速度、方向。
JEPA 的核心思想并不新鲜。杨立昆翻出了自己30年前在贝尔实验室的老发明:孪生神经网络(Siamese Network)。
当时他做的是签名防欺诈检测。系统不生成任何签名图像,而是把两张签名分别送进两个编码器,各输出一个向量,然后比较相似度,同一个人的签名要尽量像,伪造的要尽量远。它跳过了“像素级重建”,直接学抽象特征。
JEPA 的思路与之如出一辙:先编码,再预测表示,绝不退回到原始像素。
但这条路有一个很容易掉下去的陷阱:表示崩溃(Representation Collapse)。

什么意思呢?你训练两个编码器,要求它们对同一张图的不同版本输出尽量相似的向量。模型可能会找到一个“作弊解”,不管输入猫还是车,都输出同一个全1向量。这样相似度确实最大化了,但模型什么也没学到,成了废物。
杨立昆的早期孪生网络解决这个问题,靠的是对比学习(Contrastive Learning),同时用正样本和负样本,让不同输入必须产生不同表示。但这种方法规模扩大后问题就来了:需要巨量负样本,计算量爆炸。杨立昆指出,在最坏情况下,对比样本数量甚至可能随表示维度指数增长。
直到2020年左右,他和博士后 Stefan Deny 研究出了一个叫 Barlow Twins 的方案。灵感来自1961年一位神经科学家霍勒斯·巴洛的假说:生物视觉系统通过减少神经元之间的冗余信息来编码世界。
这套组合拳基本封堵了表示崩溃的漏洞。Barlow Twins 在 ImageNet 图像分类任务上达到了73.2% 的准确率,比 2012 年突破性的 AlexNet(由 Alex Krizhevsky 等提出的卷积神经网络)高出超过 10 个百分点。
杨立昆团队后来又推出了一个更简化的版本叫 VicReg,效果同样不错。与此同时,Meta 巴黎团队沿着这个思路迭代出了大名鼎鼎的 DINO 系列。

DINOv3 在2025年8月发布,在 ImageNet 上取得了88.4%的准确率。论文里写了一句很提气的话:这是自监督模型第一次在图像分类上与弱监督甚至完全监督模型打平。
更让人惊叹的是 DINO 的一个可视化能力。你可以取一张照片,选取手部区域的embedding,然后跟整张图像的其他 patch 做相似度比较,用颜色图可视化——DINO 可以非常准确地把手从背景中分割出来。同样的方法应用到球、猫或书本上,都能得到极其清晰的分割效果。这证明了模型在没有人工标注的情况下,学到了高质量的语义表示。
杨立昆的判断也因此更笃定了:联合嵌入比传统方法更适合表示学习,尤其是用于图像的自监督学习。
作为与全世界“对抗”的人,杨立昆说了一句在硅谷不太受欢迎的话:“我无法理解,一个没有预测自身行为后果能力的系统,怎么能被称为真正的智能体。”
虽然他承认 LLM 的巨大工程成就,但也指出:语言模型之所以能成功,是因为语言本身是离散的、有边界的,几千几万个 Token 就能框住。但真实世界是连续的、无限的,没有词表能装得下。
“下一 Token 预测”这条路,在语言上行得通,但硬搬到物理世界就拧巴了。
当时,所有人都在吹强化学习,他说自监督学习才是蛋糕主体。大家不信,但后来 GPT 成了最好的论证。
这一次所有人都在卷 LLM,他又来唱反调。
不同的是,这一次,他要玩把大的:不仅压上了自己的声誉、时间,还有10亿美元。
参考链接:
https://www.youtube.com/watch?v=kYkIdXwW2AE
文章来自于"51CTO技术栈",作者 "S+"。



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
