# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
这两天,最火的新闻就是美国战争部(五角大楼)把过去几十年的 UFO 档案全部「开源」了。
让我们致敬,最有互联网开源精神、最不藏着掖着的五角大楼 😆。
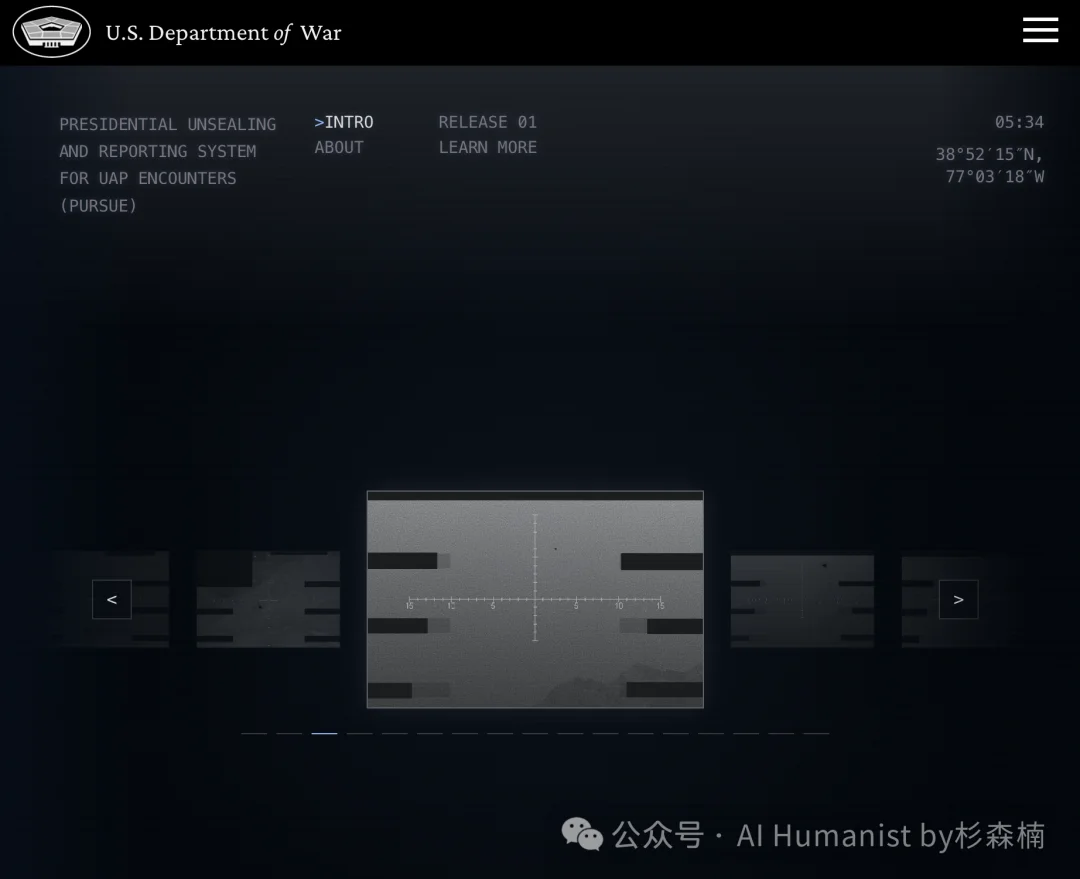
是的,你没看错。
把档案锁在地下室、你想看一份文件得提交 FOIA 申请等三年才能拿到缩印件的五角大楼,这回把过去几十年攒下来的 UFO 资料,一次性、免费、全部放上了互联网。
懂王老师终于把他当选时的承诺,变成了现实。

开源之后,全网就炸了,这回实在是太炸了。
铺天盖地的截图、分析、阴谋论,全来了。
最离谱的是 NASA 阿波罗时代的老照片,被官方标注了「不明物体关注区域」,一堆人截图出来逐帧放大分析,要在几十年前的太空照片里找外星飞船。

X 上面各种「看看战争部给我们看了什么」的帖子,评论区吵翻了,信的人觉得这是「人类历史转折点」,不信的人觉得这就是一堆旧资料换了个包装又放一遍。
懂王的性格,大家懂得都懂。
但不管你信不信,有一点谁都没法否认:UFO 的相关信息,是真的被开源了,里面确实有非常值得深挖的细节。
但问题也来了。
资料是开源了,散落在好几个官方网站上,PDF 没有目录,视频没有分类,搜索功能基本等于没有。你想找个具体案例,得自己在几百份文件里费死劲翻:
说白了就是:信息公开了,但信息的组织方式还停留在上个世纪。
这个时候,我想起了一个东西。
我之前做且开源过一个叫 Personal-Wiki 的项目。
简单说就是,你给它一堆乱七八糟的信息,它能帮你自动整理成一个成熟的 Wiki 百科站点,有搜索、有分类、词条之间还能双向链接互相跳转。
之前做这个项目的时候,我就一直在想一个问题:什么样的信息最适合用 Wiki 来组织?
答案就是那种体量大、关系复杂、你没法从头读到尾只能按需查阅的内容。
UFO 档案可以说是完美命中了。
这些资料涉及的东西太多了,时间跨度从 1947 年到 2026 年,牵扯到的人有飞行员、物理学家、吹哨人、国会议员、情报官员,案例之间还经常互相关联,A 事件里提到的某个军事基地,在 B 事件里又出现了。
所以这个周末我没怎么睡,用了 2 天把公开的所有 UFO 资料整理成了一个完整的 Wiki 百科站点,可以搜索、可以按时间线浏览、可以看视频、词条之间还能互相跳转。
网址是:https://ufo-uap-wiki.vercel.app
(需要魔法,手机也能看,文件全部开源可随意下载)
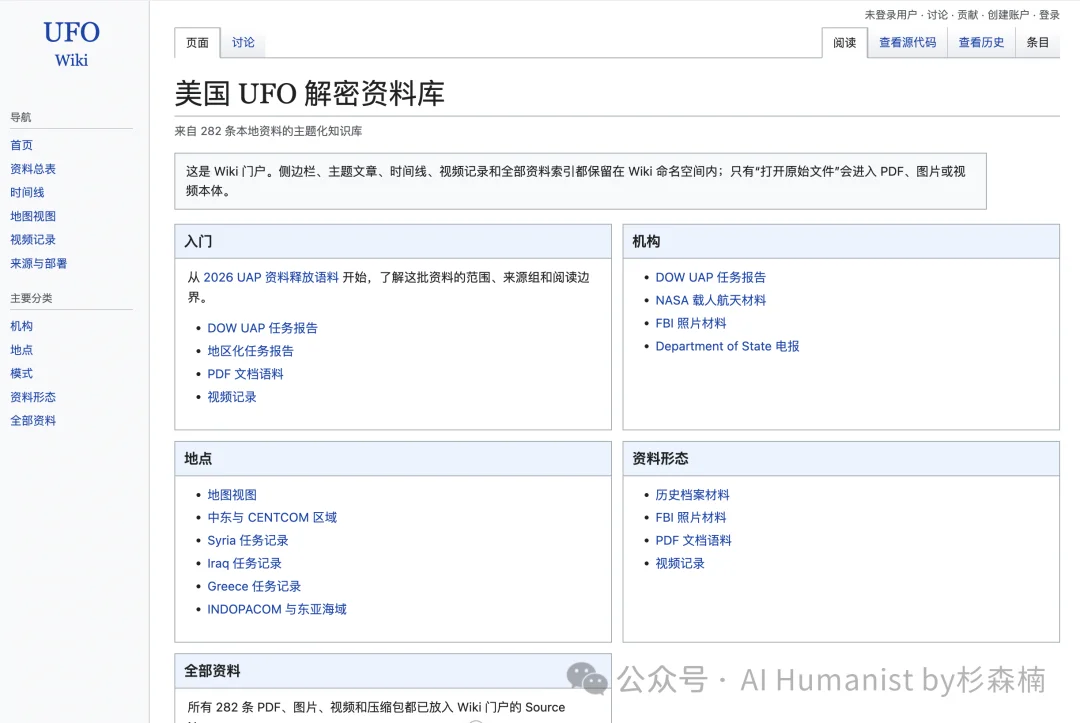
电脑端的 UFO-Wiki 首页长这样:
手机端显示长这样:

下面,看看这个网站到底是干嘛的。
首先,Wiki 的结构天然就能解决资料的冗余问题。每个案例是一个词条,每个人物是一个词条,每个地点是一个词条,它们之间通过链接互相连起来。
打开首页你就能感受到,这玩意儿不是一个随便扔了几百个 PDF 上去的资料站。
首页按「机构」「地点」「资料形态」「全部资料」组织入口,整体就是维基百科式的导航。你想从 NASA 的角度看就点 NASA,想从中东地区的角度看就点中东,想按年份翻就按年份翻。
在 UFO Wiki 的入口里,我设置了大量条目,按主题类型、别名、关联关系全部整理成了一张表格。主要按地区和事件来分,比如叙利亚、伊拉克发现的不寻常目击、NASA 载人航天资料里的异常记录、还有 FBI 的照片档案,都能从这张表里直接点进去。
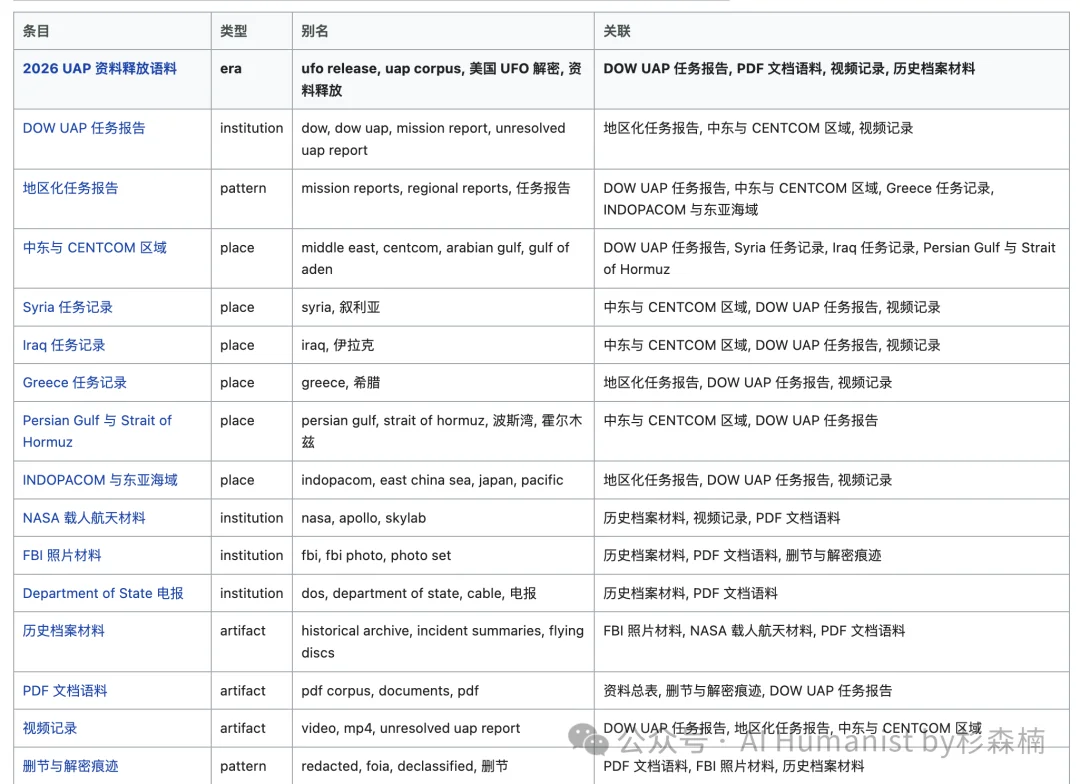
整个站收录了 282 条资料,每一份 PDF、图片、视频、ZIP 都有独立页面。里面有上百个 PDF 文件、几十个视频、100 多张照片(包括 FBI 的照片材料),还有完整的 ZIP 压缩包。所有官方放出来的原始资料,基本都进了这个库里。
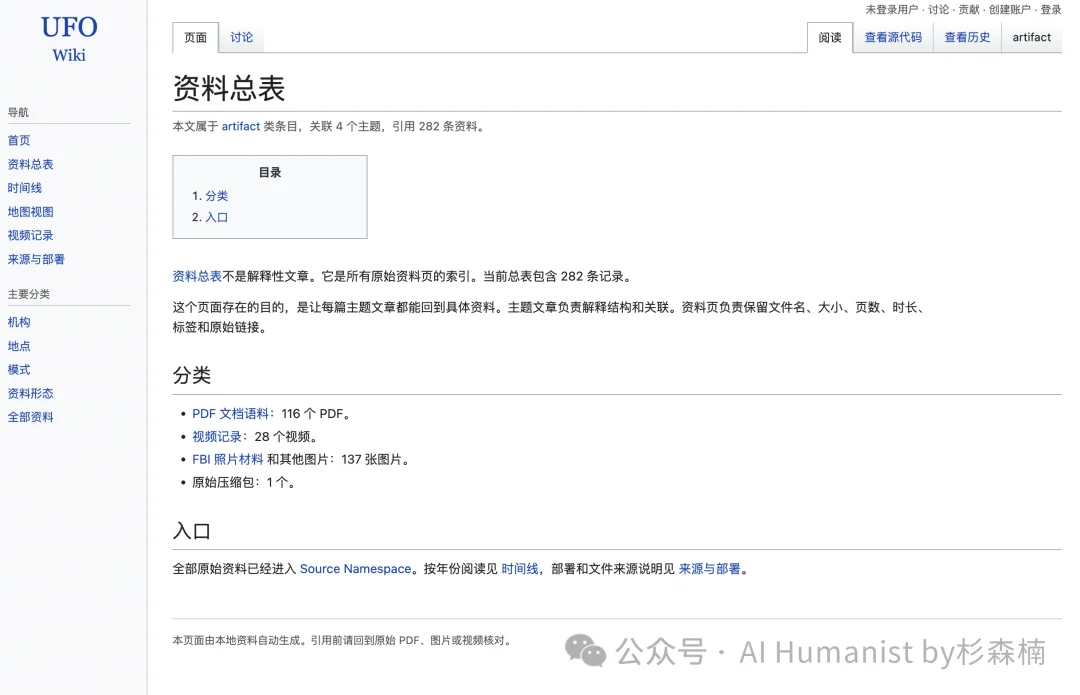
我对每一份 PDF 都跑了文本抽取,做了摘录,里面有不少是扫描件,甚至还能看到五角大楼那种经典的红色删节标记 😅。所有内容按年份、来源机构、文件大小、页数做了展示。

一份 PDF 的页面大概长这样。我给每份资料都标注了引用信息:资料 ID、标题名、类型、来源机构这些,然后你可以直接在线阅读,也可以随手下载原件。
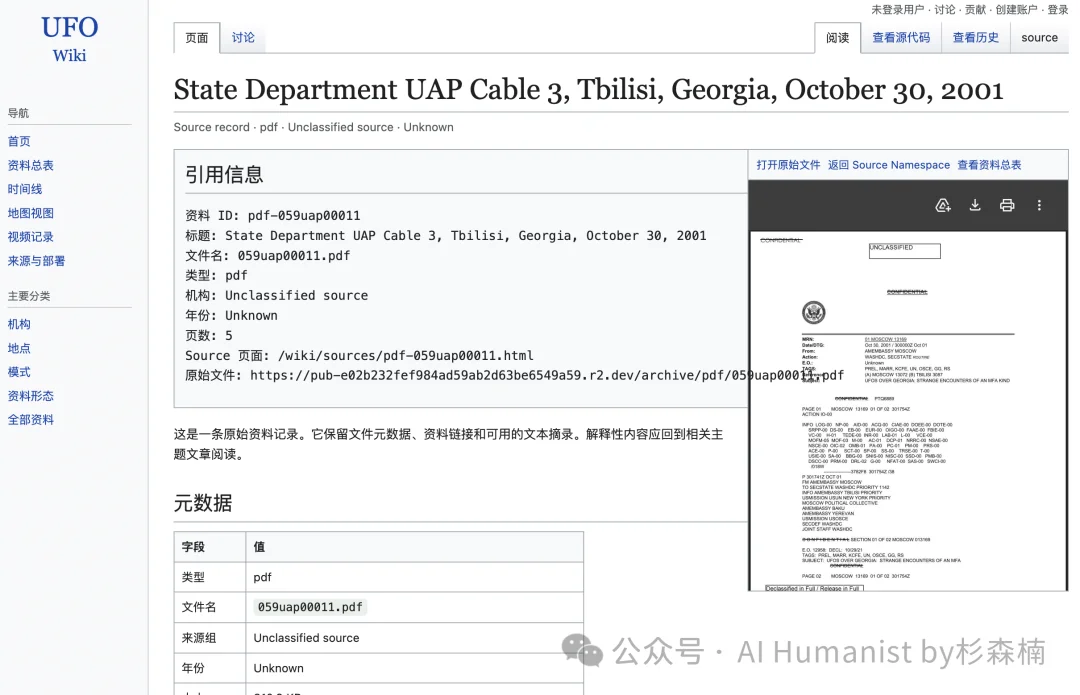
视频也是一样。所有视频我都存在 Cloudflare R2 存储桶里面,打开速度还挺快的,直接在线观看就行。
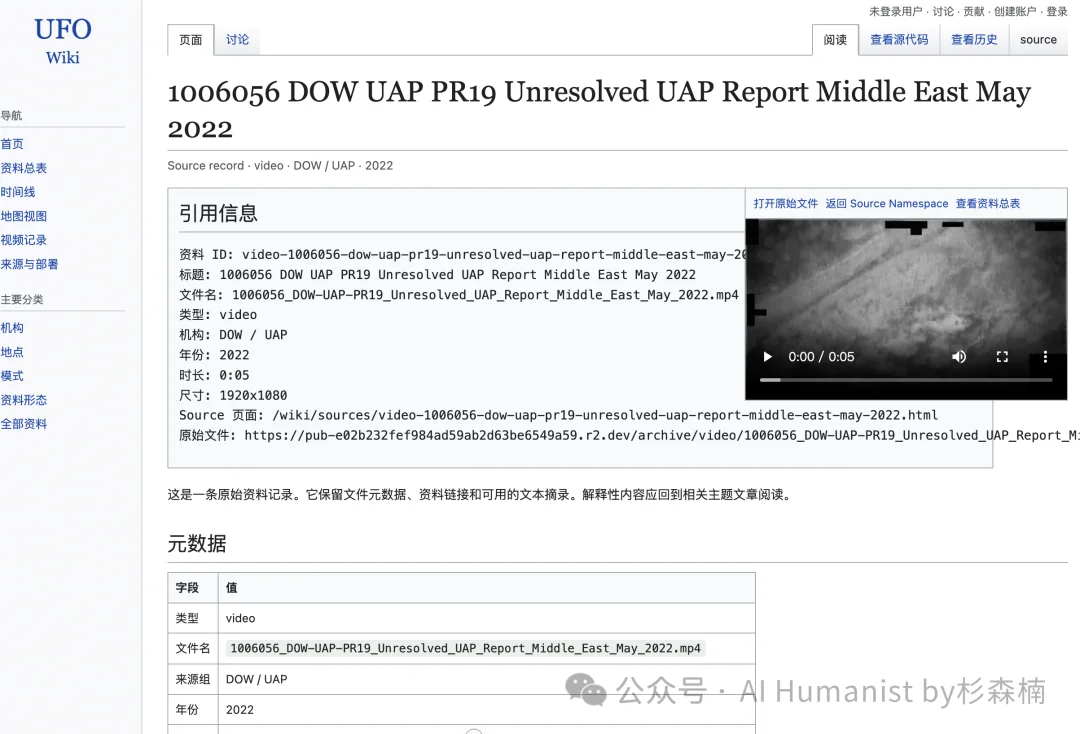
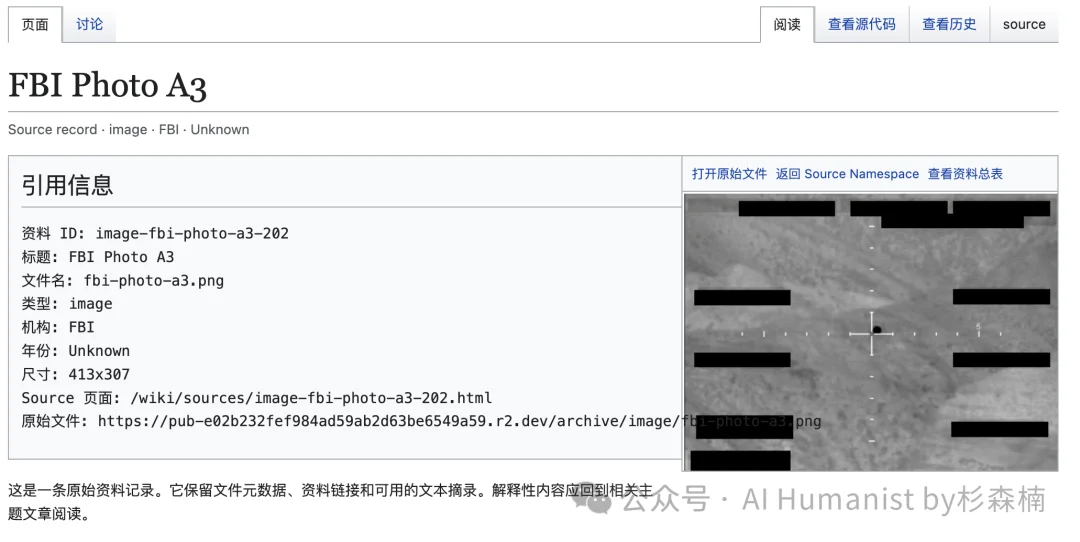
照片部分也做了大量的入库和分类。其中很多照片来自 FBI 的材料,我给 FBI 的照片单独做了一组整理,点进去就能看到全部。
导航里有一个年份索引,从 1944 年一直到现在。所有材料(包括 PDF、图片、视频)都做了年份整理,你可以直接按年份一份一份往下翻。
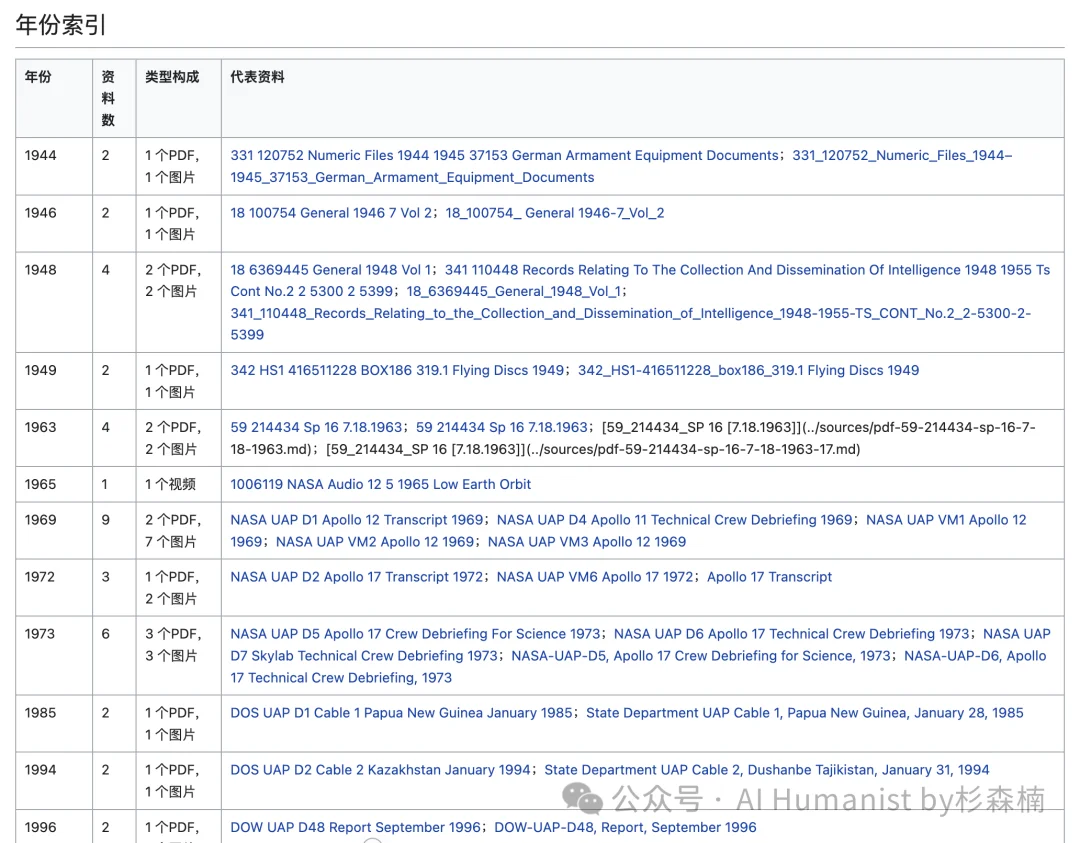
整个站整体上我分成了五大块:入门、机构、地点(中东、日本、伊拉克这些)、资料形态、还有全部资料。五个入口各自独立,你从哪块进都能拐到另外几块里去。
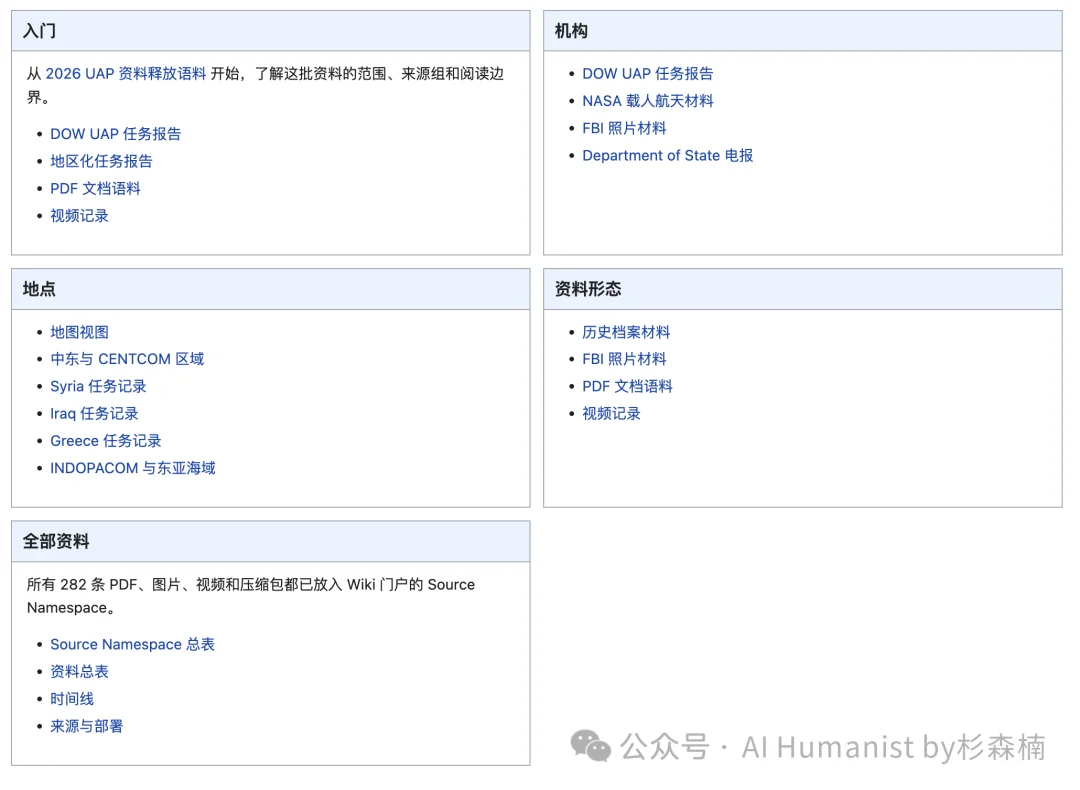
我还设置了一个 source filters,可以按文件类型(PDF、视频)和来源年份做筛选。基于所有资料,我用 Personal-Wiki 这个 skill 写了 19 篇主题文章,全部放在里面。
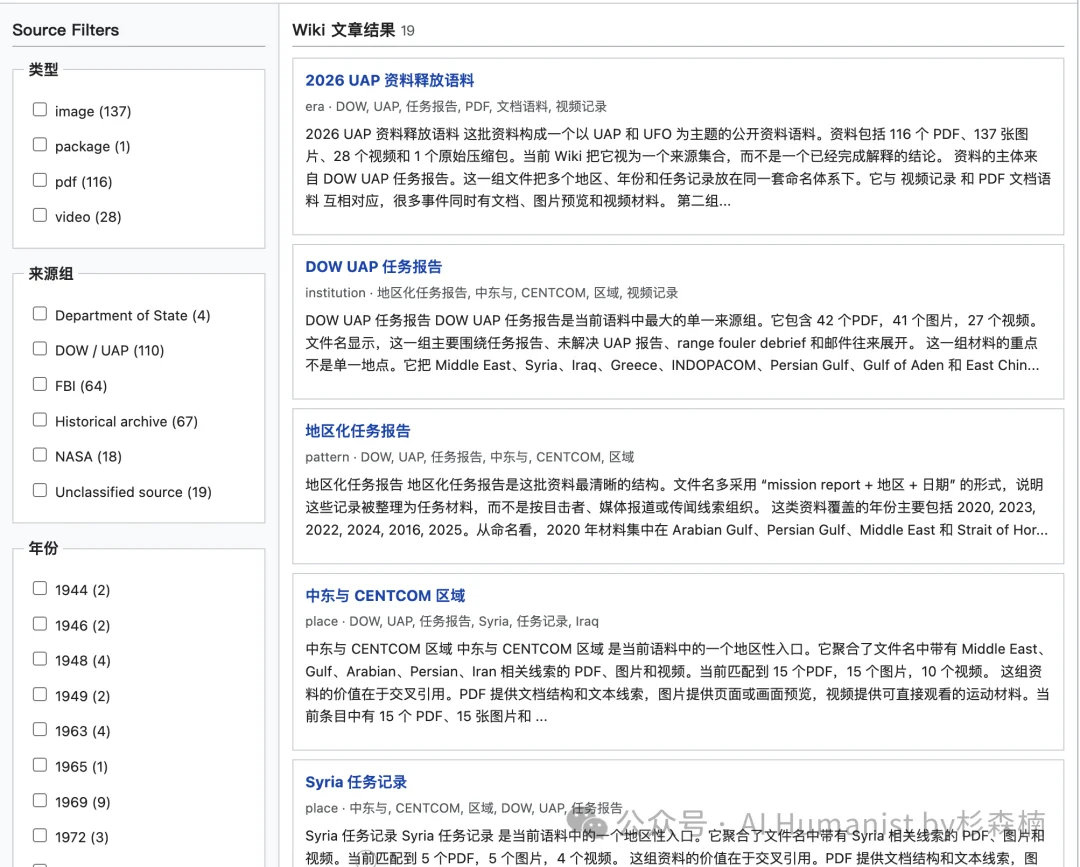
下面这个地图视图,老实说做得挺糙的 😅,地图这玩意儿确实有点难搞。
不过整体模块还算完整,按多个地区整理了对应记录,比如亚太、东亚、太平洋、欧洲、北美。右侧是该地区对应的 PDF、图片、视频资料包。
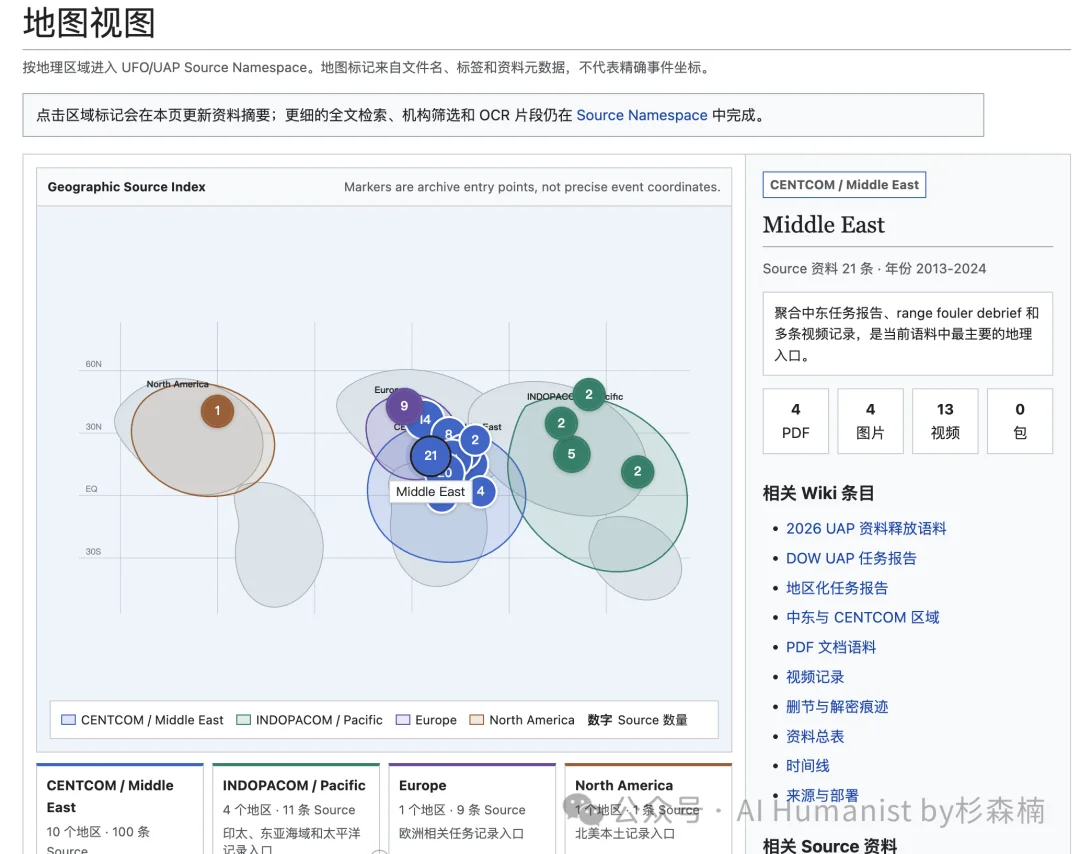
我整体把所有资料基本都过了一遍,挑了几份典型的文件给大家看。
比如下面这份 PDF 报告,是五角大楼解密的一份飞行任务报告,记录了从起飞、信号情报收集、支援行动到返回的完整时间线。
这份文件属于 UFO / 异常飞行调查任务的官方记录,里面没有直接描述目击细节。

乍一看挺索然无味的,好像也没直接提外星人。但对外星人同好来说,这种看起来什么都没说的文件,反而才是最有意思的地方 😆。
再看下面这份,也是五角大楼解密的 UFO / 异常空中目标任务报告。这次飞机从西格内拉空军基地起飞,任务过程中记录了可能的小型不明空中现象(UAP)目击:

视频资料里记录了大量「不寻常片段」。像这种看起来很诡异的物体:

还有宇航员目击记录、奇怪物体报告、无法解释的太空影像,全都能看到:

下面简单聊聊技术栈,给感兴趣的朋友看看这个站是怎么搭起来的。
整个流程全程采用 Codex 进行 Vibe Coding,我主要做的是数据整理、词条结构设计、还有一些交互细节的调整。
这里先说说我对于 Claude Code 和 Codex 的使用,由于我本人 5 个 Claude Max 号被封,非常感谢 A ➗,所以被迫 All In Codex,又由于我买了 Pro 会员,而且这个月 Codex 额度是翻倍的,所以我直接 GPT-5.5,思考 Max,输出加速。
非常爽。
整个项目,分为 2 大块。
代码侧全部托管到 GitHub:
但里面所有资料由于太大了,文件也非常的多,所以原始的 PDF 文件和视频存在 Cloudflare R2 上面。
为什么选 Cloudflare?
便宜,流量不要钱。这些档案文件加起来体积大概 7 个 G,Cloudflare 每个月的免费额度是 10 个 G,出站流量免费,存储费用也很低,整个站跑下来月成本可能是 0。
域名和云服务器又弄起来特别麻烦,所以我直接部署在了 Vercel 上,认证下 GitHub 账户即可,部署只需要 20 s。
Vercel 的好处就是简单粗暴,代码推到 GitHub,它自动帮你构建、部署到全球节点,你啥都不用管。对于这种「周末冲一个项目」的场景来说太合适了,不用折腾服务器、不用配 Nginx、不用搞 SSL,推一次 git 就上线了。
整个部署的流程,其实并不是很麻烦,倒是做 UFO-Wiki 的时候花了非常多的时间。
两天能搞定这个项目,AI 工具起码帮了 70% 的忙。剩下 30% 是我在调那些词条之间的链接关系,这部分 AI 暂时还搞不太定,得人工理一遍 😅
再放一次地址:https://ufo-uap-wiki.vercel.app
Personal-Wiki 项目本身也是开源的,如果你也想用 Personal-Wiki 把自己感兴趣的领域做成 Wiki 站,命令在这里:npx skills add cylqwe7855-alt/personal-wiki
随便用。
写到这里,我想多聊两句:为什么非得做成 Wiki,做一个普通的资料下载站它不香吗?
这个问题其实跟图书馆学有点关系。
图书馆学里有个很老的概念,叫「检索」和「浏览」是两种完全不同的行为。
检索是你已经知道自己要找什么,输入关键词,拿到结果。
浏览是你不知道自己要找什么,你需要一个结构帮你「发现」你原本不知道自己感兴趣的东西。
传统的资料站擅长前者,完全做不了后者。你去官方网站下个 PDF,你得先知道这个 PDF 存在。但如果你连「哦原来美国海军 2004 年在波斯湾做过 UAP 任务」这件事都不知道,你永远搜不到它。
Wiki 的价值就在这里 👇
每一个词条,都是一个通往未知的入口。
你本来只是想查罗斯威尔,结果看到里面提到「Project Mogul」,再点进去,发现这个项目跟冷战高空监测有关,再点进去,你就走到了一个自己本来完全没预期过的知识领域。
这种「被结构推着走」的体验,才是 Wiki 真正可用的地方。
所以这个思路其实可以映射到一堆真实的历史和事件上。
比如你把某个朝代的史料做成 Wiki,人物、战役、官职、制度互相链接,原本散落在《二十四史》里的碎片就会自己长成一张网。
比如把某次重大事件的所有公开档案做成 Wiki,涉事人物、时间线、文件之间的关联会自己浮现出来。
比如你自己的行业知识,把你过去看过的所有研究报告、公司年报、新闻事件做成 Wiki,你会发现很多你之前没注意到的关联。
信息有没有价值,很多时候看的是它有没有被放在一个能被发现的结构里 🤔。
五角大楼这次做的事情,某种意义上只完成了「解密」这一步,信息公开了,但没有被结构化。
真正让这些档案变成「可被使用的知识」的那一步,他们没做。
所以我就做了。
当然这个站肯定还有很多不完善的地方,如果你有兴趣一起玩,欢迎 PR 😆
说到底,五角大楼开源了资料,我开源了工具。
文章来自于"AI Humanist by杉森楠",作者 "杉森楠"。



【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
