# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
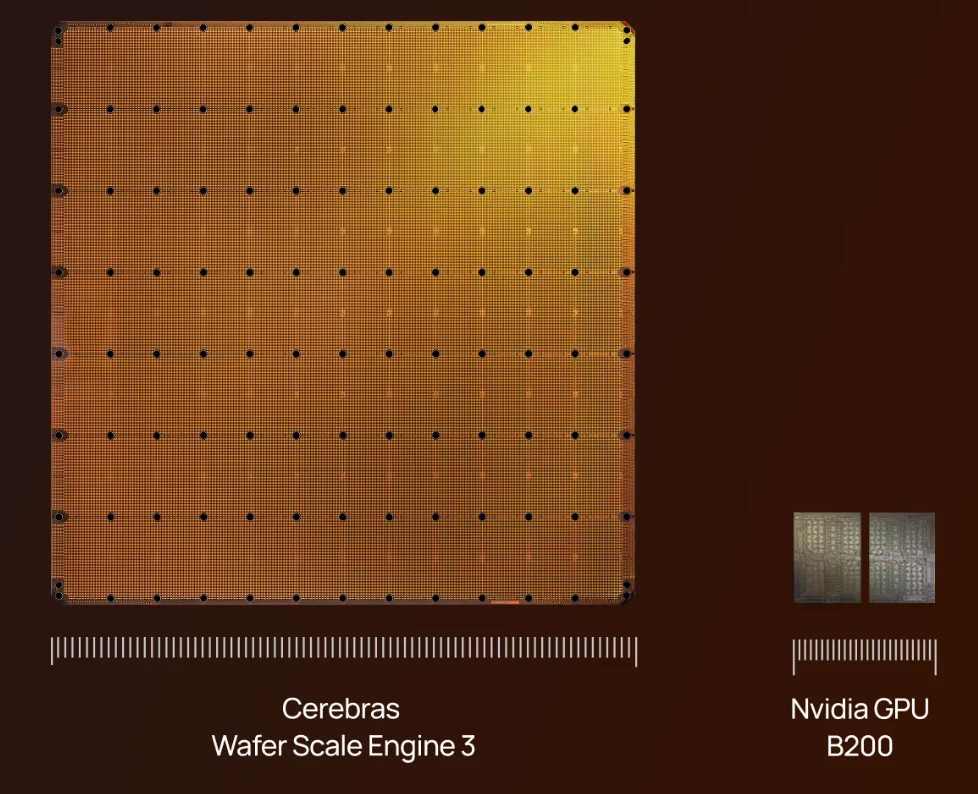
通常我们见到的电脑芯片只有指甲盖大小,GPU 也就巴掌大,美国加州一家叫 Cerebras 的公司造出的芯片跟一个大号餐盘差不多,直径超过 200 毫米,面积 46,225 平方毫米,集成了 4 万亿个晶体管。
这家公司于 2026 年 5 月 14 日在纳斯达克上市,发行价 185 美元,开盘价 350 美元,首日大涨 89%,市值冲到 750 亿美元。五位联合创始人有四位来自一家被 AMD 收购的服务器公司 SeaMicro,另一位来自 MIT。他们从 2015 年开始默默干了近十年,如今带着晶圆级芯片站到了 AI 算力竞赛的最前排。

(来源:https://www.cerebras.ai/)
Cerebras 的核心产品叫晶圆级引擎,目前已经发展到第三代 WSE-3。传统芯片制造是把一片晶圆切成上百颗小芯片,Cerebras 反其道而行之,不切割,直接把整片晶圆做成一颗芯片。这片晶圆上集成了 84 颗虚拟晶粒,每颗晶粒包含大约 10,700 个核心,整个芯片一共有 90 万个计算核心。
这些核心通过一个 2D 网格状的片上网络连接,每个核心配有一个五端口的路由器,支持四个方向的数据传输和本地的读写操作。整个芯片的内存带宽达到每秒 21 拍字节,片上网络带宽每秒 214 拍字节。

(来源:https://www.cerebras.ai/)
WSE-3 芯片采用台积电 5 纳米工艺制造,每个计算核心的面积大约 3.8 万平方微米,其中一半是 48KB 的本地 SRAM,另一半是逻辑电路。整个芯片的 SRAM 总量达到 44GB。所有内存都分布在各核心旁边,数据从内存到计算单元的物理距离只有几十微米,不需要像传统 GPU 那样通过外部高带宽内存 HBM 来获取数据。Cerebras 声称,在同等硅片面积下,他们的内存带宽是 GPU 的大约 200 倍。

(来源:https://www.cerebras.ai/)
这种架构特别适合处理神经网络的非结构化稀疏,传统 GPU 无论权重是否为 0 都会进行计算,Cerebras 的做法是在发送端就把 0 值过滤掉,只把非 0 数据通过片上网络传给对应的计算核心。每个数据包包含 16 位数据和 16 位控制信息,接收端收到数据后自动触发乘加运算。这种方式避免了大量无效计算,在稀疏度较高的模型上可以获得明显加速。
该公司的技术白皮书显示,对于 BLAS 级别低于通用矩阵乘法的运算,比如矩阵向量乘或向量标量乘,传统芯片受限于内存带宽往往无法满负荷运行,Cerebras 的架构因为内存带宽足够高,可以保持高利用率。
(来源:https://www.cerebras.ai/)
Cerebras 的另一个核心技术叫 Weight Streaming,训练大模型时模型权重不存储在芯片上,而是放在一个叫 MemoryX 的外部设备里,按需流式传输到 WSE-3 芯片。计算每一层网络时,权重从外部 DRAM 和闪存中读取,通过芯片的输入输出接口送入计算核心。
每个权重到达核心后,与本地的激活值批量做乘加运算,计算完成后权重就被丢弃,不在芯片上停留。这种方法使得模型大小不受芯片内存容量的限制,可以支持万亿参数级别的超大模型。

(来源:https://www.cerebras.ai/)
在软件层面,Cerebras 提供了完整的编译工具链,可以把 PyTorch 或 TensorFlow 编写的模型自动映射到 90 万个核心上。对于 Transformer 类模型,激活张量有三个维度,批大小、序列长度和隐藏维度。编译器会把隐藏维度切分到芯片的 X 方向,把批大小和序列长度切分到 Y 方向。
计算矩阵乘法时,权重按行广播到对应列的所有核心,触发乘加运算,然后在列方向上进行部分和归约,最终结果分布在芯片上准备下一层的计算。所有计算调度都是静态配置的,指令在运行前一次性加载,执行过程中不再改变。

(来源:https://www.cerebras.ai/)
Cerebras 的五位联合创始人均有较深的芯片和系统背景。
CEO Andrew Feldman 毕业于斯坦福大学,此前创办的微服务器公司 SeaMicro 被 AMD 以 3.57 亿美元收购。
CTO Sean Lie 拥有麻省理工学院电子工程与计算机科学学士和硕士学历,在 SeaMicro 担任 IO 虚拟化架构师,被 AMD 收购后成为 AMD 院士。
系统架构师 Jean-Philippe Fricker 拥有洛桑联邦理工学院硕士学历,曾在 DSSD、SeaMicro、阿尔卡特朗讯和 Riverstone Networks 担任硬件架构职务。
先进技术首席架构师 Michael James 拥有加州大学伯克利分校分子神经生物学、数学和计算机科学三个学位,在 SeaMicro 负责分布式系统软件。
已荣誉退休的前 CTO Gary Lauterbach 拥有 50 多项专利,曾是 Sun Microsystems 的杰出工程师,主导了 UltraSPARC III 和 UltraSPARC IV 微处理器的架构设计。
Cerebras 的商业模式以销售完整的 CS-3 系统为主,CS-3 是围绕 WSE-3 芯片设计的整机系统,可以部署在数据中心的标准机架上。客户主要来自科研机构和企业,包括阿联酋的人工智能公司 G42 和穆罕默德·本·扎耶德人工智能大学。根据上市披露文件,2025 年 Cerebras 营收 5.1 亿美元,其中 G42 贡献了 24%,MBZUAI 贡献了 62%。公司全年净利润 2.38 亿美元,相比前一年的亏损 4.82 亿美元实现了扭亏为盈。
Cerebras 曾在 2024 年尝试上市,当时营收高度依赖单一客户 G42,后者贡献了 87% 的收入。由于涉及阿联酋背景的交易需要经过美国外国投资委员会的审查,虽然最终获得批准,Cerebras 还是撤回了上市申请。这次重新上市,客户集中度已经有所改善,最大客户 MBZUAI 占比降到 62%,不过前两大客户合计仍然贡献了 86% 的收入,集中风险依然存在。
Cerebras 的技术路线在 AI 芯片领域独树一帜。其他挑战者大多在架构上模仿 GPU,采用大量小核心配合 HBM 内存,Cerebras 选择了用一片巨大的晶圆来解决问题。这种方案在稀疏计算和大模型推理上有明显优势,不过制造成本和良率也面临挑战。
整片晶圆上只要有一个致命缺陷就可能影响整颗芯片,Cerebras 通过在设计中加入冗余链路和自动纠错机制来解决这个问题。晶圆级芯片的功耗和散热也是工程难题,CS-3 系统为此设计了专门的液冷方案。
随着 OpenAI、Anthropic、SpaceX 等 AI 公司即将陆续上市,AI 芯片赛道正在成为资本市场的焦点。Cerebras 作为第一家登陆纳斯达克的纯 AI 芯片新股,首日大涨 89% 给了后续企业一个积极的信号。
不过 AI 芯片市场的竞争也在加剧,除了英伟达,AMD、英特尔以及多家创业公司都在推出新产品。Cerebras 的晶圆级方案能否在主流 AI 训练市场站稳脚跟,还需要更多客户和更长时间来检验。
参考资料:
https://www.nytimes.com/2026/05/14/technology/cerebras-ipo-ai.html
https://www.linkedin.com/in/sean-lie-4a80097/
https://www.cerebras.ai/company/news
https://www.cerebras.ai/
文章来自于"DeepTech深科技",作者 "胡巍巍"。


【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
