# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

一直在大模型浪潮有点克制的苹果,终于不再低调了。在今年的苹果股东大会上,库克罕见地谈及了生成式 AI。
苹果 2024 年将在生成式 AI 领域“开辟新天地”。
今天,苹果首次揭晓了在多模态大型语言模型(LLM)研究领域的最新突破。
这是一篇题为《MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training》的学术论文,里面详细介绍了具有高达 30B 参数规模的系列多模态 LLM。
一、不只是数苹果,超大杯自带火眼金睛
直入主题,先来看看“超大杯” MM1-30B-Chat 的能力。
MM1-30B-Chat 不仅能准确无误地数出图片中苹果、橙子的数量,而且面对一连串数字的识别,也能轻松应对。

难度进一步升级,研究人员设置了一个陷阱问题,询问 MM1-30B-Chat 能看到图片中的红球吗?
并未中招的它能够明确地回应道:“图片中并无红球,我所见到的是一只猫正坐在沙发的枕头上,除此之外,别无他物。”

我们时常在朋友圈上看到飞机上随手一拍的风景图,那 MM1-30B-Chat 会怎么解读这些风景图呢?

目睹这幅图像,人们会体验到敬畏、好奇和宁静等多种情感。飞机窗户外展现的景色令人叹为观止:飞机的机翼下,是一片广阔而雪白的山脉,给人一种宁静和自然之美的深刻感受。
山脉宏伟、层次分明的排列,及其雪峰与明亮的蓝天形成的对比,让人不禁对自然世界充满惊奇和赞赏。
这种视角还提供了一个日常生活中难以体验的独特世界,激发出人们的好奇心和兴奋感。此外,图中未被触及、原始的风景,还能带来平静与安宁之感。
它提取信息的能力也是一流,光靠一张图,就能滔滔不绝地给你解释清楚蒸发和散发的区别。
推理能力是大模型必备的核心竞争力之一,这种能力使得模型能够从有限的信息中提炼出深层次的见解和关联。MM1-30B-Chat 仅凭照片,就能推理出下面这些信息:

二、MM1 是怎么做到的?
苹果发布的论文里详细披露了背后的研究过程。
得益于大规模图像-文本数据的丰富性和大规模计算能力的普及,多模态大模型已经成为众多顶尖模型的标配。
现有的多语言大型语言模型(MLLMs)主要分为封闭和开放两类。封闭模型的信息有限,而开放模型提供详细的参数、数据和训练配置,便于进一步研究。不过,大多数研究缺乏关于算法设计选择的透明度,特别是在多模态预训练方面。
因此,苹果撰写的这篇论文详细记录了多语言大型语言模型(MLLM)的开发过程,并尝试归纳出宝贵的设计经验。

具体来说,研究团队在模型架构决策和预训练数据选择进行了小规模的消融实验,探讨了模型架构决策和预训练数据选择,并观察到了几个有趣的趋势:
在模型设计方面,研究人员发现图像分辨率、视觉编码器的损失和容量、以及视觉编码器的预训练数据是至关重要的考量点。但出乎意料的是,几乎没有发现有力证据支持视觉数据输入到大型语言模型(LLM)的架构设计对性能有显著影响。
此外,研究人员探索了三种不同的预训练数据类型:图像字幕、交错的图像文本数据以及纯文本数据。
他们发现,对于少样本学习和纯文本任务的性能来说,交错的图像-文本数据和纯文本数据极为关键,而对于零样本学习的性能而言,图像-标题对数据最为重要。

经过监督微调(SFT)阶段后,研究人员证实了这些趋势的持续性,无论是在预训练阶段的评估中,还是在后续的基准测试中。这一发现表明,模型在预训练阶段所展现的能力以及所做出的建模决策,在经过微调之后依然保持其有效性。
在研究的最终阶段,研究团队通过扩展至更大规模的大型语言模型(LLMs),包括 3B、7B 至 30B 参数级别的模型,以及探索混合专家(MoE)模型的不同配置——从拥有 64 个专家的 3B MoE 到拥有 32 个专家的 7B MoE——来进一步增强模型的性能。
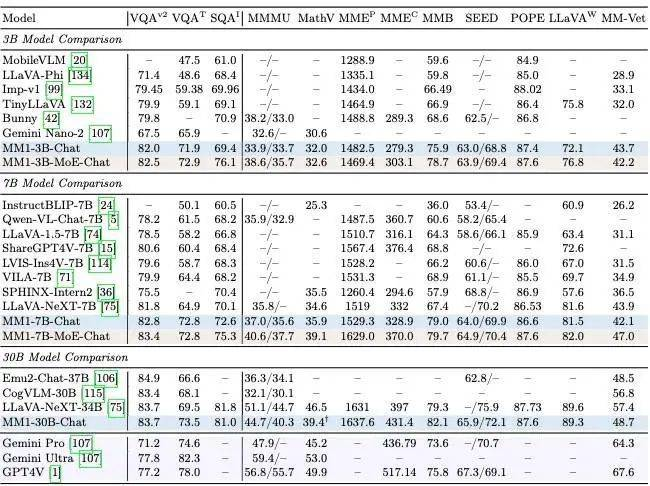
预训练模型 MM1 在少样本学习设置中,无论是在小型还是大型规模上,都在标题生成和视觉问答(VQA)任务上超越了 Emu2、Flamingo 和 IDEFICS 等众多先进模型。经过监督微调(SFT)后的最终模型,在 12 个公认的多模态基准测试中展现了竞争力十足的性能。
得益于广泛的大规模多模态预训练,MM1 展现出了一系列引人注目的能力,包括上下文预测、多图像处理和连贯性推理等。
此外,经过指令调优的 MM1 还表现出了卓越的少样本学习能力。这些显著的成果证明了研究团队提出的构建多语言大型语言模型(MLLM)的方法能够有效地将设计原则转化为实际中具有竞争力的规模化模型。
三、构建 MM1 的秘诀
构建高性能多模态大型语言模型(MLLMs)是一项极其依赖经验的工作。虽然高层次的架构设计和训练流程是明确的,但实际形式和执行方式却不明确。
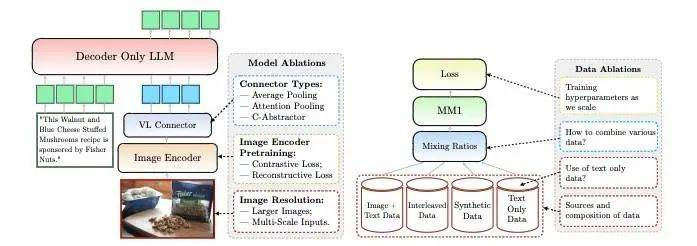
研究人员详细记录了为了构建高性能模型所进行的一系列消融实验。主要有三个设计决策维度:
鉴于训练大型多模态语言模型(MLLMs)可能涉及庞大的资源消耗,研究人员采取了一种精简的实验设置来进行消融实验。
1. 模型架构消融
实验过程中,研究者分析了使大型语言模型(LLM)有效处理视觉数据的关键组件。他们专注于两个主要问题:最佳预训练视觉编码器的方法,以及如何将视觉特征与 LLM 的内部空间有效结合起来。
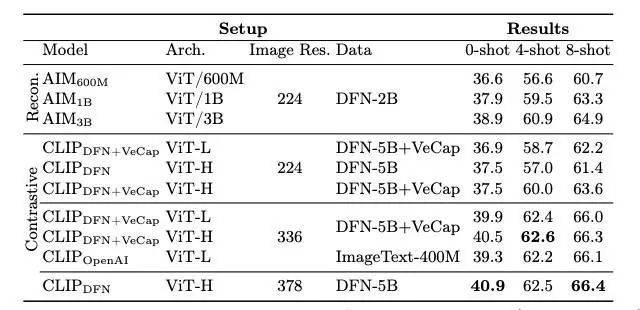
图像编码器的预训练:多数多模态大型语言模型(MLLMs)使用 CLIP 预训练的图像编码器,也有研究探索使用 DINOv2 等仅视觉的自监督模型。研究显示,预训练图像编码器的选择对下游任务性能有显著影响,重点关注图像分辨率和预训练目标的重要性。在此过程中,研究人员使用了 2.9B 的 LLM 以充分挖掘大型图像编码器的潜力。
对比损失与重建损失:大规模图像-文本数据集训练的模型展现出强大的语义理解能力,这得益于数据的丰富性和视觉编码器的语义知识。然而,CLIP 风格的模型在密集预测任务上表现不佳,因此研究者考虑使用重建损失来提升图像理解的详细程度。
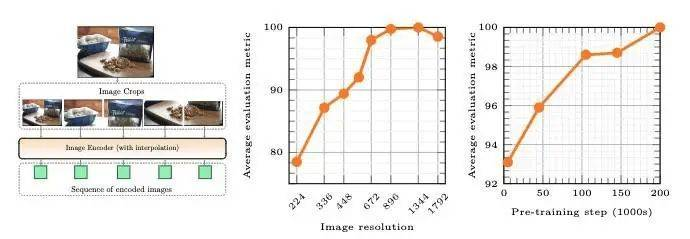
编码器课程的影响:研究发现,图像分辨率的提升对性能影响最大,其次是模型大小和训练数据组成。提高图像分辨率、增加模型参数和引入合成字幕数据集均能带来性能的小幅提升。
模型类型的选择:对比方法通常优于重建方法,特别是 ViT-L 编码器在性能上小幅超越同等尺寸的 AIM。
2. 预训练数据消融
在追求高性能模型的训练过程中,获取大量且与任务相关的数据是至关重要的。通常,模型的训练被分为两个关键阶段:预训练和指令调优。
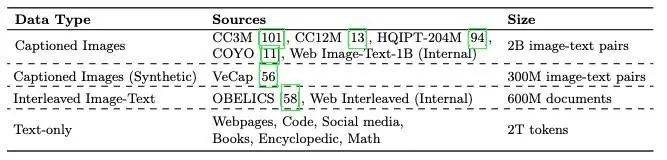
预训练阶段涉及使用广泛的网络数据,旨在为模型提供一个全面的学习基础。随后的指令调优阶段则利用针对特定任务精心挑选和策划的数据,以进一步提升模型在该任务上的表现。
而研究人员则集中讨论预训练阶段,并详细阐释他们在数据选择上的策略和考量。
3. 最终模型与训练方法
研究人员选用了 378x378 像素分辨率的 ViT-H 模型,并在 DFN-5B 数据集上以 CLIP 目标进行预训练。
研究显示视觉标记的数量至关重要,因此他们采用了包含 144 个标记的连接器,选择了 C-Abstractor 作为连接器架构。
为了保持模型在零样本和少样本场景下的性能,研究人员使用了 45% 的交错图像-文本、45% 的图像-文本对和 10% 纯文本的数据组合。
他们也将大型语言模型(LLM)的参数规模扩展至 3B、7B 和 30B,并在相同文本数据集上进行训练。利用预训练的LLM和视觉编码器初始化 MM1,并在混合数据上进行了 200 万步的多模态预训练。
所有模型都在 AXLearn 框架下,以不冻结状态、4096 的序列长度、每序列最多 16 张图像、378×378 分辨率和 512 序列的批次大小进行训练。
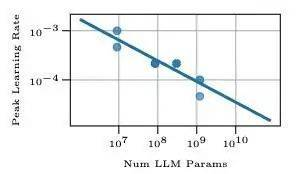
鉴于在这样规模下进行精确的超参数搜索是不现实的。研究人员依据 LLM 的扩展规律,在小规模上进行了学习率的网格搜索,并确定了最佳学习率,随后将其应用于更大规模的模型中。
4. 监督微调
研究人员还阐述了基于预训练模型所进行的监督微调(SFT)实验细节。
它们遵循了 LLaVA-1.5 和 LLaVA-NeXT 的方法,并从一系列多样化的数据集中收集了大约 100 万个 SFT 示例,包括:
由 GPT-4 和 GPT-4V 生成的指令-响应对,LLaVA-Conv 和 LLaVA-Complex 用于对话和复杂推理,以及 ShareGPT-4V 用于详细图像描述。
针对学术任务的视频-语言(VL)数据集,涵盖了自然图像的 VQAv2、GQA、OKVQA、A-OKVQA 和 COCO Captions;文本丰富的图像数据集 OCRVQA 和 TextCaps;以及文档和图表理解的 DVQA、ChartQA、AI2D、DocVQA、InfoVQA 和 Synthdog-En。
此外,研究人员使用了类似于ShareGPT 的内部数据集,以保持模型对仅文本指令的遵循能力。
5. 论文结论
研究团队致力于探索构建高效能的多模态大型语言模型(MLLMs)的策略。通过精心设计的消融实验,研究人员对建模和数据选择进行深入分析,从而归纳出一系列关键的经验教训。
这些经验成功培养出一个预训练模型,在各种少样本评估中取得了业界领先的成绩。经过监督微调(SFT)的过程,这一模型系列在多个基准测试中展现出卓越的性能,不仅能够处理多图像推理任务,还能适应少样本提示的挑战。
更多研究细节,请查阅论文地址:https://arxiv.org/pdf/2403.09611.pdf
另外,据彭博社报道,苹果在今年早些时候还悄然收购了加拿大 AI 初创公司 DarwinAI。而该公司掌握的核心技术之一是利用 AI 来理解深度神经网络算法,并据此定制生成一系列经过高度优化、满足特定需求的神经网络。
报道还指出,这项技术对苹果公司来说可能极具战略价值,因为它完美契合苹果致力于在设备上直接运行 AI 功能的长远规划,而非单纯依赖云端计算。
无论是发表学术论文,还是战略性收购,这一连串举措都清晰表明了苹果即将在 AI 领域大展拳脚。
如今距离 WWDC24 仅剩不到三个月的时间,现在,让我们备好爆米花,屏息以待,准备迎接库克所描述的“开辟新天地”。
本文来自微信公众号:APPSO (ID:appsolution),作者:莫崇宇




【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
